



Spark Streaming中的操作函数讲解
Spark Streaming中的操作函数讲解
根据根据Spark官方文档中的描述,在Spark Streaming应用中,一个DStream对象可以调用多种操作,主要分为以下几类
- Transformations
- Window Operations
- Join Operations
- Output Operations
一、Transformations
1、map(func)
map操作需要传入一个函数当做参数,具体调用形式为
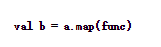
主要作用是,对DStream对象a,将func函数作用到a中的每一个元素上并生成新的元素,得到的DStream对象b中包含这些新的元素。
下面示例代码的作用是,在接收到的一行消息后面拼接一个”_NEW”字符串

程序运行结果如下:
注意与接下来的flatMap操作进行比较。
2、flatMap(func)
类似于上面的map操作,具体调用形式为
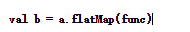
主要作用是,对DStream对象a,将func函数作用到a中的每一个元素上并生成0个或多个新的元素,得到的DStream对象b中包含这些新的元素。
下面示例代码的作用是,在接收到的一行消息lines后,将lines根据空格进行分割,分割成若干个单词
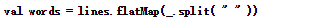
结果如下:
3、 filter(func)
filter传入一个func函数,具体调用形式为

对DStream a中的每一个元素,应用func方法进行计算,如果func函数返回结果为true,则保留该元素,否则丢弃该元素,返回一个新的DStream b。
下面示例代码中,对words进行判断,去除hello这个单词。
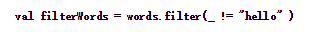
结果如下:
4、union(otherStream)
这个操作将两个DStream进行合并,生成一个包含着两个DStream中所有元素的新DStream对象。
下面代码,首先将输入的每一个单词后面分别拼接“_one”和“_two”,最后将这两个DStream合并成一个新的DStream
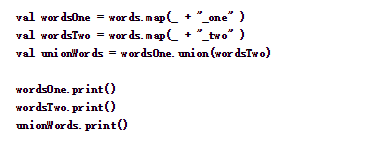
运行结果如下:
5、count()
统计DStream中每个RDD包含的元素的个数,得到一个新的DStream,这个DStream中只包含一个元素,这个元素是对应语句单词统计数值。
以下代码,统计每一行中的单词数
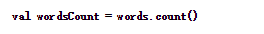
运行结果如下,一行输入4个单词,打印的结果也为4。
6、reduce(func)
返回一个包含一个元素的DStream,传入的func方法会作用在调用者的每一个元素上,将其中的元素顺次的两两进行计算。
下面的代码,将每一个单词用"-"符号进行拼接

运行结果如下:
7、countByValue()
某个DStream中的元素类型为K,调用这个方法后,返回的DStream的元素为(K, Long)对,后面这个Long值是原DStream中每个RDD元素key出现的频率。
以下代码统计words中不同单词的个数
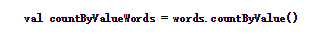
结果如下:
8、reduceByKey(func, [numTasks])
调用这个操作的DStream是以(K, V)的形式出现,返回一个新的元素格式为(K, V)的DStream。返回结果中,K为原来的K,V是由K经过传入func计算得到的。还可以传入一个并行计算的参数,在local模式下,默认为2。在其他模式下,默认值由参数spark.default.parallelism确定。
下面代码将words转化成(word, 1)的形式,再以单词为key,个数为value,进行word count。
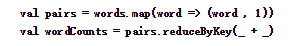
结果如下,
9、join(otherStream, [numTasks])
由一个DStream对象调用该方法,元素内容为(k, V),传入另一个DStream对象,元素内容为(k, W),返回的DStream中包含的内容是(k, (V, W))。这个方法也可以传入一个并行计算的参数,该参数与reduceByKey中是相同的。
下面代码中,首先将words转化成(word, (word + "_one"))和(word, (word + "_two"))的形式,再以word为key,将后面的value合并到一起。
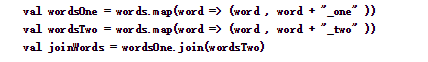
运行结果如下:
10、cogroup(otherStream, [numTasks])
由一个DStream对象调用该方法,元素内容为(k, V),传入另一个DStream对象,元素内容为(k, W),返回的DStream中包含的内容是(k, (Seq[V], Seq[W]))。这个方法也可以传入一个并行计算的参数,该参数与reduceByKey中是相同的。
下面代码首先将words转化成(word, (word + "_one"))和(word, (word + "_two"))的形式,再以word为key,将后面的value合并到一起。
结果如下:
11、transform(func)
在Spark-Streaming官方文档中提到,DStream的transform操作极大的丰富了DStream上能够进行的操作内容。使用transform操作后,除了可以使用DStream提供的一些转换方法之外,还能够直接调用任意的调用RDD上的操作函数。
比如下面的代码中,使用transform完成将一行语句分割成单词的功能。

运行结果如下:
12、updateStateByKey(func)
二、Window Operations
我觉得用一个成语,管中窥豹,基本上就能够很形象的解释什么是窗口函数了。DStream数据流就是那只豹子,窗口就是那个管,以一个固定的速率平移,就能够每次看到豹的一部分。
窗口函数,就是在DStream流上,以一个可配置的长度为窗口,以一个可配置的速率向前移动窗口,根据窗口函数的具体内容,分别对当前窗口中的这一波数据采取某个对应的操作算子。需要注意的是窗口长度,和窗口移动速率需要是batch time的整数倍。接下来演示Spark Streaming中提供的主要窗口函数。
1、window(windowLength, slideInterval)
该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
下面的代码以长度为3,移动速率为1截取源DStream中的元素形成新的DStream。
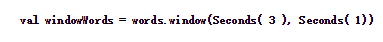
运行结果如下:
基本上每秒输入一个字母,然后取出当前时刻3秒这个长度中的所有元素,打印出来。从上面的截图中可以看到,下一秒时已经看不到a了,再下一秒,已经看不到b和c了。表示a, b, c已经不在当前的窗口中。
2、 countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数。
代码如下,统计当前3秒长度的时间窗口的DStream中元素的个数:
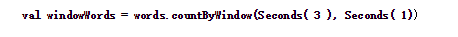
结果如下:
3、 reduceByWindow(func, windowLength,slideInterval)
类似于上面的reduce操作,只不过这里不再是对整个调用DStream进行reduce操作,而是在调用DStream上首先取窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce。
代码如下:
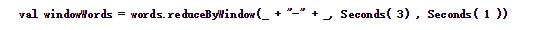
结果如下:
4、 reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
调用该操作的DStream中的元素格式为(k, v),整个操作类似于前面的reduceByKey,只不过对应的数据源不同,reduceByKeyAndWindow的数据源是基于该DStream的窗口长度中的所有数据。该操作也有一个可选的并发数参数。
下面代码中,将当前长度为3的时间窗口中的所有数据元素根据key进行合并,统计当前3秒中内不同单词出现的次数。
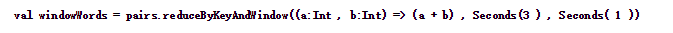
结果如下:
5、 reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
这个窗口操作和上一个的区别是多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的。
在下面这个例子中,如果把3秒的时间窗口当成一个池塘,池塘每一秒都会有鱼游进或者游出,那么第一个函数表示每由进来一条鱼,就在该类鱼的数量上累加。而第二个函数是,每由出去一条鱼,就将该鱼的总数减去一。
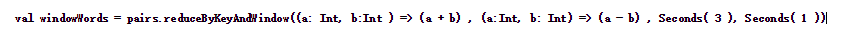
下面是演示结果,最终的结果是该3秒长度的窗口中历史上出现过的所有不同单词个数都为0。
一段时间不输入任何信息,看一下最终结果
6、 countByValueAndWindow(windowLength,slideInterval, [numTasks])
类似于前面的countByValue操作,调用该操作的DStream数据格式为(K, v),返回的DStream格式为(K, Long)。统计当前时间窗口中元素值相同的元素的个数。
代码如下

结果如下
三、Join Operations
Join主要可分为两种,
1、DStream对象之间的Join
这种join一般应用于窗口函数形成的DStream对象之间,具体可以参考第一部分中的join操作,除了简单的join之外,还有leftOuterJoin, rightOuterJoin和fullOuterJoin。
2、DStream和dataset之间的join
这一种join,可以参考前面transform操作中的示例。
四、Output Operations
在Spark Streaming中,DStream的输出操作才是DStream上所有transformations的真正触发计算点,这个类似于RDD中的action操作。经过输出操作DStream中的数据才能与外部进行交互,比如将数据写入文件系统、数据库,或其他应用中。
1、print()
print操作会将DStream每一个batch中的前10个元素在driver节点打印出来。
看下面这个示例,一行输入超过10个单词,然后将这行语句分割成单个单词的DStream。
看看print后的效果。
2、saveAsTextFiles(prefix, [suffix])
这个操作可以将DStream中的内容保存为text文件,每个batch的数据单独保存为一个文夹,文件夹名前缀参数必须传入,文件夹名后缀参数可选,最终文件夹名称的完整形式为prefix-TIME_IN_MS[.suffix]
比如下面这一行代码

看一下执行结果,在当前项目路径下,每秒钟生成一个文件夹,打开的两个窗口中的内容分别是nc窗口中的输入。
另外,如果前缀中包含文件完整路径,则该text文件夹会建在指定路径下,如下图所示
3、saveAsObjectFiles(prefix, [suffix])
这个操作和前面一个类似,只不过这里将DStream中的内容保存为SequenceFile文件类型,这个文件中保存的数据都是经过序列化后的Java对象。
实验略过,可参考前面一个操作。
4、saveAsHadoopFiles(prefix, [suffix])
这个操作和前两个类似,将DStream每一batch中的内容保存到HDFS上,同样可以指定文件的前缀和后缀。

