

「逻辑回归模型」
解决的是监督学习中的分类问题。但由于历史原因名字中带有回归,但它实际上是分类算法。还是从最基础的分类问题「二分类问题」开始讲起。
监督学习是什么呢?监督学习是从标记的训练数据来推断一个功能的机器学习任务,比如通过几个瓜外在特征推断出好瓜坏瓜。
二分类问题
我们的输出向量 y(结果) 不是连续的值范围,而是只有 0 或 1(即 y ε {0,1})
最简单的举例:这首歌曲,你喜欢,或 不喜欢(QQ音乐)
借给你钱了,你 还,还是不还(花呗)
多分类问题
学会了解决二分类问题后,现在,我们将数据分类为两类以上,即从 y = {0,1} 扩展到 y = {0,1,...,n}。
生活在互联网时代,我们的在互联网的一切行为(点击,转发,点赞)等都被应用的算法记录下来成为大数据的一部分,我们在生产数据,也在影响数据对我们决策,于是我们被在互联网上被推送了各种各样的广告、购物网站的关联商品、音乐应用的“还喜欢听”、新闻资讯网站的各种相关推荐等等。这些算法,根据我们在互联网的特点(点击行为、身份等)给我们打了许多标签,我们就“被”分类了,例如你在抖音中点赞过一个视频,接着你会发现抖音给你推送的就是这一分类相关视频。
这种分类的算法成为逻辑回归算法。

sigmoid函数
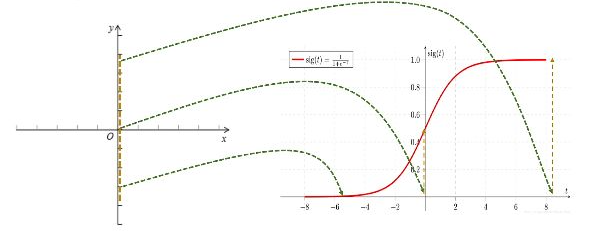
观察这个看似复杂的图:
发现
当Y的值大于0之时,对应的逻辑回归结果大于0.5
当Y的值小于0时,对应的逻辑回归结果小于0.5
一些逻辑回归公式(暂时先列出来,后来再研究)

案例:(学习时间和通过考试的预测案例了解一下逻辑回归是如何分析解决问题)
1、首先建立一个小的数据集合,一列是学习时间,一列是是否通过考试,通过考试用1表示,未通过考试用0表示。
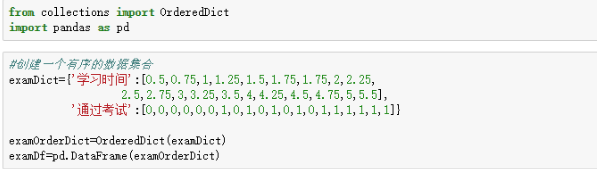
在用Pandas读取数据之后,(暂时只看数据,不细究代码)我们往往想要观察一下数据读取是否准确,这就要用到Pandas里面的head( )函数
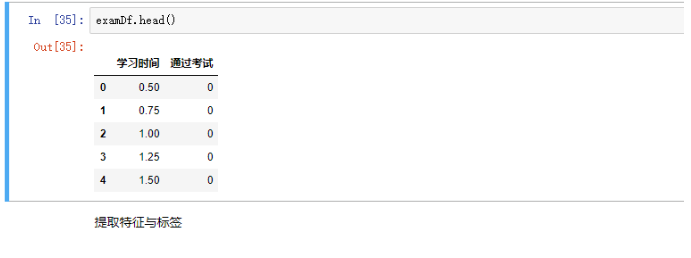
2.提取特征和标签(备注:比如 西瓜“色泽”、“根蒂”、“敲声” 被称为特征 ;好瓜和坏瓜则被称为标签)

通过散点图,观察一下数据
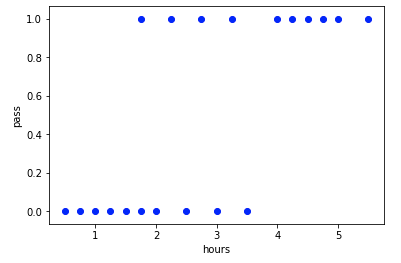
这种的散点图 不是线性的,可以看到数据是明显的两极分化:0和1;
3.确定逻辑回归模型,建立训练数据集和测试数据集。
备注:训练数据和测试数据(训练数据train:建立机器学习模型 测试数据test:验证模型的正确率)
train_test_split 是交叉验证中常用的函数,功能是从样本中随机的按照比例选取训练集合和测试数据
X:所要划分的特征
Y:所要划分的标签
train_size: 训练数据占比。如果是正数的话,乘以相应百分比就是样本的数量

解释一下:原始数据有20个,训练数据是20*0.8即为 16个数据。
4、训练模型
首先将训练数据和测试数据转换成二维数组xx行*1列;

导入逻辑回归

创建逻辑回归模型

训练模型

5、模型评估
通过一个特定的数,也就是测试一个学习时间下,通过考试的概率。

当我们假定学习时间为3小时的时候,输出的第一个值小于0.5,我们按照概率值为0, 输出的第二个值大于0.5,我们按照 概率值是1处理。
部分参考:https://zhuanlan.zhihu.com/p/520490105

 浙公网安备 33010602011771号
浙公网安备 33010602011771号