

hadoop快速入门分析(一)- 基本架构
hadoop入门分析(一)- 基本架构
这里呢我们将简单的对大数据进行一个初步的认识,毕竟大家都知道,无论是学习一项新技术还是一项新的什么其他的技能,光靠死记硬背是很难背下来的。重要的是对于你要掌握的东西的一个理解,有了理解,那就容易多了不是。所以人狠话不多,废话不多说,接下来就和大家一起探讨下大数据的基本架构。
背景
背景就不多赘述了,相信很多朋友也不愿意过多了解这个历史,这里还是主要感谢膜拜那些大老前辈吧,主要是Google发的paper以及Nutch项目组对于其分布式文件系统的实现和MapReduce的paper实现。为hadoop的问世奠定了基础。
hadoop基础架构
首先,hadoop是由两部分组成。分布式文件系统(HDFS和MapReduce即分布式计算框架构成。说白了呢,对于大数据hadoop这两部分对应的分别解决了两个问题,数据的存储以及数据的处理。并且底层的分布式文件系统是可独立的,也就是说有能力的用户可以做对文件系统做一个私人定制化,对接MapReduce时只需经过简单的配置,就能对接该文件系统。这就很人性化个性化了。接下来我们就主要研究一下这两部分。
HDFS架构
hdfs呢主要是靠磁盘,用现在的话就是罗机器,从而提高了数据的吞吐量,适合大规模数据集上的应用。架构上来讲主要是采用了master/slave架构。分为以下组件
- Client
- NameNode
- SecondaryNameNode
- DataNode
先看一张HDFS的基本架构图,如图1-1所示:
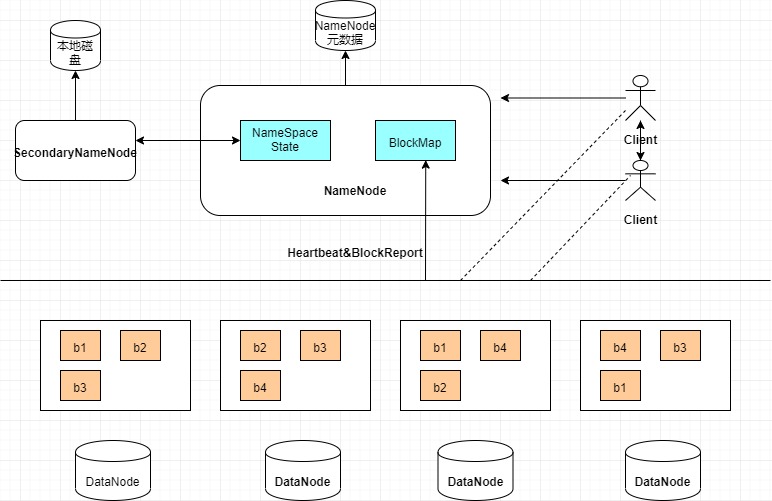
图1-1 HDFS架构图
接下来分别了解一下以上四个组件:
- Client
Client也就是用户可以通过与NameNode和DataNode交互从从而访问HDFS的文件。其实就是对外提供了访问整个文件系统的接口。
- NameNode
这一组件相当于整个系统的管家,主要负责管理HDFS的目录树和相关文件元数据信息。而这些信息是以fsimage(HDFS元数据镜像文件)和editlog(HDFS文件改动日志)两个文件存在本地磁盘的。同时从图中也可以看到,NameNode还负责检测各个DateNode的健康信息,一但有挂掉的。则将其移除HDFS并重新备份挂掉的数据。
- Secondary NameNode
图中可以看出该组件和NameNode有一定交互,其实Secondary NameNode在这里主要对fsimage和editlog进行合并,并传给NameNode,从而降低NameNode压力。
- DateNode
一般讲,每个Slave节点安装一个DateNode,负责真正的数据存储,定期向NameNode汇报数据信息,看图可以看出存储有一些特点。当用户上传大文件时分成block进行存储,默认是128mb一个block,不同hadoop版本也可能不同。并且为了数据可靠性将block进行数据备份,如图,默认备份3份也可自行配置,写到不同的DateNode上,这一过程对用户来讲是透明的。
小结
这篇主要记录了hadoop的一个全貌,分为两大部分HDFS,MapReduce。其中对HDFS进行了一些架构的介绍,后面还会对我们的MapReduce的架构以及编程的模型进行细致的分析,做到知其所以然。由于能力有限,文章中出现的一些纰漏错误或者有什么交流的地方都欢迎留言,希望我们彼此都能够有所收获。

