
kibana启动失败Kibana server is not ready yet,ES后台日志报错:NoShardAvailableActionException
kibana.log日志报错信息:
1 | {"level":"error","message":"Action failed with 'no_shard_available_action_exception'. Retrying attempt 8 out of 10 in 64 seconds."},{"level":"error","message":"Action failed with 'no_shard_available_action_exception'. Retrying attempt 9 out of 10 in 64 seconds."},{"level":"error","message":"Action failed with 'no_shard_available_action_exception'. Retrying attempt 10 out of 10 in 64 seconds."}],"sourceIndex":{"_tag":"None"},"targetIndex":".kibana_7.12.0_001","versionIndexReadyActions":{"_tag":"None"},"updateTargetMappingsTaskId":"7DrpBWixQqirLVwQUONeSg:541034","reason":"Unable to complete the UPDATE_TARGET_MAPPINGS_WAIT_FOR_TASK step after 10 attempts, terminating.","outdatedDocuments":[],"message":"[.kibana] UPDATE_TARGET_MAPPINGS_WAIT_FOR_TASK -> FATAL"} |
ES 的 CollectorDBCluster.log日志报错信息如下
1 | org.elasticsearch.action.NoShardAvailableActionException: No shard available for [get [.tasks][task][7DrpBWixQqirLVwQUONeSg:541031]: routing [null]] |
问题解决:
解决该问题的根本方案是让ES单节点不产生副本分片,因为本文中使用的是logstash+es单节点,默认情况下Elasticsearch 生成 1 个主分片和 1 个副本分片,如果要生成单副本索引,则应将 logstash配置中 replication 参数设置为 1。
链接:logstash+Elasticseach单节点 让logstash生成单副本索引
下面是不更改logstash配置恢复ES方案
查看ES单机状态:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | [es@uni-dzkf-elk kibana-log]$ curl -X GET 'http://172.16.1.10:9200/_cluster/health?pretty'{ "cluster_name" : "CollectorDBCluster", "status" : "red", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 2018, "active_shards" : 2018, "relocating_shards" : 0, "initializing_shards" : 4, "unassigned_shards" : 625, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 11, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 165139, "active_shards_percent_as_number" : 76.23724971666037}[es@uni-dzkf-elk kibana-log]$ |
发现ES单机状态为red且存在大量"unassigned_shards"的分片,各状态代表如下
绿色表示最健康的状态,代表所有的主分片和副本分片都可用; 黄色表示所有的主分片可用,但是部分副本分片不可用; 红色表示部分主分片不可用. (此时执行查询部分数据仍然可以查到)
查看索引,发现"unassigned_shards"的分片状态都为red
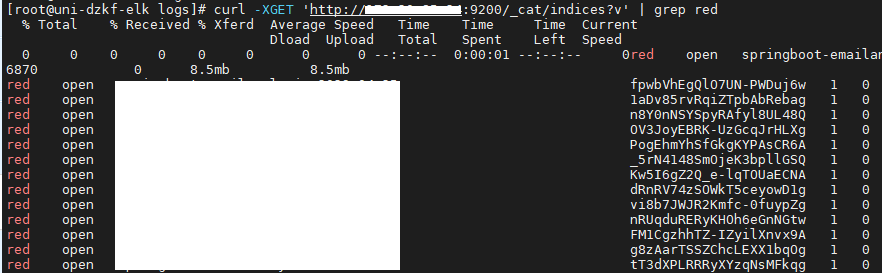
unassigned 分片问题可能的原因?
1 2 3 4 5 6 7 8 9 10 11 12 | INDEX_CREATED: 由于创建索引的API导致未分配。CLUSTER_RECOVERED: 由于完全集群恢复导致未分配。INDEX_REOPENED: 由于打开open或关闭close一个索引导致未分配。DANGLING_INDEX_IMPORTED: 由于导入dangling索引的结果导致未分配。NEW_INDEX_RESTORED: 由于恢复到新索引导致未分配。EXISTING_INDEX_RESTORED: 由于恢复到已关闭的索引导致未分配。REPLICA_ADDED: 由于显式添加副本分片导致未分配。ALLOCATION_FAILED: 由于分片分配失败导致未分配。NODE_LEFT: 由于承载该分片的节点离开集群导致未分配。REINITIALIZED: 由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。REROUTE_CANCELLED: 作为显式取消重新路由命令的结果取消分配。REALLOCATED_REPLICA: 确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。 |
如何解决 unassigned 分片问题?
方案一:极端情况——这个分片数据已经不可用,直接删除该分片 (即删除索引)(先执行方案二)
Elasticsearch中没有直接删除分片的接口,除非整个节点数据已不再使用,删除节点。
1 | [root@uni-dzkf-elk logs]# curl -s -XGET 'http://172.16.1.10:9200/_cat/indices?v' | grep ^red | awk '{print $3}' | xargs -I {} curl -XDELETE http://172.16.1.10:9200/{} |
方案二:集群中节点数量 >= 集群中所有索引的最大副本数量 +1
N > = R + 1
其中:
N——集群中节点的数目;
R——集群中所有索引的最大副本数目。
注意事项:当节点加入和离开集群时,主节点会自动重新分配分片,以确保分片的多个副本不会分配给同一个节点。换句话说,主节点不会将主分片分配给与其副本相同的节点,也不会将同一分片的两个副本分配给同一个节点。 如果没有足够的节点相应地分配分片,则分片可能会处于未分配状态。
如果Elasticsearch集群就一个节点,即N=1;所以R=0,才能满足公式。这样问题就转嫁为:
1) 添加节点处理,即N增大;
2) 删除副本分片,即R置为0。
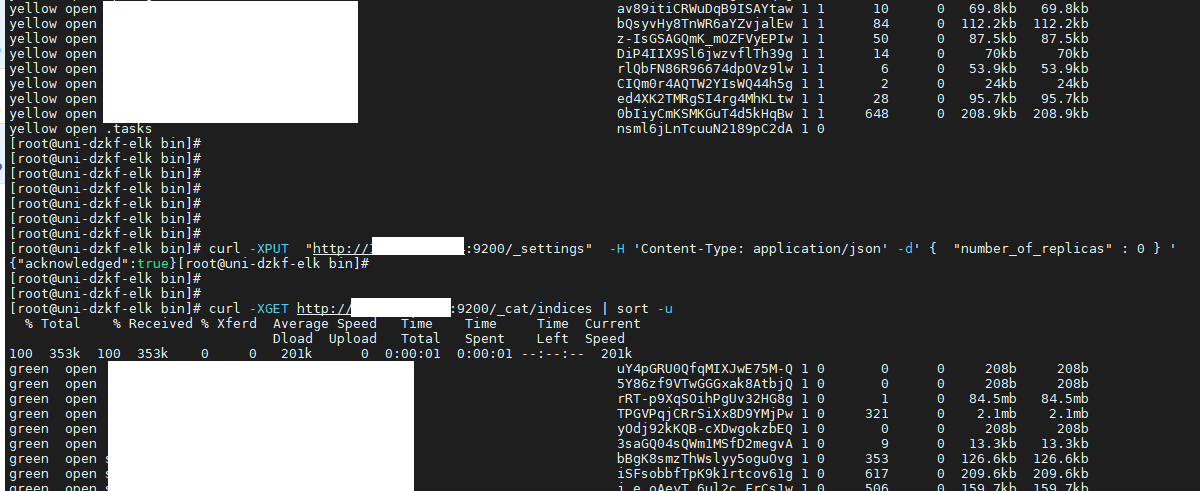
R置为0的方式,可以通过如下命令行实现:
1 2 | [root@uni-dzkf-elk bin]# curl -XPUT "http://172.16.1.10:9200/_settings" -H 'Content-Type: application/json' -d' { "number_of_replicas" : 0 } '{"acknowledged":true}[root@uni-dzkf-elk bin] |
1 2 3 4 5 6 | 这个命令是指通过 REST API 在 Elasticsearch 中修改索引的副本数量,将副本数量设置为0,即不再为该索引创建副本。这个命令的具体含义是:发送一个POST请求到 Elasticsearch服务,请求的URL为/_settings,意味着我们要去修改索引的设置。使用 -H 选项指定头信息 'Content-Type: application/json',告诉 Elasticsearch 现在要发送的数据是JSON格式的。使用 -d 选项指定请求体,也就是要更新的索引的设置信息,这里将 number_of_replicas 参数设置为 0,表示将该索引的副本数量设置为0。这个命令的作用是减少索引的副本数量以释放硬件资源,降低硬件成本,同时也可以提高索引写入性能。但需注意,当节点或分片发生故障时,如果没有副本的支持,将会导致数据丢失。因此需要在保证性能的同时,考虑数据的可靠性和安全性。 |
执行完该命令后,原来索引状态为yellow的索引,全部变为green。
方案三:allocate重新分配分片
如果方案二仍然未解决,可以考虑重新分配分片。可能的原因:
1) 节点在重新启动时可能遇到问题。正常情况下,当一个节点恢复与群集的连接时,它会将有关其分片的信息转发给主节点,然后主节点将这分片从“未分配”转换为 "已分配/已启动"。
2) 当由于某种原因 (例如节点的存储已被损坏) 导致该进程失败时,分片可能保持未分配状态。
在这种情况下,必须决定如何继续: 尝试让原始节点恢复并重新加入集群(并且不要强制分配主分片); 或者强制使用Reroute API分配分片并重新索引缺少的数据原始数据源或备份。 如果你决定分配未分配的主分片,请确保将"allow_primary":"true"标志添加到请求中。
Elasticsearch5.X使用脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #!/bin/bashNODE="YOUR NODE NAME"IFS=$'\n'for line in $(curl -s '10.0.8.47:9200/_cat/shards' | fgrep UNASSIGNED); do INDEX=$(echo $line | (awk '{print $1}')) SHARD=$(echo $line | (awk '{print $2}')) curl -XPOST '10.0.8.47:9200/_cluster/reroute' -d '{ "commands": [ { " allocate_replica ": { "index": "'$INDEX'", "shard": '$SHARD', "node": "'$NODE'", "allow_primary": true } } ] }'done |
Elasticsearch2.X及早期版本,只需将上面脚本中的allocate_replica改为 allocate,其他不变。
上面脚本解读:
步骤1:定位 UNASSIGNED 的节点和分片
1 | curl -s '10.0.8.47:9200/_cat/shards' | fgrep UNASSIGNED |
步骤2:通过 allocate_replica 将 UNASSIGNED的分片重新分配。
allocate分配原理
分配unassigned的分片到一个节点。将未分配的分片分配给节点。接受索引和分片的索引名称和分片号,以及将分片分配给它的节点。它还接受allow_primary标志来明确指定允许显式分配主分片(可能导致数据丢失)。
作者通过执行方案一和方案二后单机ES已恢复正常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | [es@uni-dzkf-elk kibana-log]$ curl -X GET 'http://172.16.1.10:9200/_cluster/health?pretty'{ "cluster_name" : "CollectorDBCluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 1915, "active_shards" : 1915, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0}[es@uni-dzkf-elk kibana-log]$ |
1 | /_cluster/health?pretty 详解 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | [root@uni-dzkf-elk config]# curl -X GET "172.10.10.1:9200/_cluster/health?pretty"{ "cluster_name" : "CollectorDBCluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 2362, "active_shards" : 2362, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0}[root@uni-dzkf-elk config]# |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | "number_of_nodes" : 1 是 Elasticsearch 索引的副本分片数量。它指定了索引要使用的节点数量,也就是决定了该索引的实际副本数量。具体来说,该设置控制 Elasticsearch 集群中用于索引的节点数量,而节点数量会影响数据的可靠性和可用性。主分片和副本分片的数量将根据此设置进行计算,并分配到可用的节点上。以下是 number_of_nodes 的一些示例设置:"number_of_nodes" : 1该设置意味着该索引将使用集群中的一个节点(即没有副本分片)。这种设置比较适合小型或测试系统,因为它不提供副本分片来提高数据的可靠性或可用性。"number_of_nodes" : 2该设置意味着该索引将使用 2 个节点(即主分片和 1 个副本分片)。这种设置比较适合中小型系统,因为它提供了一定的数据冗余和可靠性,但不会影响系统的性能。"number_of_nodes" : 3该设置意味着该索引将使用 3 个节点(即主分片和 2 个副本分片)。这种设置比较适合大型企业级系统,因为它提供了更强的数据冗余和可靠性,但会增加系统的负载和性能消耗。请注意,必须将 number_of_nodes 和 number_of_replicas 结合使用,以便为 Elasticsearch 索引分配足够的主分片和副本分片,以满足数据可靠性和可用性的需求。 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | "number_of_data_nodes" : 1 是 Elasticsearch 索引的数据节点数量,也可以称为“存储节点数量”。它指定了哪些节点上的数据分片(包括主分片和副本分片)可以被分配给该索引。具体来说,该设置指定了集群中的数据节点数量,这些节点将负责存储和管理该索引的数据分片。它与 number_of_nodes 不同,后者指定了集群中用于索引的节点数量,包括数据节点和非数据节点。以下是一些示例设置:"number_of_data_nodes" : 1该设置意味着该索引的数据分片将只分配到集群中的一个数据节点上。这种设置比较适合小型或测试系统,因为它只提供了轻微的数据冗余,不影响性能。"number_of_data_nodes" : 2该设置意味着该索引的数据分片将分配到集群中的两个数据节点上。这种设置比较适合中小型系统,因为它提供了一定的数据冗余和可靠性,但不会影响系统的性能。"number_of_data_nodes" : 3该设置意味着该索引的数据分片将分配到集群中的三个数据节点上。这种设置比较适合大型企业级系统,因为它提供了更强的数据冗余和可靠性,但会增加系统的负载和性能消耗。请注意,"number_of_data_nodes" 与 Elasticsearch 集群中的 number_of_nodes 和 number_of_replicas 结合使用,以确保为索引分配足够的主分片和副本分片,并在可用性和性能之间进行平衡。 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | "active_primary_shards" : 2361 是 Elasticsearch 集群中当前处于活动状态的主分片数量。每个 Elasticsearch 索引可以有一个或多个主分片,主分片负责将数据分布到集群中的不同节点上。具体来说,当 Elasticsearch 索引被创建时,必须指定主分片数量。该数量控制了数据如何分布到集群中不同的数据节点上,并影响了数据的可用性和性能。如果某个主分片不可用,则索引的相应数据将不可用,可能导致应用程序出现错误或异常。以下是一些示例设置:"active_primary_shards" : 1该设置意味着该索引只有一个主分片。这种设置比较适合小型或测试系统,因为它只需要少量的计算和存储资源,并且数据可用性不是很重要。"active_primary_shards" : 2该设置意味着该索引有两个主分片。这种设置比较适合中小型系统,因为它可以提供一定程度的数据冗余和可用性,但不会对系统性能产生太大影响。"active_primary_shards" : 3该设置意味着该索引有三个主分片。这种设置比较适合大型企业级系统,因为它可以提供更强的数据冗余和可用性,尽管它会消耗更多的计算和存储资源。最好的做法是计算和设置索引的主分片数量,以适应机器的数量和可用性,以确保数据可靠性和高性能。需要注意的是,主分片数量不能更改,它只能在创建索引时进行设置。 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | "active_shards" : 2361 是 Elasticsearch 集群中当前处于活动状态的所有分片数量,包括主分片和副本分片。每个分片都是一份相同大小的数据拷贝,分布在 Elasticsearch 集群中不同的节点上,以提高数据的可靠性和可用性。具体来说,当 Elasticsearch 索引被创建时,每个主分片还可以创建一个或多个副本分片。副本分片是主分片的拷贝,它们分布在集群的不同节点上,以提高数据的可靠性和可用性。如果主分片不可用,则副本分片将被晋升为主分片,以保证数据的可用性。以下是一些示例设置:"active_shards" : 1该设置意味着该索引只有一个分片,没有副本分片。这种设置比较适合小型或测试系统,因为它需要的计算和存储资源最少,但数据可用性和可靠性非常低。"active_shards" : 2该设置意味着该索引有两个分片,每个主分片都有一个副本分片。这种设置比较适合中小型系统,因为它提供了一定程度的数据冗余和可用性,但不会对系统性能产生太大影响。"active_shards" : 3该设置意味着该索引有三个分片,每个主分片都有两个副本分片。这种设置比较适合大型企业级系统,因为它可以提供更强的数据冗余和可用性,尽管需要更多的计算和存储资源。总的来说,"active_shards" 数量应该被设置为与集群中节点的数量成比例,以确保即使在节点失败时也能保持数据的可靠性和可用性。 |
1 2 3 4 5 6 7 | "timed_out" : false 表示 Elasticsearch 查询没有超时,即查询已成功执行并返回结果。如果查询超时,则该值将为 true。查询超时是指查询花费的时间超过了 Elasticsearch 集群中的设置的默认超时时间。这可能意味着查询非常耗时,需要重新评估查询或增加 Elasticsearch 集群的性能和吞吐量。在 Elasticsearch 中,超时时间可以在查询中使用 timeout 参数进行设置,也可以在 Elasticsearch 集群的设置中进行全局设置。默认情况下,全局超时时间为 30 秒,可以根据特定用例进行更改。如果 Elasticsearch 查询超时,则该查询将不会返回结果,并返回超时错误。详细的错误信息可以在查询的响应中找到。 |
1 2 3 4 5 6 7 | "relocating_shards" : 0 表示在 Elasticsearch 集群中没有正在进行分片迁移。分片迁移是指将一个分片从一个节点移动到另一个节点,以实现负载均衡、节点失效恢复或集群扩容。在 Elasticsearch 集群中进行分片迁移可以帮助优化数据分布和集群性能。当某个节点的负载过高或者发生节点故障时,Elasticsearch 会自动触发分片迁移来重新平衡数据,确保集群中的每个节点负载平均。如果在集群运行期间观察到较高的 "relocating_shards" 数量,可能表示集群正在进行较大规模的数据迁移操作。这可能是由于节点故障、节点新增或删除、集群重新平衡等原因导致的。通常情况下,您希望 "relocating_shards" 的数量保持较低,以确保集群的稳定性和可用性。如果该值持续高于正常范围,可能需要检查集群的健康状态和各节点之间的网络连接质量。 |
1 2 3 4 5 6 7 | "initializing_shards" : 0 表示 Elasticsearch 集群中没有正在初始化的分片。分片初始化是指创建新分片并将其分配到集群中的某个节点上。当创建新索引或在现有索引中增加主分片或副本分片时,Elasticsearch 集群会自动分配并初始化新的分片。这包括将分片数据从主分片或已有副本分片复制到新的副本分片上。初始化过程可能需要一些时间,具体取决于分片的大小和数量、节点的性能和网络质量等因素。如果查询返回的状态信息中有 "initializing_shards",并且该值不为 0,则可能表示当前正在创建新的分片或节点正在从其他节点复制分片数据。尽管这是一项正常的操作,并且初始化过程并不会对查询性能产生太大的影响,但是考虑需要一些时间才能初始化完所有的分片以确保节点的健康状态和集群的稳定性。在 Elasticsearch 中,可以使用 _cat/allocation API 来查看集群中正在初始化或处理的分片信息。 |
1 2 3 4 5 6 7 8 9 | "unassigned_shards" : 1 表示在 Elasticsearch 集群中有一个未分配的分片。未分配的分片是指没有被分配到集群中的任何节点上的分片。这可能是由于以下原因导致的:节点故障:如果节点上的分片副本不能在其他节点上找到,则可能会导致分片未分配。在这种情况下,Elasticsearch 会自动启动分片重分配过程以恢复未分配的分片。索引创建或分片增加:如果索引或分片的增加操作正在进行中,则该分片可能不会立即分配到节点上。Elasticsearch 会在后台自动分配这些新分片,但这可能需要一段时间。集群性能问题:如果集群的性能问题导致分片分配变得缓慢或失败,则可能会导致未分配的分片。这可能是由于资源不足、网络问题或集群中其他故障引起的。通常情况下,"unassigned_shards" 的数量应该为 0。如果该值不为 0,则需要进一步检查集群的健康状态并解决任何故障以确保分片的正常分配和集群的可用性。在检查问题时,可以使用 Elasticsearch 提供的 _cat/shards API 来查找未分配的分片的详细信息。 |
1 2 3 4 5 6 7 8 9 | "delayed_unassigned_shards" : 0 表示 Elasticsearch 集群中没有延迟分配的未分配分片。延迟未分配的分片是指尚未分配到节点上的分片,但是由于某些原因而需要延迟分配。延迟未分配的分片通常会在以下情况下发生:索引恢复:如果正在进行索引的恢复操作,Elasticsearch 可能会延迟分配恢复的分片。这是为了避免在恢复过程中过度消耗集群的资源,而导致查询性能下降。一旦恢复过程完成,延迟分配的分片将会被重新分配。索引关闭和打开:当将索引关闭或打开时,Elasticsearch 会延迟分配关闭的索引的所有分片。这是为了避免关闭或打开索引期间的资源冲突。一旦索引关闭或打开完成,延迟分配的分片将会重新分配。延迟未分配的分片是 Elasticsearch 集群的正常行为。通常情况下,这并不会对集群的性能或可用性产生重大影响。然而,如果延迟未分配的分片的数量持续较高,可能需要进一步检查集群的健康状态和性能,并采取相应的措施来解决问题。 |
1 2 3 4 5 6 7 | "number_of_pending_tasks" : 0 表示 Elasticsearch 集群中当前没有等待处理的任务。该值表示当前等待队列中的任务数量,这些任务被添加到 Elasticsearch 的内部异步执行队列中,因此可能不会立即执行。这些任务包括索引写入、搜索请求、分片重分配、节点加入或退出等操作。当 Elasticsearch 收到这些操作时,它们将被添加到待执行队列中,然后异步执行,以确保系统的高吞吐量和低延迟。但是,如果待执行队列中的任务数量过多,并且未及时处理,可能会导致集群的性能受到影响。因此,当查询返回的状态信息中的 "number_of_pending_tasks" 值持续较高时,我们就需要进一步检查集群的健康状态以及任何可能会导致任务堆积的问题。可以通过 Elasticsearch 提供的 _tasks 和 _cat/tasks API 来查看待执行任务的列表以及它们的详细信息,以便更好地了解待执行任务在集群中的情况。可以查找待执行任务是否是由于索引写入、搜索请求或其他操作导致的,以及任何可能导致任务堆积的问题,并针对实际情况采取相应的措施。 |
1 2 3 4 5 6 7 8 9 | "number_of_in_flight_fetch" : 0 表示 Elasticsearch 集群中没有正在执行的 scroll 操作或查询操作,或这些操作都已经成功完成并返回结果。在 Elasticsearch 中,scroll 操作是一种可以检索大量数据的快速方式。它允许在查询结果集较大且无法一次完全返回时,通过多个小批次查询来检索所有数据。当执行 scroll 操作时,Elasticsearch 会将每个批次的搜索结果缓存起来,直到所有结果集都返回为止。在此过程中,number_of_in_flight_fetch 表示正在等待或当前正在运行的 scroll 操作的数量。此外,查询操作也可能会使 "number_of_in_flight_fetch" 的值增加。因为在处理查询时,Elasticsearch 也会使用一种类似于 scroll 的机制来动态生成和解除束缚,以最大限度地利用内存和硬件资源。当 "number_of_in_flight_fetch" 的值持续较高时,可能会影响 Elasticsearch 集群的性能和响应时间。可以通过使用 Elasticsearch 提供的 _cat/shards API 或查询集群的响应时间等指标来监控集群的健康状况。如果查询的响应时间过长或存在性能瓶颈,则可以优化查询或增加硬件资源以提高查询的吞吐量和响应时间。 |
1 2 3 4 5 6 7 | "task_max_waiting_in_queue_millis" : 0 表示 Elasticsearch 集群中没有等待时间超过阈值的任务。当任务被添加到 Elasticsearch 的内部异步执行队列中时,它们可能会在队列中等待一段时间,直到系统空闲时才被取出并执行。"task_max_waiting_in_queue_millis" 表示等待时间最长的任务在队列中等待的时间(以毫秒为单位)。如果该值持续较高,则表示有部分任务等待执行的时间过长,可能会影响系统的响应速度和性能。当 Elasticsearch 集群中出现任务长时间滞留或任务数持续较多时,可能会导致系统出现堆积的情况。检查可能导致任务堆积的原因,如节点健康状态、网络连接状态等,并尝试通过增加硬件资源、优化索引结构、合理分配节点等方式来解决问题。可以通过 Elasticsearch 提供的 _tasks 和 _cat/tasks API 来查看待执行任务的列表以及它们的详细信息,以便更好的了解待执行任务在集群中的情况。也可以通过使用 Elasticsearch 的监控工具(如 X-Pack 或者其他第三方工具)来监控 Elasticsearch 集群并实时反馈任务的堆积情况以及其他性能指标的变化。 |
1 2 3 4 5 | "active_shards_percent_as_number" 表示 Elasticsearch 集群中所有分片副本(replica)和主分片(primary)的可用性百分比,是一个浮点数。在查询的响应信息中,这个值通常以相对于整个集群中的所有分片而言的可用性百分比的形式进行展示。例如,"active_shards_percent_as_number" : 99.95766299745978 表示当前集群中有约 99.96% 的分片副本和主分片处于可用状态。这个值的大小与集群的健康状态密切相关,较低的值通常表示集群中存在一些问题或异常情况,需要进一步的诊断和处理。当这个值较低时,可能需要查找导致问题的原因,例如网络故障、物理或逻辑硬件故障、复本分片数量过低等情况。可以使用 Elasticsearch 提供的 _cat/shards API 或 GET /_cluster/allocation/explain API 来检查分片的状态并查找问题。同时,也可以使用 Elasticsearch 的监控工具(如 X-Pack 或其他第三方工具)来监测集群的运行状况和性能指标变化,以便及时发现和解决问题。 |
ES问题可参考这个篇文章,写的非常详细:https://www.cnblogs.com/kevingrace/p/10671063.html
本文作者:香菜哥哥
本文链接:https://www.cnblogs.com/yizhipanghu/p/17502796.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步