

案例:设置 HDFS 文件系统的状态后端,取消 Job 之后再次恢复 Job。查看其状态是否连续?
代码示例:
import org.apache.flink.api.scala.createTypeInformation import org.apache.flink.runtime.state.filesystem.FsStateBackend import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} object TestCheckByHdfs { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.enableCheckpointing(5000) env.setStateBackend(new FsStateBackend("hdfs://node2/flink/checkpoint/cp1")) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) env.getCheckpointConfig.setCheckpointTimeout(5000) env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) env.getCheckpointConfig.enableExternalizedCheckpoints( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) // 终止job时不会删除检查点数据 // 默认并行度给所有算子适用,并行度<= slot数量 env.setParallelism(1) // 3. 读取数据 sock流中的数据 // DataStream 相当于spark中的Dstream val stream: DataStream[String] = env.socketTextStream("node1", 8888) // 4. 转换和处理数据 val result: DataStream[(String, Int)] = stream.flatMap(_.split(" ")) .map((_, 1)).setParallelism(2) .keyBy(0) // 分组算子,0或者1 代表下标,0代表单词,1代表单词出现的次数 .sum(1) // 聚会累加算子 result.print("结果") env.execute("wordcount") } }
- 打包在服务器上执行
首先应启动Flink webUI及hdfs
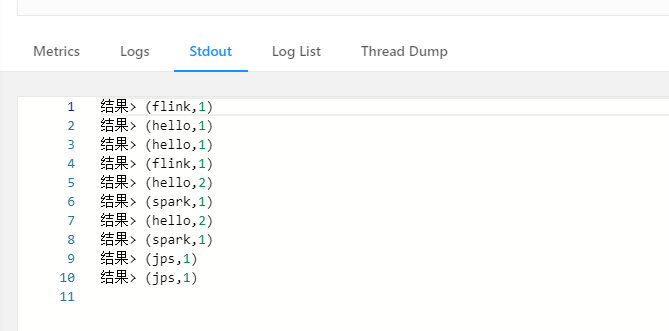
执行结果(下面结果重复显示了一次,因为我手残多一点了一次提交job,可忽略):
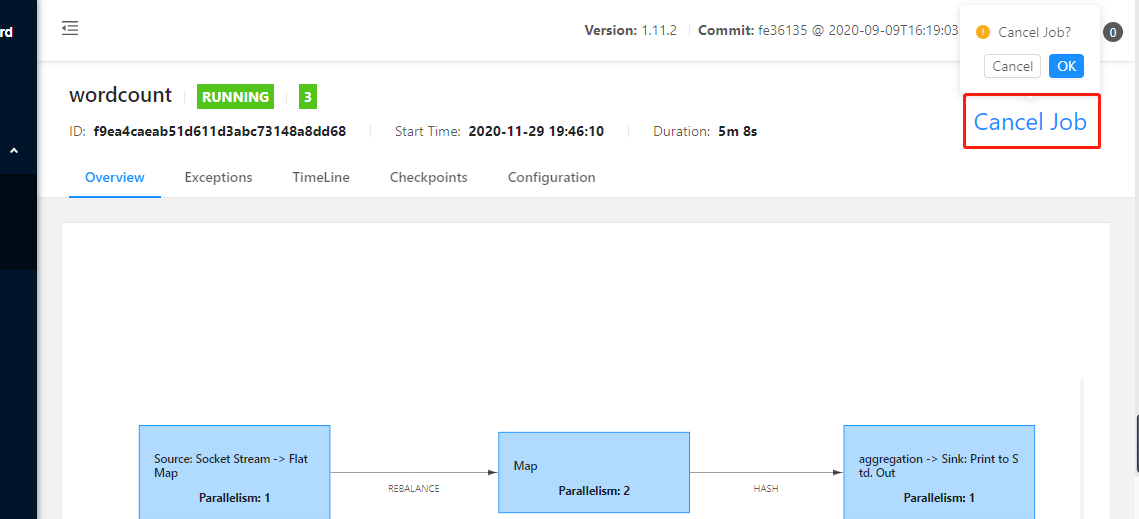
结束本次job:
通过webUI恢复本次job:
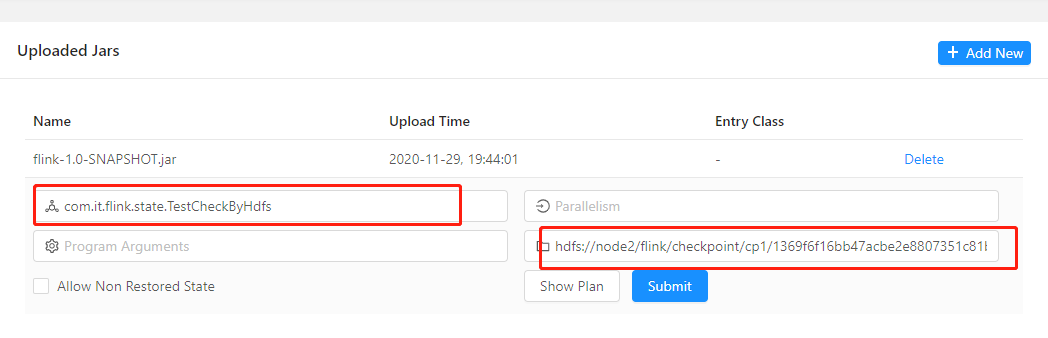
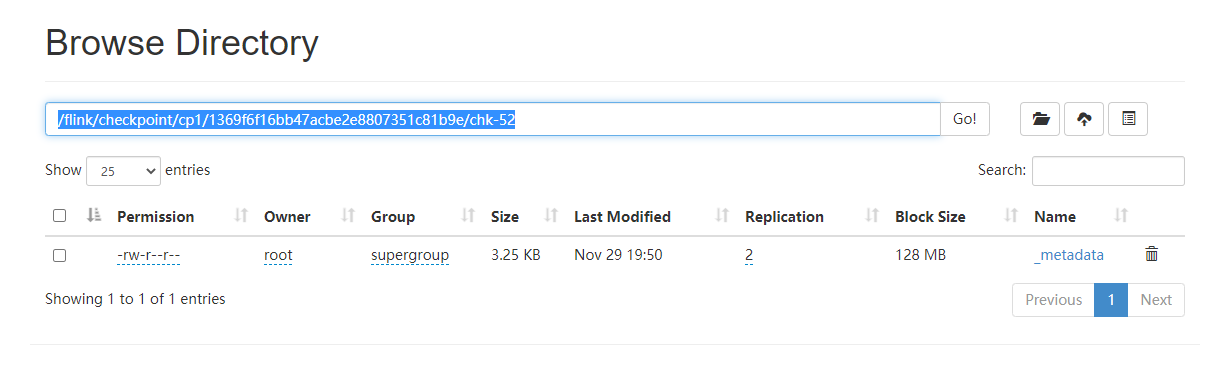
checkpoint目录为代码中指定的输出目录,可通过HDFS查看:
验证结果,在netcat中继续输入:
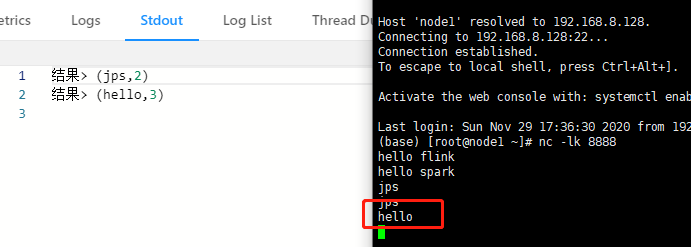
其中jps及hello是我第二次启动job后分别输入了一次,在flink Stdout显示结果表明其已经成功保留了之前输入的状态!
上一节:Flink中State管理与恢复之CheckPoint原理及三种checkpoint使用方式对比
下一节:

