初识hadoop
2017-05-05 18:32 轩脉刃 阅读(852) 评论(0) 编辑 收藏 举报初识hadoop
概念
hadoop首先是大数据领域。大数据领域至少是分布式的,分布式数据必然是有一定规模了。如果数据只有几个G或者更小就没有什么意义了。
hadoop最核心的概念就是HDFS和MapReduce。hadoop的源码在github上也有对应的开源:https://github.com/apache/hadoop
hdfs
hdfs是一个分布式文件系统。我们有多台廉价的机器,需要存储非常大量的数据。我们就需要使用一个文件系统,把数据分成块,分别放在不同的机器上,并且可以使用像hdfs://A/B/C 之类的路径进行访问。
hdfs和nfs有什么区别?
linux的nfs (Network File system)是网络文件系统协议。为的是不同机器上的文件可以互相访问。比如B机器把A机器上的一个分区\home\a挂载为自己机器上的\home\b,这样在B机器上就可以像访问本地机器上的文件一样访问A机器上的文件了。

而hdfs (Hadoop Distributed File System)是hadoop的分布式文件系统。它是通过网络和机器节点把多个机器上的文件统一成一个文件系统的机制。HDFS不止是解决多个机器之间的文件访问问题。还解决了数据备份,切割之类的问题。
一个文件,在nfs上必然完完整整存储在一个节点的一个硬盘上。但是在hdfs中,一个文件可能会被切割为多个小文件,存储在不同的机器上。甚至于,每个小文件还会有一份备份以防止数据丢失。
hdfs架构

hdfs基本还是主从结构,有一个namenode,和多个datanode。所有对文件的访问都经过namenode,namenode中存储文件访问路径和实际存储路径的映射关系,就是元数据。然后通过了namenode,就访问datanode获取实际的文件。
mapreduce
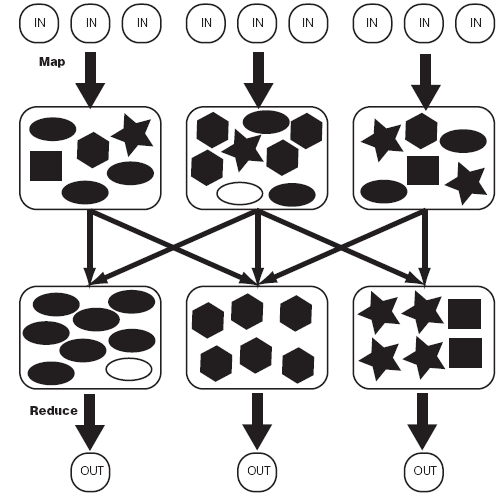
mapreduce是一个计算框架,它分为map部分和reduce。map阶段相当于把数据进行整理的阶段,各种相同的数据都整理在一起,reduce相当于是统计阶段,统计出每个数据需要的数据。其中,map整理完的数据,哪个reduce处理哪个整理完的数据,这个过程叫做shuffle。
实时了解作者更多技术文章,技术心得,请关注微信公众号“轩脉刃的刀光剑影”
本文基于署名-非商业性使用 3.0许可协议发布,欢迎转载,演绎,但是必须保留本文的署名叶剑峰(包含链接http://www.cnblogs.com/yjf512/),且不得用于商业目的。如您有任何疑问或者授权方面的协商,请与我联系。

