
uniittest 使用DDT数据驱动生成的html报告中的测试方法过长,ddt源码修改:HtmlTestRunner报告依据接口名显示用例方法名字
背景是这样的:
自己写了一套接口自动化的框架,其中使用unittest + ddt + mysql作为数据驱动模式的应用,使用HtmlTetstRunner来生成测试用例。
一切看起来很完美。
但是,发现测试报告中,测试用例名称都是:test_api_index.index表示用例的编号,从1开始,递增。比如:test_api_01、test_api_02......test_api_0N
希望能在不同的用例名称当中,显示相应的接口用例名字。比如登陆接口的成功登陆用例:测试报告中用例名称显示为test_login_success。密码错误的用例名称为:test_login_wrongPasswd
这样,我直接从报告中就可以知道是哪个接口的哪个用例失败了,一目了然。
于是,就开始琢磨这事儿了。。。
======================================背景分割线==================================
一琢磨就琢磨到ddt源码上去了。心中有一个疑惑:
1、为什么我的测试用例名称是这样的??
查看了ddt源码之后,发现有个函数是用来生成测试用例名字的。这个函数叫:mk_test_name
它是如何来生成测试用例名字的呢?
它接受两个参数:name 和 value.
name:为单元测试中,测试用例的名字。即test_api.
value:为测试数据。ddt是处理一组测试数据。而这个value就是这一组数据中的每一个测试数据。
对value的值是有限制的:要么就是单值变量,要么就是元组或者列表并且要求元组和列表中的数据都是单值变量。如("name","port") 、["name","port"]
如果传进来的测试数据,不符合value的要求,那么测试用例名字为:name_index。
如果传进来的测试数据,符合value的要求,那么测试用例名字为:name_index_value。如果value为列表或者元组,那么将列表/元组的每个数据依次追加在末尾。
比如传进来的name值为test_login,value值为["name","port"]。那最终的测试用例名字是:test_login_01_name_port。
如果传进来的name值为test_login,value值为{"name":"login","port":2204},那最终的测试用例名字为:test_login_01。因为它不支持对字典类型的数据处理。
很不巧,我的接口自动化框架中,ddt处理的数据是一列表:列表当中每个数据都为字典。ddt一遍历整个列表,那传给value的值刚好是字典。。
so。。。我得到的测试用例名称就是:test_api_01,test_api_02,test_api_03..........test_api_0N
ddt源码如下(红色粗体部分标识):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | def mk_test_name(name, value, index=0): """ Generate a new name for a test case. It will take the original test name and append an ordinal index and a string representation of the value, and convert the result into a valid python identifier by replacing extraneous characters with ``_``. We avoid doing str(value) if dealing with non-trivial values. The problem is possible different names with different runs, e.g. different order of dictionary keys (see PYTHONHASHSEED) or dealing with mock objects. Trivial scalar values are passed as is. A "trivial" value is a plain scalar, or a tuple or list consisting only of trivial values. """ # Add zeros before index to keep order index = "{0:0{1}}".format(index + 1, index_len) if not is_trivial(value): #如果不符合value的要求,则直接返回用例名称_下标作为最终测试用例名字。 return "{0}_{1}".format(name, index) try: value = str(value) except UnicodeEncodeError: # fallback for python2 value = value.encode('ascii', 'backslashreplace') test_name = "{0}_{1}_{2}".format(name, index, value) return re.sub(r'\W|^(?=\d)', '_', test_name) |
2、修改ddt源码,显示测试用例名字
为了让我的测试报告,呈现的更好。那就改改ddt源码,让它能够适应我的框架。
考虑两个问题:
1、不同接口的测试用例名字如何来??
2、如何让ddt支持对字典的处理??
解决方法:
第一个问题:每一个测试用例主动提供一个用例名字,说明你是什么接口的什么场景用例。比如:接口名_场景名。login_success、login_noPasswd、login_wrongPasswd等。
在我的框架当中,每一个测试用例是一个字典。那么我就在字典中添加一个键值对,case_name=用例名称
第二个问题:在ddt中添加对字典的处理,如果字典中有case_name字段,则将字典中键名为case_name的值作为测试用例名称中的value值。
修改后的ddt源码为(红色粗体部分为修改的内容):def mk_test_name(name, value, index=0):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | def mk_test_name(name, value, index=0): print("-------first value------------") print(value) # Add zeros before index to keep order index = "{0:0{1}}".format(index + 1, index_len) #---------------------------------------------------------------------------------- #添加了对字典数据的处理。 if not is_trivial(value) and type(value) is not dict: return "{0}_{1}".format(name, index) #如果数据是字典,则获取字典当中的api_name对应的值,加到测试用例名称中。 if type(value) is dict: try: value = value["case_name"] #case_name作为value值 except: return "{0}_{1}".format(name, index) #---------------------------------------------------------------------------------- try: value = str(value) except UnicodeEncodeError: # fallback for python2 value = value.encode('ascii', 'backslashreplace') test_name = "{0}_{1}_{2}".format(name, index, value) return re.sub(r'\W|^(?=\d)', '_', test_name) |
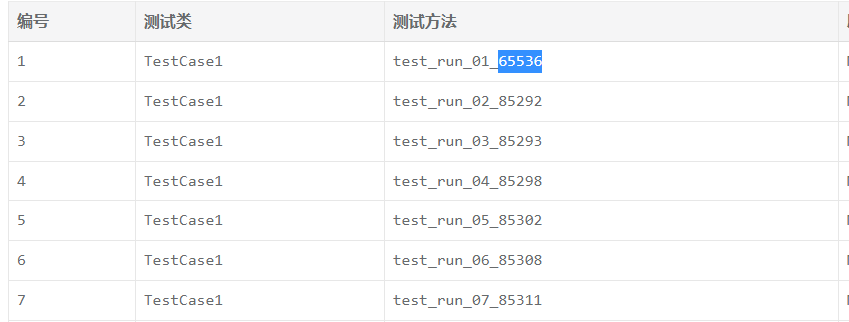
修改完成之后,再次运行接口测试,就可以在测试报告当中看到对应的用例名字了。。
本文作者:香菜哥哥
本文链接:https://www.cnblogs.com/yizhipanghu/p/15926541.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY