
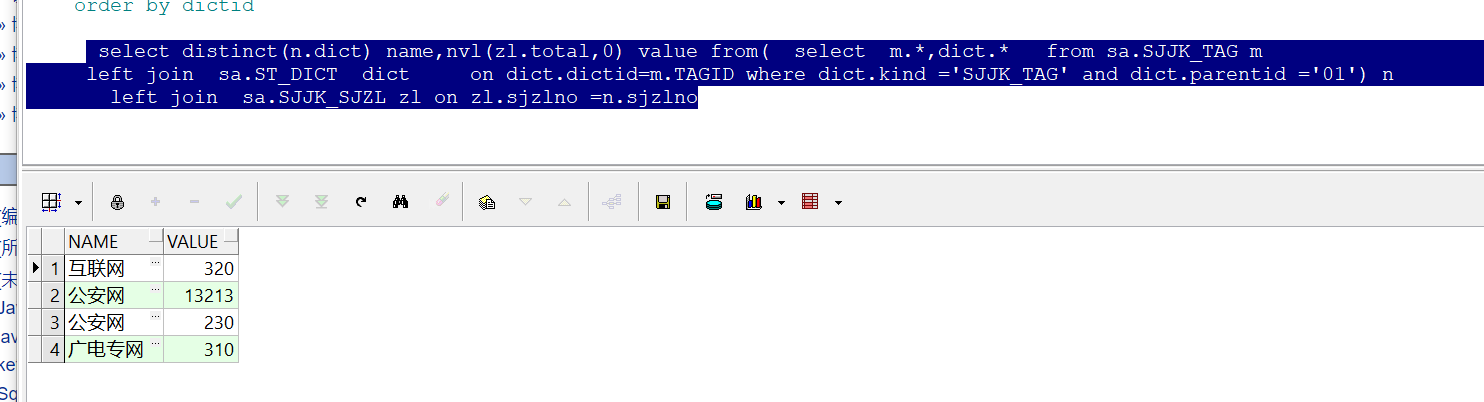
如下图的查出来的结果是有问题的。
select distinct(n.dict) name,nvl(zl.total,0) value from( select m.*,dict.* from sa.SJJK_TAG m left join sa.ST_DICT dict on dict.dictid=m.TAGID where dict.kind ='SJJK_TAG' and dict.parentid ='01') n left join sa.SJJK_SJZL zl on zl.sjzlno =n.sjzlno
select name,sum(value) value from ( select dict.dictid,dict.dict name,value from (select tagid,nvl(sum(total),0) value from sa.sjjk_sjzl a,sa.sjjk_tag b where a.sjzlno =b.sjzlno and b.tagid like '01%' group by tagid) m left outer join sa.st_dict dict on dict.dictid=m.tagid and dict.kind ='SJJK_TAG' union all ( select dictid,dict name ,0 value from sa.st_dict dict where dict.kind ='SJJK_TAG' and dict.parentid ='01' ) ) group by dictid,name order by dictid
上面的sql为正解。把重复的数据先分组去重,再和别的表连接。
以防止完全没数据的情况,用
union all ( select dictid,dict name ,0 value from sa.st_dict dict where dict.kind ='SJJK_TAG' and dict.parentid ='01' )
给没值的字段赋0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号