


HA脑裂问题解决方案
前言:HA中最复杂的,也是最难处理的就是集群脑裂问题,如果处理不好会导致数据丢失、数据不一致等一系列问题。HA解决方案中大多数都是基于VIP也就是虚拟IP的方式,虚拟IP的实现又依赖于ARP协议,让我们先来看下一些基础知识。
一、ARP请求过程:
1:发送ARP请求
2层网络中需要通过IP地址访问另一台机器,需要先找到它的MAC地址,这个过程就是通过ARP协议来实现的。请求发送方会先查找本机的ARP缓存表如果其中找不到对应的记录,就会通过往同网段中所有机器发送ARP广播。


如上图我们ping 192.168.1.111,同网段所有机器都会收到下图所示的arp广播内容。
2:回应ARP请求

如上图是一个arp回应包,网关询问谁是192.168.1.195, 192.168.1.195机器发送了ARP reply包,告诉网关它是192.168.1.195并且自己的MAC地址是fa:16:3e:74:cd:8f。网段内机器受到arp广播后,首先会检查请求的IP地址是不是在本机网口上,具体的回应策略根据内核的一些参数(arp_ignore)来决定是只回应接收ARP广播网卡上的IP还是本机所有网卡上的IP,最后如果在本机找到了请求的IP地址,则发送arpReply回应包。
3:接收ARP回应并缓存
发送ARP请求的机器接收到ARP回应包后,把其缓存在本机的ARP缓存表后,下次再次请求时直接从ARP缓存表中获取请求目标的MAC地址,不再发送ARP广播。
二、ARP状态流转过程:
下图中我们执行 ip neigh可以看到本机arp缓存表的条目,显示了缓存在本机ARP缓存表中的机器对应的MAC信息。

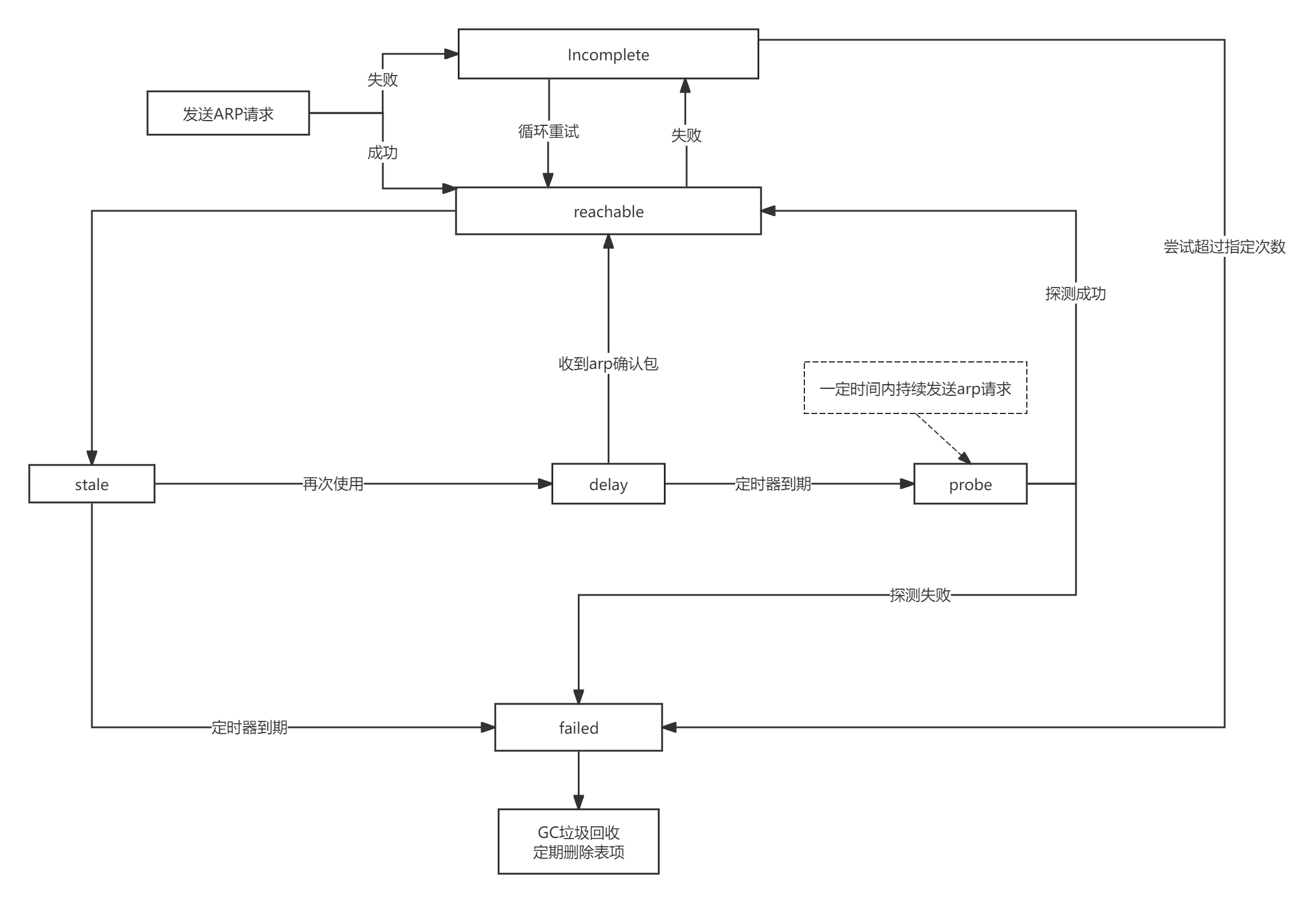
1:发送ARP请求
2:如果收到ARP回应包,则进入REACHABLE状态
3:如果没有收到ARP回应包,则进入INCOMPLETE状态
4:进入REACHABLE状态超过一定的时间后(base_reachable_time参数设置的时间),会进入STALE状态
5:如果再次请求ARP缓存表中的MAC,则该ARP状态从STALE短暂进入DELAY状态
6:如果进入DELAY状态后收到了回应包,则再次从DELAY状态转为REACHABLE状态
7:如果进入DELAY状态并在DELAY定时器到期后还没收到回应包,则进入probe状态重新探测
8:进入probe状态后会在一定时间内持续发送ARP请求,如果成功收到回应包则进入REACHABLE状态,如果没有收到则进入failed状态
9:INCOMPLETE状态下尝试一定次数到最大尝试次数后会转为failed状态
10:处理ARP缓存的gc垃圾器会定期进行回收,清除STALE和failed状态的条目来释放空间
关键点:其实说了这么多,这里最关键的部分就是回收STALE和failed状态条目的时机,我们在本机测试发现arp缓存表里面STALE状态和failed状态的条目会一直存在,貌似不会被清除。STALE状态正常的清除周期是60S,由gc_stale_time参数确定,reachable状态转为STALE状态的时间默认是30S,由base_reachable_time参数确定,所以正常来说90S后STALE状态的信息就应该被GC回收器清除了,那为什么实际STALE状态的条目实际并未在90S后被清除,而是一直存在。
这里的关键就在net.ipv4.neigh.default.gc_thresh1参数,默认的值是128,也就是ARP缓存的最大条目,只有超过这个条数后才会触发ARP的GC机制开始回收,因为正常ARP缓存表的条目都很难达到这个数目所以会导致不会被清除。
我们把net.ipv4.neigh.default.gc_thresh1的值设为3,再次测试发现STALE状态和failed状态的条目60S后自动消失了,说明被GC自动回收了,这再次验证了我们的说法。
三、HA脑裂原因:
了解了ARP后我们再来看HA脑裂的情况。
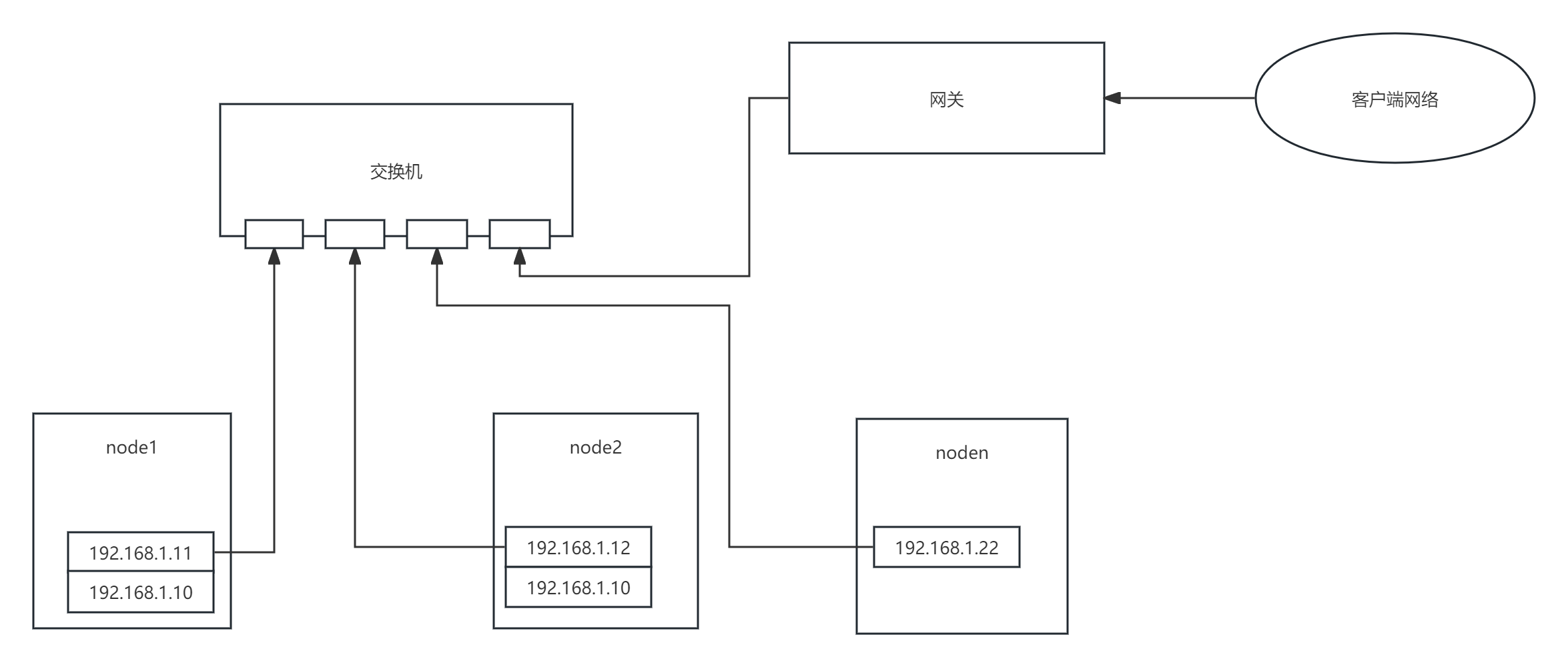
脑裂过程:如上图,192.168.1.11和192.168.1.12是HA 双机的原IP,而192.168.1.10是VIP,正常主备模式下只有主机才会启用vip,备机是关闭的,这样客户端和其他机器就可以通过vip访问到主机上的服务。但是在脑裂场景下,比如HA主备机器因为心跳检测端口被防火墙拦截导致双机无法通过心跳检测到对方状态,故都被提升成了主节点,所以2台机器都启用了VIP。
造成问题:这样造成的问题是 其他机器访问VIP后,可能一会访问的是node1,一会访问的是node2,这样会把数据一部分写到node1上,一部分写到node2上,造成数据不一致甚至文件系统损坏等众多问题。这里为什么会出现这种情况呢?就是上面的ARP机制导致的,我们来结合ARP机制来分析HA脑裂后客户端访问的VIP会在双机之间来回漂移的原因。
原因分析:核心在于我们二里面的说的关键点,

我们先看下上图,比如vip是192.168.1.254,我们访问vip后对应的arp缓存就会缓存在arp缓存表里面,下次访问的时候直接从ARP缓存表里面获取。这种情况下即使HA脑裂后出现了2个VIP,由于ARP缓存表的原因,其访问的还是其中某一台机器,但是下面2种情况下就会出问题:
1:如果用户手动设置了net.ipv4.neigh.default.gc_thresh1参数,比如设置成了5或者10,那么再和该机交互的ip超过5条后 192.168.1.254的缓存信息就会很快被回收掉;
2:即使用户不手动修改net.ipv4.neigh.default.gc_thresh1参数,虽然默认的128条数目正常很难达到,但这个没法100%保证,在某些场景下如果有大量的IP和本机交互 ,条数也很可能超过128导致192.168.1.254的缓存被清理;
3:客户端首次访问,由于之前arp缓存表没有192.168.1.254的缓存信息,导致它只能从HA双机里面随机选一个,这时候谁最先回它的arp请求它就会选谁。
4:如果客户端和HA不在一个网段,需要通过网关来访问HA节点的话,则取决于网关的ARP缓存表上192.168.1.254的刷新时间,这个网关可能是路由器、3层交换机、软路由等,主要取决于其ARP缓存刷新周期(也就是ARP缓存老化时间),这个时间没有一个固定值,不同的品牌机器都不一样,比如思科是 5分钟,华为是 20分钟等。
所以上面4种情况都可能导致在HA脑裂期间,客户端数据一部分写到node1,一部分写到node2,这会造成不可逆的损失,显然是无法接受的。
四、常用HA脑裂解决方案:
了解了上面的原理后其实再去解决脑裂问题就相对来说比较简单了,我们先来看下目前市面上和一些HA组件官方提供的解决方案:
1:多节点
实现方式:部署多个节点,如果主节点网络故障,则可以在剩余节点里面通过选举机制重新选取新的主节点。
优点:能解决网络恢复后主节点不会切换到脑裂之前的节点去,因为新主节点是选举产生的,少数服从多数原理。
缺点:
1:无法彻底解决脑裂问题,特别是脑裂后双vip问题,脑裂期间数据依然可能被分别写入2个主节点中;
2:需要机器数量增多,硬件成本上升;
3:多节点数据同步开销增大,因为主节点数据需要同步到多个节点中去,降低可靠性。
2:STONITH隔离
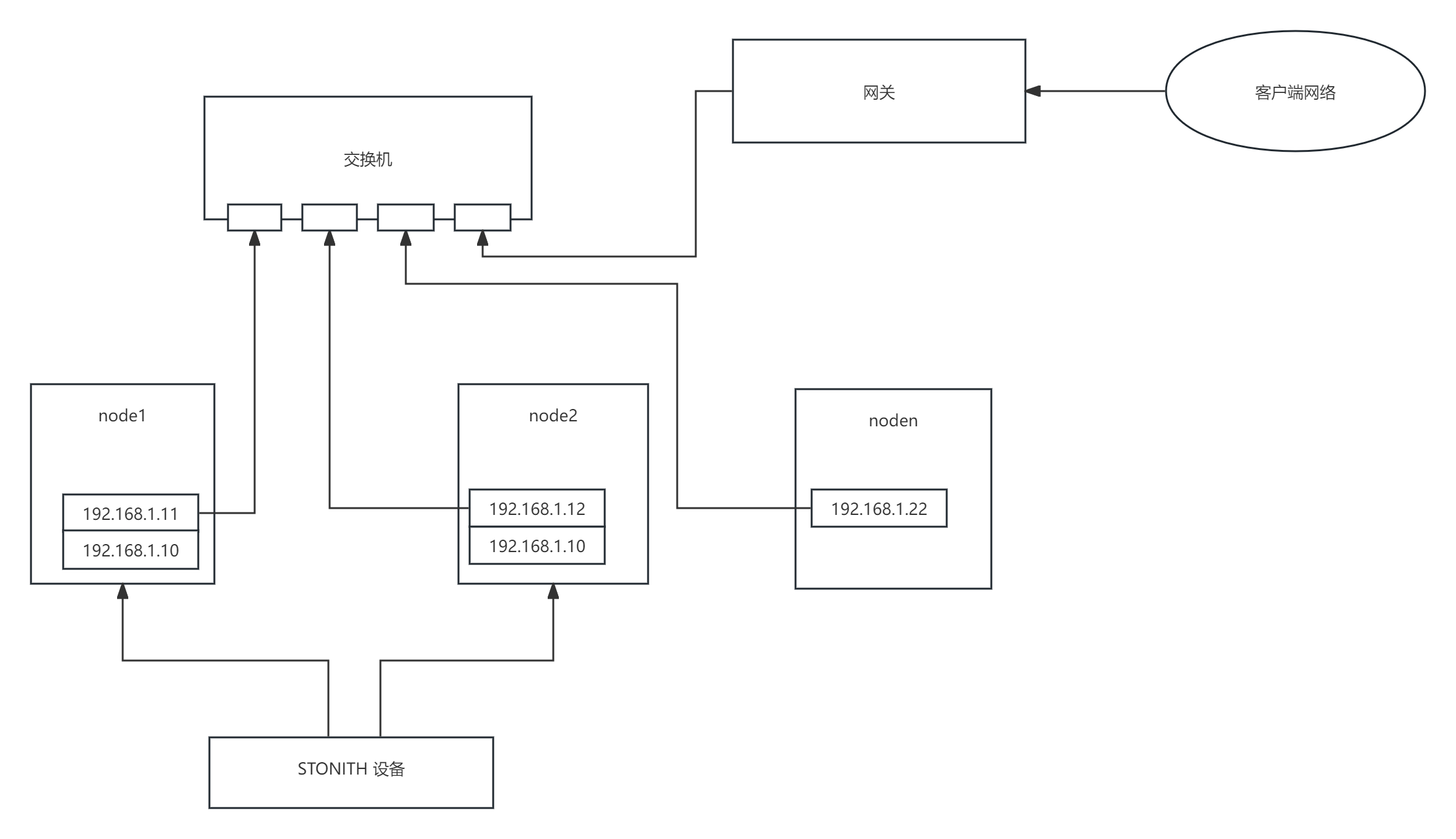
实现方式:STONITH机制的实现方式是通过一个专业的STONITH硬件设备(通常称为爆头设备),通过STONITH硬件设备来检测双机的网络通信情况,如果有一方网络无法连通了,就判定其网络故障将其直接通过控制电源设备强制关机从而达到隔离的目的。
优势:能解决一定场景下的脑裂隔离问题,通过强制关机能保证很强的隔离成功率。
缺点:
1:需要专业的STONITH硬件设备,部署成本高;
2:STONITH硬件本身可能存在可靠性问题;
3:兼容性差,STONITH硬件设备方式只能部署在物理机场景下,虚拟机环境无法使用;部分其他STONITH虚拟机方案(使用服务器本身的的硬件接口称为内部Fence)也必须在宿主机上安装、配置相应的fence服务,且很多系统都无法完全支持;云平台则完全无法支持。
4:部分客户机器业务不允许随意关机和重启。
3:仲裁节点
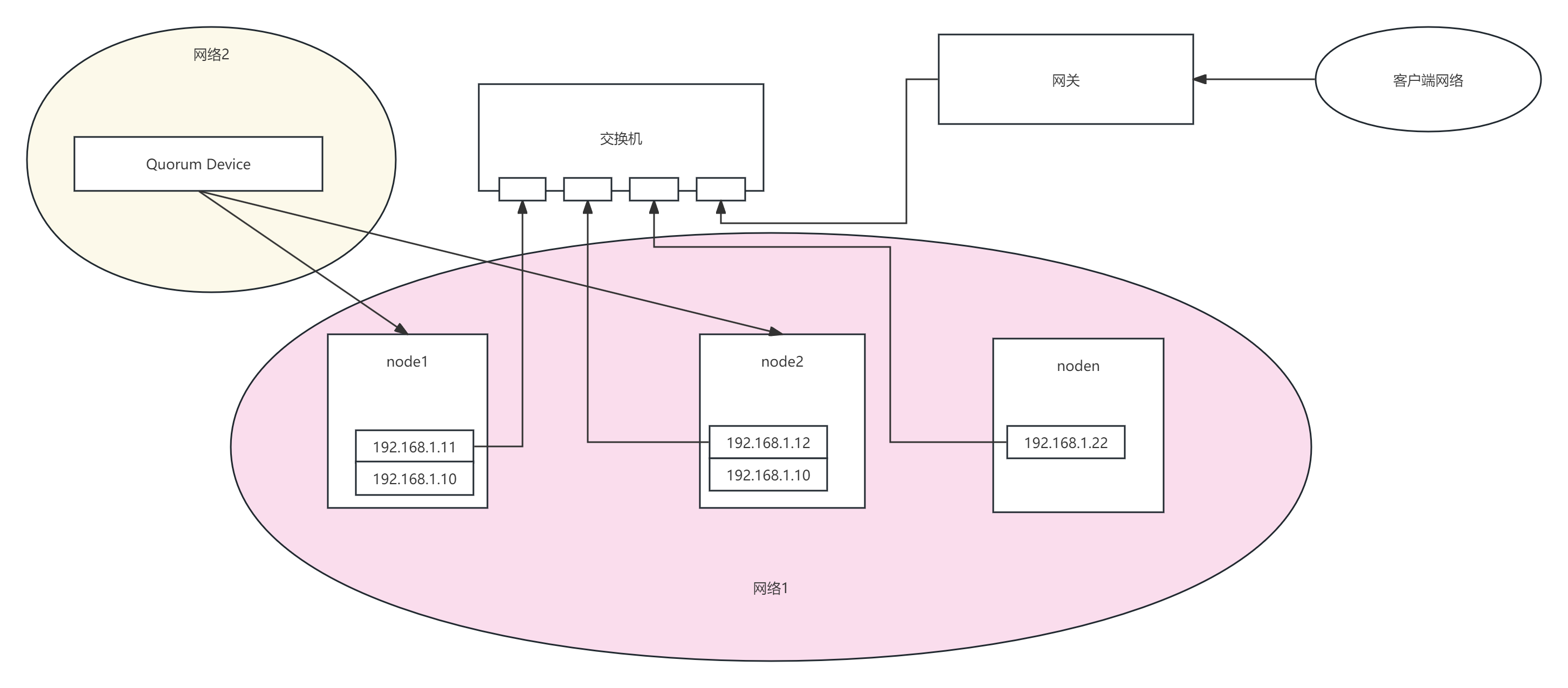
实现方式:在集群之外启用一个仲裁节点,其上部署Quorum Device,仲裁节点必须部署在HA网段之外的一个独立网段中。集群主节点故障后,会重新进行选举,仲裁节点具有更高的投票权;
优势:适合部署在偶数节点中特别是双节点集群中,由于其部署在单独的一个网段中,不受集群网络的影响,能解决主节点选举问题,网络恢复后主节点不会切换到之前的主节点上;
缺点:仲裁节点本身可靠性问题,如果仲裁节点本身故障,或者仲裁节点所在网络故障,则会导致更大的问题,比如在双节点部署下,由于启用了选举机制且2个主节点都各只有1票的情况下2个节点都将不可用,导致无法对外提供服务;
五:我的HA脑裂解决方案:
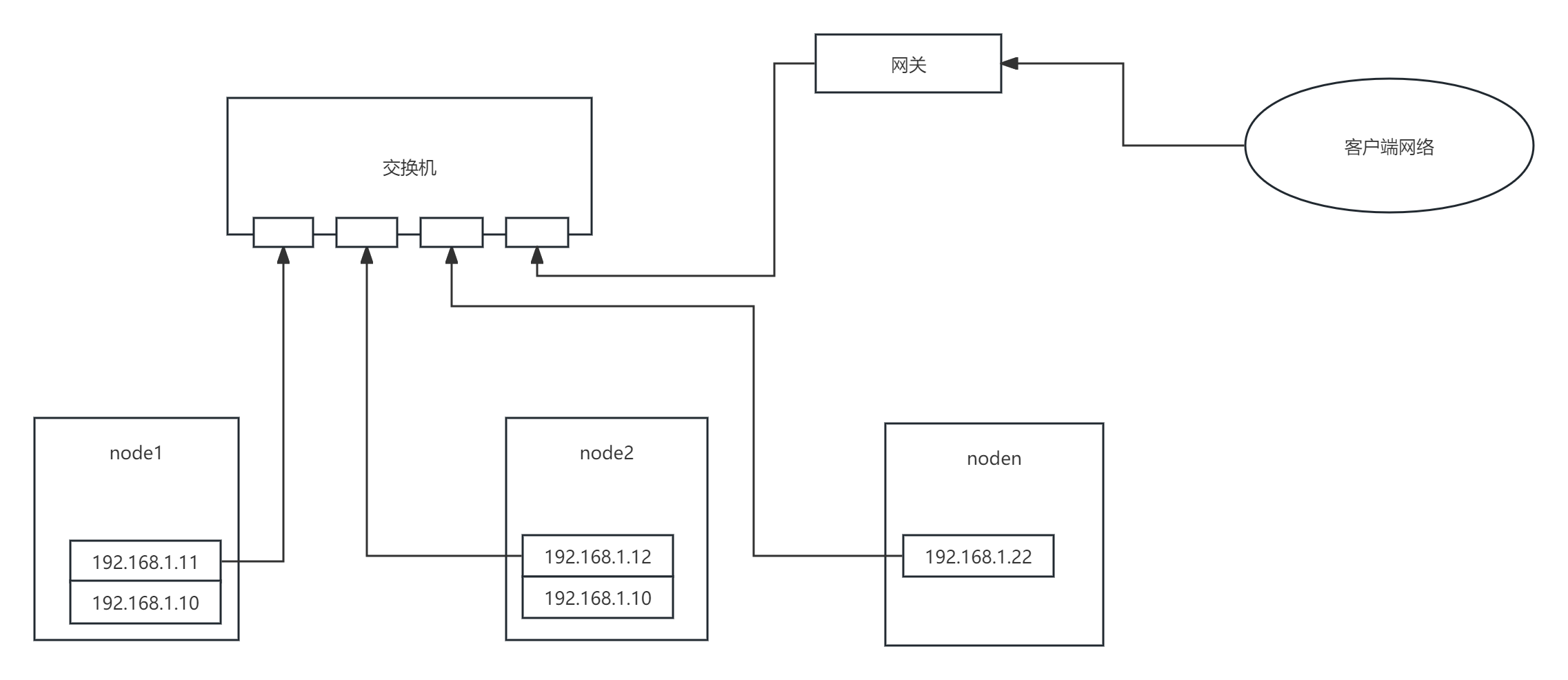
整体思路:
1:往往越简单的方法有时候越可靠,很多解决方案往往是把事情考虑的过于复杂了而忽略了简单的方法
2:网络故障归类,其实导致HA双机网络无法连通的原因就那么多,可以把所有可能的情况按类型归类并按类型采取统一的处理策略
导致HA双机网络无法连通的原因无非是,1:物理网络故障(网卡、链路、交换机等),2:网络系统故障(网络协议栈、网络参数配置、负载过高等),3:端口开放问题(心跳检测的端口未开放)
实现方案:
一、网络链路故障
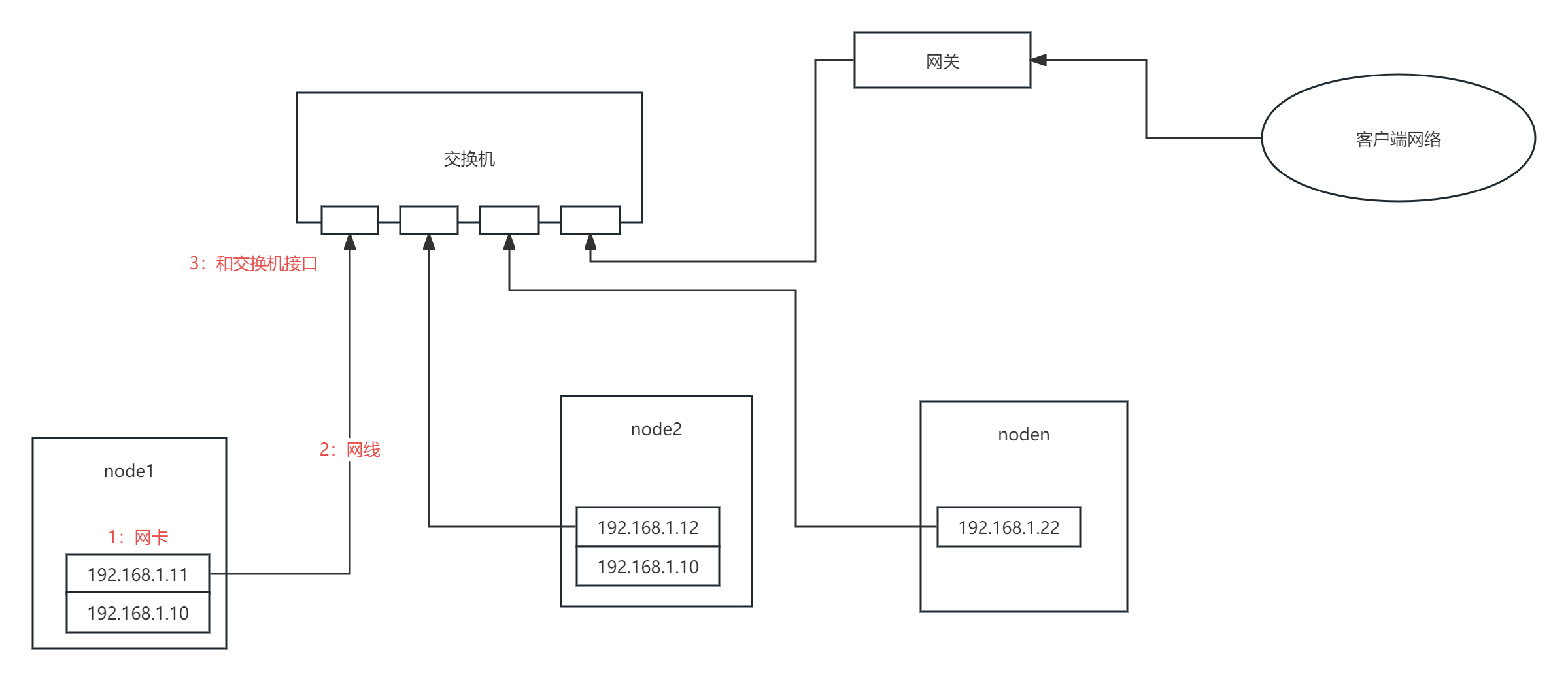
链路故障无非是网卡、网线、交换机接口故障,通过检测链路来判定链路状态是否异常,如果链路状态不是yes,则可以判定该机的网络100%故障,直接将其隔离;
二、网络连通性
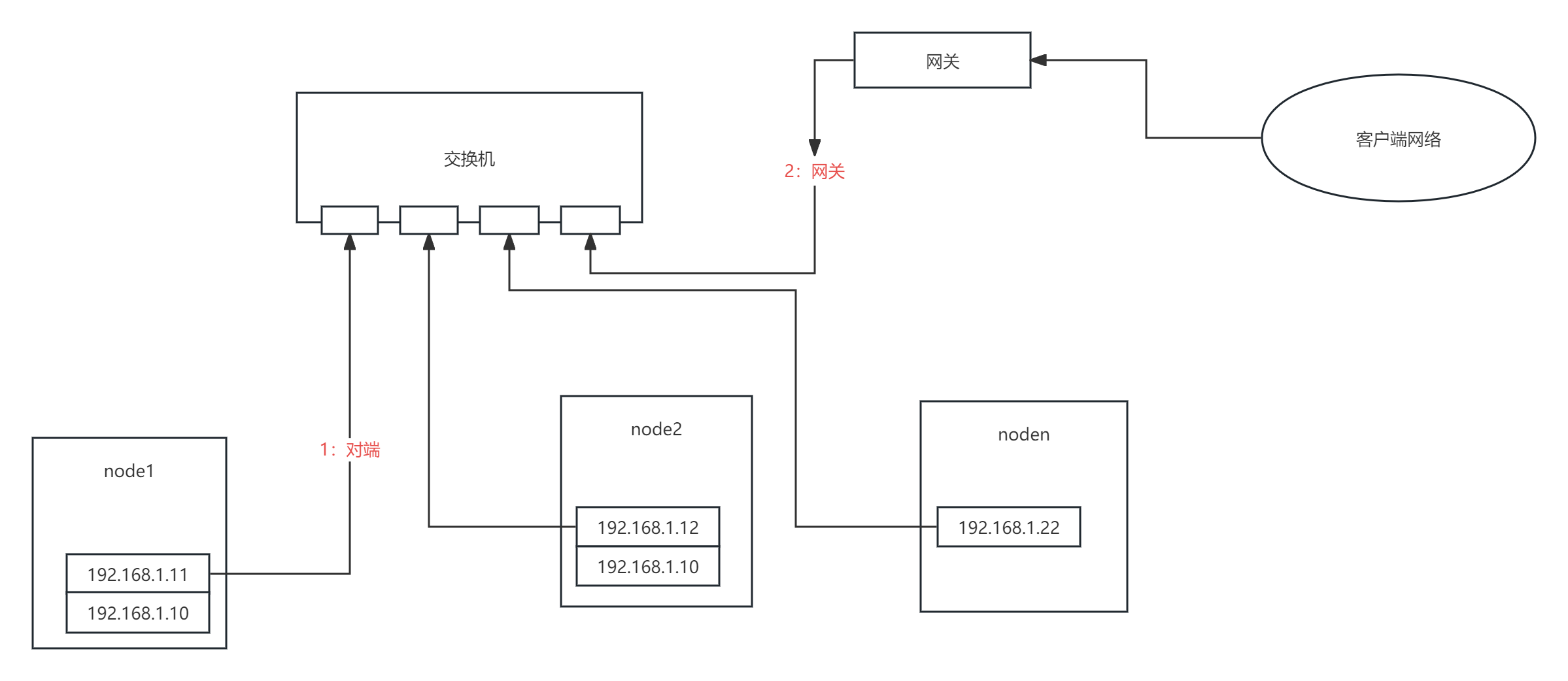
检测机制:
1:如果当前节点链路状态正常,则检测和对端网络的连通性
这里利用了ping功能,最简单的检测网络连通的方式往往最可靠,因为几乎所有的机器上ping都是可以ping通的,ping对端节点的ip,如果无法ping通,则代表和对端的网络无法连通了。
2:判定和网关的连通性
HA的很多方案里面引入了各自第三方仲裁设备,但往往却忽略了现成的可以作为第三方的设备,那就是网关,网关是最稳定和可靠的第三方设备。
通过ping网关来判定当前节点和网关之前的网络连通性,如果无法无法ping通对端 + ping通网关,则可以判定当前节点网络故障,直接将当前节点隔离。
隔离机制:
1、自身链路正常 + 无法ping通对端,可以判定有这些可能情况,1:对方节点链路故障; 2:自身网络系统故障(网络协议栈、系统超载等)3:交换机故障
2、自身链路正常 + 无法ping通对端 + ping通网关,可以排除:自身网络系统故障(网络协议栈、系统超载等)、交换机故障、和对端心跳端口不通,所有只剩下:对方节点链路故障,故至少可以判定当前节点是正常的无需隔离;
3、自身链路正常 + 无法ping通对端 + ping不通网关,则有可能是:自身网络系统故障(网络协议栈、系统超载等),直接将当前节点身隔离;
// 这里有个极端情况,网关故障+对端网络故障,这种情况下隔离当前节点也无影响,因为网关挂了代表外部已经无法访问到HA所在网络了。
三、网络端口连通性
检查机制:
如果自身网络链路正常且能ping通对端,代表和对端的网络是连通的,但不能排除和对端的心跳检测端口是连通的,所以这个步骤核心是判定和对端心跳检测端口连通性。
这里同样和ping、网关一样,运用了最简单的一个功能,ssh 22端口默认开放。ssh的端口和ping功能一样是所有系统默认开放的,目前没有遇到过这2个最基础功能无法使用的场景。
HA由于部署时候不仅需要开放双机之间的SSH端口,还需要配置了双机免密登录,使得双机之间SSH端口无法连通的可能性几乎为0,排除了极少客户未开放ssh 22端口的可能性。
隔离机制:
1:如果心跳组件返回的信息里对端节点下线了,代表和对端的心跳检测失败了,则通过ssh免密登录登录到对端节点,然后通过集群状态和vip信息判定是否出现了双主;
2:如果出现双主则隔离之前的主节点,因为在提升新的主节点后会强制刷新网段内其他机器的ARP缓存,所以在短时间内的请求都会发送到最新的主节点,之前的主节点会被记录在特定文件中;
3:同时在提升主节点中写入检测逻辑,如果集群已经有一个主节点,则会阻止其提升行为,从而保证了集群中始终有一个主节点;
通过2和3双重保障,进一步保障了因为心跳检测端口被错误操作导致不通的情况下集群可能出现脑裂导致2个主节点的行为。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!