
Flink 是一个默认就有状态的分析引擎,前面的 WordCount 案例可以做到单词的数量的累加,其实是因为在内存中保证了每个单词的出现的次数,这些数据其实就是状态数据。但是如果一个 Task 在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义(At -least-once 和 Exactly-once)上来说,Flink引入了 State 和 CheckPoint。
- State 一般指一个具体的 Task/Operator 的状态,State 数据默认保存在 Java 的堆内存58中。
- CheckPoint(可以理解为 CheckPoint 是把 State 数据持久化存储了)则表示了一个Flink Job 在一个特定时刻的一份全局状态快照,即包含了所有 Task/Operator 的状态。
1. 常用 State
Flink 有两种常见的 State 类型,分别是:
- keyed State(键控状态)
- Operator State(算子状态)
1) Keyed State(键控状态)
Keyed State:顾名思义就是基于 KeyedStream 上的状态,这个状态是跟特定的 Key 绑定的。KeyedStream 流上的每一个 Key,都对应一个 State。Flink 针对 Keyed State 提供了以下可以保存 State 的数据结构:
- ValueState<T>: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过update(T) 进行更新,通过 T value() 进行检索。
- ListState<T>: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T) 或者 addAll(List<T>) 进行添加元素,通过 Iterable<T>get() 获得整个列表。还可以通过 update(List<T>) 覆盖当前的列表。
- ReducingState<T>: 保 存 一 个 单 值 , 表示 添 加 到 状 态 的 所 有 值 的 聚 合 。 接口 与ListState 类似,但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。
- AggregatingState<IN, OUT>: 保留一个单值,表示添加到状态的所有值的聚合。和ReducingState 相反的是, 聚合类型可能与 添加到状态的元素的类型不同。 接口与ListState 类似,但使用 add(IN) 添加的元素会用指定的 AggregateFunction 进行聚合。
- FoldingState<T, ACC>: 保留一个单值,表示添加到状态的所有值的聚合。 与ReducingState 相反,聚合类型可能与添加到状态的元素类型不同。接口与 ListState类似,但使用 add(T)添加的元素会用指定的 FoldFunction 折叠成聚合值。
- MapState<UK, UV>: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用 put(UK,UV) 或者 putAll(Map<UK,UV>) 添加映射。使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图。
2) Operator State(算子状态)
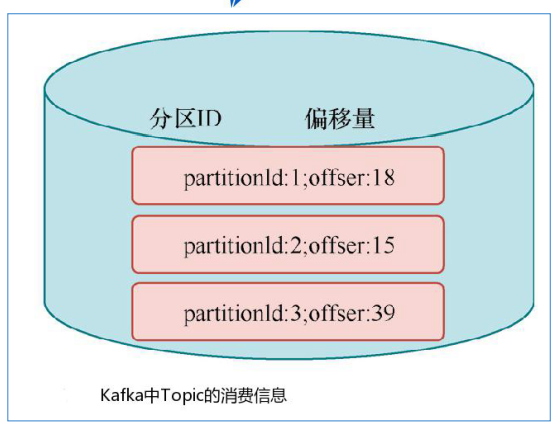
Operator State 与 Key 无关,而是与 Operator 绑定,整个 Operator 只对应一个 State。比如:Flink 中的 Kafka Connector 就使用了 Operator State,它会在每个 Connector 实例中,保存该实例消费 Topic 的所有(partition, offset)映射。
3) Keyed State 案例
原始数据:
station_4,18600003294,18900004149,busy,1606550754162,0 station_6,18600007904,18900004783,success,1606550754162,20 station_8,18600000183,18900000865,success,1606550754162,10 station_0,18600005712,18900000678,failed,1606550754162,0 station_6,18600002230,18900000053,busy,1606550754163,0 station_0,18600008917,18900008108,barring,1606550754163,0 station_0,18600002944,18900008155,busy,1606550754163,0 station_4,18600004526,18900006991,barring,1606550754163,0 station_5,18600003263,18900006649,barring,1606550754163,0 station_5,18600003263,18900006649,barring,1606550884163,0 station_9,18600007853,18900004122,success,1606550754163,60 station_9,18600007855,18900004122,success,1606550764163,60
import com.it.flink.source.StationLog import org.apache.flink.api.common.functions.{FlatMapFunction, RichFlatMapFunction} import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.api.scala.createTypeInformation import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.util.Collector object TestKeyedState { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) val path: String = getClass.getResource("/station.log").getPath() val stream: DataStream[StationLog] = env.readTextFile(path) .map(line => { val arr: Array[String] = line.split(",") StationLog(arr(0), arr(1), arr(2), arr(3), arr(4).toLong, arr(5).toLong) }) val result: DataStream[(String, Long)] = stream .keyBy(_.callIn) .flatMap(new CallIntervalFunction()) result.print("时间间隔为:") env.execute() } } /** * 统计每个手机的呼叫间隔时间,并输出 * 富函数 */ class CallIntervalFunction() extends RichFlatMapFunction[StationLog, (String, Long)] { //定义一个保存前一条呼叫的数据的状态对象,preData.value()即为前一条状态的值 private var preData: ValueState[StationLog] = _ override def open(parameters: Configuration): Unit = { preData = getRuntimeContext.getState( new ValueStateDescriptor[StationLog]("pre", classOf[StationLog])) } override def flatMap(in: StationLog, collector: Collector[(String, Long)]): Unit = { var pre: StationLog = preData.value() if (pre == 0 || pre == null) { preData.update(in) } else { val interval = pre.callTime collector.collect(in.callIn, in.callTime - interval) } } }
结果展示:
时间间隔为:> (18900006649,130000)
时间间隔为:> (18900004122,10000)
还有第二种简单的方法:调用 flatMapWithState或者mapWithState算子
val result: DataStream[(String, Long)] = stream .keyBy(_.callIn) .mapWithState[(String, Long), StationLog] { case (in: StationLog, None) => ((in.callIn, 0), Some(in)) case (in: StationLog, pre: Some[StationLog]) => { var interval = in.callTime - pre.value.callTime ((in.callIn, interval), Some(in)) } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号