

1、Java IO简介:
IO,即in和out,对应输入和输出,指应用程序和外部设备之间的数据传递。常见的外部设备包括文件、管道、网络连接。 在Java中,通过流来处理IO操作,那么什么是流呢?
流(Stream), 它是一个抽象的概念,是指一连串的数据(字符或字节)以先进先出的方式发送信息的通道。
当程序需要读取数据时,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或者是网络连接,当程序需要写入数据的时候,就会开启一
个通向目的地的流。我们可以想象成数据好像在"流动"一样。
关于流的特点:
- 先进先出:最先写入输出流的数据最想被输入流读取到
- 顺序存取:可以一个接一个的往流中写入一串字节,读出时按照写入顺序读取一串字节,不能随机访问中间的数据 ( RandomAccessFile 除外)
- 只读或只写:每个流只能是输入流或者输出流的一种,不能同时具备两个功能,输入流只能进行读操作,输出流只能进行写操作。如果在一个数据传输通道中,既要写入数据,又要读取数据,则要分别提供两个流。
1.1、IO流分类
-
-
- 按照数据流的方向:输入流、输出流
- 按处理数据单位:字节流、字符流
- 按功能:节点流、处理流
-
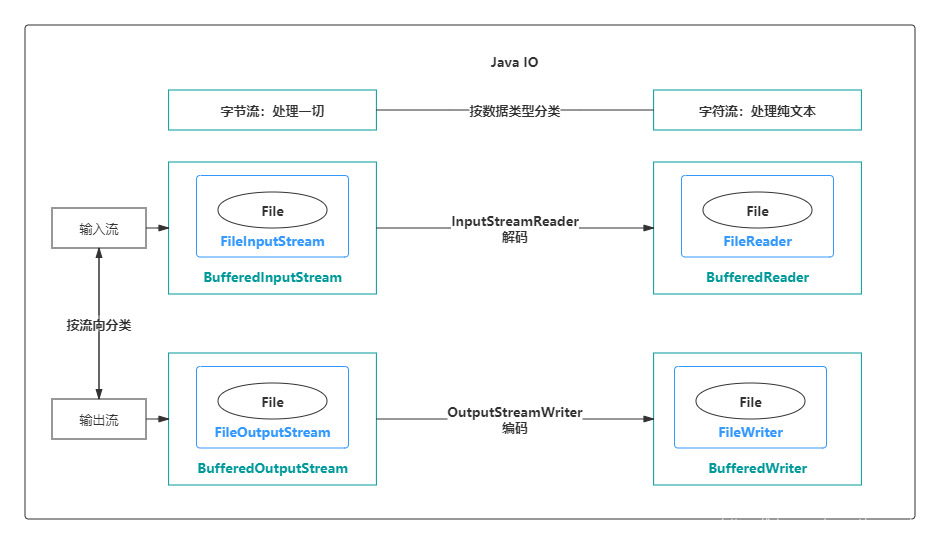
1、输入流与输出流
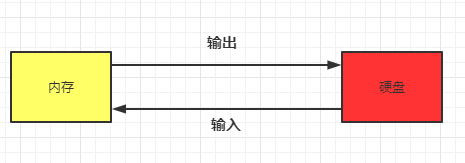
这里输入,输出涉及一个方向问题,划分输入/输出流时是从程序运行所在的内存的角度来考虑的。数据从内存写入到硬盘,用的是输出流,数据从
磁盘读到内存,用的是输入流。我们可以这么记忆,以内存为准,从内存出来的方向是输出,进入到内存的方向是输入。比如文件读写,读取
文件是输入流,写文件是输出流,这点很容易搞反。
2、字节流和字符流
字节流和字符流的用法几乎完全一样,区别在于字节流和字符流所操作的数据单元不同。

为什么需要字符流?
在Java中,字符是才采用Unicode标准,Unicode编码中,一个英文为一个字节,一个中文为两个字节。
在UTF-8编码中,一个中文字符是3个字节。例如下面图中,“云深不知处”5个中文对应的是15个字节:-28-70-111-26-73-79-28-72-115-25-97-91-27-92-124
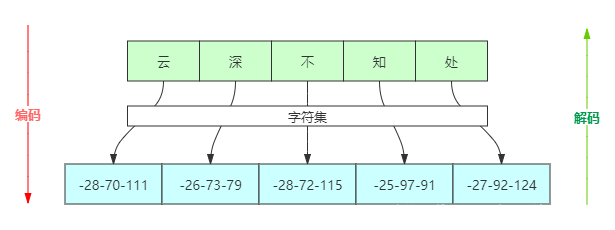
那么问题来了,如果使用字节流处理中文,如果一次读写一个字符对应的字节数就不会有问题,一旦将一个字符对应的字节分裂开来,就会出现乱码了。为了更方便地处理中文这些字符,Java就推出了字符流,以字符为单位来处理文本文件。
字节流和字符流的其他区别:
- 字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。字符流一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。用一句话说就是:字节流可以处理一切文件,而字符流只能处理纯文本文件。
- 字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。
查看字符流的write方法源码,发现确实有利用到缓冲区:

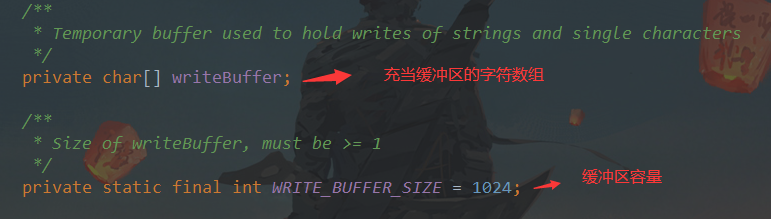
3、节点流和处理流
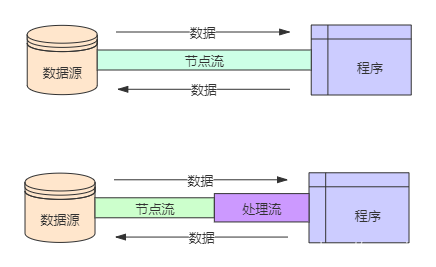
节点流:直接操作数据读写的流类,比如FileInputStream
处理流:对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能,例如BufferedInputStream (缓冲字节流)
节点流和处理流应用了Java的装饰者设计模式。
参考:https://www.cnblogs.com/of-fanruice/p/11565679.html
在诸多处理流中,有一个非常重要,那就是缓冲流。
我们知道,程序与磁盘的交互相对于内存运算是很慢的,容易成为程序的性能瓶颈。减少程序与磁盘的交互,是提升程序效率一种有效手段。缓冲流,就应用这种思路:普通流每次读写一个字节,而缓冲流在内存中设置一个缓存区,缓冲区先存储足够的待操作数据后,再与内存或磁盘进行交互。这样,在总数据量不变的情况下,通过提高每次交互的数据量,减少了交互次数。

加入缓冲区:
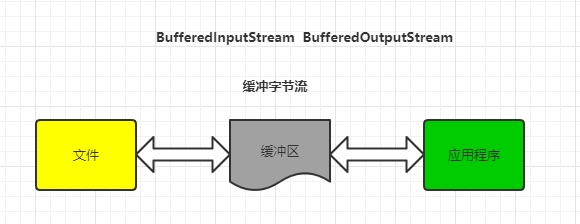
联想生活中例子,搬砖的时候,一块一块地往车上装肯定是很低效的。我们可以使用一个小推车,先把砖装到小推车上,再把这小推车推到车前,把砖装到车上。这个例子中,小推车可以视为缓冲区,小推车的存在,减少了我们装车次数,从而提高了效率。
完整的IO分类图如下:

1.2、案例实操
接下来,我们看看如何使用Java IO。
文本读写的例子,也就是文章开头所说的,将“松下问童子,言师采药去。只在此山中,云深不知处。" 写入本地文本,然后再从文件读取内容并输出到控制台。
1、FileInputStream、FileOutputStream(字节流)
字节流的方式效率较低,不建议使用
1 public class IOTest { 2 public static void main(String[] args) throws IOException { 3 File file = new File("D:/test.txt"); 4 5 write(file); 6 System.out.println(read(file)); 7 } 8 9 public static void write(File file) throws IOException { 10 OutputStream os = new FileOutputStream(file, true); 11 12 // 要写入的字符串 13 String string = "松下问童子,言师采药去。只在此山中,云深不知处。"; 14 // 写入文件 15 os.write(string.getBytes()); 16 // 关闭流 17 os.close(); 18 } 19 20 public static String read(File file) throws IOException { 21 InputStream in = new FileInputStream(file); 22 23 // 一次性取多少个字节 24 byte[] bytes = new byte[1024]; 25 // 用来接收读取的字节数组 26 StringBuilder sb = new StringBuilder(); 27 // 读取到的字节数组长度,为-1时表示没有数据 28 int length = 0; 29 // 循环取数据 30 while ((length = in.read(bytes)) != -1) { 31 // 将读取的内容转换成字符串 32 sb.append(new String(bytes, 0, length)); 33 } 34 // 关闭流 35 in.close(); 36 37 return sb.toString(); 38 } 39 }
2、BufferedInputStream、BufferedOutputStream(缓冲字节流)
缓冲字节流是为高效率而设计的,真正的读写操作还是靠FileOutputStream和FileInputStream,所以其构造方法入参是这两个类的对象也就不奇怪了。
1 public class IOTest { 2 3 public static void write(File file) throws IOException { 4 // 缓冲字节流,提高了效率 5 BufferedOutputStream bis = new BufferedOutputStream(new FileOutputStream(file, true)); 6 7 // 要写入的字符串 8 String string = "松下问童子,言师采药去。只在此山中,云深不知处。"; 9 // 写入文件 10 bis.write(string.getBytes()); 11 // 关闭流 12 bis.close(); 13 } 14 15 public static String read(File file) throws IOException { 16 BufferedInputStream fis = new BufferedInputStream(new FileInputStream(file)); 17 18 // 一次性取多少个字节 19 byte[] bytes = new byte[1024]; 20 // 用来接收读取的字节数组 21 StringBuilder sb = new StringBuilder(); 22 // 读取到的字节数组长度,为-1时表示没有数据 23 int length = 0; 24 // 循环取数据 25 while ((length = fis.read(bytes)) != -1) { 26 // 将读取的内容转换成字符串 27 sb.append(new String(bytes, 0, length)); 28 } 29 // 关闭流 30 fis.close(); 31 32 return sb.toString(); 33 } 34 }
3、InputStreamReader、OutputStreamWriter(字符流)
字符流适用于文本文件的读写,OutputStreamWriter类其实也是借助FileOutputStream类实现的,故其构造方法是FileOutputStream的对象
1 public class IOTest { 2 3 public static void write(File file) throws IOException { 4 // OutputStreamWriter可以显示指定字符集,否则使用默认字符集 5 OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(file, true), "UTF-8"); 6 7 // 要写入的字符串 8 String string = "松下问童子,言师采药去。只在此山中,云深不知处。"; 9 osw.write(string); 10 osw.close(); 11 } 12 13 public static String read(File file) throws IOException { 14 InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8"); 15 // 字符数组:一次读取多少个字符 16 char[] chars = new char[1024]; 17 // 每次读取的字符数组先append到StringBuilder中 18 StringBuilder sb = new StringBuilder(); 19 // 读取到的字符数组长度,为-1时表示没有数据 20 int length; 21 // 循环取数据 22 while ((length = isr.read(chars)) != -1) { 23 // 将读取的内容转换成字符串 24 sb.append(chars, 0, length); 25 } 26 // 关闭流 27 isr.close(); 28 29 return sb.toString() 30 } 31 }
4、字符流便捷类
Java提供了FileWriter和FileReader简化字符流的读写,new FileWriter等同于new OutputStreamWriter(new FileOutputStream(file, true))
1 public class IOTest { 2 3 public static void write(File file) throws IOException { 4 FileWriter fw = new FileWriter(file, true); 5 6 // 要写入的字符串 7 String string = "松下问童子,言师采药去。只在此山中,云深不知处。"; 8 fw.write(string); 9 fw.close(); 10 } 11 12 public static String read(File file) throws IOException { 13 FileReader fr = new FileReader(file); 14 // 一次性取多少个字节 15 char[] chars = new char[1024]; 16 // 用来接收读取的字节数组 17 StringBuilder sb = new StringBuilder(); 18 // 读取到的字节数组长度,为-1时表示没有数据 19 int length; 20 // 循环取数据 21 while ((length = fr.read(chars)) != -1) { 22 // 将读取的内容转换成字符串 23 sb.append(chars, 0, length); 24 } 25 // 关闭流 26 fr.close(); 27 28 return sb.toString(); 29 } 30 }
5、BufferedReader、BufferedWriter(字符缓冲流)
1 public class IOTest { 2 3 public static void write(File file) throws IOException { 4 // BufferedWriter fw = new BufferedWriter(new OutputStreamWriter(new 5 // FileOutputStream(file, true), "UTF-8")); 6 // FileWriter可以大幅度简化代码 7 BufferedWriter bw = new BufferedWriter(new FileWriter(file, true)); 8 9 // 要写入的字符串 10 String string = "松下问童子,言师采药去。只在此山中,云深不知处。"; 11 bw.write(string); 12 bw.close(); 13 } 14 15 public static String read(File file) throws IOException { 16 BufferedReader br = new BufferedReader(new FileReader(file)); 17 // 用来接收读取的字节数组 18 StringBuilder sb = new StringBuilder(); 19 20 // 按行读数据 21 String line; 22 // 循环取数据 23 while ((line = br.readLine()) != null) { 24 // 将读取的内容转换成字符串 25 sb.append(line); 26 } 27 // 关闭流 28 br.close(); 29 30 return sb.toString(); 31 } 32 }
2、 IO流对象
第一节中,我们大致了解了IO,并完成了几个案例,但对IO还缺乏更详细的认知,那么接下来我们就对Java IO细细分解,梳理出完整的知识体系来。
Java种提供了40多个类,我们只需要详细了解一下其中比较重要的就可以满足日常应用了。
2.1、File类
File类是用来操作文件的类,但它不能操作文件中的数据。
1 public class File extends Object implements Serializable, Comparable<File>
File类实现了Serializable、 Comparable<File>,说明它支持序列化和排序。
File类的构造方法
| 方法名 | 说明 |
| File(File parent, String child) | 根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。 |
| File(String pathname) | 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。 |
| File(String parent, String child) | 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。 |
| File(URI uri) | 通过将给定的 file: URI 转换为一个抽象路径名来创建一个新的 File 实例。 |
File类的常用方法
| 方法 | 说明 |
| createNewFile() | 当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。 |
| delete() | 删除此抽象路径名表示的文件或目录。 |
| exists() | 测试此抽象路径名表示的文件或目录是否存在。 |
| getAbsoluteFile() | 返回此抽象路径名的绝对路径名形式。 |
| getAbsolutePath() | 返回此抽象路径名的绝对路径名字符串。 |
| length() | 返回由此抽象路径名表示的文件的长度。 |
| mkdir() | 创建此抽象路径名指定的目录。 |
File类使用实例
public class FileTest { public static void main(String[] args) throws IOException { File file = new File("C:/Mu/fileTest.txt"); // 判断文件是否存在 if (!file.exists()) { // 不存在则创建 file.createNewFile(); } System.out.println("文件的绝对路径:" + file.getAbsolutePath()); System.out.println("文件的大小:" + file.length()); // 刪除文件 file.delete(); } }
2.2、字节流
InputStream与OutputStream是两个抽象类,是字节流的基类,所有具体的字节流实现类都是分别继承了这两个类。
以InputStream为例,它继承了Object,实现了Closeable
1 public abstract class InputStream 2 extends Object 3 implements Closeable
InputStream类有很多的实现子类,下面列举了一些比较常用的:

详细说明一下上图中的类:
InputStream:InputStream是所有字节输入流的抽象基类,前面说过抽象类不能被实例化,实际上是作为模板而存在的,为所有实现类定义了处理输入流的方法。FileInputSream:文件输入流,一个非常重要的字节输入流,用于对文件进行读取操作。PipedInputStream:管道字节输入流,能实现多线程间的管道通信。ByteArrayInputStream:字节数组输入流,从字节数组(byte[])中进行以字节为单位的读取,也就是将资源文件都以字节的形式存入到该类中的字节数组中去。FilterInputStream:装饰者类,具体的装饰者继承该类,这些类都是处理类,作用是对节点类进行封装,实现一些特殊功能。DataInputStream:数据输入流,它是用来装饰其它输入流,作用是“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。BufferedInputStream:缓冲流,对节点流进行装饰,内部会有一个缓存区,用来存放字节,每次都是将缓存区存满然后发送,而不是一个字节或两个字节这样发送,效率更高。ObjectInputStream:对象输入流,用来提供对基本数据或对象的持久存储。通俗点说,也就是能直接传输对象,通常应用在反序列化中。它也是一种处理流,构造器的入参是一个InputStream的实例对象。
OutputStream类继承关系图:
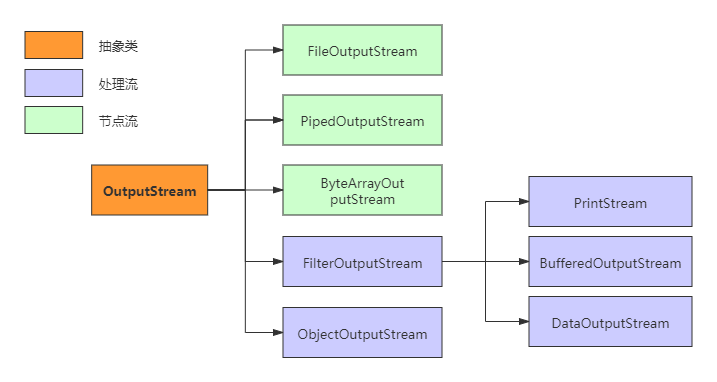
OutputStream类继承关系与InputStream类似,需要注意的是多了PrintStream.
2.3、字符流
与字节流类似,字符流也有两个抽象基类,分别是Reader和Writer。其他的字符流实现类都是继承了这两个类。
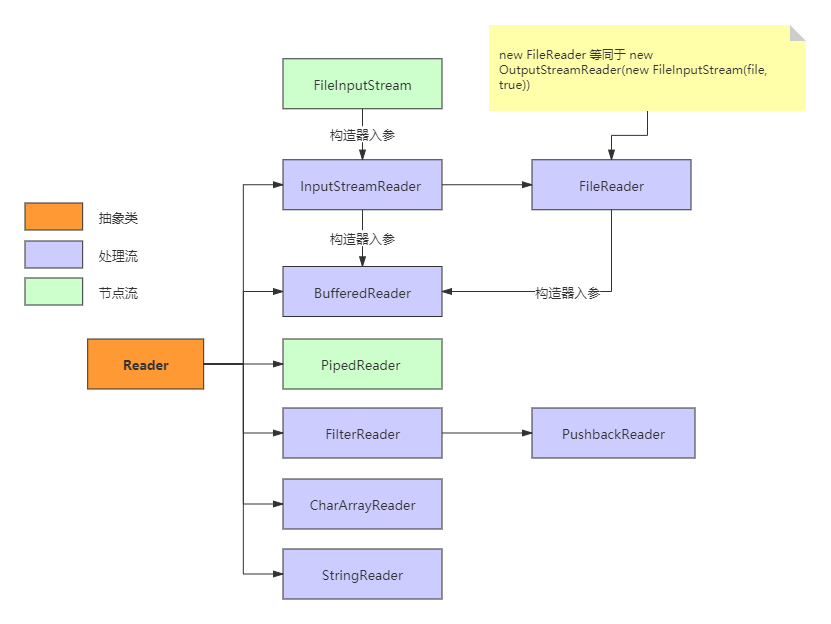
各个类的详细说明:
InputStreamReader:从字节流到字符流的桥梁(InputStreamReader构造器入参是FileInputStream的实例对象),它读取字节并使用指定的字符集将其解码为字符。它使用的字符集可以通过名称指定,也可以显式给定,或者可以接受平台的默认字符集。BufferedReader:从字符输入流中读取文本,设置一个缓冲区来提高效率。BufferedReader是对InputStreamReader的封装,前者构造器的入参就是后者的一个实例对象。FileReader:用于读取字符文件的便利类,new FileReader(File file)等同于new InputStreamReader(new FileInputStream(file, true),"UTF-8"),但FileReader不能指定字符编码和默认字节缓冲区大小。PipedReader:管道字符输入流。实现多线程间的管道通信。CharArrayReader:从Char数组中读取数据的介质流。StringReader:从String中读取数据的介质流。
Writer与Reader结构类似,方向相反。唯一有区别的是,Writer的子类PrintWriter
2.4、序列化与反序列化
2.4.1、序列化
Java进程运行时会把相关的类生成一堆实例,并放入堆栈空间中,如果进程执行结束,那么内存中的实例对象就会被gc回收。如果想在新的程序中使用之前那个对象,应该怎么办?
远程接口调用时,两端在各自的虚拟机中运行,因为内存是不共享的,那么入参和返回值如何传递?
序列化就是解决这个问题的。虽然内存不共享,但我们可以将对象转化为一段字节序列,并放到流中,接下来就交给 I/O,可以存储在文件中、可以通过网络传输……当我们想用到这些对象的时候,再通过 I/O,从文件、网络上读取字节序列,根据这些信息重建对象。而重建对象的过程也叫做“反序列化”。如果没有 “反序列化”,那么“序列化”是没有任何意义的。
用现实生活中的搬桌子为例,桌子太大了不能通过比较小的门,我们要把它拆了再运进去,这个拆桌子的过程就是序列化。同理,反序列化就是等我们需要用桌子的时候再把它组合起来,这个过程就是反序列化。
理解上面的背景知识后,序列化和反序列化概括起来就是下面这张图:

即序列化是一种用来 处理对象流 的机制,而 对象流 是将对象的内容进行流化。可以对流化后的对象 进行读写操作 ,也可将流化后的对象 传输于网络 之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现 Serializable接口(标记接口) ,该接口没有需要实现的方法,implements Serializable只是为了 标注 该对象是可被序列化的 ,然后用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象;接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
示例:
1 // ObjectOutputStream 对象输出流,将Person对象存储到E盘的Person.txt文件中,完成对Person对象的序列化操作 2 ObjectOutputStream oo = new ObjectOutputStream(new FileOutputStream(new File("E:/Person.txt")));
什么时候时候使用序列化呢?
-
-
- 对象序列化可以 实现分布式对象
-
主要应用例如:RMI (即远程调用Remote Method Invocation) 要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
-
-
- Java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。
-
可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的 "深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
-
-
- 序列化可以将内存中的类写入文件或数据库中。
-
比如:将某个类序列化后存为文件,下次读取时只需将文件中的数据 反序列化 就可以将原先的类还原到内存中。也可以将类序列化为流数据进行传输。总的来说就是 将一个已经实例化的类转成文件存储 ,下次需要实例化的时候只要反序列化即可将类实例化到内存中并保留序列化时类中的所有变量和状态。
-
-
- 对象、文件、数据,有许多不同的格式,很难统一传输和保存。
-
序列化以后就都是字节流了,无论原来是什么东西,都能 变成一样的东西 ,就可以进行通用的格式传输或保存,传输结束以后,要再次使用,就进行反序列化还原,这样对象还是对象,文件还是文件。
Serializable接口
所谓的Serializable,就是java提供的通用数据保存和读取的接口。至于从什么地方读出来和保存到哪里去都被隐藏在函数参数的背后了。这样子,任何类型只要实现了Serializable接口,就可以被保存到文件中,或者作为数据流通过网络发送到别的地方。也可以用管道来传输到系统的其他程序中。public interface Serializable类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
序列化ID(serialVersionUID)
serialVersionUID: 字面意思上是序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量
1 private static final long serialVersionUID
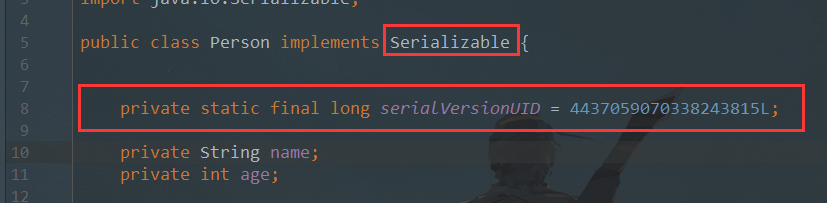
鼠标停在类名处,通过Alt+Enter来生成serialVersionUID
通过代码例子来理解一下serialVersionUID的作用
创建Person类
1 import java.io.Serializable; 2 3 public class Person implements Serializable { 4 5 6 //Person类中没有显式定义serialVersionUID 7 8 private String name; 9 10 private int age; 11 12 public Person(String name, int age) { 13 this.name = name; 14 this.age = age; 15 } 16 17 18 @Override 19 public String toString() { 20 return "Person{" + 21 "name='" + name + '\'' + 22 ", age=" + age + 23 '}'; 24 } 25 }
进行序列化及反序列化
1 import java.io.*; 2 3 public class TestSerializable { 4 public static void main(String[] args) throws Exception { 5 SerializePerson(); //序列化Person对象 6 Person person = DeserializePerson(); //反序列化Person对象 7 System.out.println(person); 8 } 9 10 11 /** 12 * MethodName: SerializePerson 13 * Description: 序列化Person对象 14 * 15 * @throws IOException 16 */ 17 private static void SerializePerson() throws IOException { 18 19 Person person = new Person("xiaoyu", 20); 20 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("D:\\Java_study\\Person.txt"))); 21 oos.writeObject(person); 22 System.out.println("Person对象序列化成功"); 23 oos.close(); 24 } 25 26 27 /** 28 * MethodName:DeserializePerson 29 * Description:反序列化Person对象 30 * 31 * @return 32 * @throws IOException 33 * @throws ClassNotFoundException 34 */ 35 private static Person DeserializePerson() throws IOException, ClassNotFoundException { 36 ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("D:\\Java_study\\Person.txt"))); 37 Person person = (Person) ois.readObject(); 38 System.out.println("Person对象反序列化成功"); 39 return person; 40 } 41 }
运行结果:

修改Person类,添加一个属性,如下:
1 import java.io.Serializable; 2 3 public class Person implements Serializable { 4 5 6 //Person类中没有显式定义serialVersionUID 7 8 private String name; 9 10 private int age; 11 //添加性别属性 12 private String sex; 13 14 public Person(String name, int age) { 15 this.name = name; 16 this.age = age; 17 } 18 19 public Person(String name, int age, String sex) { 20 this.name = name; 21 this.age = age; 22 this.sex = sex; 23 } 24 25 @Override 26 public String toString() { 27 return "Person{" + 28 "name='" + name + '\'' + 29 ", age=" + age + 30 '}'; 31 } 32 }
接下来单独执行反序列化操作,发现报错
1 Exception in thread "main" java.io.InvalidClassException: com.demo.demo08.Person; local class incompatible: stream classdesc serialVersionUID = -5121667000045934802, local class serialVersionUID = -8890120725225522028 2 at java.base/java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:689) 3 at java.base/java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1958) 4 at java.base/java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1827) 5 at java.base/java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2115) 6 at java.base/java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1646) 7 at java.base/java.io.ObjectInputStream.readObject(ObjectInputStream.java:464) 8 at java.base/java.io.ObjectInputStream.readObject(ObjectInputStream.java:422) 9 at com.demo.demo08.TestSerializable.DeserializePerson(TestSerializable.java:39) 10 at com.demo.demo08.TestSerializable.main(TestSerializable.java:8) 11 at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 12 at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) 13 at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 14 at java.base/java.lang.reflect.Method.invoke(Method.java:566) 15 at com.intellij.rt.execution.application.AppMainV2.main(AppMainV2.java:131)
即文件流中的class和classpath中的class,也就是修改后的class与文件流中的class不兼容,出于安全机制考虑,程序抛出异常,并且拒绝载入。在TestSerializable例子中,没有指定Person类的serialVersionUID的,那么Java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件 多一个空格,得到的UID就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以,添加了一个字段后,由于没有显指定 serialVersionUID,编译器又为我们生成了一个UID,当然和前面保存在文件中的那个不会一样了,于是就出现了2个序列化版本号不一致的错误。因此,只要我们自己指定了serialVersionUID,就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。
给Person类指定serialVersionUID,修改如下:
1 public class Person implements Serializable { 2 3 //Person类指定serialVersionUID (序列化版本号) 4 private static final long serialVersionUID = -7075331390912761300L; 5 6 private String name; 7 8 private int age; 9 10 11 public Person(String name, int age) { 12 this.name = name; 13 this.age = age; 14 } 15 16 17 @Override 18 public String toString() { 19 return "Person{" + 20 "name='" + name + '\'' + 21 ", age=" + age + 22 '}'; 23 } 24 }
重新执行序列化操作,将Person对象序列化到本地硬盘的Person.txt文件存储,然后修改Person类,添加sex属性,修改后的Person类代码如下:
1 import java.io.Serializable; 2 3 public class Person implements Serializable { 4 5 //Person类指定serialVersionUID (序列化版本号) 6 private static final long serialVersionUID = -7075331390912761300L; 7 8 private String name; 9 10 private int age; 11 12 private String sex; 13 14 public Person(String name, int age) { 15 this.name = name; 16 this.age = age; 17 } 18 19 public Person(String name, int age, String sex) { 20 this.name = name; 21 this.age = age; 22 this.sex = sex; 23 } 24 25 @Override 26 public String toString() { 27 return "Person{" + 28 "name='" + name + '\'' + 29 ", age=" + age + 30 '}'; 31 } 32 }
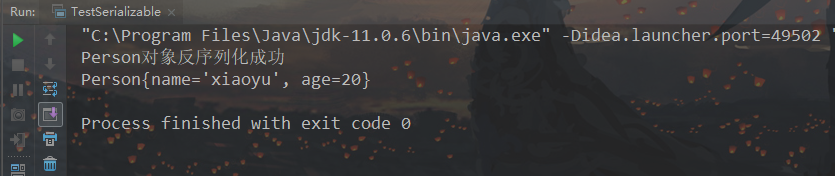
添加属性后,再次执行,可以看到反序列化成功,如下:
serialVersionUID的取值
serialVersionUID的取值是Java运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能也会发生变化。
类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,有可能会导致不同的 serialVersionUID,也有可能相同。为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
Java序列化为什么要使用serialVersionUID
If a serializable class does not explicitly declare a serialVersionUID, then the serialization runtime will calculate a default serialVersionUID value for that class based on various aspects of the class, as described in the Java™ Object Serialization Specification. However, it is strongly recommended that all serializable classes explicitly declare serialVersionUID values, since the default serialVersionUID computation is highly sensitive to class details that may vary depending on compiler implementations, and can thus result in unexpected InvalidClassExceptions during deserialization.
以上是序列化接口上的注释,如果用户没有自己声明一个serialVersionUID,接口会默认生成一个serialVersionUID (根据包名、类名、继承关系、非私有的方法和属性以及参数、返回值等诸多因子计算得出的,生成极度复杂的一个64位的long值。基本上计算出来的这个值是唯一的),但是强烈建议用户自定义一个serialVersionUID,因为默认的serialVersinUID对于class的细节非常敏感,类修改后默认的serialVersionUID也会发生变化。如果序列化和反序列化时用的serialversionUID不同,会导致InvalidClassException异常。
当指定序列化版本serialversionUID时,序列化端 和 反序列化端的对象属性个数、名字即使对应不上,也不会影响反序列化,对应不上的属性会有默认值。也就是说对象显式指定serialversionUID时,序列化和反序列化时,兼容性更好。这里所说的兼容性,仅仅以反序列化成功为标准。在很多复杂的业务中,兼容性还要满足其他约束条件,不仅仅是满足反序列化成功而已。
看完以上的知识点后,相信已经可以回答下面的问题
- Java IO流有什么特点?
- Java IO流分为几种类型?
- 字节流和字符流的关系与区别?
- 字符流是否使用了缓冲?
- 缓冲流体现了Java中的哪种设计模式思想?
- 为什么要实现序列化?如何实现序列化?
- 序列化数据后,再次修改类文件,读取数据会出问题,如何解决呢?
本文参考,整理自以下出处:
https://blog.csdn.net/mu_wind/article/details/108674284
https://www.cnblogs.com/xdp-gacl/p/3777987.html
https://blog.csdn.net/so_geili/article/details/99836043
 posted on
posted on
