

KNN算法--python实现
邻近算法
或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
关于K最近邻算法,非常好的一篇文章:KNN算法理解; 另外一篇文章也值得参考:KNN最近邻Python实现
行业应用: 客户流失预测、欺诈侦测等(更适合于稀有事件的分类问题)
写在前面的:Python2.7
数据iris: http://pan.baidu.com/s/1bHuQ0A 测试数据集: iris的第1行数据; 训练数据: iris的2到150行数据

1 #coding:utf-8 2 import pandas as pd 3 import numpy as np 4 5 class KNNa(object): 6 7 #获取训练数据集 8 def getTrainData(self): 9 dataSet = pd.read_csv('C:\pythonwork\practice_data\iris.csv', header=None) 10 dataSetNP = np.array(dataSet[1:150]) 11 trainData = dataSetNP[:,0:dataSetNP.shape[1]-1] #获得训练数据 12 labels = dataSetNP[:,dataSetNP.shape[1]-1] #获得训练数据类别 13 return trainData,labels 14 #得到测试数据的类别 15 def classify(self, testData, trainData, labels, k): 16 #计算测试数据与训练数据之间的欧式距离 17 dist = [] 18 for i in range(len(trainData)): 19 td = trainData[i,:] #训练数据 20 dist.append(np.linalg.norm(testData - td)) #欧式距离 21 dist_collection = np.array(dist) #获得所有的欧氏距离,并转换为array类型 22 dist_index = dist_collection.argsort()[0:k] #按升序排列,获得前k个下标 23 k_labels = labels[dist_index] #获得对应下标的类别 24 25 #计算k个数据中,类别的数目 26 k_labels = list(k_labels) #转换为list类型 27 labels_count = {} 28 for i in k_labels: 29 labels_count[i] = k_labels.count(i) #计算每个类别出现的次数 30 testData_label = max(labels_count, key=labels_count.get) #次数出现最多的类别 31 return testData_label 32 33 34 if __name__ == '__main__': 35 kn = KNNa() 36 trainData,labels = kn.getTrainData() #获得训练数据集,iris从第2行到第150行的149条数据 37 testData = np.array([5.1, 3.5, 1.4, 0.2]) #取iris中的数据的第1行 38 k = 10 #最近邻数据数目 39 testData_label = kn.classify(testData,trainData,labels,k) #获得测试数据的分类类别 40 print '测试数据的类别:',testData_label
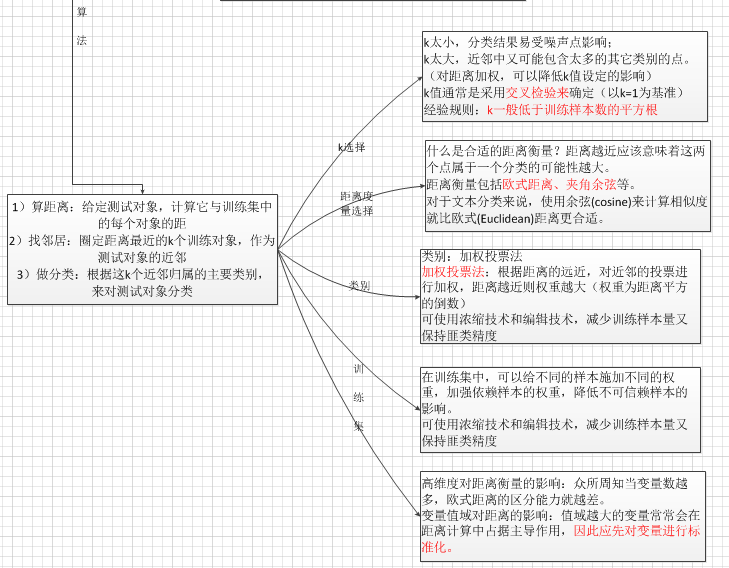
理论:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY