

决策树ID3算法--python实现
参考:
统计学习方法》第五章决策树】 http://pan.baidu.com/s/1hrTscza



1 #coding:utf-8 2 # ID3算法,建立决策树 3 import numpy as np 4 import math 5 import uniout 6 ''' 7 #创建数据集 8 def creatDataSet(): 9 dataSet = np.array([[1,1,'yes'], 10 [1,1,'yes'], 11 [1,0,'no'], 12 [0,1,'no'], 13 [0,1,'no']]) 14 features = ['no surfaceing', 'fippers'] 15 return dataSet, features 16 ''' 17 18 #创建数据集 19 def createDataSet(): 20 dataSet = np.array([['青年', '否', '否', '否'], 21 ['青年', '否', '否', '否'], 22 ['青年', '是', '否', '是'], 23 ['青年', '是', '是', '是'], 24 ['青年', '否', '否', '否'], 25 ['中年', '否', '否', '否'], 26 ['中年', '否', '否', '否'], 27 ['中年', '是', '是', '是'], 28 ['中年', '否', '是', '是'], 29 ['中年', '否', '是', '是'], 30 ['老年', '否', '是', '是'], 31 ['老年', '否', '是', '是'], 32 ['老年', '是', '否', '是'], 33 ['老年', '是', '否', '是'], 34 ['老年', '否', '否', '否']]) 35 features = ['年龄', '有工作', '有自己房子'] 36 return dataSet, features 37 38 #计算数据集的熵 39 def calcEntropy(dataSet): 40 #先算概率 41 labels = list(dataSet[:,-1]) 42 prob = {} 43 entropy = 0.0 44 for label in labels: 45 prob[label] = (labels.count(label) / float(len(labels))) 46 for v in prob.values(): 47 entropy = entropy + (-v * math.log(v,2)) 48 return entropy 49 50 #划分数据集 51 def splitDataSet(dataSet, i, fc): 52 subDataSet = [] 53 for j in range(len(dataSet)): 54 if dataSet[j, i] == str(fc): 55 sbs = [] 56 sbs.append(dataSet[j, :]) 57 subDataSet.extend(sbs) 58 subDataSet = np.array(subDataSet) 59 return np.delete(subDataSet,[i],1) 60 61 #计算信息增益,选择最好的特征划分数据集,即返回最佳特征下标 62 def chooseBestFeatureToSplit(dataSet): 63 labels = list(dataSet[:, -1]) 64 bestInfoGain = 0.0 #最大的信息增益值 65 bestFeature = -1 #******* 66 #摘出特征列和label列 67 for i in range(dataSet.shape[1]-1): #列 68 #计算列中,各个分类的概率 69 prob = {} 70 featureCoulmnL = list(dataSet[:,i]) 71 for fcl in featureCoulmnL: 72 prob[fcl] = featureCoulmnL.count(fcl) / float(len(featureCoulmnL)) 73 #计算列中,各个分类的熵 74 new_entrony = {} #各个分类的熵 75 condi_entropy = 0.0 #特征列的条件熵 76 featureCoulmn = set(dataSet[:,i]) #特征列 77 for fc in featureCoulmn: 78 subDataSet = splitDataSet(dataSet, i, fc) 79 prob_fc = len(subDataSet) / float(len(dataSet)) 80 new_entrony[fc] = calcEntropy(subDataSet) #各个分类的熵 81 condi_entropy = condi_entropy + prob[fc] * new_entrony[fc] #特征列的条件熵 82 infoGain = calcEntropy(dataSet) - condi_entropy #计算信息增益 83 if infoGain > bestInfoGain: 84 bestInfoGain = infoGain 85 bestFeature = i 86 return bestFeature 87 88 #若特征集features为空,则T为单节点,并将数据集D中实例树最大的类label作为该节点的类标记,返回T 89 def majorityLabelCount(labels): 90 labelCount = {} 91 for label in labels: 92 if label not in labelCount.keys(): 93 labelCount[label] = 0 94 labelCount[label] += 1 95 return max(labelCount) 96 97 #建立决策树T 98 def createDecisionTree(dataSet, features): 99 labels = list(dataSet[:,-1]) 100 #如果数据集中的所有实例都属于同一类label,则T为单节点树,并将类label作为该结点的类标记,返回T 101 if len(set(labels)) == 1: 102 return labels[0] 103 #若特征集features为空,则T为单节点,并将数据集D中实例树最大的类label作为该节点的类标记,返回T 104 if len(dataSet[0]) == 1: 105 return majorityLabelCount(labels) 106 #否则,按ID3算法就计算特征集中各特征对数据集D的信息增益,选择信息增益最大的特征beatFeature 107 bestFeatureI = chooseBestFeatureToSplit(dataSet) #最佳特征的下标 108 bestFeature = features[bestFeatureI] #最佳特征 109 decisionTree = {bestFeature:{}} #构建树,以信息增益最大的特征beatFeature为子节点 110 del(features[bestFeatureI]) #该特征已最为子节点使用,则删除,以便接下来继续构建子树 111 bestFeatureColumn = set(dataSet[:,bestFeatureI]) 112 for bfc in bestFeatureColumn: 113 subFeatures = features[:] 114 decisionTree[bestFeature][bfc] = createDecisionTree(splitDataSet(dataSet, bestFeatureI, bfc), subFeatures) 115 return decisionTree 116 117 #对测试数据进行分类 118 def classify(testData, features, decisionTree): 119 for key in decisionTree: 120 index = features.index(key) 121 testData_value = testData[index] 122 subTree = decisionTree[key][testData_value] 123 if type(subTree) == dict: 124 result = classify(testData,features,subTree) 125 return result 126 else: 127 return subTree 128 129 130 if __name__ == '__main__': 131 dataSet, features = createDataSet() #创建数据集 132 decisionTree = createDecisionTree(dataSet, features) #建立决策树 133 print 'decisonTree:',decisionTree 134 135 dataSet, features = createDataSet() 136 testData = ['老年', '是', '否'] 137 result = classify(testData, features, decisionTree) #对测试数据进行分类 138 print '是否给',testData,'贷款:',result
相关理论:
决策树
概念原理
决策树是一种非参数的监督学习方法,它主要用于分类和回归。决策树的目的是构造一种模型,使之能够从样本数据的特征属性中,通过学习简单的决策规则——IF THEN规则,从而预测目标变量的值。
决策树学习步骤:1 特征选择 2 决策树的生成 3 决策树的修剪
那么如何进行特征选择:
由于特征选择的方法不同,衍生出了三种决策树算法:ID3、C4.5、CART
ID3信息增益

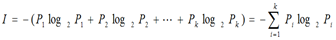 熵越大,随机变量的不确定性越大。
熵越大,随机变量的不确定性越大。
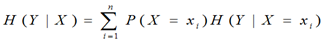 条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。所谓信息量,就是熵。
C4.5信息增益比

CART 基尼指数
 基尼指数越大,样本的不确定性就越大
基尼指数越大,样本的不确定性就越大
三个算法的优缺点
|
ID3算法 |
C4.5算法 |
CART算法(Classification and Regression Tree) |
|
以信息增益为准则选择信息增益最大的属性。 2)ID3只能对离散属性的数据集构造决策树。 |
以信息增益率为准则选择属性;在信息增益的基础上对属性有一个惩罚,抑制可取值较多的属性,增强泛化性能。 1)在树的构造过程中可以进行剪枝,缓解过拟合; 2)能够对连续属性进行离散化处理(二分法); 3)能够对缺失值进行处理; |
顾名思义,可以进行分类和回归,可以处理离散属性,也可以处理连续的。 |
ID3、C4.5、CART区别 参考:https://www.zhihu.com/question/27205203?sort=created




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY