nginx负载均衡
一、基础概念
正向代理和反向代理
正向是代理客户端,比如路由器通过NAT代理客户端上网;
反向代理是代理服务器,代理服务器对客户端响应。
为什么用负载均衡
通过分发实现实现压力分担。
集群
集群中服务器的配置一模一样,就IP和主机名不一样,如果企业中搞先搞明白一台,然后ansible推送到所有的台,批量部署,用脚本或者ansible。
通过nginx做负载均衡,主要通过两个模块:upstream和proxy_pass
我们在使用nginx代理功能时,用到了proxy_pass或fastcig_pass两个模块,这两个模块我们通常是定义在location段下面,假如说我们有两台REAL-SERVER,那岂不是我们在location段下面要把两个pass模块写两遍?如果更多的REAL-SERVER呢?针对这个问题,nginx早就已经给了解决方法,解决方法其实很简单,把后端的多台REAL-SERVER定义到一个组里面,然后给组起一个名字,我们通过proxy_pass模块或者fastcgi模块进行调用时就用不着调用具体的REAL-SERVER,而是直接调用组即可。
nginx做代理会充当客户端访问后端的REAL-SERVER,那么当proxy_pass模块将请求交给REAL-SERVER组之后,REAL-SERVER又该如何分配呢?其实我们在REAL-SERVER里面可以定义分配算法,有些算法虽然和LVS的算法名字不太一样,但是功能是一样的。
upstream模块用于定义REAL-SERVER成员,表示格式如下:
-
IP[:PORT],我们通常用这种格式
-
HOSTNAME[:PORT]
upstream模块常用参数:
weight=number,权重,默认为1;
max_fails=number,失败尝试最大次数;超出此处指定的次数时,server将被标记为不可用;默认一次。 fail_timeout=time,设置将服务器标记为不可用状态的超时时长;默认10秒
max_conns,当前的服务器的最大并发连接数;
backup,将服务器标记为“备用”,即所有服务器均不可用时此服务器才启用;
down,标记为“不可用”,做灰度发布的时候可以用一用试试。
//例如
vim nginx.conf
upstream etiantian {
server 192.168.80.12:80 down;
server 192.168.80.13:80 backup;
server 192.168.80.15:80 fail_timeout=1 max_fails=3;
server 192.168.80.16:80 max_conns=2000;
server 192.168.80.17:80 weight=3 max_conns=2000;
}
server {
listen 80;
location /{
proxy_pass http://etiantian;
}
}
nginx负载均衡的缺点:
nginx可实现基于IP、cookie、uri等来做持久会话,但是社区版的nginx不支持基于cookie做会话保持。
而且nginx也不支持慢启动。
以下两个就是nginx的缺点,但haproxy都支持。
慢启动:
当我们把一台REAL-SERVER加入到upsteam模块当中时,正常的情况下如果不加权重,数据一下就会涌入到新加入的这台主机,它有可能会一下抗不住这么大的压力而宕机,慢启动的意思就是新加入的主机可以逐步的涌入数据,不要一下子涌入那么多。
关于算法:
upstream模块默认是rr算法,如果在主机后面加上权重就变成wrr算法了,此外nginx还支持sh算法,下面就演示一下:
upstream etiantian {
ip_hash; #等同于hash remote_addr;
server 192.168.80.12:80 down;
server 192.168.80.15:80 fail_timeout=1 max_fails=3;
server 192.168.80.16:80 max_conns=2000;
server 192.168.80.17:80 weight=3 max_conns=2000;
}
以上是三个静态算法,下面演示一下nginx的动态算法:
upstream etiantian {
least_conn; #最少连接算法lc,当有权限时就变成了wlc算法
server 192.168.80.12:80 down;
server 192.168.80.15:80 fail_timeout=1 max_fails=3;
server 192.168.80.16:80 max_conns=2000;
server 192.168.80.17:80 weight=3 max_conns=2000;
}
nginx负载均衡里面最值得说的算法就是hash key,这个hash真的是什么都能hash,一旦hash了,持会话的,在上面我们用它hsh了$remote_addr就等价于sh算法,此外我们还可以用它来哈希uri,这就相当于根据uri来负载均衡。
upstream etiantian {
hash $request_uri;
server 192.168.80.12:80 down;
server 192.168.80.15:80 fail_timeout=1 max_fails=3;
server 192.168.80.16:80 max_conns=2000;
server 192.168.80.17:80 weight=3 max_conns=2000;
}
那它的原理是什么呢?虽然LVS和nginx都有hash相关的内容,但此处的hash的方式之前的所有方式都不同,其中和nginx缓存的hash与LVS的SH算法的hash计算是一样的,都是通过计某个字符串(IP或URI)形成另一串16进制的字符串当做键,值对应的就是具体的内容,SH算法当中键对应的值就是后端的REAL-SERVER,nginx缓存当中键对应的值就直接是硬盘当中的数据块,而此处的hash值对应的不再是具体的内容,而变成uri哈希过的一的十六进制数与REAL-SERVER权重之和取模的值,比如REAL-SERVER有两台:A和B,A的权重是2,B的权重是1,A占两份(相当于两台REAL-SERVER),B占一份(相当于一台REAL-SERVER),它们的权重之和是3,十六进制与三取模有三种可能性,0,1,2,这三种,0,1,2分别代表着后面的三台REAL-SERVER。如果uri与权重取模之后的结果是0,那就给A REAL-SERVER;如果uri与权重取模之后的结果是1,还是给A REAL-SERVER,因为A主机占两份嘛;如果是2的话就得给BREAL-SERVER,为什么不用哈希表了呢?还是因为哈希表比较占用内存空间。
我们在nginx代理与REAL-SERVER之间再加一层varnish做缓存也是同样的道理,这种架构反而比较常见。
这种算法存在一种巨大的缺陷,就是如果B主机宕机了,那现在就是十六进制数与权重之和取模,有两种可能性,0或1,那么之前被B主机服务的URI全都调用 到了A主机上(假设这里的主机已经换成了varnish,之前的REAL-SERVER后移了),那之前的会话就不见了!一下子丢失了三分之一的会话内容,这其实不要紧,要紧的是因为没有会话,那丢失会话的连接就得通过varnish向后端的REAL-SERVER发起大量的请求,后面的REAL-SERVER很有可能一下子被压跨,这就形成了雪崩!!!!一个用词请求都无法响应了。
后来伯克利一名教授发明了一种算法:一致性HASH算法,来解决这个雪崩问题,至于这个算法我们没有必须知道,我们之要知道用了这个算法之后可以有效的减轻了一台REAL-SERVER崩溃了之后,余下的REAL-SERVER因为一下子无法接收这么多的并发而导致的宕机问题。我们可以通过consistent参数调用这种算法,如下所示:
upstream etiantian {
hash $request_uri consistent;
server 192.168.80.12:80 down;
server 192.168.80.15:80 fail_timeout=1 max_fails=3;
server 192.168.80.16:80 max_conns=2000;
server 192.168.80.17:80 weight=3 max_conns=2000;
}
server {
listen 80;
location /{
proxy_pass http://etiantian;
}
}
这种算法也有一个问题,就是消耗的CPU比较多,至于是否应该使用,我们应该具体场景具体分析。
还有最后一个常见的参数:keepalive connections,为每个worker进程保留的空闲的长连接数量;
upstream etiantian {
keepalive 32;
hash $request_uri consistent;
server 192.168.80.12:80 down;
server 192.168.80.15:80 fail_timeout=1 max_fails=3;
server 192.168.80.16:80 max_conns=2000;
server 192.168.80.17:80 weight=3 max_conns=2000;
}
这个长连接指的是nginx负载均衡到后端的varnish或者是REAL-SERVE的长连接个数,注意,是每个worker的长连接个数,这个最好开启。
二、操作
理解负载
//平均负载
upstream etiantian { #负载给哪些服务器,后面etiantian是名字,随便起,默认是平均负载。
server 192.168.80.100:80;
server 192.168.80.122:80;
server 192.168.80.133:80;
}
server {
listen 80;
server_name www.zhanghe.com;
location / {
proxy_pass http://etiantian; #通过这里关联到上面
}
}
上面的这个配置的意思就是当用户来访问www.zhanghe.com的时候,会分发到另外三台主机。
//权重
upstream etiantian {
server 192.168.80.100:80 weight=3;
server 192.168.80.122:80 weight=2;
server 192.168.80.133:80 weight=1;
}
server {
listen 80;
server_name www.zhanghe.com;
location / {
proxy_pass http://etiantian;
}
}
//热备功能
upstream etiantian {
server 192.168.80.100:80 ;
server 192.168.80.122:80 ;
server 192.168.80.133:80 backup;
}
server {
listen 80;
server_name www.zhanghe.com;
location / {
proxy_pass http://etiantian;
}
}
如果查看负载均衡把数据包扔给哪个后面服务器了呢?通过抓包软件就可以看到,wireshark或tcpdump
理解另外三个模块
proxy_set_header Host $host;
这个模块一看名字就知道作用了,让负载均衡发送给后端nginx的http头部携带host参数,默认是不带的,如果不带的话就会出现一个问题,什么问题呢?就是一个服务器可能有两个站点(假设用的是域名区分),都是侦听相同的套接字:IP+端口,那就会无法区分,客户端访问的时候只会进入第一个站点,当我们用上这个模块之后,负载均衡向后端请求时,会携带上客户端要访问的域名,这样的话就不会出现傻傻分不清楚的现象 了。
proxy_set_header X-Forwarded-For $remote_addr;
负载均衡服务器给客户端代理的时候并不是转发,而是自己做为客户端然后去访问后端的服务器,这样的话,源IP就是负载均衡自己,这样的话,后端服务器收到的请求就一直是负载均衡自己,这本来没有啥问题,但是如果是要在后端服务器上做数据统计的话呢?所以要加上这个模块,这样模块的作用就是让负载均衡再做转发的时候要附加 上真实客户端的IP地址,方便做数据统计.
在nginx日志里面可以加上这个参数,就可以看到真实的客户端IP了。
proxy_next_upstream error timeout http_404 http_502 http_403;
在负载正常的情况下,假设有一台后端的服务器出了问题,这个问题并不是服务器挂了,如果挂了负载均衡就自动探测到后端服务器挂了,就不会把用户的请求发送给挂掉的服务器,这里说的故障是指软故障,比如权限问题,找不到页面这些,这样的话负载均衡就无法探测到,那么返回给用户的界面可能一回是正常的服务器,一会就是异常的服务器,这样用户体验非常不好,怎么办呢?加上这个错误模块,这个错误模块可以实现这样的功能,当代替用户进行访问服务器的时候会先看一下里面的状态码,如果是异常状态吗:403、502、404这样的,就不会再返回给用户了,而是丢弃掉,使用另一台正常运行的服务器。
三、动静分离

为什么要动静分离?
大型网站都是动静分离的,静态和动态不是一个集群,比如像京东,假设京东的动态集群挂了,那京东仍然可以访问,浏览商品没问题,只不过不能下单了。
如果没有集群分类,上传目录和查看目录都在一个目录下面,用户对只应该有查看的目录却有上传的权限,这样不安全呀,应该把用户上传的东西专门放到一个上传集群上面,这个集群可以有上传的权限,而查看的目录就不能给上传的权限。
如何实现动静分离?
我们看一下京东是如何实现动静分离的,当我们注册一个京东账号的时候,将要发生的操作由读(浏览器商品)变成了写(向京东的 数据库写入数据),这个时候URL也会发生变化,京东的负载均衡收到这个不同的URL之后,会将其引入到数据库集群,而浏览商品的静态请求会引入到其它的集群,动静分离就是通过URL来控制的。
upstream upload{
server 10.0.0.8:80;
}
upstream sttaic{
server 10.0.0.7:80;
}
upstream default{
server 10.0.0.9:80;
}
server{
listen 80;
servername www.zhanghe.com;
location / {
proxy_pass http://default;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_next_upstream error timeout http_404 http_502 http_403;
}
location /upload {
proxy_pass http://upload;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_next_upstream error timeout http_404 http_502 http_403;
}
location /static {
proxy_pass http://static;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_next_upstream error timeout http_404 http_502 http_403;
}
}
总结:
-
动静分离可以提高网站服务安全性
-
管理操作工作简化
-
可以换分不同人员管理不同的集群服务
四、区分终端
通过不同的终端类似引导到不同的集群当中,通过if模块可以实现,如下所示:
pstream web{
server 10.0.0.8:80;
}
upstream mobile{
server 10.0.0.7:80;
}
upstream default{
server 10.0.0.9:80;
}
server{
listen 80;
servername www.zhanghe.com;
location / {
if ($http_user_agent ~* iphone){
proxy_pass http://mobile;
}
if ($http_user_agent ~* Chrome){
proxy_pass http://web;
}
proxy_pass http://default;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_next_upstream error timeout http_404 http_502 http_403;
}
}
五、负载均衡算法
LVS的负载均衡的算法共十种,又分为动态和静态两种。静态方法四种,动态方法六种。
静态方法与动态方法有什么区别呢?
静态方法就是明确告诉LVS怎么做,LVS不懂得变通,不会根据后端RS忙闲进行调整。
动态方法会根据后端RS的忙闲进行相当的调整。
静态方法
静态方法:仅根据算法本身进行调度。
- RR:round robin(轮询
轮询就是用户的请求平均分配,轮着来,你一个,我一个,非常容易理解。
- weighted RR:加权轮询
我们可以定义一个权重,比如对于性能高的服务器给它一个大的权重,然后给性能低服务器一个小的权重,这样用户的请求到来之后,就会根据权重进行分配,并不会进行平均分配。从这个角度来看,轮询就是一个特殊的加权,加权的比重为1:1。
- SH:source hashing
源IP地址哈希,将来自同一个IP地址的请求始终发往同一个RS,从而实现会话绑定,但是这种绑定是有缺陷的,假如用户是用S-NAT访问的话,这种源地址哈希就不好使了。
- DH:destination hashing
目标地址哈希,将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型的使用场景是正向代理缓存场景中的负载均衡,如宽带运营商。
目标地址哈希有点难以理解,企业里面很少使用目标地址哈希,通常使用的都是运营商。
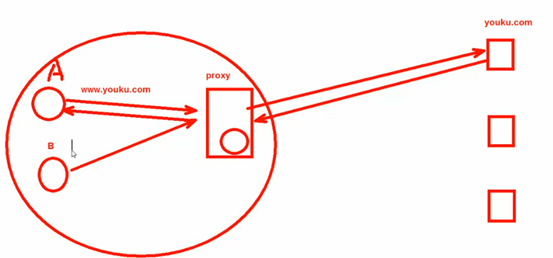
在世界杯举办期间一个大型小区(小区里面有运营商)里面很多用户都要访问优酷观看世界杯,优酷为了保证用户的观看体验,所以在小区的网络出口处放置了一个代理服务器。当其中一个用户观看世界杯视频时,proxy会缓存一份在本地,那么当第二个用户再去优酷观看世界杯的视频时,这时候缓存服务器直接从缓存里面给他了,这样就不用去youku.com里面去拿了,proxy是如何区分的呢?就是通过目标IP地址哈希。
proxy是正向代理服务器,正向代理服务器距离客户端比较近。
动态方法
动态方法:主要根据每RS当前的负载状态及调度算法进行调度overhead=value,较小的RS将被调度
- LC:least connections最少连接调度算法
哪台服务器的连接数最小就向哪台服务器调度,如何判断谁的连接比较少呢?通过下面的公式,值越小越优先接受连接。
overhead=activeconnes256+inactiveconns #活动的连接256+非活动的连接
非活动连接就是握手完成之后不干别的事情。
这种算法有个缺点,缺点就是这个公式太简单粗暴了,仅根据连接数去判断,假如说A设备连接了500条用户请求资源已经快用完了,而B设备因为性能好连接了600条请求之后占用了整体资源的一半都不到,如果再有用户连接,按理应该给B设备,B设备还有很多资源没有用上,但是如果根据“最小连接数算法”就应该给A设备,因为A设备的连接数更少,不科学~,怎么办呢?加上权重就可以了,那就是下面的算法。
- WLC:weighted LC(默认调度算法)
(activeconns*256+inactiveconns)/weight
(活动的连接*256+非活动的连接)/权重
性能好的机器我们就给它大一些权重,性能差的机器我们就给他少一些的权重。
假如现在有三台RS:A/B/C,连接数分别是100/200/300,权重分别是2:3:5,没有非活动连接。
A:(100*256+0)/2=12800(优先接受用户请求)
B:(200*256+0)/3=17266
C:(300*256+0)/5=15360
这个算法也有一个缺点,啥缺点呢?刚开始的时候,所有的RS一个连接都没有的时候,情况是这样的:
A:(0*256+0)/2=0
B:(0*256+0)/3=0
C:(0*256+0)/5=0
蒙圈了,全都是零,昨办呢?
如果真的是这样的话,谁先加入到LVS里面就会先给谁?这样不科学呀!我们加入的时候并不是根据权重去加的呀,如果真的这样的话,性能不好的服务器反而成了优先响应的服务器,这样并不很合理,所以又有下面的算法。
- SED:shortest expectioni delay,初始连接高权重优先
这种的算法的目的就是让权重高的服务器优先接受用户的请求,怎么搞呢?在上一个算法公式的基础上加上1就好了。
overhead=(activeconns+1)*256/weight
(活动的连接+1)*256/权重
A:(0+1)*256/2=128
B:(0+1)*256/3=85
C:(0+1)*256/5=51(权重最大的接受连接,这是我们想要的结果)
新的问题又来了,如果权重设置的比较极端呢?比如。
假如现在有三台RS:A/B/C,连接数分别是100/200/300,权重分别是1:1:10,没有非活动连接。
A:(0+1)*256/1=256
B:(0+1)*256/1=256
C:(0+1)*256/10=25.6(权重最大的接受连接,这是我们想要的结果)
但是二次呢?如下
A:(0+1)*256/1=256
B:(0+1)*256/1=256
C:(1+1)*256/10=51.2(第二次依然是权重最大的接受连接,还可以接受)
如果依次类推的话,10次之前都是权重最大的服务器优先接受连接,而A和B都没有干活!咱不能老是按着一个服务器欺负呀!所以这样也不是太科学。
所以又出了第四种算法,如下。
- NQ:never queue:第一轮均匀分配,后续SED
这种算法的在第一轮的时候,不按照任何算法,第一轮平均分配请求,一机一个, 这样的话,第一轮完成之后再使用SED算法。
A:(1+1)*256/1=512
B:(1+1)*256/1=512
C:(1+1)*256/10=51.2(权重最大的接受连接,这是我们想要的结果)
- LBLC:locality-based LC,动态的DH算法。
使用场景:根据负载状态实现正向代理
还是那个看世界杯的场景,优酷独家,可能导致某一台优酷代理压力过大,动态的DH的算法会将一些请求强行引导到其它的代理上,不会一直按着一台代理连接不放,导致其压力过大,可以动态调整。
注意,这是根据负载状态来实现的,也就是当一台代理的负载过大时,才会将一些用户请求引导到其它的代理上,这种做法是被动的,是逼不利己的,有没有更好的算法呢?有的,就是第六种算法:带复制功能的LBLC。
- LBLCR:LBLC with replication
带复制功能的LBLC,解决LBLC负载不均衡的问题,从负载重的复制到负载轻的RS。
带复制功能的LBLC比LBLC更主动了,不用等到负载过大才会将数据引流到其它代理上,当其发现某个资源被访问的比较频繁时,主动引导流量到其他代理上。
