
1、HashSet简介
Set是一个继承于Collection的接口,即Set也是集合中的一种。Set是没有重复元素的集合。
HashSet是Set接口典型实现,它按照Hash算法来存储集合中的元素,具有很好的存取和查找性能。底层数据结构是哈希表。
哈希表即一个元素为链表的数组,综合了数组与链表的优点。
HashSet主要具有以下特点:
- 不保证set的迭代顺序
- HashSet不是同步的,如果多个线程同时访问一个HashSet,要通过代码来保证其同步
- 集合元素值可以是null,但只能有一个null
2、HashSet继承关系及实现的接口
2.1、结构图

HashSet的继承关系如下:
java.lang.Object ↳ java.util.AbstractCollection<E> ↳ java.util.AbstractSet<E> ↳ java.util.HashSet<E> public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { }
3、HashSet源码分析
3.1、属性
static final long serialVersionUID = -5024744406713321676L; //序列化ID private transient HashMap<E,Object> map; //底层使用HashMap来保存所有元素,确切说存储在map的key中,并使用transient关键字修饰,防止被序列化 // Dummy value to associate with an Object in the backing Map // private static final Object PRESENT = new Object(); //常量,构造一个虚拟的对象PRESENT,默认为map的value值(HashSet中只需要用到键,而HashMap是key-value键值对,使用PRESENT作为value的默认填充值,解决差异问题)
3.2 、构造方法
/** * Constructs a new, empty set; the backing {@code HashMap} instance has * default initial capacity (16) and load factor (0.75). * 构造一个新的,空的HashSet,其底层 HashMap实例的默认初始容量是 16,加载因子是 0.75 */ public HashSet() { map = new HashMap<>(); } /** * Constructs a new set containing the elements in the specified * collection. The {@code HashMap} is created with default load factor * (0.75) and an initial capacity sufficient to contain the elements in * the specified collection. * * 构造一个包含指定集合中元素的新HashSet * 对 HashMap 的容量进行了计算,在 16 和 给定值大小之间选择最大的值 * 此处用 (int) (c.size ()/.75f) + 1 来表示初始化的值 * @param c the collection whose elements are to be placed into this set * @throws NullPointerException if the specified collection is null */ public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); } /** * Constructs a new, empty set; the backing {@code HashMap} instance has * the specified initial capacity and the specified load factor. * * 构造一个指定初始容量和加载因子的HashSet * @param initialCapacity the initial capacity of the hash map * @param loadFactor the load factor of the hash map * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */ public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } /** * Constructs a new, empty set; the backing {@code HashMap} instance has * the specified initial capacity and default load factor (0.75). * * 构造指定初始容量的HashSet * @param initialCapacity the initial capacity of the hash table * @throws IllegalArgumentException if the initial capacity is less * than zero */ public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); } /** * Constructs a new, empty linked hash set. (This package private * constructor is only used by LinkedHashSet.) The backing * HashMap instance is a LinkedHashMap with the specified initial * capacity and the specified load factor. * 传入初始化容量 负载因子初始化,dummy相当于一个占位符 * 初始化底层使用了LinkedHashMap实现 * @param initialCapacity the initial capacity of the hash map * @param loadFactor the load factor of the hash map * @param dummy ignored (distinguishes this * constructor from other int, float constructor.) * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */ HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }
3.3、常用方法
/** * Returns an iterator over the elements in this set. The elements * are returned in no particular order. * 返回迭代器,实际上返回的是HashMap的"key集合的迭代器" * 从返回的是keySet可以看出HashSet中的元素,只是存放在底层HashMap的key上 * @return an Iterator over the elements in this set * @see ConcurrentModificationException */ public Iterator<E> iterator() { return map.keySet().iterator(); } /** * Returns the number of elements in this set (its cardinality). * 调用map的size方法返回HashSet中包含元素的个数 * * @return the number of elements in this set (its cardinality) */ public int size() { return map.size(); } /** * Returns {@code true} if this set contains no elements. * * 判断set是否不包含任何元素,是则返回true * @return {@code true} if this set contains no elements */ public boolean isEmpty() { return map.isEmpty(); } /** * Returns {@code true} if this set contains the specified element. * More formally, returns {@code true} if and only if this set * contains an element {@code e} such that * {@code Objects.equals(o, e)}. * * 如果set中包含指定元素,返回true(实际调用的是hashmap的containsKey()方法,) * @param o element whose presence in this set is to be tested * @return {@code true} if this set contains the specified element */ public boolean contains(Object o) { return map.containsKey(o); } /** * Adds the specified element to this set if it is not already present. * More formally, adds the specified element {@code e} to this set if * this set contains no element {@code e2} such that * {@code Objects.equals(e, e2)}. * If this set already contains the element, the call leaves the set * unchanged and returns {@code false}. * 如果此 set 中尚未包含指定元素,则添加指定元素 * 调用hashmap的put方法 * @param e element to be added to this set * @return {@code true} if this set did not already contain the specified * element */ public boolean add(E e) { return map.put(e, PRESENT)==null; } /** * Removes all of the elements from this set. * 移除此set中的所有元素 * The set will be empty after this call returns. */ public void clear() { map.clear(); }
4、内部存储机制
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。如果有两个元素通过equals方法比较为true,但它们的hashCode方法返回的值不相等,HashSet将会把它们存储在不同位置,依然可以添加成功。
也就是说。HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode方法返回值也相等。
靠元素重写hashCode方法和equals方法来判断两个元素是否相等,如果相等则覆盖原来的元素,以此来确保元素的唯一性。
应用示例:
Person类,此时没有重写hashCode和equals方法
public class Person { private String name; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
测试代码
public class Demo03HashSetSavePerson { public static void main(String[] args) { //创建HashSet集合存储Person HashSet<Person> set = new HashSet<>(); Person p1 = new Person("红花", 20); Person p2 = new Person("红花", 20); Person p3 = new Person("红花", 21); //没有重写hashCode方法和equals方法之前 System.out.println(p1.hashCode()); System.out.println(p2.hashCode()); System.out.println(p1 == p2); //false 可以看到p1和p2的hashCode不同 System.out.println(p1.equals(p2)); //false 自定义类在没有重写equals方法时,equals比较的是引用的是不是同一块地址 set.add(p1); set.add(p2); set.add(p3); Iterator<Person> itr = set.iterator(); while (itr.hasNext()) { System.out.println(itr.next()); } } }
运行结果
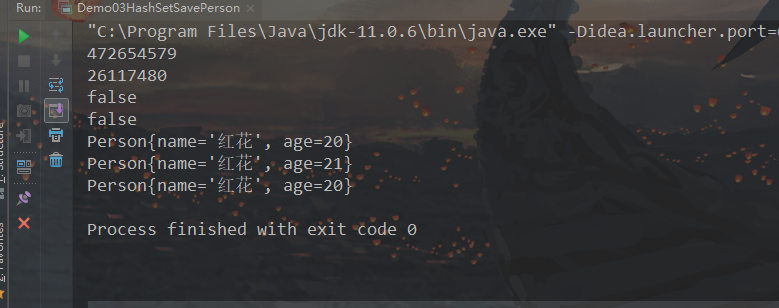
可以看到在没有重写Person类的hashCode和equals方法的情况下,集合中出现重复元素。
现在重写Person类的hashCode和equals方法
public class Person { private String name; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } //判断两个对象是否相等,对象是否存在,对象的name和age是否相等 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return age == person.age && Objects.equals(name, person.name); } //返回对象的name和age的hash值 @Override public int hashCode() { return Objects.hash(name, age); } }
测试代码
public class Demo03HashSetSavePerson { public static void main(String[] args) { //创建HashSet集合存储Person HashSet<Person> set = new HashSet<>(); Person p1 = new Person("红花", 20); Person p2 = new Person("红花", 20); Person p3 = new Person("红花", 21); Person p4 = new Person("绿叶", 21); //重写hashCode方法和equals方法之后 System.out.println(p1.hashCode()); System.out.println(p2.hashCode()); System.out.println(p1 == p2); //false 自定义类在重写equals方法后,==比较的是引用的是不是同一块内存地址 System.out.println(p1.equals(p2)); //true 自定义类在重写equals方法后,equals比较的是引用的对象内容是否相同 set.add(p1); set.add(p2); set.add(p3); set.add(p4); Iterator<Person> itr = set.iterator(); while (itr.hasNext()) { System.out.println(itr.next()); } } }
运行结果
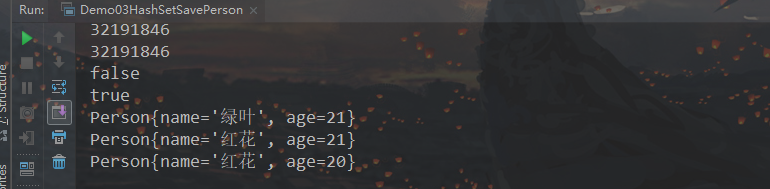
可以看到在重写hashCode和equals方法之后,hashCode相同而且equals方法返回true,则两个对象判断同一对象,不会重复出现在集合中。
为什么不直接使用数组,而用HashSet呢?
因为数组的索引是连续的而且数组的长度是固定的,无法自由增加数组的长度。而HashSet就不一样了,HashCode表用每个元素的hashCode值来计算其存储位置,从而可以自由增加HashCode的长度,并根据元素的hashCode值来访问元素。而不用一个个遍历索引去访问,这就是它比数组快的原因。
图解哈希表存储原理

LinkedHashSet类
HashSet还有一个子类LinkedList、LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说当遍历集合LinkedHashSet集合里的元素时,集合将会按元素的添加顺序来访问集合里的元素。
输出集合里的元素时,元素顺序总是与添加顺序一致。但是LinkedHashSet依然是HashSet,因此它不允许集合重复。
以上参考整理自以下出处
https://blog.csdn.net/mashaokang1314/article/details/83721792
https://www.cnblogs.com/xujian2014/p/4643759.html
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号