



CheckPoint
当程序出现问题需要恢复 Sate 数据的时候,只有程序提供支持才可以实现 State 的容错。State 的容错需要依靠 CheckPoint 机制,这样才可以保证 Exactly-once 这种语义,但是注意,它只能保证 Flink 系统内的 Exactly-once,比如 Flink 内置支持的算子。针对 Source和 Sink 组件,如果想要保证 Exactly-once 的话,则这些组件本身应支持这种语义。
1) CheckPoint 原理
Flink 中基于异步轻量级的分布式快照技术提供了 Checkpoints 容错机制,分布式快照可以将同一时间点 Task/Operator 的状态数据全局统一快照处理,包括前面提到的 KeyedState 和 Operator State。Flink 会在输入的数据集上间隔性地生成 checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数据划分到相应的 checkpoint 中。每个算子都会进行checkpoint 操作。如下图:

从检查点(CheckPoint)恢复如下图:
假如我们设置了三分钟进行一次CheckPoint,保存了上述所说的 chk-100 的CheckPoint状态后,过了十秒钟,offset已经消费到 (0,1100),pv统计结果变成了(app1,50080)(app2,10020),但是突然任务挂了,怎么办?
莫慌,其实很简单,flink只需要从最近一次成功的CheckPoint保存的offset(0,1000)处接着消费即可,当然pv值也要按照状态里的pv值(app1,50000)(app2,10000)进行累加,不能从(app1,50080)(app2,10020)处进行累加,因为 partition 0 offset消费到 1000时,pv统计结果为(app1,50000)(app2,10000)当然如果你想从offset (0,1100)pv(app1,50080)(app2,10020)这个状态恢复,也是做不到的,因为那个时刻程序突然挂了,这个状态根本没有保存下来。我们能做的最高效方式就是从最近一次成功的CheckPoint处恢复,也就是我一直所说的chk-100;
2) CheckPoint 参数和设置
默认情况下 Flink 不开启检查点的,用户需要在程序中通过调用方法配置和开启检查点,另外还可以调整其他相关参数:
- Checkpoint 开启和时间间隔指定:
开启检查点并且指定检查点时间间隔为 1000ms,根据实际情况自行选择,如果状态比较大,则建议适当增加该值。
streamEnv.enableCheckpointing(1000);
- exactly-ance 和 at-least-once 语义选择:
选择 exactly-once 语义保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复,与此同时,Flink 的性能也相对较弱,而at-least-once 语义更适合于时廷和吞吐量要求非常高但对数据的一致性要求不高的场景。
如 下 通 过 setCheckpointingMode() 方 法 来 设 定 语 义 模 式 , 默 认 情 况 下 使 用 的 是exactly-once 模式。
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//或者 streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
- Checkpoint 超时时间:
超时时间指定了每次 Checkpoint 执行过程中的上限时间范围,一旦 Checkpoint 执行时间超过该阈值,Flink 将会中断 Checkpoint 过程,并按照超时处理。该指标可以通过setCheckpointTimeout 方法设定,默认为 10 分钟。
streamEnv.getCheckpointConfig.setCheckpointTimeout(50000)
- 检查点之间最小时间间隔:
该参数主要目的是设定两个 Checkpoint 之间的最小时间间隔,防止出现例如状态数据过大而导致 Checkpoint 执行时间过长,从而导致 Checkpoint 积压过多,最终 Flink 应用密集地触发 Checkpoint 操作,会占用了大量计算资源而影响到整个应用的性能。
streamEnv.getCheckpointConfig.setMinPauseBetweenCheckpoints(600)
- 最大并行执行的检查点数量:
通过 setMaxConcurrentCheckpoints()方法设定能够最大同时执行的 Checkpoint 数量。在默认 情况下只 有一个检查 点可以运行 ,根据用 户指定的数 量可以同时 触发多个Checkpoint,进而提升 Checkpoint 整体的效率。
streamEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
- 是否删除 Checkpoint 中保存的数据:
设置为 RETAIN_ON_CANCELLATION:表示一旦 Flink 处理程序被 cancel 后,会保留CheckPoint 数据,以便根据实际需要恢复到指定的 CheckPoint。
设置为 DELETE_ON_CANCELLATION:表示一旦 Flink 处理程序被 cancel 后,会删除CheckPoint 数据,只有 Job 执行失败的时候才会保存 CheckPoint
//删除 streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION) //保留64 streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
- TolerableCheckpointFailureNumber:
设置可以容忍的检查的失败数,超过这个数量则系统自动关闭和停止任务。
streamEnv.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
保存机制 StateBackend(状态后端)
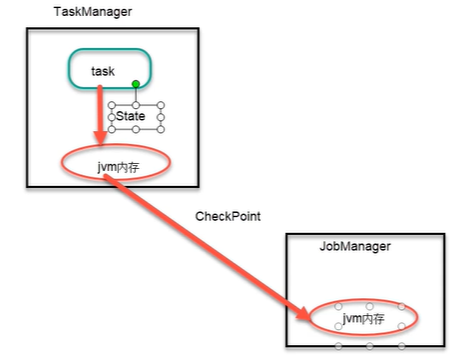
默认情况下,State 会保存在 TaskManager 的内存中,CheckPoint 会存储在 JobManager的内存中。State 和 CheckPoint 的存储位置取决于 StateBackend 的配置。Flink 一共提供了 3 种 StateBackend 。 包 括 基 于 内 存 的 MemoryStateBackend 、 基 于 文 件 系 统 的FsStateBackend,以及基于 RockDB 作为存储介质的 RocksDBState-Backend。
1) MemoryStateBackend
基于内存的状态管理具有非常快速和高效的特点,但也具有非常多的限制,最主要的就是内存的容量限制,一旦存储的状态数据过多就会导致系统内存溢出等问题,从而影响整个应用的正常运行。同时如果机器出现问题,整个主机内存中的状态数据都会丢失,进而无法恢复任务中的状态数据。因此从数据安全的角度建议用户尽可能地避免在生产环境中使用MemoryStateBackend。
streamEnv.setStateBackend(new MemoryStateBackend(10*1024*1024))
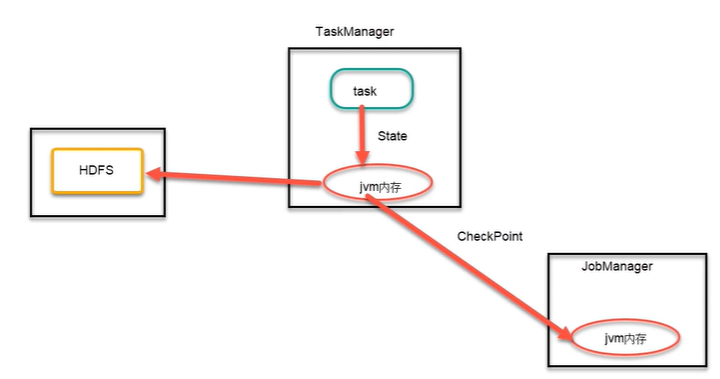
2) FsStateBackend
和 MemoryStateBackend 有所不同,FsStateBackend 是基于文件系统的一种状态管理器,这里的文件系统可以是本地文件系统,也可以是 HDFS 分布式文件系统。FsStateBackend 更适合任务状态非常大的情况,可以使checkpoint数据大量存储于HDFS或本地文件,例如应用中含有时间范围非常长的窗口计算,或 Key/valueState 状态数据量非常大的场景。
缺点:跟MemoryStateBackend一样,内存中保存的状态数据不宜过大
streamEnv.setStateBackend(new FsStateBackend("hdfs://mycluster/checkpoint/cp1"))
3) RocksDBStateBackend
RocksDBStateBackend 是 Flink 中内置的第三方状态管理器,和前面的状态管理器不同,RocksDBStateBackend 需要单独引入相关的依赖包到工程中。
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-statebackend-rocksdb_2.12</artifactId> <version>1.11.2</version> </dependency>
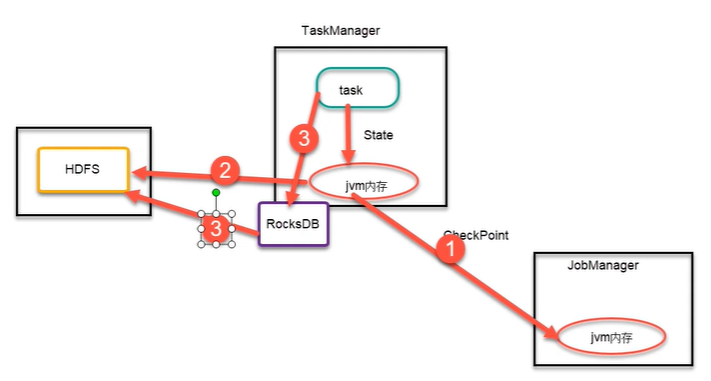
RocksDBStateBackend 采用异步的方式进行状态数据的 Snapshot,任务中的状态数据首先被写入本地 RockDB 中,这样在 RockDB 仅会存储正在进行计算的热数据,而需要进行CheckPoint 的时候,会把本地的数据直接复制到远端的 FileSystem 中。RocksDB 同时在内存及磁盘中存储数据
与 FsStateBackend 相比,RocksDBStateBackend 在性能上要比 FsStateBackend 高一些,65主要是因为借助于 RocksDB 在本地存储了最新热数据,然后通过异步的方式再同步到文件系统中,但 RocksDBStateBackend 和 MemoryStateBackend 相比性能就会较弱一些。RocksDB克服了 State 受内存限制的缺点,同时又能够持久化到远端文件系统中,推荐在生产中使用。
streamEnv.setStateBackend(new RocksDBStateBackend("hdfs://mycluster/checkpoint/cp2"))
4) 全局配置 StateBackend
以 上 的 代 码 都 是 单 job 配 置 状 态 后 端 , 也 可 以 全 局 配 置 状 态 后 端 , 需 要 修 改flink-conf.yaml 配置文件:
state.backend: filesystem
其中:
filesystem 表示使用 FsStateBackend,
jobmanager 表示使用 MemoryStateBackend
rocksdb 表示使用 RocksDBStateBackend。
state.checkpoints.dir: hdfs://hadoop101:9000/checkpoints
默认情况下,如果设置了 CheckPoint 选项,则 Flink 只保留最近成功生成的 1 个CheckPoint,而当 Flink 程序失败时,可以通过最近的 CheckPoint 来进行恢复。但是,如果希望保留多个 CheckPoint,并能够根据实际需要选择其中一个进行恢复,就会更加灵活。
添加如下配置,指定最多可以保存的 CheckPoint 的个数。
state.checkpoints.num-retained: 2

