MySQL - 索引(INDEX)
一、about
索引,在MySQL中也被称为"键(key)",是存储引擎提高查询性能的一种数据结构,它的主要作用:
- 约束
- 提供类似书籍的目录,可以优化查询
MySQL支持的索引的类型(算法):
- B树索引
- hash索引
- R树,空间数据索引
- full text,全文索引
- 其他索引类型
索引情况比较复杂,这里仅以MySQL5.7版本和innodb引擎展开,且环境是基于centos7.9的。
二、B树?B+树?
说到innodb表的索引,就离不开B树,也离不开B+树,我们就先来研究下innodb存储引擎到底是怎么组织数据的,了解了这些我们才好更好的学习索引。
是的,MySQL的innodb存储引擎基于B树来组织的数据,但是为了提升范围查询性能,它更像一棵B+树,但同时又是一棵很特别的B+树。
下图是一个B树:
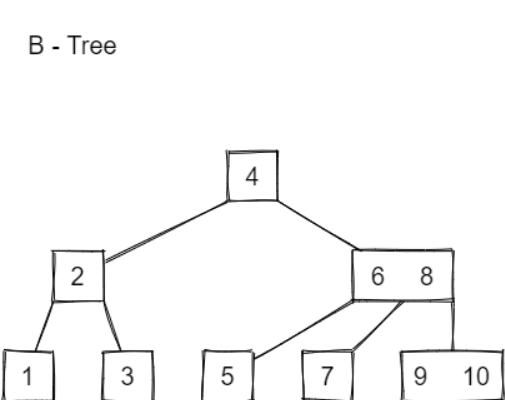
下图是一棵B+树:
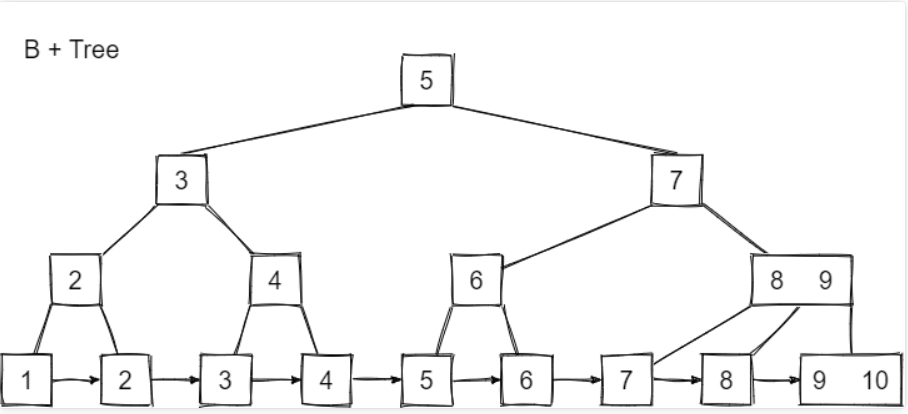
而MySQL的B+树长这样:
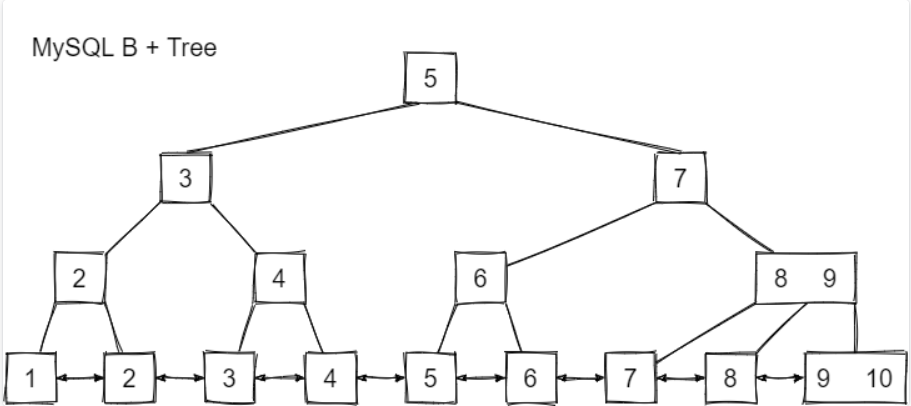
是的,相对于B+树来说,MySQL的B+树的叶子节点存储了完整的记录,且存储了左右节点的指针,方便范围查找。
页和局部性原理
局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
例如我要访问磁盘中a b c d中a,那么CPU经过一次io读取a到内存中,紧接着又要访问b,那CPU再经过一次io读取b到内存中,如果在需要读取c和d就又要两次io操作才能完成。
这是低效的操作,通常Linux以页为逻辑单位来组织数据,对于32位的系统每页通常是4kb;64位系统则是8kb,而CPU在读取数据时也是以页为单位来处理,比如读取a那么它会一次性将a b c d所在整页数据读取到内存中,后续再有读取b、c、d的,就直接在内存中进行读取,减少io操作。
这种思想也应用到了软件中,MySQL中的innodb引擎也是以页为逻辑单位组织数据,只不过默认每页的大小是16kb,可以通过下面参数查看:
mysql> select @@innodb_page_size,@@innodb_page_size/1024 as kb; +--------------------+---------+ | @@innodb_page_size | kb | +--------------------+---------+ | 16384 | 16.0000 | +--------------------+---------+ 1 row in set (0.00 sec)
B树索引的适用范围
B树索引适用于全键值、键值范围或者键前缀查找,其中键前缀查找只使用与根据最左前缀的查找。
- 全值匹配,全值匹配值得是和索引中的所有列进行匹配:
-- 有组合索引 idx(name,age,phone) select * from tb where name="zhangkai" and age=23 and phone="15592925142";
- 匹配最左前缀,只匹配前面的几列:
-- 有组合索引 idx(name,age,phone) select * from tb where name="zhangkai" and age=23; select * from tb where name="zhangkai" and age=23 and phone="15592925142";
- 匹配列前缀,匹配指定列值得开头部分:
select * from tb where name like "zhang%"; select * from tb where name like "%kai";
- 匹配范围值,可以查找某个范围的数据:
select * from tb where age > 18;
- 精确匹配某一列并范围匹配另一列,全值匹配第一列,范围匹配第二列:
select * from tb where name="zhangkai" and age > 25;
- 只访问索引的查询,查询的指定字段是索引列,而不是所有字段,本质上就是索引覆盖:
select name from tb where name="zhangkai";
三、索引管理
为了更好的研究索引,这里先学习索引的相关命令。
MySQL提供了三种创建索引的方法。
3.1 使用 CREATE INDEX 语句创建索引
该语句在一个已有的表上创建索引,但是不能创建主键:
-- 基本语法 CREATE INDEX <索引名> ON <表名> (<列名> [<长度>] [ ASC | DESC]) -- 示例,为 userinfo 表的 name 字段创建一个名为 id_name 的普通索引,默认为 ASC CREATE INDEX id_name ON userinfo(name);
语法说明如下:
<索引名>:指定索引名。一个表可以创建多个索引,但每个索引在该表中的名称是唯一的。<表名>:指定要创建索引的表名。<列名>:指定要创建索引的列名。通常可以考虑将查询语句中在 JOIN 子句和 WHERE 子句里经常出现的列作为索引列。<长度>:可选项。指定使用列前的 length 个字符来创建索引。使用列的一部分创建索引有利于减小索引文件的大小,节省索引列所占的空间。在某些情况下,只能对列的前缀进行索引。索引列的长度有一个最大上限 255 个字节(MyISAM 和 InnoDB 表的最大上限为 1000 字节),如果索引列的长度超过了这个上限,就只能用列的前缀进行索引。另外,BLOB 或 TEXT 类型的列也必须使用前缀索引。ASC|DESC:可选项。ASC指定索引按照升序来排列,DESC指定索引按照降序来排列,默认为ASC。
3.2 使用 CREATE TABLE 语句创建索引
create table tt( id int, name char(20), index index_name(name),--方法一 key(name) -- 方法二 );
3.3 使用 ALTER TABLE 语句创建索引
-- 创建单列辅助索引 ALTER TABLE 表名 ADD INDEX 索引名称(字段); -- ALTER TABLE 表名 ADD KEY 索引名称(字段); -- MySQL中,index 就是 key,所以也可以ADD KEY -- 创建联合索引 ALTER TABLE 表名 ADD INDEX 索引名称(字段1,字段2); -- 创建唯一索引 ALTER TABLE 表名 ADD UNIQUE [ INDEX | KEY] [<索引名>] [<索引类型>] (<列名>,…) -- 创建前缀索引,只取指定字段的前几个字符来创建索引 ALTER TABLE 表名 ADD INDEX 索引名称(字段(length)); -- 关联外键,不过用的不多,因为外键关系,建表时也都关联好了 ALTER TABLE 表名 ADD FOREIGN KEY [<索引名>] (<列名>,…)
注意:在一张表中,索引名称是唯一的;但是一个字段上可以建立多个索引(但生产中基本不用);也没必要在多个列上建立多个索引;一般的,我们在建表时,基本上都会设置主键和设置唯一约束。所以,以上的命令都是在创建辅助索引;主键索引都在建表时同时指定了
3.4 查看和删除索引
至于修改命令,就直接使用ALTER或者DROP语句来修改即可,再来看其他命令:
-- 删除索引 ALTER TABLE 表名 DROP INDEX 索引名称; DROP INDEX 索引名称 ON 表名; -- 查看索引 DESC 表名; SHOW INDEX FROM 表名; -- 输出相对详细信息
另外,如果使用DESC命令查看表的索引信息,在Key栏,有三种索引:
- PRI:主键
- UNI:唯一键索引
- MUL:辅助索引
四 、聚簇索引
准备数据:
create table userinfo( id int not null primary key, name varchar(32) default "zhangkai", age tinyint default 18, phone varchar(32) default "13202512591", addr varchar(128) default "北京", email varchar(128) default "", birth date )engine=innodb charset=utf8; insert into userinfo(id,name,age,phone,addr,email,birth) values (1, '王秀华', 67, '13202512591', '甘肃省莹县朝阳许街C座 934491', 'pinglai@caotan.cn', '2002-04-15'), (2, '党敏', 74, '13139383427', '上海市福州市友好合肥街F座 562347', 'yang59@shen.cn', '1977-02-13'), (3, '陈桂花', 81, '15670720985', '吉林省莹县吉区乌鲁木齐路s座 424624', 'jingqiao@guiyingzhu.cn', '1986-01-31'), (4, '徐娟', 68, '14530781109', '北京市秀华县孝南长沙街L座 180057', 'hdong@yahoo.com', '1982-05-16'), (5, '陈强', 13, '13861616932', '安徽省北京市山亭潮州街M座 397960', 'nading@gmail.com', '1984-02-28'), (6, '刘淑英', 75, '13833925643', '台湾省沈阳县梁平太原街v座 494700', 'yili@tianyao.cn', '2002-03-21'), (7, '卢建华', 89, '15893082836', '浙江省南京市闵行台北路j座 822249', 'guiyingshi@jundeng.cn', '2003-05-03'), (8, '马楠', 31, '18948071089', '北京市哈尔滨县南长佛山路a座 574046', 'yang97@gmail.com', '1996-08-11'), (9, '曾宇', 6, '18565097633', '天津市利县江北香港路O座 863353', 'cyu@yahoo.com', '1983-05-24'), (10, '吴飞', 9, '13109375333', '青海省俊市梁平高街z座 868705', 'pmo@haozhao.cn', '2017-06-09');
聚簇
聚簇是一种术语,表示数据行和相邻的键值紧凑的存储在一起。因为无法同时把数据行存放在不同的地方,所以一个表只能由一个聚簇索引。
聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式,也是一类索引的统称。
说白了,一张InnoDB表的数据都被组织在聚簇索引这棵特殊B+树上。那到底是如何组织的呢?在创建一张InnoDB的表时,如果没有指定主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式的创建一个6字节的主键来作为聚簇索引,然后后续插入的数据都被组织在这棵聚簇索引树上。
问题来了,主键索引一定是聚簇索引么?思考一下,假如创建表的时候,没有设置主键索引和唯一索引,而在添加数据之后,设置了主键,那么原隐式创建的聚簇索引会和新创建的主键索引合并么?答案是会的。因为一个表只能有一个聚簇索引树,而这棵树的叶子节点存储了全部的记录,没有必要再重新为主键索引再创建一份数据,所以,它会合并。
这也就意味着,聚簇索引可以是主键索引、唯一索引的统称。当一张表设置了主键或者唯一键,那么InnoDB就会以以主键索引或者唯一索引的方式组织数据。
下图是一个以id为主键的表的存储结构
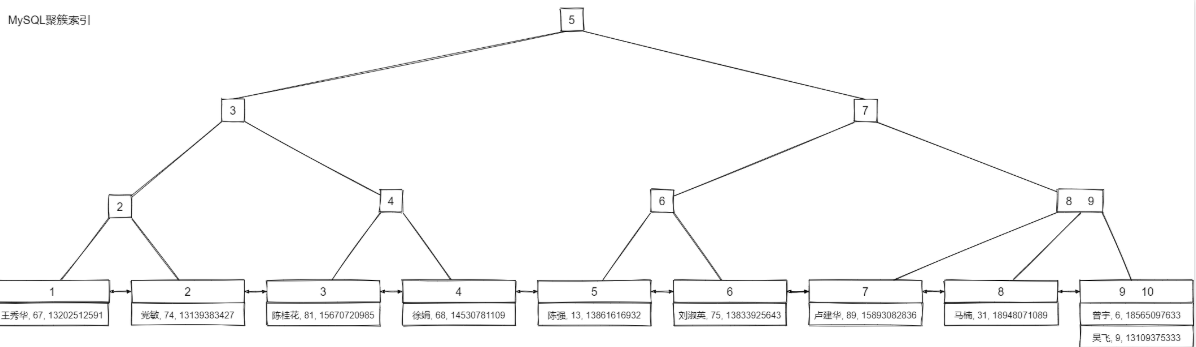
聚簇索引树的叶子节点页包含了全部的数据,而节点页只包含了索引列。
另外,聚簇索引树在组织数据时,会按照一定的顺序对数据进行排序,比如按照主键进行升序排序。
由于数据的聚集性,聚簇索引也叫做聚集索引。
这里一直强调,基于InnoDB的表,一个张表只能有一个聚簇索引,所以,索引可以简单粗暴的分为聚簇索引和非聚簇索引
非聚簇索引也叫做辅助索引、二级索引等等,又根据索引的不同特点,也有了更多的称呼,比如具有唯一约束的唯一索引;具有非空且唯一特点的主键索引,多个字段组合而成的索引——联合索引,当联合索引又具有唯一性时,这个联合索引又可以被称为联合唯一索引;为单个字段创建的索引叫做单列索引,它的作用只用来加速查询时,所以它又被称为普通的单列辅助索引;针对索引列数据较长的字段,通常截取前若干字段建立的索引叫做前缀索引........
聚簇索引和辅助索引构成区别
- 聚簇索引只能有一个(主键),非空且唯一
- 辅助索引可以有多个,主要配合聚集索引使用的
- 聚簇索引的叶子节点,就是磁盘数据行存储的数据页
- MySQL是根据聚簇索引来组织数据,即数据存储时,就是按照聚簇索引的顺序进行存储数据
- 辅助索引只会提取索引键值,进行自动排序生成B树
由于聚簇索引的特点,通常在创建表的时候,设置id字段为聚簇索引,当然,这里一般称为主键索引,它具有非空且唯一、自增的特性。这里不在展开演示其具体创建过程了。
五、前缀索引
准备数据:
import re import faker import random import pymysql from pymysql.connections import CLIENT conn = pymysql.Connect( host='10.0.0.200', user='root', password='123', database='my_idb', charset='utf8', client_flag=CLIENT.MULTI_STATEMENTS) cursor = conn.cursor() fk = faker.Faker(locale='en_US') def create_table(): """ 创建表 """ sql = """ DROP TABLE IF EXISTS prefix_tb; CREATE TABLE prefix_tb ( id int(11) NOT NULL AUTO_INCREMENT, text varchar(255) DEFAULT NULL, email varchar(64) DEFAULT NULL, suffix_email varchar(64) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; """ # 注意,一次性执行多行sql,必须在连接时,指定client_flag=CLIENT.MULTI_STATEMENTS cursor.execute(sql) conn.commit() def gen(num, tmp_list): for i in range(num): tmp = fk.paragraph() if random.randint(0, 1) else tmp_list[random.randint(0, (tmp_list.__len__() - 1))] email = fk.email() yield tmp, email, ''.join(reversed(re.split('(@)', email))) def insert_many(num): """ 批量插入 """ tmp_list = [fk.paragraph() for i in range(100)] sql = "insert into prefix_tb(text, email, suffix_email) values(%s, %s, %s);" cursor.executemany(sql, gen(num, tmp_list)) conn.commit() if __name__ == '__main__': num = 10000 create_table() insert_many(num) # 数据长这样 """ mysql> select * from prefix_tb limit 2\G *************************** 1. row *************************** id: 1 text: Practice cost maintain drive walk. Chance treat should conference officer audience. Similar event agree away. email: bmata@davis-harris.info suffix_email: davis-harris.info@bmata *************************** 2. row *************************** id: 2 text: Child across those. Admit especially try I. email: jeffrey64@rodriguez.biz suffix_email: rodriguez.biz@jeffrey64 2 rows in set (0.00 sec) """
要对一个字符列很长的字段,建立索引,通常会让索引变得大而且慢,而解决办法可以仅对字符的开始部分建立索引,这样节省了索引空间,也提高了索引效率,对于这类索引,通常称为——前缀索引。
不重复的索引值(也称为基数,cardinality)和数据表的记录总数(#T)的比值,范围从1/#T到1之间。说白了就是一个表中,不重复的记录和总记录的比值
索引的选择性越高则查询效率越高,因为选择性高的索引可以让给MySQL在查询时过滤掉更多的行,就像唯一索引的选择性是1,这是最好的选择性,性能也是最好的。
对于BLOB、TEXT或者很长的VARCHAR类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。
诀窍在于要选择足够长的前缀以保证较高的选择性,同时不能太长(以便节约空间)。前缀索引的长度处于什么范围?才能让前缀索引的选择性接近整个列,换句话说,前缀的"基数"应该接近于完整的"基数"。
为了解决前缀的合适长度,我们一般通过简单的公式来测试,最终筛选出前缀的选择性接近完整列的选择性。
SELECT COUNT(DISTINCT text) / count(*) as "最优选择性" from prefix_tb;
有了公式,我们就可以来计算尝试计算出一个合适的索引长度:
SELECT COUNT(DISTINCT text) / count(*) as "最优选择性", COUNT(DISTINCT left(text,10)) / count(*) as len10, COUNT(DISTINCT left(text,12)) / count(*) as len12, COUNT(DISTINCT left(text,14)) / count(*) as len14, COUNT(DISTINCT left(text,16)) / count(*) as len16, COUNT(DISTINCT left(text,18)) / count(*) as len18, COUNT(DISTINCT left(text,20)) / count(*) as len20, COUNT(DISTINCT left(text,22)) / count(*) as len22, COUNT(DISTINCT left(text,24)) / count(*) as len24, COUNT(DISTINCT left(text,26)) / count(*) as len26 from prefix_tb; -- 结果如下 +-----------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+ | 最优选择性 | len10 | len12 | len14 | len16 | len18 | len20 | len22 | len24 | len26 | +-----------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+ | 0.5116 | 0.4667 | 0.5013 | 0.5098 | 0.5114 | 0.5114 | 0.5116 | 0.5116 | 0.5116 | 0.5116 | +-----------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+
由上例结果发现,当前缀长度为20时,最接近(这里刚好是等于)最优的选择性,而再增加长度时,值已经不在变化,所以,前缀的长度为20时,比较合适。
算出了合适的前缀长度,我们来创建前缀索引
-- 为text列创建一个名为pre_idx的前缀索引,前缀长度为20 alter table prefix_tb add index pre_idx(text(20)); -- 查看 show index FROM prefix_tb;
来看应用
mysql> explain select * from prefix_tb where text like "you%"; +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ | 1 | SIMPLE | prefix_tb | NULL | range | pre_idx | pre_idx | 63 | NULL | 19 | 100.00 | Using where | +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
前缀索引是一种能使索引更小、更快的有效办法,但前缀索引也有自己的缺点
- MySQL无法使用前缀索引进行order by和group by,因为前缀索引的数据结构是按照前缀排序的,和完整的字段排序不一样。
- 无法使用前缀索引做覆盖扫描,如下图,前缀索引的叶子节点存储的并不是完整的列值,所以当查询时,还是需要回表。

后缀索引?
有时候,后缀索引(suffix index),或者说是反向索引也很用,例如找到某个域名的所有email。而MySQL原生并不支持后缀索引(suffix index),但可以通过字符串"反转"的方式,如将ryanlove@yahoo.com"反转"为yahoo.com@ryanlove,然后建立前缀索引达到加速查询的目的。
在本小节的prefix_tb表中,suffix_email字段就是为了email字段的"反转"后的值,我们为suffix_email建立前缀索引,进而过滤出想要的记录。
-- 通过为suffix_email字段建立前缀进行结果过滤 alter table prefix_tb add index suffix_idx(suffix_email(28)); -- 下面两个查询语句的性能是不一样的 mysql> explain select count(email) from prefix_tb where email like "%yahoo.com"; +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | prefix_tb | NULL | ALL | NULL | NULL | NULL | NULL | 9968 | 11.11 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select count(email) from prefix_tb where suffix_email like "yahoo.com%"; +----+-------------+-----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | prefix_tb | NULL | range | suffix_idx | suffix_idx | 87 | NULL | 1642 | 100.00 | Using where | +----+-------------+-----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
六、联合索引
MySQL可以创建复合索引(Multiple column indexes),即同时为多个列创建索引,一个复合索引最多可以包含16列。
当然,我们通常更习惯将复合索引叫做联合索引或组合索引,当多个索引列具有唯一性时,你可以称它为联合唯一索引
6.1 最左原则
在联合索引中,需要重点掌握——最左(前缀匹配)原则,所谓最左原则,即当你创建如下联合索引时
create table t1( id int not null primary key auto_increment, a int not null, b int not null, c int not null, d int not null, index mul_idx(a,b,c) )engine=innodb charset=utf8; insert into t1 values (1, 1, 1, 1, 1),(2, 2, 2, 2, 2),(3, 3, 3, 3, 3),(4, 4, 4, 4, 4),(5, 5, 5, 5, 5), (6, 6, 6, 6, 6),(7, 7, 7, 7, 7),(8, 8, 8, 8, 8),(9, 9, 9, 9, 9),(10, 10, 10, 10, 10);
如上创建一个联合索引mul_idx,相当于:
- 创建了
a列索引、ab列索引、ac列索引(这个要是情况而定)。因为这个几个索引都有a开头,也就是向左具有聚集性,所以被称为最左前缀。 - 按道理说,因为
b列、bc列、ba列、ca列、cb列不符合最左原则,所以无法应用联合索引。但事实上,MySQL的优化器会在某些情况下,调整where条件的先后顺序,以尽可能的应用上索引,如ca列where c=1 and a=1,就会被优化器调整为where a=1 and c=1,然后它就符合最左前缀原则,走索引;ba列同理。所以,再次强调,索引情况非常复杂,还是尽可能的通过执行计划的结果,来具体情况具体考虑
由上面的总结来看,我们在创建联合索引时,一定要将最常被查询的列放在联合索引的最左侧。接下来的示例,要关注一个key_len参数
-- 单独将a作为条件,走索引 explain select * from t1 where a=1; +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 4 | const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
- ab作为条件,走索引 explain select * from t1 where a=1 and b=1; +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 8 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+
-- ac作为条件,走索引 explain select * from t1 where a=1 and c=1; +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+--------------------------+ | 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 4 | const | 1 | 10.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+--------------------------+
-- 单独将b作为条件,不走索引 explain select * from t1 where b=1; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- ba作为条件,按照上面的说法,MySQL优化器将 b=1 and a=1 调整为 a=1 and b=1,然后就符合最左原则,走索引了 explain select * from t1 where b=1 and a=1; +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 8 | const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------+ -- bc作为条件,不走索引 explain select * from t1 where b=1 and c=1; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ -- ca作为条件,按理说,不应该走索引,但实际上MySQL优化器会优化查询条件,将 c=1 and a=1 两个条件进行交换顺序为 a=1 and c=1,然后就符合最左原则,走索引了 explain select * from t1 where c=1 and a=1; +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 4 | const | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ -- cb作为条件,不走索引 explain select * from t1 where c=1 and b=1; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
通过上面的示例,我们演示了最左前缀的应用,接下来再看看其他情况。
6.2 索引截断
在联合索引中,where条件遇到大于、小于时,会阻断后续条件的索引的使用,但等于不会,这点是需要我们注意的
-- 通过 key_len(a、b、c的索引长度都为4,加一块等于12) 的结果发现,a、b、c三个索引列都被应用,一切正常,我们往下看 explain select * from t1 where a=1 and b=1 and c=1; +----+-------------+-------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | mul_idx | mul_idx | 12 | const,const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+ -- 通过 key_len 的结果发现,当大于小于在最后的时候,索引没有被阻断 explain select * from t1 where a=1 and b=2 and c>3; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | range | mul_idx | mul_idx | 12 | NULL | 1 | 100.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+ -- 通过 key_len 的结果发现,只有a、b两个索引列被应用,c索引列被阻断 explain select * from t1 where a=1 and b>2 and c=3; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | range | mul_idx | mul_idx | 8 | NULL | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+ -- 通过 key_len 的结果发现,a、b、c三个索引列都没有被应用 explain select * from t1 where a>1 and b=2 and c=3; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | mul_idx | NULL | NULL | NULL | 10 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ -- 通过 key_len 的结果发现,a、b、c三个索引列都没有被应用 explain select * from t1 where a>=1 and b>2 and c=3; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | mul_idx | NULL | NULL | NULL | 10 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
联合索引中的索引列是表的所有列的话,它不一定符合最左匹配原则
按照前面说的最左原则,ab、abc、ac走索引;ba、ca被优化器优化后走索引,但bc、cb不走索引,我们已经通过前面的示例证明了。
但联合索引中的索引列是表的所有列的话,最左原则就不灵了,来看示例:
-- 联合索引的索引列示表的所有列,来看,按照最左原则本不该走的bc、cb的情况,虽然优化器会优化,但bc调整为cb那不一样么..... create table t2(a int not null, b int not null, c int not null, index mul_idx(a,b,c)); -- bc作为索引列,走了索引 explain select * from t2 where b=1 and c=1; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | t2 | NULL | index | NULL | mul_idx | 12 | NULL | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ -- 同理,cb作为索引列,也会走索引 explain select * from t2 where c=1 and b=1; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | t2 | NULL | index | NULL | mul_idx | 12 | NULL | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
七 、覆盖索引
通常大家都会根据查询的where条件来创建合适的索引,不过这只是索引优化的一个方向面。设计优秀的索引应该考虑到整个查询,而不是单单是where条件部分。索引确实是一种查找数据的高效方式,但是MySQL也可以使用索引来直接获取列的数据,这样就不再需要读取数据行。如果索引的叶子节点中已经包含了要查询的数据,那么还有必要再回表查询么?
如果一个索引包含或者说覆盖所有要查询的字段的值,我们就称之为"覆盖索引(也称索引覆盖)"。覆盖索引极大的提高了查询性能,且索引条目远小于完整记录行的大小,所以如果只需要读取索引,MySQL就会极大的减少数据访问量。
当发起一个被索引覆盖的查询(也叫做索引覆盖查询)时,再explain的extra字段,会看到"Using index"的信息
-- 首先创建一个联合索引 alter table userinfo add index com_idx(name,phone); explain select name,phone from userinfo where name="王秀华"\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: userinfo partitions: NULL type: ref possible_keys: com_idx key: com_idx key_len: 99 ref: const rows: 1 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.00 sec)
这也是我们在刚开始学习MySQL时,会提到尽量不要使用select *而是建议使用select id等指定字段,这就是希望能走覆盖索引,进一步提高查询语句的性能。
比如同样的where条件,select *就不会走索引覆盖:
explain select * from userinfo where name="王秀华"\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: userinfo partitions: NULL type: ref possible_keys: com_idx key: com_idx key_len: 99 ref: const rows: 1 filtered: 100.00 Extra: NULL 1 row in set, 1 warning (0.00 sec)
八、回表查询
索引的叶子节点中已经包含了要查询的数据,就会走覆盖索引,否则就需要进行回表查询了。
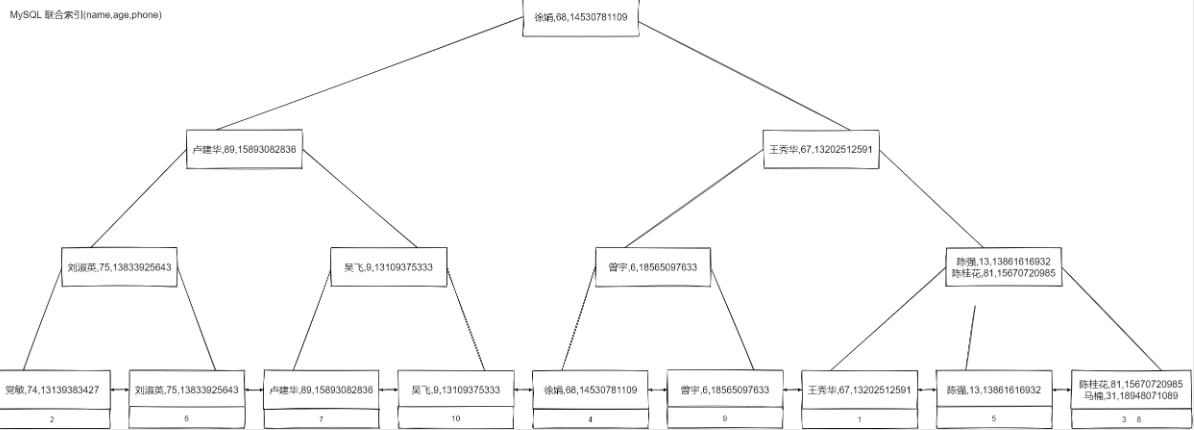
根据上图,如果一个表,只有主键索引和联合索引时。查询字段是索引字段时,就会走覆盖索引,因为索引的叶子节点中已经包含了要查询的数据,如下示例:
explain select name,phone from userinfo where name="王秀华"\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: userinfo partitions: NULL type: ref possible_keys: com_idx key: com_idx key_len: 99 ref: const rows: 1 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.00 sec)
而下面的查询则需要回表查询,因为索引的叶子节点不包含addr字段的值,需要通过主键id进行回表查询。
explain select name,phone,addr from userinfo where name="王秀华"\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: userinfo partitions: NULL type: ref possible_keys: com_idx key: com_idx key_len: 99 ref: const rows: 1 filtered: 100.00 Extra: NULL 1 row in set, 1 warning (0.00 sec)
九、索引下推
MySQL5.6版本开始,新增"索引下推(IPC)"功能来优化查询。索引下推也被称为索引条件下推、索引条件推送(Index condition pushdown),SQL下推、谓词下推。
当EXPLAIN的输出在Extra列中显示Using index condition时,表示使用了索引下推。
如我们对idb_tb表进行查询
-- 首先这里会用到联合索引 alter table userinfo add index com_idx(name,addr,phone); -- 查询条件如下 explain select * from userinfo where name="王秀华" and phone like "155%";
mysql> explain select * from user where name="王秀华" and phone like "155%"; +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | user | NULL | ref | com_idx | com_idx | 98 | const | 589 | 11.11 | Using index condition | +----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec)
在使用索引下推之前,也就是MySQL5.6版本之前,上面的SQL语句执行:
- MySQL会先使用联合索引查询出所有
name="王秀华"的索引,然后回表查询出相应的全行数据。 - 然后再根据后面的条件筛选结果。
但在使用索引下推后,上面的SQL语句执行:
- MySQL根据联合索引过滤所有
name="王秀华"索引,再回表查询相应的全行数据之前,先对phone条件进行筛选,再进行回表查询,将最终的结果发返回。
很明显,索引下推会减少回表次数,进而减少总的查询量,达到优化查询的功能
注意:
- 索引下推可应用于innodb和myisam表,且MySQL 5.6中的分区表不支持索引下推,但在 MySQL 5.7中已解决此问题。
- 对于innodb表来说,索引下推仅适用于二级索引。
默认情况下,索引条件下推处于启用状态。可以optimizer_switch通过设置index_condition_pushdown 标志使用系统变量 进行控制
SET optimizer_switch = 'index_condition_pushdown=off'; SET optimizer_switch = 'index_condition_pushdown=on'; -- 查看该参数 SELECT @@optimizer_switch;
十、更好的使用索引
10.1 冗余和重复索引
MySQL允许在相同的列上创建多个索引,但MySQL需要单独维护这些索引,并且优化器在优化查询时,也要逐个的对这些索引进行考虑,这就会一定程度上影响性能和磁盘占用。
重复索引
重复索引指在相同列上按照相同的方式创建的相同类型的索引,对于这样的重复索引,应该及时进行移除。
如下面的示例,在不经意间,就创建了重复索引:
create table tb( id int not null primary key, col1 int not null, col2 int not null, unique(id), index(id) )engine=innodb;
mysql> show index from tb; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | tb | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | | tb | 0 | id | 1 | id | A | 0 | NULL | NULL | | BTREE | | | | tb | 1 | id_2 | 1 | id | A | 0 | NULL | NULL | | BTREE | | | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
在MySQL中,唯一限制和主键限制都是通过索引实现的,上面的写法,相当于在相同的列上创建了三个重复的索引,我们应该避免这种情况出现。
对于相同列,如果多个索引类型不同,则不算是重复索引,比如创建key(col2)和full text(col2)这两种索引类型。
冗余索引
冗余索引和重复索引有些不同,如下:
alter table tb add index com_idx(col1,col2); alter table tb add index idx_1(col1); alter table tb add index idx_2(col2,col1);
如果创建了联合索引com_idx,再创键idx_1,那么idx_1就是冗余索引,因为idx_1相当于com_idx索引的前缀索引。
而idx_2则不是冗余索引,因为col2列不是com_idx的最左前缀列。
解决冗余和重复索引可以有以下几种办法。
- 使用infomation_schema来过滤,下面贴出示例代码(执行起来有问题):
SELECT a.TABLE_SCHEMA AS '数据名', a.TABLE_NAME AS '表名', a.INDEX_NAME AS '索引1', b.INDEX_NAME AS '索引2', a.COLUMN_NAME AS '重复列名' FROM STATISTICS a JOIN STATISTICS b ON a.TABLE_SCHEMA = b.TABLE_SCHEMA AND a.TABLE_NAME = b.TABLE_NAME AND a.SEQ_IN_INDEX = b.SEQ_IN_INDEX AND a.COLUMN_NAME = b.COLUMN_NAME WHERE a.SEQ_IN_INDEX = 1 AND a.INDEX_NAME != b.INDEX_NAME;
-
可以使用Shlomi Noach的common_schema中的一些视图来定位,common_schema是一系列可以安装到服务器上的常用的存储和视图。
-
可以使用Percona Toolkit中的pt_duplicate-key-checker,该工具通过分析表结构来找出冗余和重复的索引。
10.2 查询索引的使用情况
我们可以通过一些参数或者专业工具来查看索引的使用情况。
这里推荐使用Percona Toolkit中的pt-index-usage,该工具可以读取查询日志,并对日志中的每条查询进行explain操作,然后打印出关于索引和查询的报告,这个工具不仅可以找出哪些索引是未使用的,也可以了解查询的执行计划。
但这里不在过多展开介绍。
十一.索引效果压力测试
这里选择mysqlslap,mysqlslap是MySQL5.1.4之后自带的基准(benchmark)测试工具,该工具可以模拟多个客户端同时并发的向服务器发出查询更新,给出了性能测试数据而且提供了多种引擎的性能比较。
准备数据:
-- MYSQL version 5.7.20 DROP DATABASE IF EXISTS pp; CREATE DATABASE pp CHARSET=utf8mb4 collate utf8mb4_bin; USE pp; -- SET AUTOCOMMIT=0; DROP TABLE IF EXISTS pressure; CREATE TABLE pressure( id INT, num INT, k1 CHAR(2), k2 CHAR(4), dt TIMESTAMP ); DELIMITER // CREATE PROCEDURE rand_data(IN num INT) BEGIN DECLARE str CHAR(62) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ0123456789'; DECLARE str2 CHAR(2); DECLARE str4 CHAR(4); DECLARE i INT DEFAULT 0; WHILE i<num DO SET str2=CONCAT(SUBSTRING(str,1+FLOOR(RAND()*61),1),SUBSTRING(str,1+FLOOR(RAND()*61),1)); SET str4=CONCAT(SUBSTRING(str,1+FLOOR(RAND()*61),2),SUBSTRING(str,1+FLOOR(RAND()*61),2)); SET i=i+1; INSERT INTO pressure VALUES (i,FLOOR(RAND()*num),str2,str4,NOW()); END WHILE; END // DELIMITER ; call rand_data(1000000); commit;
然后执行:
mysqlslap --defaults-file=/etc/my.cnf \ --concurrency=100 \ --iterations=1 \ --create-schema='pp' \ --query="select * from pp.pressure where k1='oa';" \ --engine=innodb \ --number-of-queries=2000 \ -uroot -p123 -verbose
各项参数:
--defaults-file:默认的配置文件。--concurrency:并发用户数。--iterations:要运行这些测试多少次。--create-schema:被压测数据库名。--query:执行压力测试时的SQL语句。--number-of-queries:SQL语句执行次数
相当于,模拟100个用户并发,每个用户执行20次查询操作。
我们针对pressure做个简单的查询操作,来看SQL的执行时间:
[root@cs home]# mysqlslap --defaults-file=/etc/my.cnf \ > --concurrency=100 \ > --iterations=1 \ > --create-schema='pp' \ > --query="select * from pp.pressure where k1='oa';" \ > --engine=innodb \ > --number-of-queries=2000 \ > -uroot -p123 -verbose mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine rbose Average number of seconds to run all queries: 272.527 seconds Minimum number of seconds to run all queries: 272.527 seconds Maximum number of seconds to run all queries: 272.527 seconds Number of clients running queries: 100 Average number of queries per client: 20
有执行结果可以看到,100个并发,共2000次查询,平均耗时272.527秒,非常的慢了。我们来分析一下慢的原因:
-- 没有索引 mysql> SHOW INDEX FROM pressure; Empty set (0.00 sec) -- type是all,rows大约是95万 mysql> EXPLAIN SELECT * FROM pressure WHERE k1='oa'; +----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | pressure | NULL | ALL | NULL | NULL | NULL | NULL | 955377 | 10.00 | Using where | +----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
既然没有索引,我们现在为查询字段建立上索引:
-- 添加索引 mysql> ALTER TABLE pressure ADD INDEX idx_k1(k1); Query OK, 0 rows affected (1.54 sec) Records: 0 Duplicates: 0 Warnings: 0 -- 再次查看执行计划,发现type:ref,而rows:267 mysql> EXPLAIN SELECT * FROM pressure WHERE k1='oa'; +----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | 1 | SIMPLE | pressure | NULL | ref | idx_k1 | idx_k1 | 9 | const | 267 | 100.00 | NULL | +----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
再来执行同一个压力测试语句,看效果
[root@cs home]# mysqlslap --defaults-file=/etc/my.cnf \ > --concurrency=100 \ > --iterations=1 \ > --create-schema='pp' \ > --query="select * from pp.pressure where k1='oa';" \ > --engine=innodb \ > --number-of-queries=2000 \ > -uroot -p123 -verbose mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine rbose Average number of seconds to run all queries: 0.612 seconds Minimum number of seconds to run all queries: 0.612 seconds Maximum number of seconds to run all queries: 0.612 seconds Number of clients running queries: 100 Average number of queries per client: 20
看平均执行时间,从原来的270多秒到现在的零点几秒,这性能提升多少倍,算不过来........
再来点稍微复杂的语句,加个ORDER BY:
mysqlslap --defaults-file=/etc/my.cnf \ --concurrency=100 \ --iterations=1 \ --create-schema='pp' \ --query="SELECT * FROM pressure WHERE k2='oa' ORDER BY k1;" \ --engine=innodb \ --number-of-queries=2000 \ -uroot -p123 -verbose mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine rbose Average number of seconds to run all queries: 271.739 seconds Minimum number of seconds to run all queries: 271.739 seconds Maximum number of seconds to run all queries: 271.739 seconds Number of clients running queries: 100 Average number of queries per client: 20
耗时也不短!
先来看当前的索引和SQL语句的执行计划:
mysql> SHOW INDEX FROM pressure; +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | pressure | 1 | idx_k1 | 1 | k1 | A | 3772 | NULL | NULL | YES | BTREE | | | +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 1 row in set (0.00 sec) mysql> EXPLAIN SELECT * FROM pressure WHERE k2='oa' ORDER BY k1; +----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+ | 1 | SIMPLE | pressure | NULL | ALL | NULL | NULL | NULL | NULL | 955377 | 10.00 | Using where; Using filesort | +----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+ 1 row in set, 1 warning (0.01 sec)
再来添加一个索引,看看效果
-- 由于k1有了索引,这次我们为k1和k2建立一个联合索引 ALTER TABLE pressure ADD INDEX idx_k2_k1(k2,k1);
根据WHERE条件,在建立联合索引中,k2要在k1前面,此时以下情况都会走该联合索引:
-- 示例,仔细观察,根据字段的位置不同,MySQL选择的索引也不同 mysql> EXPLAIN SELECT * FROM pressure WHERE k2='oa' ORDER BY k1; -- 走联合索引 +----+-------------+----------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | pressure | NULL | ref | idx_k2_k1 | idx_k2_k1 | 17 | const | 1 | 100.00 | Using index condition | +----+-------------+----------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) mysql> EXPLAIN SELECT * FROM pressure WHERE k1='oa' ORDER BY k2; -- 走之前创建的索引 +----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+ | 1 | SIMPLE | pressure | NULL | ref | idx_k1 | idx_k1 | 9 | const | 267 | 100.00 | Using index condition; Using filesort | +----+-------------+----------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+ 1 row in set, 1 warning (0.00 sec)
上面的联合索引的一种情况,其实联合索引非常复杂,除了上面的情况,还要考虑优化器是否优化了SQL语句、根据查询的字段不同,要考虑是否进行了回表查询等等
再来看性能:
[root@cs home]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='pp' --query="SELECT * FROM pressure WHERE k2='oa' ORDER BY k1;" --engine=innodb --number-of-queries=2000 -uroot -p123 -verbose mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine rbose Average number of seconds to run all queries: 0.058 seconds Minimum number of seconds to run all queries: 0.058 seconds Maximum number of seconds to run all queries: 0.058 seconds Number of clients running queries: 100 Average number of queries per client: 20
十二 索引无法命中的情况
准备点数据,通过pymysql录入一百万条数据
import time import faker import pymysql from pymysql.connections import CLIENT fk = faker.Faker(locale='zh_CN') conn = pymysql.Connect( host='10.0.0.200', user='root', password='123', database='', charset='utf8', client_flag=CLIENT.MULTI_STATEMENTS) cursor = conn.cursor() def create_table(databaseName, tableName): """ 创建表 """ sql = """ DROP DATABASE IF EXISTS {databaseName}; CREATE DATABASE {databaseName} CHARSET utf8; USE {databaseName}; DROP TABLE IF EXISTS {tableName}; CREATE TABLE {tableName}( id int not null primary key unique auto_increment, name varchar(32) not null default "张开", addr varchar(128) not null default "", phone varchar(32) not null, email varchar(64) not null ) ENGINE=INNODB CHARSET=utf8; """.format(databaseName=databaseName, tableName=tableName) # 注意,一次性执行多行sql,必须在连接时,指定client_flag=CLIENT.MULTI_STATEMENTS cursor.execute(sql) conn.commit() def insert_many(num, tableName): """ 批量插入 """ gen = ((i, fk.name(), fk.address(), fk.phone_number(), fk.email()) for i in range(1, num + 1)) sql = "insert into {tableName}(id, name, addr, phone, email) values(%s, %s, %s, %s, %s);".format( tableName=tableName) cursor.executemany(sql, gen) conn.commit() if __name__ == '__main__': num = 1000000 database = "my_idb" table = 'idb_tb' create_table(database, table) insert_many(num, table) cursor.close() conn.close()
这里要明确一点,创建的索引不一定被应用;不合理的索引不会加速查询。
另外由于查询语句非常的复杂,导致索引命中情况也非常复杂,这里只是根据当前环境下,列举一些查询语句,有索引但无法命中情况。
在往下看之前,请务必对示例中的表结构和记录烂熟于心。
12.1 类型不一致
如果要查询的列是字符串类型,那么查询条件也必须是字符串,否则无法命中
-- 创建辅助索引 ALTER TABLE idb_tb ADD KEY phone_idx(phone); -- 这里的phone字段类型是varchar -- 查询条件是字符串,走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone = "123"; +----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------+ | 1 | SIMPLE | idb_tb | NULL | ref | phone_idx | phone_idx | 98 | const | 1 | 100.00 | NULL | +----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) -- 如果是整型,不走索引,MySQL内部会使用函数将整型条件转换为字符串后进行查询 mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone = 123; +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 10.00 | Using where | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 3 warnings (0.00 sec)
当where条件中,索引列和非索引列同时作为查询条件时,可能走也可能不走索引:
-- 当or的两边一个是索引列一个非索引列,不走索引
-- 如果and两边一个是索引列一个非索引列,走索引
-- 这里的id是主键索引,email是非索引列 explain select * from idb_tb where id=1 or email="yongqian@yahoo.com"; +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | ALL | PRIMARY,id | NULL | NULL | NULL | 994224 | 10.00 | Using where | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ -- id主键,name是辅助索引列,email是非索引列,走索引 explain select * from idb_tb where id=1 or name="余秀芳" and email="yongqian@yahoo.com"; +----+-------------+--------+------------+-------------+--------------------------+---------------+---------+------+------+----------+-----------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------------+--------------------------+---------------+---------+------+------+----------+-----------------------------------------+ | 1 | SIMPLE | idb_tb | NULL | index_merge | PRIMARY,id,com_idx,idx_1 | PRIMARY,idx_1 | 4,98 | NULL | 44 | 100.00 | Using union(PRIMARY,idx_1); Using where | +----+-------------+--------+------------+-------------+--------------------------+---------------+---------+------+------+----------+-----------------------------------------+
对于辅助索引来说,!=、NOT IN也不走索引
phone字段已经创建了辅助索引phone_idx。
-- 不走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone NOT IN ("15592925142", "13449332638", "18257778732"); +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 100.00 | Using where | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) -- 但下面这种情况,会走辅助索引,因为查询语句只需要phone字段,而phone字段是索引字段,这是索引覆盖现象 mysql> EXPLAIN SELECT phone FROM idb_tb WHERE phone NOT IN ("15592925142", "13449332638", "18257778732"); +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+ | 1 | SIMPLE | idb_tb | NULL | index | phone_idx | phone_idx | 98 | NULL | 994224 | 100.00 | Using where; Using index | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+ 1 row in set, 1 warning (0.00 sec) -- 这些情况只是针对于辅助索引,如主键索引就没事 mysql> EXPLAIN SELECT * FROM idb_tb WHERE id NOT IN (155, 134, 182); +----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | range | PRIMARY,id | PRIMARY | 4 | NULL | 497291 | 100.00 | Using where | +----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
在索引列上,使用函数及运算操作(+、-、*、/等),不走索引
-- 走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE id = 123; +----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | idb_tb | NULL | const | PRIMARY,id | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) -- 由于有运算,不走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE id + 1 = 123; +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | ALL | NULL | NULL | NULL | NULL | 994224 | 100.00 | Using where | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) -- 但把运算放到值上,就可以走索引 mysql> explain select * from idb_tb where id=4+1; +----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | idb_tb | NULL | const | PRIMARY,id | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
某些情况下,查询结果集如果超过了表中记录的25%,优化器就觉得没有必要走索引了
如下面两条查询语句,根据结果集大小,索引命中也不一样。
查询以 "155" 开头的手机号:
-- 结果集小于表记录的25% mysql> SELECT COUNT(*) FROM idb_tb WHERE phone LIKE "155%"; +----------+ | COUNT(*) | +----------+ | 33390 | +----------+ 1 row in set (0.02 sec) -- 走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "155%"; +----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+ | 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 61282 | 100.00 | Using index condition | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec)
查询以 "15" 开头的手机号
-- 结果集大于表记录的25% mysql> SELECT COUNT(*) FROM idb_tb WHERE phone LIKE "15%"; +----------+ | COUNT(*) | +----------+ | 300102 | +----------+ 1 row in set (0.13 sec) -- 不走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%"; +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 50.00 | Using where | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
针对这种情况,可以使用limit来解决,并且我发现,只要加上limit,就走索引,无论限制的记录条数是多少。
mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%" limit 20000; +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ | 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 497112 | 100.00 | Using index condition | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%" limit 250000; +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ | 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 497112 | 100.00 | Using index condition | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%" limit 400000; +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ | 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 497112 | 100.00 | Using index condition | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec)
由上例可以发现,哪怕最后的limit限制条数大于实际结果集的大小,最后也都走了索引。
对于like来说,%开头,不走索引,%在后事情况而定
-- %开头,不走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "%778732"; +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | ALL | NULL | NULL | NULL | NULL | 994224 | 11.11 | Using where | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) -- %在后,要根据结果集和其他情况而定,如下面结果集的大小决定是否走索引 mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "155%"; +----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+ | 1 | SIMPLE | idb_tb | NULL | range | phone_idx | phone_idx | 98 | NULL | 61282 | 100.00 | Using index condition | +----+-------------+--------+------------+-------+---------------+-----------+---------+------+-------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) mysql> EXPLAIN SELECT * FROM idb_tb WHERE phone LIKE "15%"; +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | idb_tb | NULL | ALL | phone_idx | NULL | NULL | NULL | 994224 | 50.00 | Using where | +----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
我们来进行一个总结:
- 建表时一定要有主键,一般是一个无关列,如
id - 选择唯一性索引,唯一性索引的值是唯一的,能快速的通过索引来确定某条记录
- 为经常需要
WHERE、ORDER BY、GROUP BY、JOIN、ON这些长操作的字段,根据业务建立索引 - 如果索引字段的值很长,最好选择建立前缀索引
- 对于重复值较多的列,可以选择建立联合索引
- 降低索引的数量,一方面不要创建没用的索引,另外对于不常用的索引及时清理
- 索引的数目不是越多越好,因为随着索引数量的增多,可能带来的问题:
- 每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大
- 修改表时,对于索引的重构和更新就越麻烦;越多的索引,会使更新表时浪费更多的时间
- 优化器的负担会加重,有可能会影响到优化器的选择
- 删除不再使用或者很少使用的索引,当表中的数据被大量更新,或者数据的使用方式发生改变后,原有的索引可能不在需要,数据库管理员应定期找出并删除这些索引,从而减少索引对更新操作的影响
- 我们可以通过percona toolkit这个工具来分析索引是否有用
- 索引的数目不是越多越好,因为随着索引数量的增多,可能带来的问题:
- 对于索引的维护要避开业务繁忙期
- 大表加索引,也要避开业务繁忙期
- 尽量少在经常更新的列上建立索引
- 查询结果集如果超过了表中记录的25%,优化器就觉得没有必要走索引了,可能的解决方法:
- 如果业务允许,可以使用limit加以控制
- 如果在MySQL中没有更好的解决方案,可以考虑放到redis中
- 索引失效,导致统计的数据不真实,索引本身有自我维护的能力,但对于表记录变化比较频繁的情况下,有可能会出现索引失效,解决办法一般是删除重建索引
- 不要再索引列上,进行函数及运算操作(
+、-、*、/等) - 对于模糊查询的搜索需求,可以使用elasticsearch加mongodb来搭配实现。

