解码 xsync 的 map 实现
2024-07-17 09:14 轩脉刃 阅读(539) 评论(4) 收藏 举报解码 xsync 的 map 实现
最近在寻找 Go 的并发 map 库的时候,翻到一个 github 宝藏库,xsync (https://github.com/puzpuzpuz/xsync) 。这个库提供了一些支持并发的数据结构,计数器Counter,哈希 Map,队列Queue。我着重看了下它的 Map 的实现,遇到一个新的知识点:Cache-Line Hash Table (CLHT) 。问了半天 GPT,大致了解了其中的内容,这里总结下。
利用 Cache-Line 实现无锁编程
CacheLine 是 CPU 一次性读取内存的最小单元。它在不同的硬件设备上有不同的大小。在x86-64的机器上是 64 字节。就代表着 CPU 一次性能从内存中获取64 字节的大小。CPU处理器在处理一个变量数据的时候,会依次从寄存器,CPU 缓存,内存,磁盘中进行获取,当然他们的处理速度也是依次递减。
当计算机中多个 CPU 核读写同一个数据结构的时候,他们每次都会读取CacheLine 结构的数据进入自己的 CPU 缓存中。这里不同的数据结构设计,就会有不同的性能。
假设有一个大的数据结构 Object,a1 核负责读Object 的 field1 字段,而 a2 核负责写 Object 的 field2 字段,而 field1 和 field2 都在同一个 Cache Line 中,这就意味着 a1 和 a2 在并行计算的时候,都会把包含有 field1 和 field2 字段的 Cache line 读取到自己的 CPU 缓存中。那么问题来了,当 a2 核变更 field2 字段的时候,就要想办法通知a1 核,更新 CPU 缓存,否则a1 核计算可能是有问题的。a2核变更通知 a1 核更新 CPU 缓存,这种交互机制叫做 MESI。
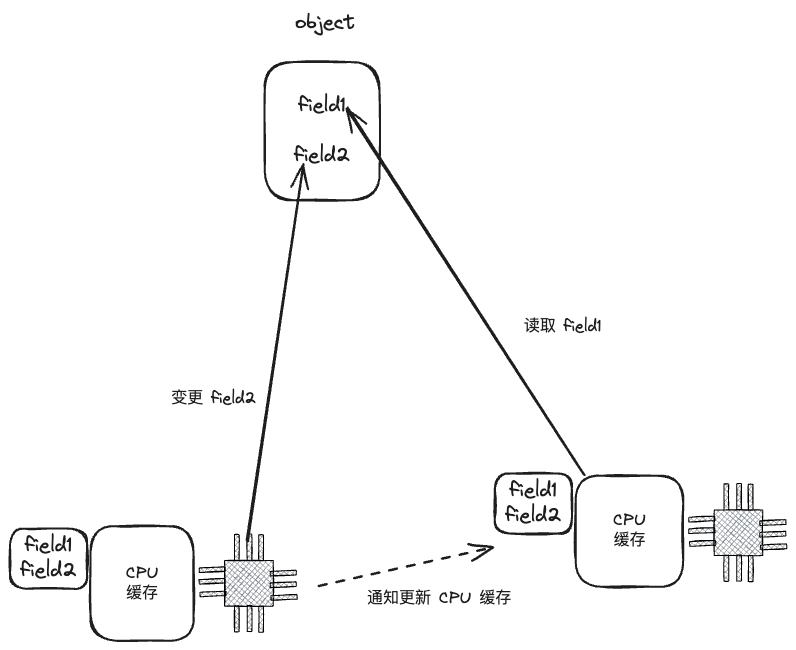
当然这种交互机制是非常低效的。我们应该想办法尽量避免!
其中一种避免的方法之一就是使用锁,在修改数据的时候上锁,读取数据的时候读锁。但这种方式并不高效。我们在想,是否有一种无锁的编程方式呢?
控制 Object 结构的设计是个好办法,我们设计结构将其中的 field1 字段放在一个 CacheLine 中,另外一个 field2 在第二个 CacheLine 中,那么如果我们使用 a1 线程读 field1,a2 线程写 field2,那么我们就能做到无锁读写。

这就是利用 Cache-line 实现的无锁编程。
基于 CacheLine 的哈希表
节点设计
现在回到 hash 表,我们使用 hash 表的时候最头疼的就是 hash 表是非并发安全的,一般我们使用 hash 表的时候,都会带一个全局锁,我们读写hash 表的时候会读或者写一下这个全局锁。
但是这明显效率就比较低了。
要想效率高,Cache-Line Hash Table (CLHT) 就提出了使用 CacheLine 的逻辑来优化 hash 表。一个 hash 表一般就是一个 hash 函数+节点链表,我们如果让每个节点都保持一个 CacheLine 的大小(64 byte)。那么每次 cpu 读写的时候,就只会读取一个完整的节点进入到 cpu 缓存中,这样不是就能无锁使用 hash 表了吗?
是的,这种方案确实可行,但是最重要的就是设计这个 由多个hash节点组成的 hash 表结构。
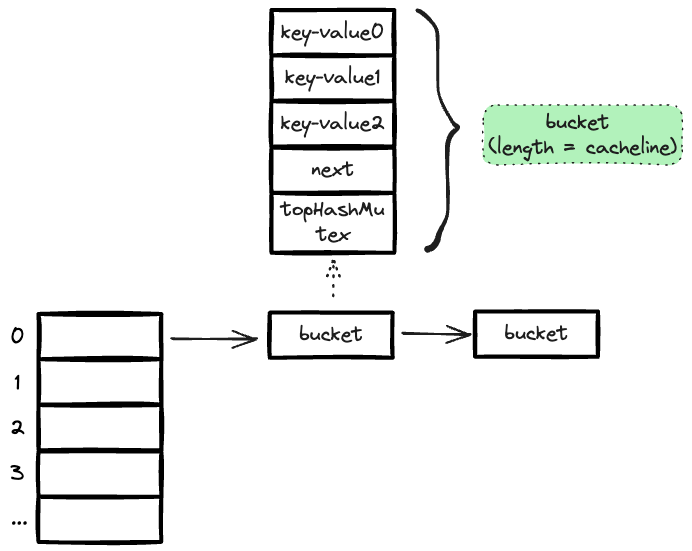
我们先需要回答:一个 CacheLine(64 bytes = 64 * 8 bit = 512 bit) 能保存多少个hash key-value 对呢?
解:
一个指针是 uint64 类型,hash 的每个 key-value 对中 key 和 value 都是指针,key 指向一个 string,value 指向一个 interface{}, 即任何的数据结构, 那么一个 key-value 对占2*64bit = 128bit。
由于 hash 表中相同 hash的节点是通过指针链链接起来的,所以至少节点中要保存一个指向 next 节点的指针,uint64 = 64bit。
所以一个 cacheline 最多可以有3 个key-value 对 + 1 个 next 指针 = 128 * 3 + 64 = 448 bit。
解答完毕。
但是如此设计,cacheline 的空间还有盈余,还多了一个 512 - 448 = 64 bit 的大小,我们利用这个空间设计了一个 topHashMutex 结构(uint64),具体它是做什么用的,后面详聊。
我们的 bucke 节点在代码中如上设计,实现如下:
type bucket struct {
next unsafe.Pointer // *bucketPadded
keys [3]unsafe.Pointer
values [3]unsafe.Pointer
...
topHashMutex uint64
}
而我们的 hash 表结构就有如下展示:
不同场景分析
这样根据 cacheline 设计 hash 表,是否能实现真正的无锁化呢?我们需要分析不同场景:
1 两个 cpu 核,读取两个不同的 bucket 节点
这是我们最希望见到的情况,由于我们事先设计了每个 bucket 节点正好是一个 hash 大小。
所以两个 cpu 读取自己的cpu 缓存即可,里面的节点互相不干扰,这个时候效率非常高。
2 两个cpu核,读取相同的 bucket 节点
这个 bucket 节点会从内存中被复制两份到两个 cpu 缓存中,但是这种场景,由于没有任何更新操作,我们也用不到任何锁。
3 两个 cpu 核,对相同 bucket 节点,一个在读取,另一个在更新
这种情况,我们要保证的是读取的操作一定是原子的,我们可以读取更新前的值,也可以读取更新后的值,但是不能读取一个中间无效的值。
所以读取的 cpu 核在读取自己 cpu 缓存内容的时候,必须小心 cpu 缓存被修改,而导致了无效值。那么我们能怎么做呢?
指针快照的方法(snapshot)
首先,我们先从 bucket 节点中找到目标 key-value 对(这里如何快速找到后面会说),我们先读取一次key1 和 value1 ,但是注意,由于之前设计,我们bucket 里面存储的是key1 指针,value1 指针,所以我们实际读取的是指针。这个时候并不直接使用这个指针指向的内容,而是相当于我们为 key1 和 value1 做了一个快照。
这里要注意的是,读取 key1 和 value1 的指针快照是2 个原子操作。但是这两个原子操作,由于另外一个核在更新这个 key-value 对,就是在通过 MESI 机制同步修改我们的 cpu 缓存,我们是有可能读取到一个无效指针 value1 的(我们是否不会读到无效指针 key1,因为更新操作不会修改 key1 的指针)。
那么我们如何确定 value1 是可用的呢?办法就是我们再取一次cpu 缓存中的 key1 和 value1 指针,判断他们是否有变化。
如果快照 key1和快照 value1 等于第二次查询的 key1 和 key2,那么就证明快照的 key1 和 value1 是可用的,不是正被修改中的内存。
如果快照 key1和快照 value1 不等于第二次查询的 key1 和 key2,那么就证明快照的 key1 和 value1 是不可用的,当前正在有其他cpu 在修改我的 cpu 缓存,这时候要做的就是重新进行快照过程。
这就是 atomic snapshot 的方法。
代码实现如下:
func (m *Map) Load(key string) (value interface{}, ok bool) {
...
for {
...
atomic_snapshot:
// Start atomic snapshot.
vp := atomic.LoadPointer(&b.values[i])
kp := atomic.LoadPointer(&b.keys[i])
if kp != nil && vp != nil {
if key == derefKey(kp) {
if uintptr(vp) == uintptr(atomic.LoadPointer(&b.values[i])) {
// Atomic snapshot succeeded.
return derefValue(vp), true
}
// Concurrent update/remove. Go for another spin.
goto atomic_snapshot
}
}
}
bptr := atomic.LoadPointer(&b.next)
if bptr == nil {
return
}
b = (*bucketPadded)(bptr)
}
}
引申一下,这个更新操作,实际换成删除操作也是生效的,因为删除操作相当于试一次特殊的更新(将 value1 的指针替换为 nil)。
4 两个CPU核,对相同的 bucket 节点,两个都在写
在这种场景下,我们需要保证只有一个 cpu 核在写,另外一个需要等待,我们不得不使用锁了,但是这个锁是非常小的,它只保证锁住 cacheline 就行了。
锁放在哪里呢?前面设计的 uint64 topHashMutex , 我们只需要使用1bit 的大小(最后一个 bit),标记 0/1就行了,0 代表没有锁,1 代表锁。
更新操作的时候,我们需要用 atomic.CompareAndSwapUint64 来抢到这个 topHashMutex 的最后一个 bit 的锁。
如果抢到的话,当前 cpu 核就可以心安理得的处理自己的 cpu 缓存区的内容,并且通知其他的 cpu 缓存区内容进行更新。
如果没有抢到的话,当前 cpu 核使用自旋锁,进入锁等待阶段,runtime.Gosched(), 让渡这个 goroutine 的执行权。等着go 调度机制再次调度到到这个goroutine,再次抢锁。
加锁代码逻辑如下:
func lockBucket(mu *uint64) {
for {
var v uint64
for {
v = atomic.LoadUint64(mu)
if v&1 != 1 {
break
}
runtime.Gosched()
}
if atomic.CompareAndSwapUint64(mu, v, v|1) {
return
}
runtime.Gosched()
}
}
同样引申一下,这个情景也适用于两个 CPU的删除操作,或者更新删除操作并行的情况。cacheline 小锁的机制,保证了同一时间只有一个 cpu 核能对这个节点进行操作。
如何加速节点中 key-value 对的查找
好了,以上四种情况基本把并发读写同一个 map 节点的情景都列出来了。
但是还差一点,bucket 中的 topHashMutex 结构还有 63bit 的剩余空间,我们是否可以利用它来加速key-value 对的查找?答案是可以的,我们可以通过建立索引机制来加速。
我们将这个 63bit 分为 3 x 20 + 3 。前面的 3 个 20 是3 个 key-value 对的 key 值的索引。至于索引方式嘛,我们可以简单将 key 的 hash 值的前 20 位作为索引。这样我们在查找一个 key 的时候,先判断下其 hash 值的前 20 位在不在这个索引中,就能大概率判断出是否在这个 bucket 节点中了。
但是建立索引还是不够,前面说过了,删除某个 key-value,我们是直接将 value 的指针置为 nil,那么这个时候,它的 key 还存在,我们需要标记位来标记这个 key 是否能用。
topHashMutex 后面的 3 个 bit 就启动用处了, 0/1表示3 个 key-value 是否可用。
topHashMutex 的结构如下:
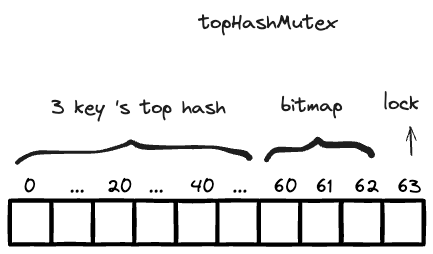
我们再举例说明:
假设我有一个 key 为 "foo", value 为 struct Bar。存储时,我们算好要存入 bucket 的第二个 key-value 位置。
"foo" 的 hash 值为 uint64: 1721009463561,转为二进制:1100010000110110110110110110110111101001001,取前 20 位,11000100001101101101。
我们把 topHashMutex 的第二个 20bit 设置为11000100001101101101。再把 topHashMutex 的第 62(3 x 20 + 2)设置为 1.表示可用。
在查询操作,我们在拿着 key = "foo" 来查找 value 的时候,先去判断 key 的 hash是否在前 60bit 中,然后再确认下对应的 bitmap 是否是可用的,我们就能判断目标 key 大概率是在这个 bucket 的第二个位置,我们这时候再走快照逻辑,判断快照的 key 的值是否是 “foo”,并且快照原子获取其value 值。
结论
这就是这个开源 go 的 xsync 库中的 Map 结构的核心原理了。确实是非常巧妙的设计思路。核心思想就是利用cpu 一次读取 cacheline 大小的内容进 cpu 缓存区,就设计一个符合这个特性的 hash 表,尽量保证每个 cpu 的读取互不干扰,对于可能出现的并发干扰的情况,使用快照机制能保证读取的原子性,这样能有效避免全局锁的使用,提高性能。
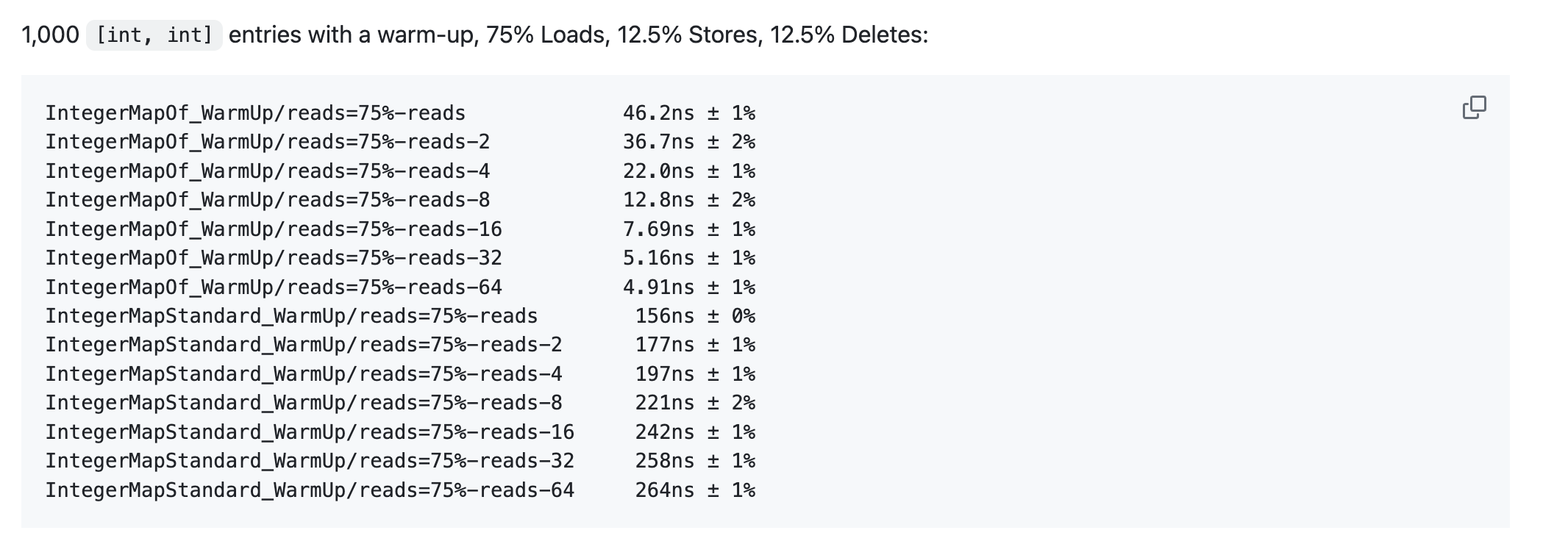
至于可以看这个 benchmark 测评,https://github.com/puzpuzpuz/xsync/blob/main/BENCHMARKS.md 比较了xsync 的 map 和标准库 sync.Map。基本上真是秒杀,特别是在读写混杂的情况下,xsync 能比 sync.Map 节省2/3 的时间消耗。
参考
实时了解作者更多技术文章,技术心得,请关注微信公众号“轩脉刃的刀光剑影”
本文基于署名-非商业性使用 3.0许可协议发布,欢迎转载,演绎,但是必须保留本文的署名叶剑峰(包含链接http://www.cnblogs.com/yjf512/),且不得用于商业目的。如您有任何疑问或者授权方面的协商,请与我联系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号