


Linux文件系统详解
一、文件系统基础概念
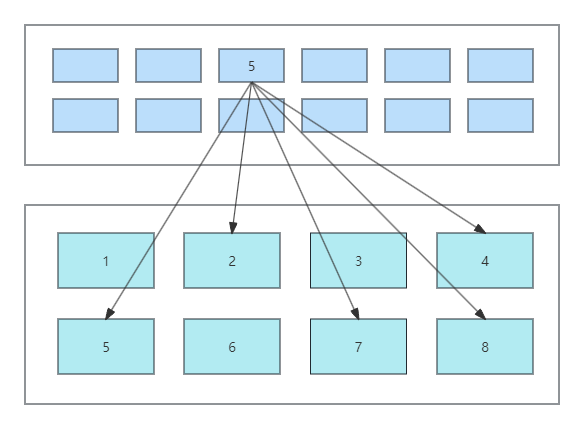
文件系统的基本组成结构是inode和data以及superblock。
inode:代表了文件的元信息,包括:inode号、文件大小、权限、所属用户和组等信息。
data:是数据部分,存储了实际的文件数据,data的基本存储单位是块(block),不同文件系统下块的大小各不相同,但一般都是4KB,相当于8个连续扇区的大小。
如上图,上面是inode部分,下面是data部分,inode中存储了文件所在各个块的指针,文件块在磁盘上并不一定连续分布,可能分散在不同的各个块中。当然这个只是基础的原理示意,实际的存储过程显然要复杂的多,不同的文件系统有不同的实现方式,比如ext3/4是通过多级索引和Extent组织索引,而xfs则是b+ tree的方式组织索引。
superblock:代表了文件系统的元信息,inode和data是相对于文件来说的,而superblock则是相对于文件系统来说的,存储了已使用和未使用的inode和data信息,以及block的大小和块组、文件系统类型、文件系统挂载等信息。
二、虚拟文件系统VFS
我们通常说的文件系统是指磁盘上的实际文件系统,如ext3/4、xfs等,但文件系统在内存中也有自己的表示结构,这个结构就是VFS。
VFS是一个在具体的文件系统之上抽象的一层,用来处理与文件系统相关的所有调用,通过给各种文件系统提供一个通用的接口,从而屏蔽了底层不同文件系统之间的差异,使上层的应用程序能够使用一个通用的接口访问不同文件系统。
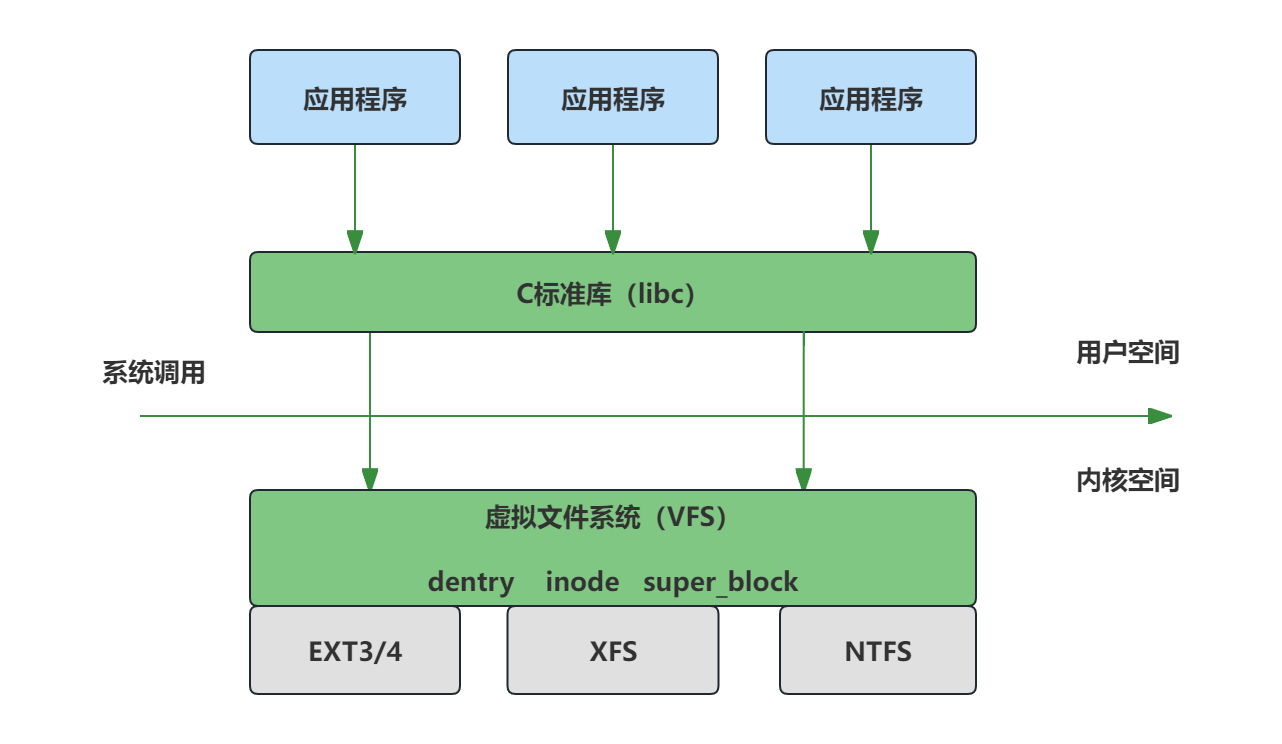
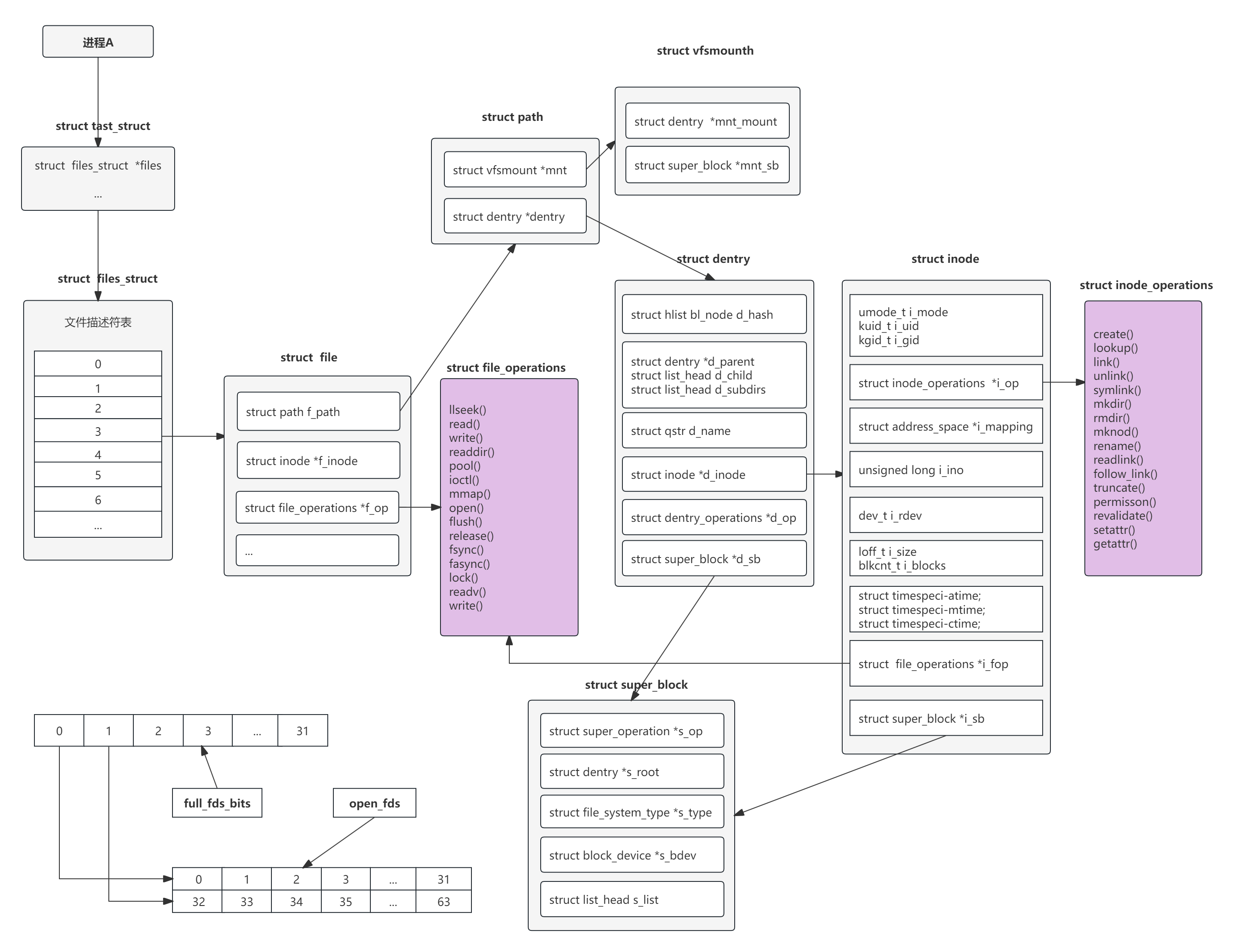
VFS主要由dentry、inode、super_block和file结构体 4部分组成。
2.1 dentry(目录项):
dentry结构体如下:

struct dentry { /* RCU lookup touched fields */ unsigned int d_flags; /* 目录项状态标志 */ seqcount_spinlock_t d_seq; /* 实现顺序一致性访问的锁 */ struct hlist_bl_node d_hash; /* 目录项查找函数 */ struct dentry *d_parent; /* 父目录 */ struct qstr d_name; /* 目录项名称 */ struct inode *d_inode; /* 该目录项对应的inode */ unsigned char d_iname[DNAME_INLINE_LEN]; /* 短名称 */ const struct dentry_operations *d_op; /* 目录项操作方法集 */ struct super_block *d_sb; /* 对应的超级块结构 */ unsigned long d_time; /* 重新变为有效的时间 */ void *d_fsdata; /* 私有数据 */ struct lockref d_lockref; /* 自旋锁 */ union { struct list_head d_lru; /* 最近未使用的目录项的链表 */ wait_queue_head_t *d_wait; /* 等待队列头 */ }; struct hlist_node d_sib; /* 哈希列表节点 */ struct hlist_head d_children; /* 目录项通过这个加入到父目录的d_subdirs中 */ union { struct hlist_node d_alias; /* 目录项别名 */ struct hlist_bl_node d_in_lookup_hash; /* 哈希列表节点,只有在目录项正在被查找时才使用*/ struct rcu_head d_rcu; } d_u; };
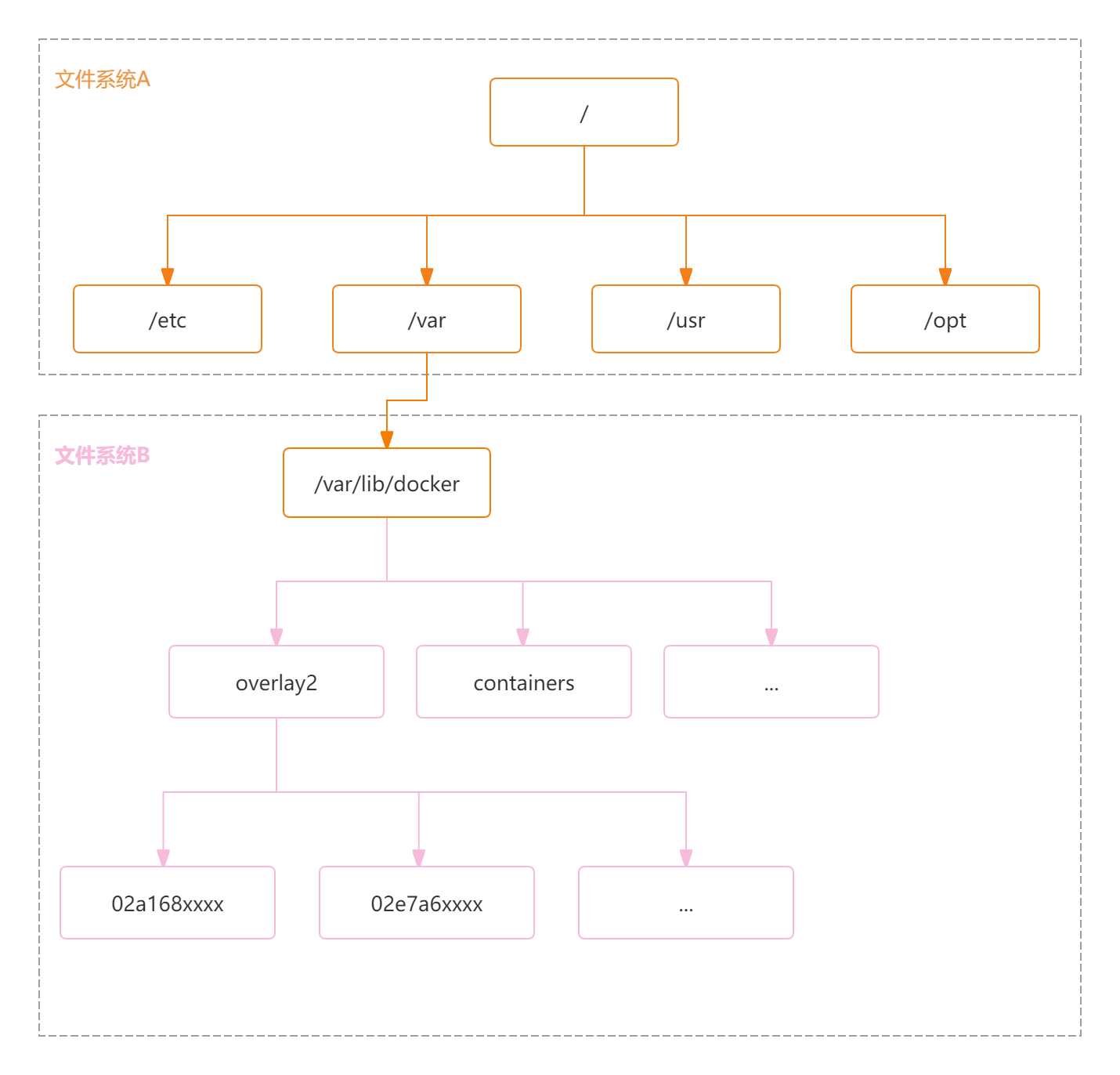
dentry也叫目录项,可以理解为文件路径在VFS中的表示结构,每个文件路径对应唯一的一个dentry结构,所有的dentry结构组成了dentry结构树,即:文件系统目录树。Linux可以把一个文件系统挂载到某个目录上,dentry是相对于文件系统来说的,每个dentry在其文件系统内dentry结构树上的位置是固定的,如上图,文件系统B挂载到文件系统A的/var/lib/docker目录,虽然containers可以通过/var/lib/docker/container路径访问,但containers的dentry结构在文件系统B对应的dentry结构树上的位置是固定的,不会随着文件系统B挂载到不同的位置而改变,也就是说dentry是相对于其所在的文件系统来说的。
1.dentry与inode是多对一的(硬链接的情况),可以通过inode->i_dentry找到指向inode的所有dentry.
2.sys_open() 打开一个文件,如果文件不存在,dentry仍然会被创建且被加入到dcache中,但是dentry指向的inode为空(此时dentry为负状 态),path_walk()完毕后,dentry被加入到super_block的LRU链表中,等待销毁.
3.dentry有自己所属的文件系统,因此dentry建立的树状层次结构只在dentry所属的文件系统中生效.
4. 引用计数为0的dentry仍然会保留在dcache中,但是同时也会被加入到super_block的LRU未使用链表中,当需要释放内存时,压缩 dentry的slab回调函数shrink_dcache_memory()被调用,将LRU链表中最久未被使用的dentry从dentry缓存中删 除后,释放给slab分配器.
5.dentry被创建时其父dentry必然存在,且会增加父dentry的引用计数,dentry被销毁 时会减少其父dentry的引用计数,如果其父dentry的引用计数被递减后变为0,那么其父dentry会被销毁,依次向上,直到文件系统的root dentry.
Q:文件系统中有一个文件foo,假设文件系统同时挂载到/mnt1/和/mnt2/,那么/mnt1/foo和/mnt2/foo对应的dentry是同一个dentry吗?
A:是的,一个块设备可以被挂载到多处,每次挂载都会创建vfsmount,但是VFS的super_block只有一个,dentry是属于文件系统的 而不是属于某个挂载点,唯一代表文件系统的是VFS的super_block,因此,dentry结构体中有到super_block的指针,但是没有到 vfsmount的指针,/mnt1/foo和/mnt2/foo是同一个文件系统下的同一个文件,他们对应的dentry也必然是相同的,理解了 dentry是属于文件系统的,就很容易理解为什么struct path的成员只有vfsmount和dentry了.
Q:得到dentry后,可以沿着dentry->d_parent往上一直到系统的根目录吗?
A:如果dentry是属于根文件系统的,则可以.否则,如果dentry属于新挂载的文件系统,则不能,因为通过dentry是无法得知文件系统的挂载 点的(如果文件系统只挂载了一次,通过dentry拿到文件系统的根dentry,找到vfsmount,获得挂载点也是一种办法).
Q:引用计数为0的dentry会同时存在于super_block的未使用链表和dcache中,当通过do_lookup()函数从dcache中找到dentry时只是增加dentry的引用计数,为什么不把它从super_block的链表中删除?
A:dentry的LRU实现使用了lazy LRU,因为dentry的使用时间可能非常短(如stat一个文件),如果从dcahce中找到后,立即将dentry从LRU中移除,使用完毕后,马 上又要插入到LRU链表中,增加了链表操作的开销,由于LRU链表是受全局dcache_lock保护的,加剧对dcache_lock的争用.但是,这 样一来又有一个问题,dentry的引用计数从0->1,到1->0的过程中,dentry在LRU链表中的位置没有变化,且dput() 时,dentry已经在LRU链表中,DCACHE_REFERENCED标志不会置位,shrink_dcache_memory()被调用时,可能被 当作最久未使用dentry给释放掉,但是实际情况是,dentry刚刚才被使用,super_block的LRU链表明显没有达到效果?哥们的这个疑问 还真是一个问题,这个问题已由Nick Piggin在这个中解决.
Q: 调用unlink()删除文件时,经过sys_unlink()->do_unlinkat()->vfs_unlink()进入到 d_delete(),如果dentry还被其他进程使用(dentry->d_count>1),为什么d_delete()需要将 dentry从dcache中移除?
A:如果dentry被其他进程引用,在d_delete()中还不能将dentry转化为负状态,但是必须 将dentry(记为dentry1,dentry1对应的inode记为inode1)从dcache中移除,否则,后续在同一个目录下创建相同文件名 的文件时会从dcache中找到dentry1,导致引用inode1,出现新创建的文件就有数据的情况.
2.2 inode(索引节点):
inode结构体如下:
struct inode {
struct hlist_node i_hash; /* 哈希表 */
struct list_head i_list; /* 索引节点链表 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用记数 */
umode_t i_mode; /* 访问权限控制 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用者id组 */
kdev_t i_rdev; /* 实设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改(modify)时间 */
struct timespec i_ctime; /* 最后改变(change)时间 */
unsigned int i_blkbits; /* 以位为单位的块大小 */
unsigned long i_blksize; /* 以字节为单位的块大小 */
unsigned long i_version; /* 版本号 */
unsigned long i_blocks; /* 文件的块数 */
unsigned short i_bytes; /* 使用的字节数 */
spinlock_t i_lock; /* 自旋锁 */
struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */
struct inode_operations *i_op; /* 索引节点操作表 */
struct file_operations *i_fop; /* 默认的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct file_lock *i_flock; /* 文件锁链表 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */
struct list_head i_devices; /* 块设备链表 */
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备驱动 */
unsigned long i_dnotify_mask; /* 目录通知掩码 */
struct dnotify_struct *i_dnotify; /* 目录通知 */
unsigned long i_state; /* 状态标志 */
unsigned long dirtied_when; /* 首次修改时间 */
unsigned int i_flags; /* 文件系统标志 */
unsigned char i_sock; /* 可能是个套接字吧 */
atomic_t i_writecount; /* 写者记数 */
void *i_security; /* 安全模块 */
__u32 i_generation; /* 索引节点版本号 */
union {
void *generic_ip; /* 文件特殊信息 */
} u;
};
inode是文件的元信息,如上,inode存储了文件的各种属性、权限信息、以及文件各个数据块的存储位置。inode和dentry是一对多的关系,一个inode可以对应多个dentry,比如文件和硬链接虽然对应不同的dentry结构,但其对应的inode是同一个,inode通过i_dentry链表链接起了对应的所有dentry的d_alias成员,从而实现了inode和dentry之间1对多的映射关系。但反过来一个dentry只能对应一个inode,是通过d_inode成员指向对应的inode结构体。
2.3 super_block(超级块):代表了文件系统的元信息,inode和data是相对于文件来说的,而superblock则是相对于文件系统来说的,存储了已使用和未使用的inode和data信息,以及block的大小和块组、文件系统类型、文件系统挂载等信息。
超级块的结构体如下:
struct super_block
{
/************描述具体文件系统的整体信息的域*****************/
kdev_t s_dev; /* 包含该具体文件系统的块设备标识符。例如,对于 /dev/hda1,其设备标识符为 0x301 */
unsigned long s_blocksize; /* 该具体文件系统中数据块的大小,以字节为单位 */
unsigned char s_blocksize_bits; /* 块大小的值占用的位数,例如,如果块大小为1024字节,则该值为10 */
unsigned long long s_maxbytes; /* 文件的最大长度 */
unsigned long s_flags; /* 安装标志*/
unsigned long s_magic; /* 魔数,即该具体文件系统区别于其它文系统的一个标志 */
/**************用于管理超级块的域******************/
struct list_head s_list; /* 指向超级块链表的指针 */
struct semaphore s_lock /* 锁标志位,若置该位,则其它进程不能对该超级块操作 */
struct rw_semaphore s_umount /* 对超级块读写时进行同步 */
unsigned char s_dirt; /* 脏位,若置该位,表明该超级块已被修改 */
struct dentry *s_root; /* 指向该具体文件系统安装目录的目录项。*/
int s_count; /* 对超级块的使用计数*/
atomic_t s_active;
struct list_head s_dirty; /* 已修改的索引节点形成的链表 */
struct list_head s_locked_inodes; /* 要进行同步的索引节点形成的链表 */
struct list_head s_files
/***********和具体文件系统相联系的域*************************/
struct file_system_type *s_type; /* 指向文件系统的file_system_type 数据结构的指针 */
struct super_operations *s_op; /* 指向某个特定的具体文件系统的用于超级块操作的函数集合 */
struct dquot_operations *dq_op; /* 指向某个特定的具体文件系统用于限额操作的函数集合 */
u; /*一个共用体,其成员是各种文件系统的 fsname_sb_info数据结构 */
};
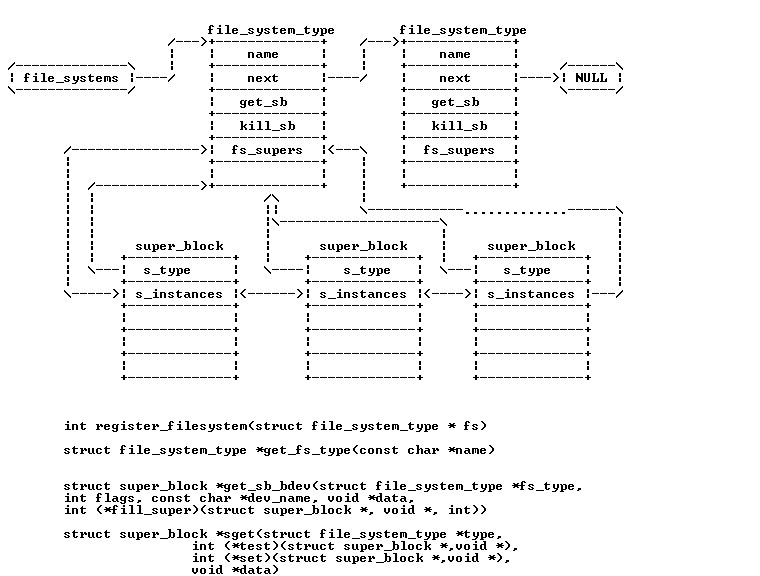
如下图:super_block存在于两个链表中,一个是系统所有super_block的链表, 一个是对于特定的文件系统的super_block链表,所有的super_block都存在于 super_blocks(VFS管理层) 链表中。
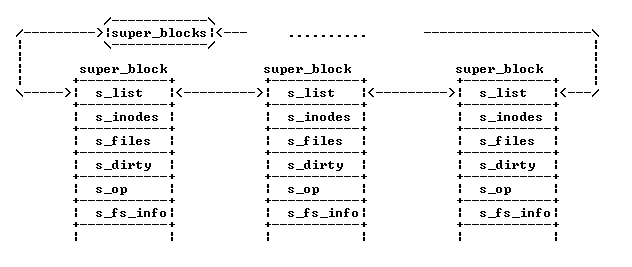
对于特定的文件系统(文件系统层的具体文件系统), 该文件系统的所有的super_block 都存在于file_sytem_type中的fs_supers链表中.
而所有的文件系统都存在于file_systems链表中,这是通过调用register_filesystem接口来注册文件系统的。
int register_filesystem(struct file_system_type * fs)
2.4 file结构体:每个打开的文件在内核中都由file结构体表示,里面记录了打开文件的各种信息,它由内核在打开文件时创建,并传递给在文件上进行操作的任何函数。在文件的所有实例都关闭后,内核释放这个数据结构。
file结构体如下:
struct file { ...
spinlock_t f_lock; /* 自旋锁 */ fmode_t f_mode; /* 文件模式 */ atomic_long_t f_count; /* 文件引用计数 */ struct mutex f_pos_lock; /* 互斥锁 */ loff_t f_pos; /* 当前文件读写位置 */ unsigned int f_flags; /* 文件标志 */ struct fown_struct f_owner; /* 文件所有者 */
struct path f_path; /* 文件路径,包含dentry结构体和vfsmount结构 */ struct inode *f_inode; /* 指向inode结构体的指针 */ const struct file_operations *f_op; /* 文件操作方法集 */ u64 f_version; /* 版本号 */ #ifdef CONFIG_SECURITY void *f_security; /* 存储与文件安全相关的数据 */ #endif void *private_data; /* 私有数据 */ struct address_space *f_mapping; /* 指向address_space结构体 */ } __randomize_layout __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
2.5 VFS关系图:
三、path_walk过程
path_walk是通过文件路径查找其在vfs中dentry和inode的过程,查找过程如下图:


打开一个文件的调用链: open -> sys_open -> do_sys_open -> do_filp_open -> path_openat
path_openat会执行 alloc_empty_filp、path_init、link_path_walk、do_last、terminate_walk从而完成路径的查找。

3.1 do_sys_open:
do_sys_open()函数首先调用build_open_flags()将传递进来的flags进行解析并存在op中,并调用getname把用户态的文件路径字符串拷到内核态,接着调用get_unused_fd_flags()获取一个可用的文件描述符fd,接着调用do_filp_open()创建文件结构f,并通过fd_install()将f其和文件描述符fd关联起来。这里的文件结构f即上文所述的结构体file。
传入文件描述符表后,首先将fd赋值为files->next_fd,然后通过find_next_fd()去检查是否可用,如果不可用则会继续自增直至找到可用的文件描述符。找到之后,会将files->next_fd赋值为fd + 1以备下次使用,最后调用__set_open_fd()将fd位表的修改赋给fdt并保存。
3.2 alloc_empty_filp:
调用alloc_empty_filp() 生成一个 struct file 结构体,实际最终调用kmem_cache_alloc()分配,即采用前文所述的slab分配器分配;
3.3 path_init简述:
1:nd(nameidata)初始化
struct nameidata { struct path path; //存储文件挂载点和dentry地址 struct qstr last; //路径名最后分量 struct path root; //存在文件所在文件系统根的信息 struct inode *inode; //path.dentry.d_inode unsigned int flags; //标志 unsigned seq, m_seq; //seq 是相关目录项的顺序锁序号; m_seq 是相关文件系统(其实是mount)的顺序锁序号 int last_type; //路径最后的文件类型 unsigned depth; //解析符号链接过程中的递归深度 char *saved_names[MAX_NESTED_LINKS + 1]; //相应递归深度的符号链接的路径 };
enum {LAST_NORM, LAST_ROOT, LAST_DOT, LAST_DOTDOT, LAST_BIND};
//分别代表了普通文件,根文件,.文件,..文件和符号链接文件
1:初始设置nd->last_type= LAST_ROOT,搜索路径名的过程中,值会根据情况改变,如:enum {LAST_NORM, LAST_ROOT, LAST_DOT, LAST_DOTDOT, LAST_BIND} ,如果最后停留在点上,用LAST_DOT记录,如果成功找到了这一级的目标文件,就用LAST_NORM表示正常。
2:然后查看条件(flags & LOOKUP_ROOT)是否满足,当root目录的数据结构struct path不为空时,flag的这个bit才会拉高,此时从根目录开始搜索,一般不会满足。
3:调用read_seqbegin(&mount_lock),获取一个顺序锁,它给写操作赋予了更高的优先级,在使用顺序锁时即便正在进行读操作,写动作也可以进行。其优点在于写者永远不会由于有读者正在进行读而等待,其缺点在于读者可能需要尝试读好多次才能读到合法的数据。
4:判断路径名nd->name->name是否是根目录开始搜索,如果是,在不考虑RCU的情况下(为方便分析,不考虑RCU的链表搜索方式),调用set_root->get_fs_root首先设置nd->root=current->fs->root,然后调用path_get->mntget->mnt_add_count,将nd->root->mnt->mnt_count加1,由于每当将一个设备mount到某个节点时,内核都要为其建立一个vfsmnt结构,该结构包含设备信息和节点信息。因此此处加1表示在整个VFS下,搜索到当前挂载在此目录下的数目加1。同时调用path_get-> dget->lockref_get将nd->root->dentry->d_lockref->count加1,表示当前dentry结构的用户增加了一个。
5:接步骤4的判断,如果不是根目录的情况下,(nd->dfd== AT_FDCWD)条件满足,表示使用相对目录,则调用get_fs_pwd(current->fs,&nd->path)。代码如图所示
首先将当前进程的当前目录的struct path pwd作为入参传给path_get。之前介绍过pwd的作用,此处正是利用了pwd的dentry和mnt结构中存储的信息来做相对路径搜索的初始化。path_get函数在上一步已经分析过。
6:如果某目录已经被当前进程打开,则根据文件描述符fd.file->f_path.dentry找到dentry,且nd->path= f.file->f_path,最后调用path_get(&nd->path)做类似步骤4,5的操作。
7:最后设置nd->inode= nd->path.dentry->d_inode。
enum {LAST_NORM, LAST_ROOT, LAST_DOT, LAST_DOTDOT, LAST_BIND};
LAST_NORM 就是普通的路径名;LAST_ROOT 是 “/”;LAST_DOT 和 LAST_DOTDOT 分别代表了 “.” 和 “..”;
2. 路径不是绝对路径,我们指定从当前目录开始开始查找
3. 函数第一个参数@dfd是一个目录文件描述符,我们就从这个目录开始查
用于检查'jumped'的dentry,即那些不是通过lookup获取的dentry,如'', '.'或者'..'。这种场景只需要检查dentry对应inode是否OK即可。该函数不会在rcu-walk模式下调用,所以可以放心的使用inode。*/
| | |-->hash = init_name_hash(); # 算出该文件名的哈希值,和文件名长度。
| | |-->## 判断文件名是否使用了"."或者"..",来标明文件类型type ##
| | |-->d_hash # 重新计算hash值
| | |-->walk_component # 依据刚刚识别的类型,做单次搜索。
| | | |-->handle_dots # "." 和 ".." 文件名处理。
| | | |-->do_lookup # 其他文件的搜索。
| | | | |-->__d_lookup_rcu # 带rcu搜寻。
| | | | |-->__d_lookup # 不带rcu,可能引起阻塞搜寻。
| | | | |-->d_alloc_and_lookup # 上两步搜不到,就要通过硬盘文件系统搜寻。
| | | |-->should_follow_link # 查看是否可以继续链接文件,前面提到过,对链接次数有限制。
| | |-->nested_symlink # 限制递归调用不能超过8次,符号链接不能超过40次。
| | |-->can_lookup # 判断是否可以继续查找,可以则继续。
| | |-->terminate_walk(nd); # 查找完成操作,包括解RCU锁。
/*
RCU机制的实现细节:
RCU机制通过复制被保护数据结构的副本来实现读写并发。当写者需要修改数据时,它会先复制数据的一个副本,并在副本上进行修改,而不会直接修改原始数据。
修改完成后,写者会在合适的时机(如所有读者都完成了对原始数据的访问后)将修改后的副本替换回原数据。这个替换过程通常是通过原子操作完成的,以确保数据的一致性和完整性。
RCU机制的适用场景:读多写少的场景,像文件目录这种极少修改的内容,是RCU的极佳使用场景
除了读多写少的场景外,RCU机制还适用于那些对读取性能要求很高,但对数据一致性要求不是非常严格的场景。例如,文件系统的目录结构、网络配置信息等。在这些场景下,即使读者读取到的是旧的数据版本,也不会对系统的整体性能和稳定性造成太大的影响。
RCU机制优势::
与传统的锁机制相比,RCU机制在读写并发性能方面具有明显的优势。它允许读者和写者并发地访问和修改数据,而无需等待锁释放或进行上下文切换。RCU机制缺点:如果读取的数据正在被修改,可能需要多次读取才能读取到最新数据,
在数据一致性要求非常高的场景下,RCU机制可能并不是一个很好的选择此外,RCU机制的实现相对复杂,需要仔细处理各种同步和一致性问题。
综上所述,RCU机制是一种高效的并发控制机制,适用于读多写少、对读取性能要求高但对数据一致性要求不是非常严格的场景
4:在开始搜索之前假定type= LAST_NORM,然后判断name[0]== '.',再判断name[1]== '.',如果都满足,则标记type= LAST_DOTDOT,后文将向上级目录搜索。如果第二条不满足,则标记type= LAST_DOT,表示搜索到一个隐藏文件或者表示当前目录。
5:如果经过步骤4,type ==LAST_NORM仍然成立,说明不需要往上搜索,首先清除nd->flags&= ~LOOKUP_JUMPED,然后确定nd->path.dentry->d_flags的DCACHE_OP_HASHbit是否拉高,拉高则需要调用nd->path.dentry->d_op->d_hash来重新计算hash值,有些情况下搜索过程可能会跳到另一个文件系统中去,所以会有重新计算的需求。
6:此时还需进一步判断name指针偏移hash_len之后是否为“/0“,表示路径到头了,如果初始需要搜索的路径为”/home“就是这种情况,此时直接跳到”OK“标签处的代码,如果不为空,则自加,防止home///usr的情况,此时则自加三次,name指针指向”usr“,为下次搜索做好准备。
7:接着步骤6来看下OK标签处的代码,首先判断!nd->depth,表示符号递归深度为0,解析完成了,直接退出;再查看nd->stack[nd->depth- 1].name,表示相应递归深度对应的符号链接,如果递归深度不为0,但对应的符号链接为0,也可以直接退出了。
8:如果没有退出则调用walk_component进行搜索,这个API非常重要。
8.1:首先检查nd->last_type!= LAST_NORM,步骤4中分析过type的值遇到“.“时会做一些标记,如果不是LAST_NORM就要调用handle_dots->follow_dotdot处理点的问题,由于一个点只是表示隐藏文件或者当前目录,隐藏文件按正常搜索处理即可,当前目录可以不做任何处理。两个点就表示上一级了。
8.1.2:其次判断(nd->path.dentry != nd->path.mnt->mnt_root)
8.1.4:最后处理特殊挂载点的情况,如果一个挂载点挂载了多个文件系统就需要进行特殊处理。
8.2:处理完带点的情况,检查if(flags & WALK_PUT),如果为高则调用put_link(nd)释放nd中的链接数据。步骤7中展示过,递归深度为0或者无链接符号时便是这种情况。
8.3:调用lookup_fast。lookup_fast在之前的内核中叫cached_lookup,意思就是在内存中寻找已经建立起来的dentry结构。内核中有一个hash表—dentry_hashtable,他是一个list_head指针数组,一旦在内存中建立起一个dentry数据结构,就根据其节点(比如“/home/usr”中,/home和/home/usr都是一个节点)的hash值将其加入dentry_hashtable。所以使用link_path_walk查找dentry的过程中,当前节点的上游节点都已有dentry位于内存中。
使用lookup_fast查找内存中路径的过程又分RCU模式__d_lookup_rcu和非RCU模式__d_lookup两种场景,RCU模式为无锁操作,性能比非RCU模式高,但是RCU模式不能保证读到的数据是最新的,所以存在lookup失败的可能,如果失败的话,会通过unlazy_wlak清除flags中的LOOKUP_RCU属性,通过非RCU模式__d_lookup再执行一次查找。如果内存中找不到当前节点的dentry结构,则进一步通过lookup_slow去硬盘上上寻找到inode信息,并组装dentry结构,然后挂入哈希表。
内核中还有一个队列dentry_unused来记录用户数目为0 (步骤4中分析过nd->root->dentry->d_lockref->count表示该dentry用户数)的dentry结构。这是一个LRU队列(Leastrecently used,最近最少使用),当内核做内存回收时,将从LRU中回收最先放入其中的dentry。调用dput()API将回收dentry的计数器清0。Dentry中总共有6个list_head结构,list_head既可以用作一个队列的头部,也可以挂入到其他队列中,例如list_headd_hash可以挂入内核中的dentry_hashtable。
有了以上基础认识再来看lookup_fast,由于步骤2中已经调用may_lookup->unlazy_walk清除flags中的LOOKUP_RCU属性,因此此处直接调用__d_lookup,首先调用d_hash(parent,name-> hash)重新计算name的hash值,计算时带上了parent节点的dentry(此处为nd->path.dentry,即已经处理过的完整路径),这样做的原因是例如在计算机机房里很多学生都在/home/xxx(各自的姓名)下面创建了project,那么在该dentry的list_headd_hash中,将有很多个成员,这个d_hash挂入内核中的dentry_hashtable中后,搜索这个节点将有很多线性搜索,加上parent dentry重新hash可以减少哈希碰撞接下来就根据hash值在内存中寻找dentry,如果dentry->d_name.hash== name->hash,则表示找到了想要的dentry,然后检查dentry的d_parent,d_flags,d_flags等成员是否符合预期,如果都正确,则dentry->d_lockref.count++,将dentry用户再加1。然后返回lookup_fast,如果dentry为空,则拉高need_lookup,表示需要lookup_slow。同时还要调用d_revalidate(dentry,nd->flags),防止在搜索过程中,内存保存的dentry又失效了,如果不幸失效,调用d_invalidate(dentry)处理。最后还要调用d_is_negative(dentry)。如果以上一切都通过,则执行path->mnt= mnt;path->dentry = dentry;表示找到待处理的路径名对应的dentry和vfsmount结构。接下来调用follow_managed处理dentry中mount相关的flag,比如是否是automount,是否需要手动mount。最后调用*inode= d_backing_inode(path->dentry)获取dentry对应的inode
8.4.1:首先调用lookup_dcache->d_lookup->__d_lookup再来一次fast搜索,万一这间隙,其他线程创建了dentry呢?
8.4.2:然后才调用lookup_real中的API:nd->path.dentry->d_inode ->i_op->lookup(nd->path.dentry->d_inode, dentry,flags),即已搜索路径的dentry对应的inode中的操作函数lookup,入参是nd->path.dentry->d_inode。对于EXT4来说,这个API是ext4_lookup。
其中最重要的两个调用是ext4_find_entry和ext4_iget_normal,首先看ext4_find_entry,其目的是找到目录名的dentry,并返回目录所在的page cache对应的bufferhead。
8.4.2.1:首先从调用sb= dir->i_sb,即从nd->path.dentry->d_inode获取super block,dentry中的super block都是从父节点继承过来的。
8.4.2.2:如果节点名字太长,需要调用ext4_fname_setup_filename(dir,d_name, 1, &fname)使用fname额外存储名字。
8.4.2.3:如果有内联数据,调用ext4_has_inline_data处理。内联数据的特性,可以有效的减少磁盘次数,对于小文件的处理可以提高很大的性能。原始的ext4文件所有数据采用的都是blocks的map方式在逻辑块和物理块之间的转换,小文件为包括字节数一般为几十个字节,会带来很多碎片。采用inline data的方式,会将文件的数据直接放在inode的后面,此时的inode为扩大的inode,需要进行扩大处理。
8.4.2.4:如果路径名中出现了"."or "..",则设置block= start = 0;nblocks = 1然后直接跳到restart处。
8.4.2.5:再来看下restart标记的while循环,其功能是执行硬盘读数据操作。首先调用cond_resched主动让出cpu,为接下来从硬盘拷贝数据做准备。由于硬盘的物理特性,读一个记录块很消耗时间,而且大部分消耗在准备工作上,因此读一个记录块与读几个记录块时间起始差不多,所以读硬盘最好的办法就是预读一些记录块,EXT4最多预读八个记录块,读回来的数据会用buffer来管理。因此代码中使用bh_use[8]来存储预读回来的8个记录块的bufferhead指针。读数据的API是ext4_getblk,其返回bufferhead指针。
8.4.2.6:由于CPU读数据是异步,因此调用wait_on_buffer等待记录块到位。然后就带着bh返回上一级。
8.4.3:ext4_find_entry返回后,获得了路径名在磁盘上数据对应的bufferhead指针。有了bh即有了raw_inode,然后就调用ext4_iget_normal->ext4_iget(sb,ino)在内存中组织起inode结构,和dentry一样,构建好inode后,计算一个hash值并加入列表。
8.4.4:上一步建立了inode,然后就需要调用d_splice_alias中的security_d_instantiate->call_void_hook将inode和dentry绑定。最好还要调用d_rehash(dentry)将dentry计算hash值并加入内核中的dentryhash列表。
到这一步,dentry终于在内存中建好了,返回walk_component中进行步骤8.5。
8.6:调用path_to_nameidata(&path,nd)将dentry信息传入nameidatand中。
至此,对路径名中的一个节点搜索就完成了,回到link_path_walk中执行循环for(;;),直到所有节点都搜索完成。
在Kernel 中任何一个常用操作都会有两套以上的策略,其中一个是高效率的(lookup_fast),另一个效率低但是搜索的成功率高(lookup_slow)。Kernel 会在rcu-walk 模式下会首先进入 lookup_fast 进行尝试,如果失败了那么就尝试就地转入 ref-walk,如果还是不行就回到 do_filp_open 从头开始。Kernel在 ref-walk 模式下会首先在内存缓冲区查找相应的目标(lookup_fast),如果找不到就启动具体文件系统自己的 lookup 进行查找(ext4_lookup)。因此,在 rcu-walk 模式下不会进入lookup_slow 。如果有权限问题或者不适合ref-walk mode,将中止搜索,前者原因好理解,后者意思是如果rcu-walk mode找不到(这种情况概率挺大的),又无法使用ref-walk mode,将报找不到文件的错误。LOOKUP_JUMPED:用于检查'jumped'的dentry,即那些不是通过lookup获取的dentry,如'', '.'或者'..'。这种场景只需要检查dentry对应inode是否OK即可。该函数不会在rcu-walk模式下调用,所以可以放心的使用inode。
| | -->walk_component
| | -->mnt_want_write # 获取对文件系统的写访问权限
| | -->lookup_open
| | |-->d_lookup # 在内存的目录项缓存中查找
| | |-->如果没有找到,调用dir_inode_i_op->lookup()进行查找
| | |-->如果两次都没有找到
| | | | |-->may_o_create # 检查是否有创建文件的权限
| | | | |-->dir_inode_i_op->create() #创建文件
| | | | |-->fsnotify_create # 通告创建文件事件
| | -->may_open # 检查访问权限
| | -->vfs_open
| | |-->do_dentry_open
| | | |-->调用文件操作集合的open方法
1:获取文件对应的 inode 对象,并且初始化 file 对象
| 设置 f->f_mapping 为inode->i_mapping;
| 执行f->f_op->open
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev) { inode->i_mode <span class<font="" color="#67cdcc">= mode; if (S_ISCHR(mode)) { inode->i_fop <span class<font="" color="#67cdcc">= &def_chr_fops; // 字符设备方法 inode->i_rdev <span class<font="" color="#67cdcc">= rdev; } else if (S_ISBLK(mode)) { inode->i_fop <span class<font="" color="#67cdcc">= &def_blk_fops; // 块设备方法 inode->i_rdev <span class<font="" color="#67cdcc">= rdev; } else if (S_ISFIFO(mode)) inode->i_fop <span class<font="" color="#67cdcc">= &pipefifo_fops; // FIFO文件方法 else if (S_ISSOCK(mode)) ; /* leave it no_open_fops */ else printk(KERN_DEBUG "init_special_inode: bogus i_mode (%o) for" " inode %s:%lu\n", mode, inode->i_sb->s_id, inode->i_ino); } EXPORT_SYMBOL(init_special_inode);
.llseek = noop_llseek,
};
主要做一些最终的资源释放工作,会将对路径的引用释放,同时将查找过程中跨越的符号链接引用释放掉,解RCU锁,并将nameidata的深度置为0。
d_alloc_root调用d_instantiate填充dentry的inode信息
d_instantiate调用__d_instantiate将inode指针设置到dentry的d_inode中
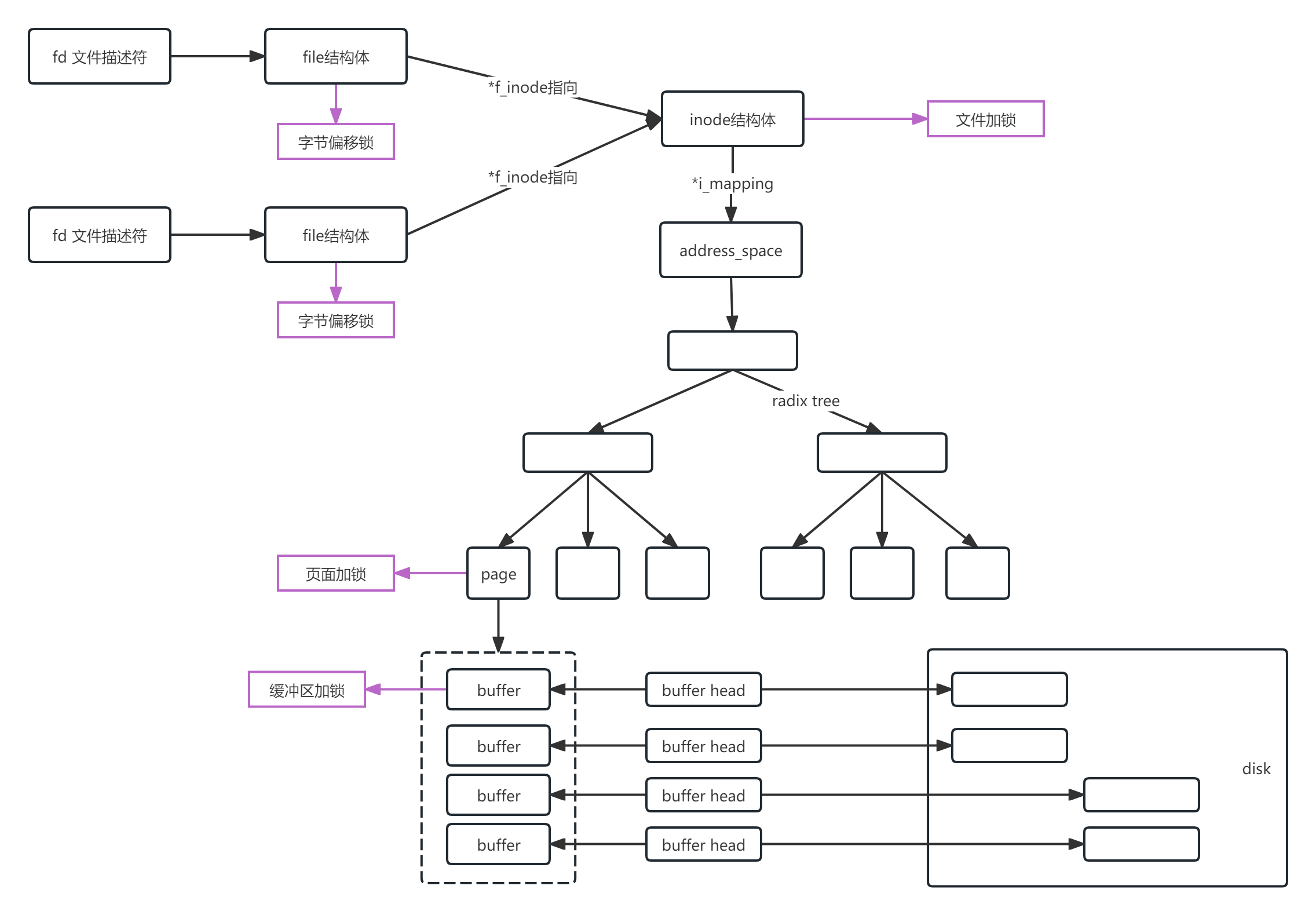
四、VFS和内存页的交互以及文件锁
五、内存页和磁盘的交互
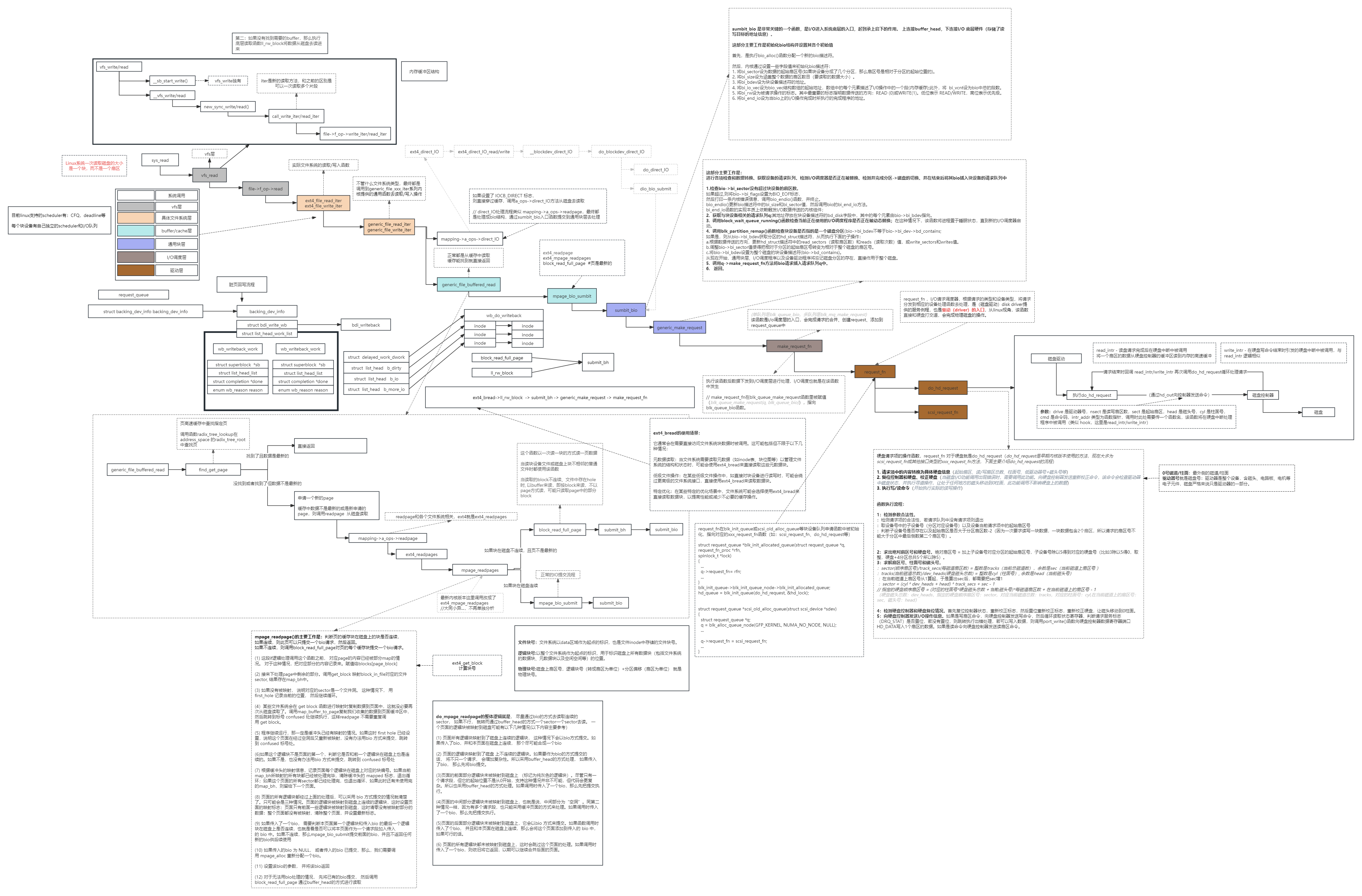
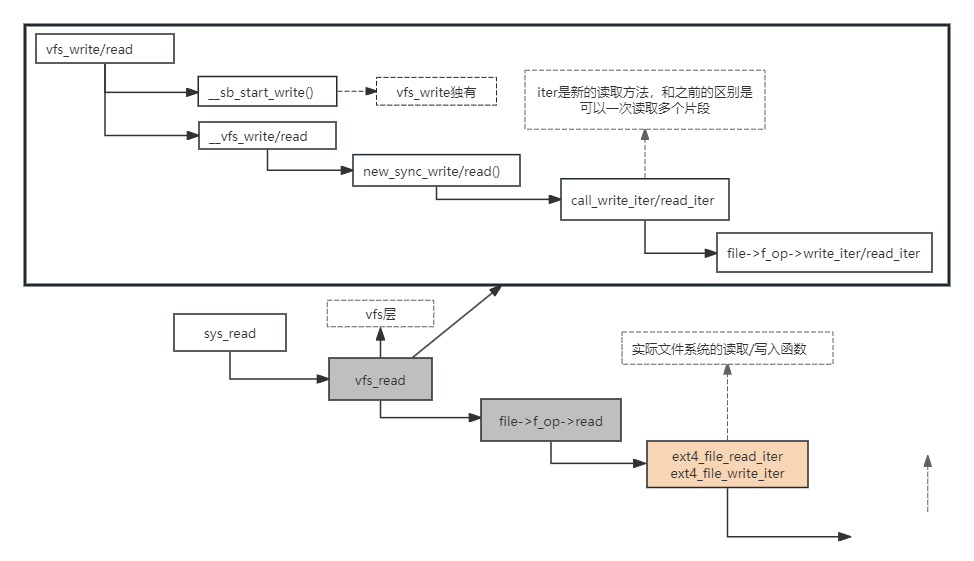
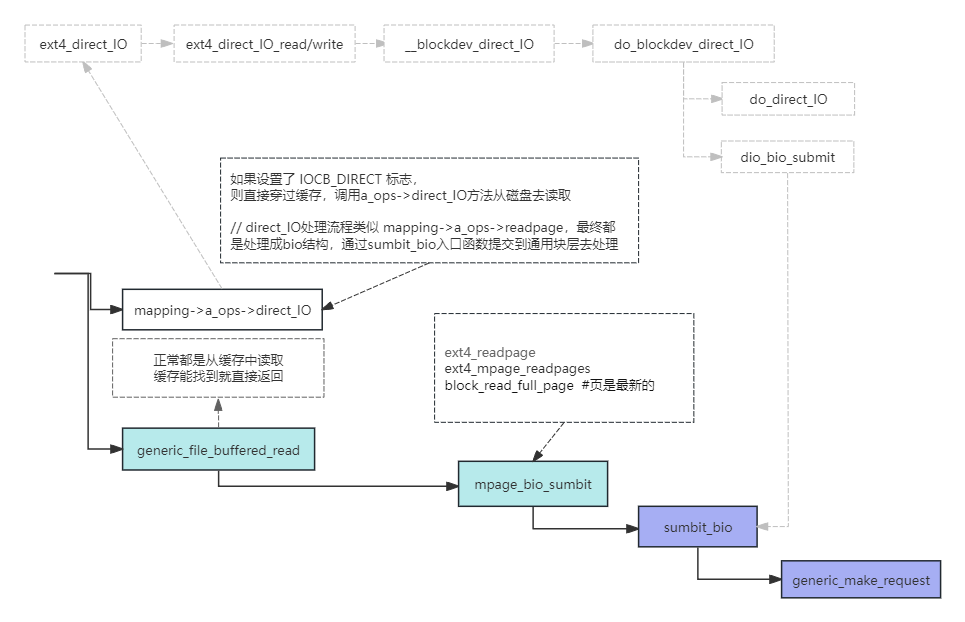
1:先看下sys_read调用链
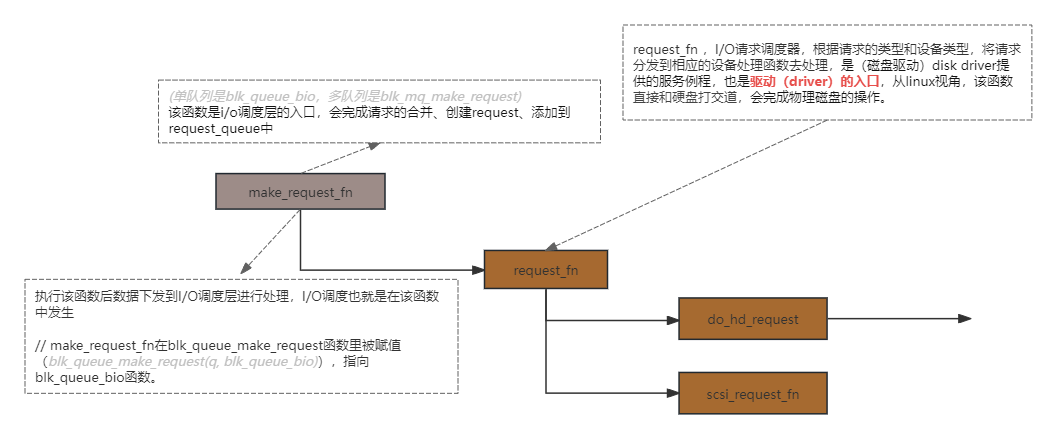
sys_read -> vfs_read file -> f_op->read -> ext4_file_read_iter -> generic_file_read_iter -> mapping->a_ops->direct_IO -> generic_file_buffered_read -> mpage_bio_sumbit -> sumbit_bio -> generic_make_request -> make_request_fn -> request_fn do_hd_request -> scsi_request_fn
2:文件系统整体层次分布

3:buffer和page映射关系
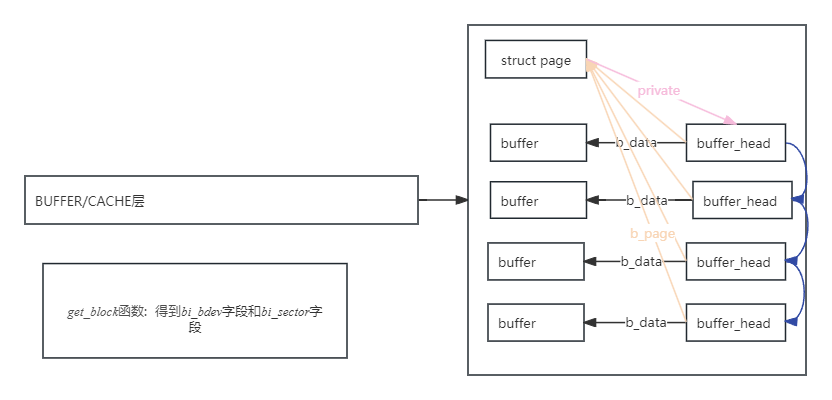
4:buffer_head和b_state
buffer_head:
b_next:指向具有相同hash值的下一个缓冲头,用于链接到块缓冲区的hash表 b_blocknr:本block的块号 b_size:block的大小 b_list:表示当前的这个buffer在那个链表中 b_dev:虚拟设备标识 b_count:引用计数(几个人在使用这个buffer) b_rdev:真实设备标识 b_state:状态位图,如下: b_flushtime:脏buffer需要被写入的时间 b_next_free:指向lru链表中next元素 b_prev_free:指向链表上一个元素 b_this_page:连接到同一个page中的那个链表 b_reqnext:请求队列 b_pprev:hash队列双向链表 b_data:指向数据块的指针 b_page:这个buffer映射的页面 b_end_io:IO结束时候执行函数 b_private:保留 b_rsector:缓冲区在磁盘上的实际位置 //在submit_bh方法中会转换成真实的扇区号 b_inode_buffers:inode脏缓冲区循环链表
b_state:
BH_Uptodate, /* 如果缓冲区包含有效数据则置1 */ BH_Dirty, /* 如果buffer脏(存在数据被修改情况),那么置1 */ BH_Lock, /* 如果缓冲区被锁定,那么就置1 */ BH_Req, /* 如果缓冲区无效就置0 */ BH_Mapped, /* 如果缓冲区有一个磁盘映射就置1 */ BH_New, /* 如果缓冲区是新的,而且没有被写出去,那么置1 */ BH_Async, /* 如果缓冲区是进行end_buffer_io_async I/O 同步则置1 */ BH_Wait_IO, /* 如果要将这个buffer写回,那么置1 */ BH_Launder, /* 如果需要重置这个buffer,那么置1 */ BH_Attached, /* 1 if b_inode_buffers is linked into a list */ BH_JBD, /* 如果和 journal_head 关联置1 */ BH_Sync, /* 如果buffer是同步读取置1 */ BH_Delay, /* 如果buffer空间是延迟分配置1 */ BH_PrivateStart,/* not a state bit, but the first bit available * for private allocation by other entities * 当数据被写入缓冲块但没有写入设备时b_dirt=1,b_uptodate=0。特殊情况:在新申请的一个设备缓冲块时b_dirt与b_uptodate都为1,表示缓冲块中数据虽然与块设备上的不同,但是数据有效。
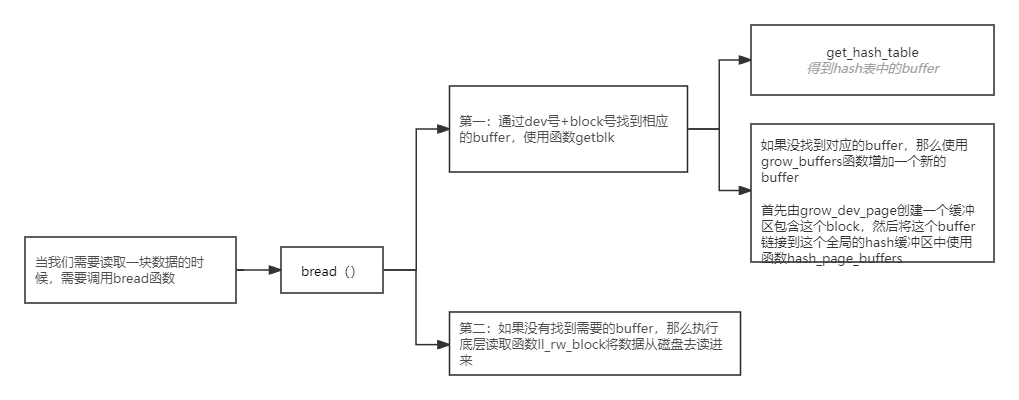
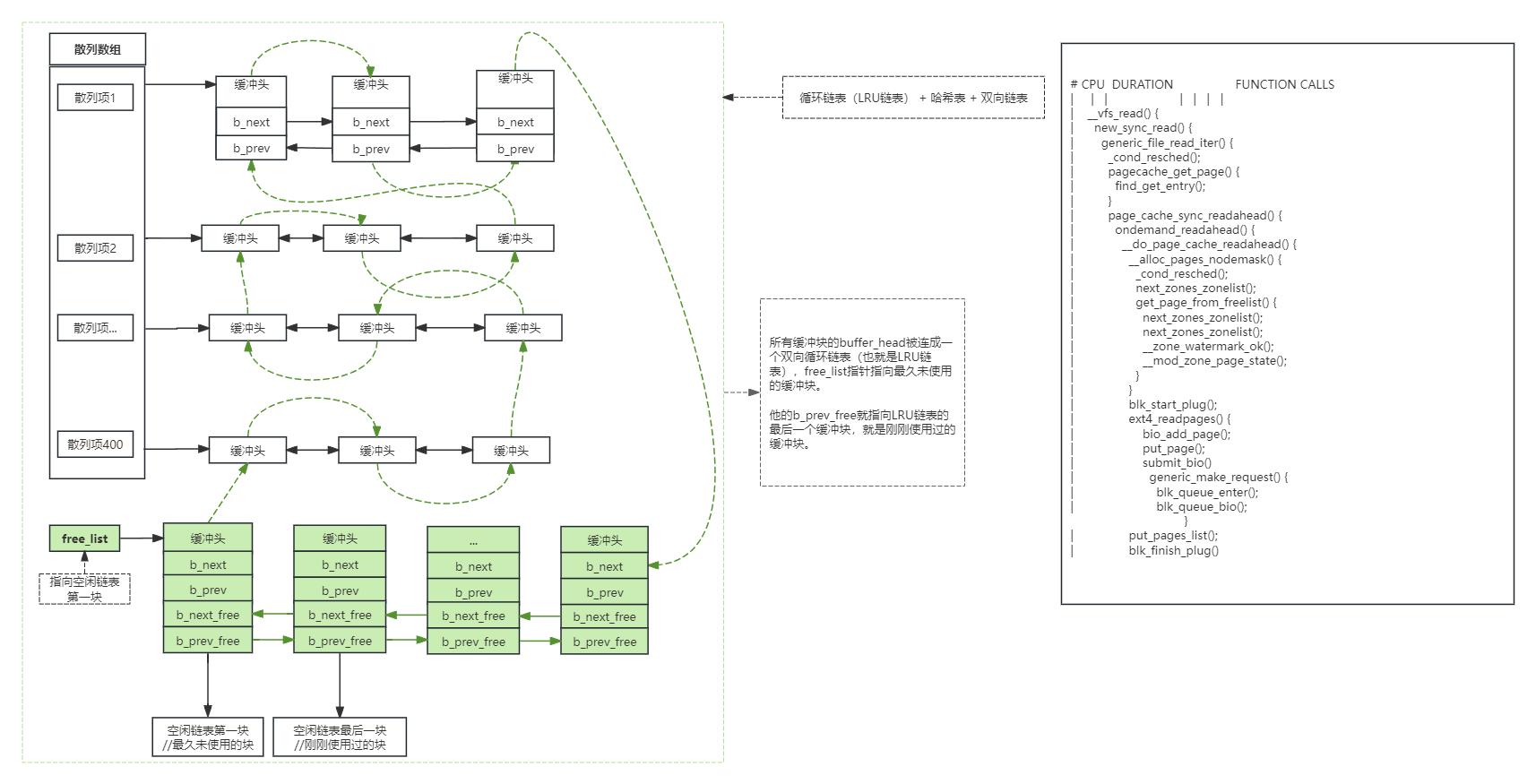
5:buffer缓冲区:
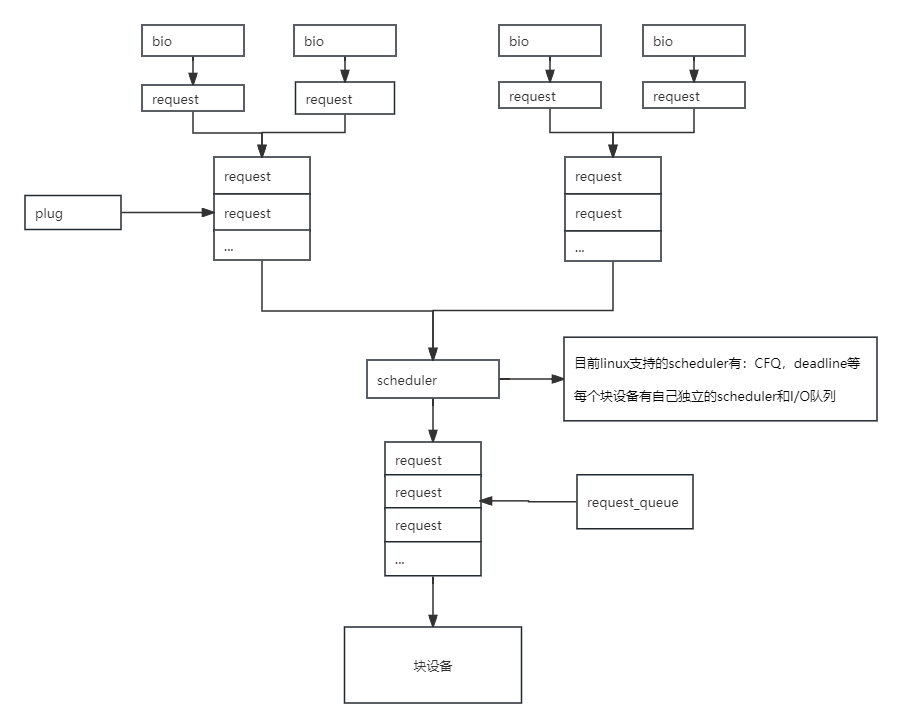
6:数据下发到磁盘流程
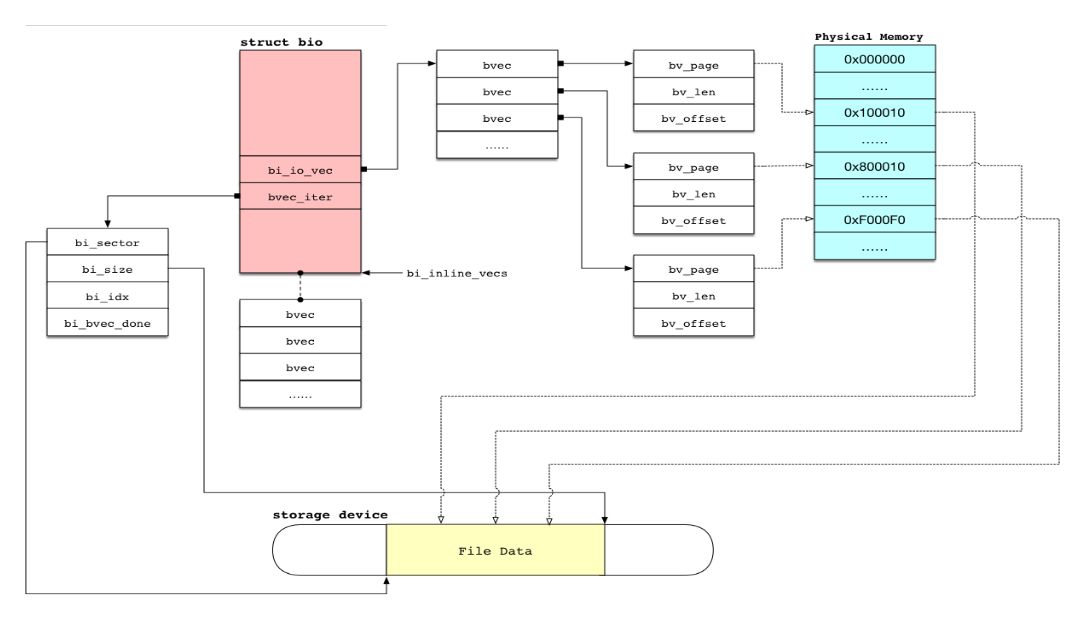
7:bio结构
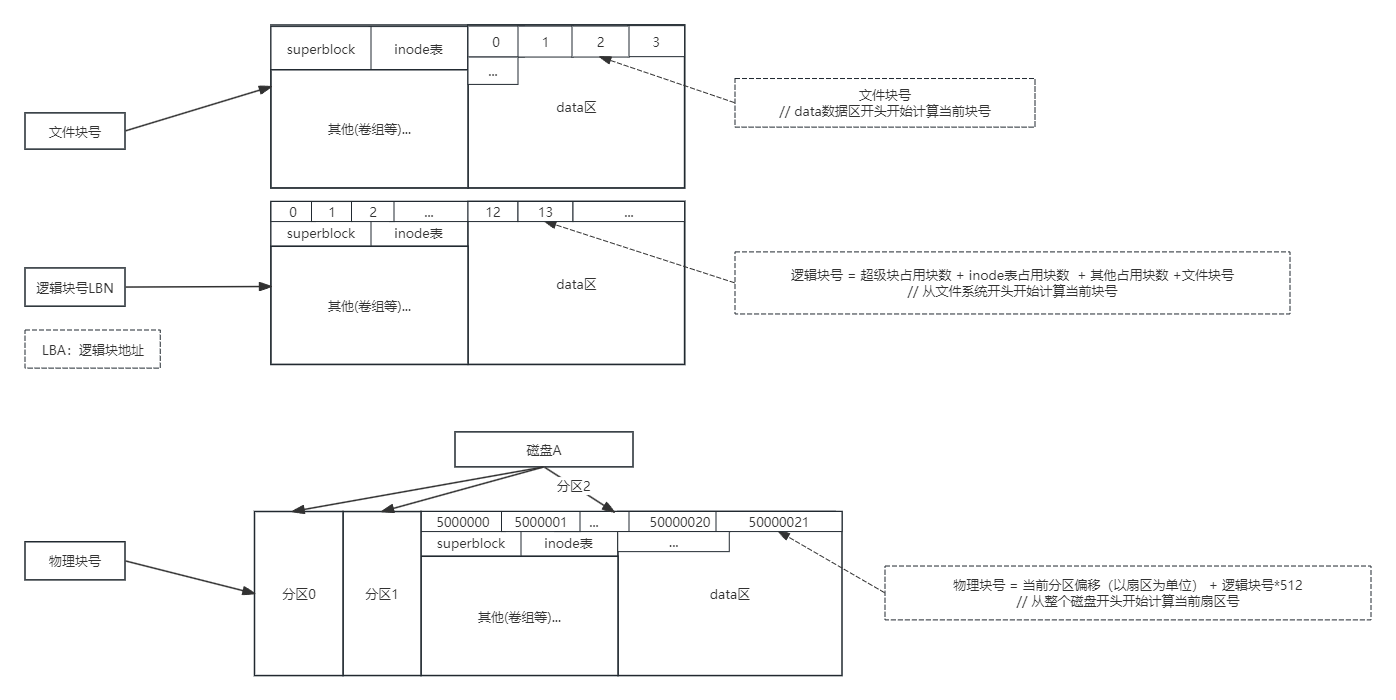
8:文件、逻辑、物理块号
9:磁盘相关参数

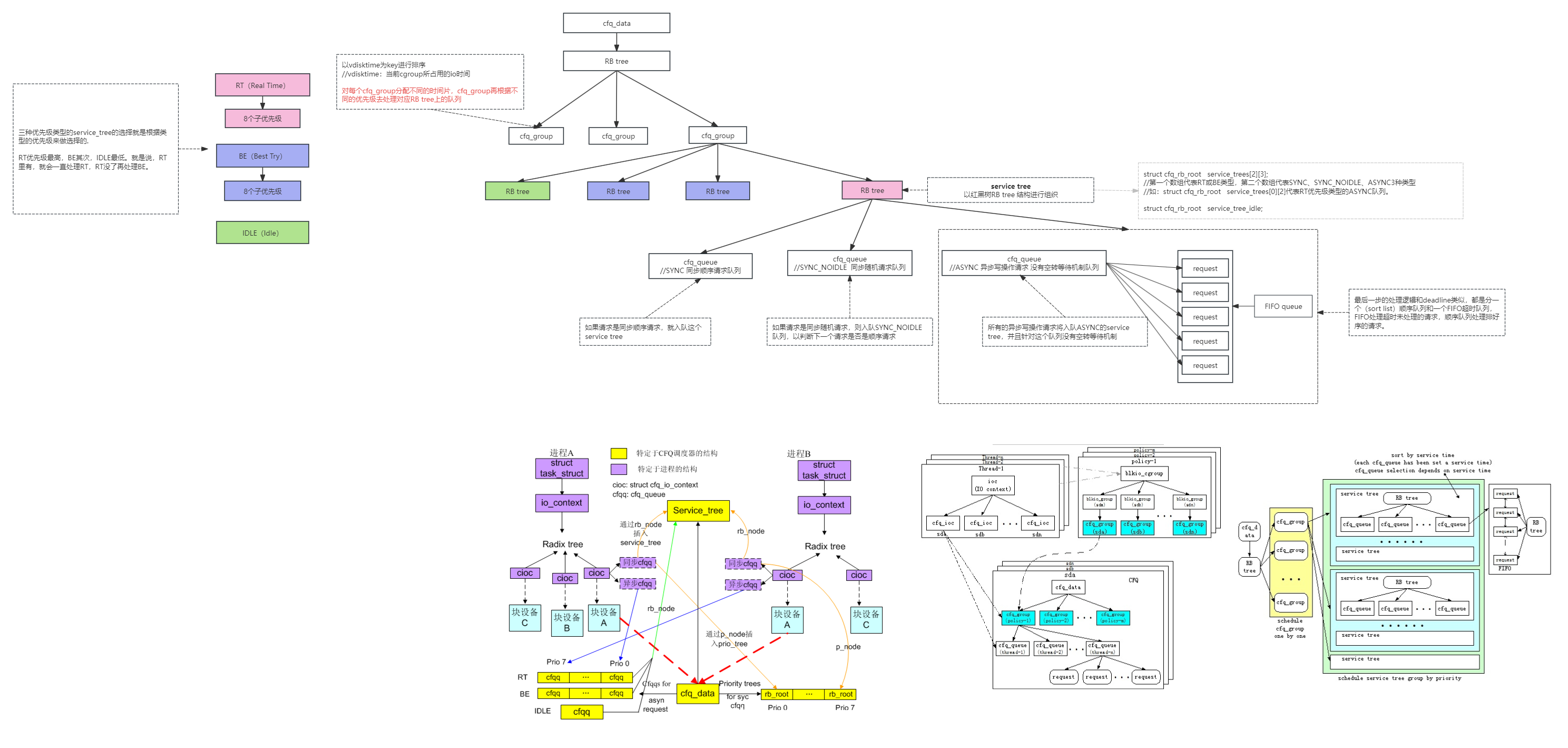
10:调度算法


11:完整调用链
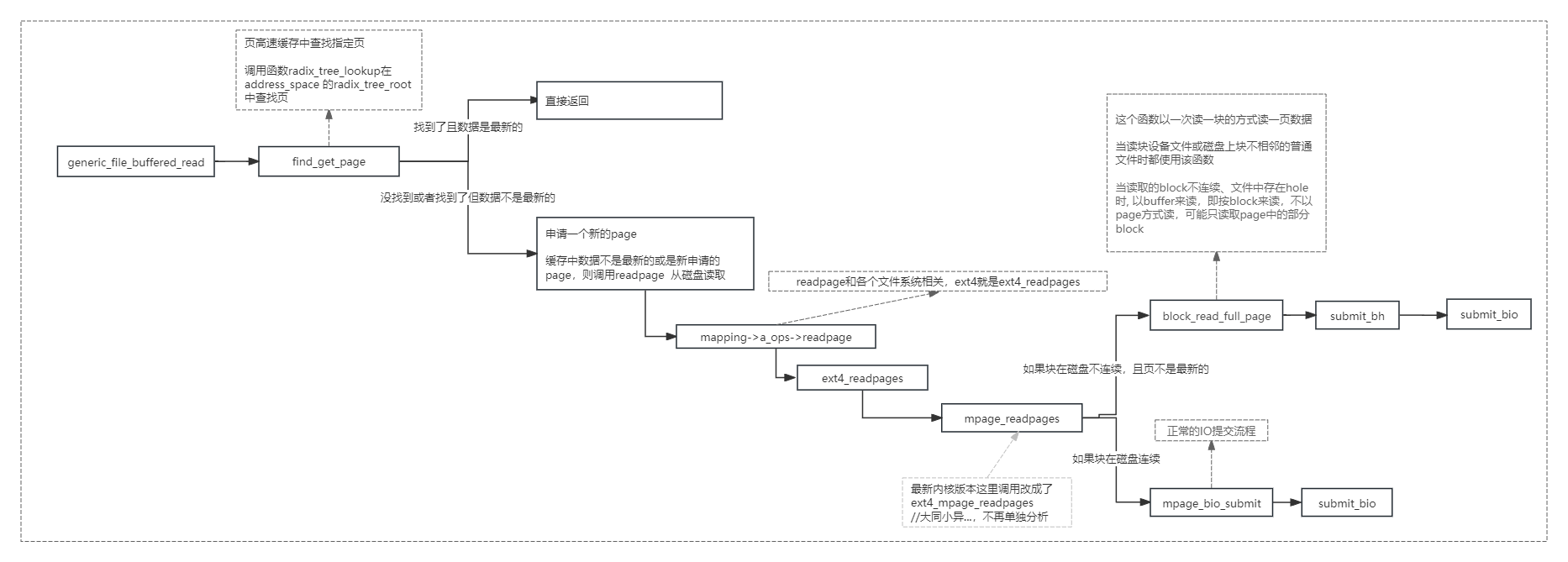
上图流程详解:
mpage_readpage()的主要工作是:判断页的缓存块在磁盘上的块是否连续,
如果连续,则此页可以只提交一个bio请求,然后返回。
如果不连续,则调用block_read_full_page对页的每个缓存块提交一个bio请求。
(4)某些文件系统会在 get block 函数进行映射时复制数据到页面中,这就没必要再次从磁盘读取了。调用map_buffer_to_page复制我们收集的数据到页面缓冲区中,然后跳转到标号 confused 处继续执行,这样readpage 不需要重复调用 get block。
(5) 程序继续运行,那一定是缓冲头己经有映射的情况。如果这时 first hole 已经设置,说明这个页面在经过空洞后又重新被映射,没有办法用bio 方式来提交,跳转到 confused 标号处。
(6)如果这个逻辑块不是页面的第一个,判断它是否和前一个逻辑块在磁盘上也是连续的。如果不是,也没有办法用bio 方式来提交,跳转到 confused 标号处
(7) 根据缓冲头的映射信息,记录页面每个逻辑块在磁盘上对应的块编号。如果当前map_bh所映射的所有块都已经被处理完毕,清除缓冲头的 mapped 标志,退出循环;如果这个页面的所有sector都己经处理完,也退出循环,如果此时还有未使用完的map_bh,则留给下一个页面。
(8) 页面的所有逻辑块都经过上面的处理后,可以采用 bio 方式提交的情况就清楚了。只可能会是三种情况。页面的逻辑块被映射到磁盘上连续的逻辑块,这时设置页面的映射标志;页面只有前面一些逻辑块被映射到磁盘,这时清零没有被映射部分的数据:整个页面都没有被映射,清除整个页面,并设置最新标志。
(9) 如果传入了一个bio, 需要判断本页面第一个逻辑块和传入bio 的最后一个逻辑块在磁盘上是否连续,也就是看是否可以将本页面作为一个请求段加入传入的 bio 中。如果不连续,那么mpage_bio_submit提交前面的bio,并且不返回任何新的bio供后续使用
(10) 如果传入的bio 为 NULL, 或者传入的bio 已提交,那么,我们需要调用 mpage_alloc 重新分配一个bio。
(11) 设置该bio的参数, 并将该bio返回
(12) 对于无法用bio处理的情况, 先将已有的bio提交, 然后调用block_read_full_page 通过buffer_head的方式进行读取
(1) 页面所有逻辑块映射到了磁盘上连续的逻辑块, 这种情况下会以bio方式提交。如果传入了bio,并和本页面在磁盘上连续, 那个尽可能合成一个bio
(2) 页面的逻辑块映射到了磁盘 上不连续的逻辑块。如果要作为bio的方式提交的话, 将不只一个请求, 会增加复杂性。所以采用buffer_head的方式处理, 如果传入了bio, 那么先将bio提交。
(3)页面的前面部分逻辑块未被映射到磁盘上 (标记为纯灰色的逻辑块)。尽管只有一个请求段,但它的起始位置不是从0开始,支持这种情况并非不可能,但代码会更复杂。所以也采用buffer_head的方式处理。如果调用时传入了一个bio,那么先把提交执行。
(4)页面的中间部分逻辑块未被映射到磁盘上,也就是说,中间部分为“空洞”。同第二种情况一样,因为有多个请求段,也只能采用缓冲页面的方式来处理。如果调用时传入了一个bio,那么先把提交执行。
(5)页面的后面部分逻辑块末被映射到磁盘上,它会以bio 方式来提交。如果函数调用时传入了个bio, 并且和本页面在磁盘上连续,那么会将这个页面添加到传入的 bio 中,如果可行的话。
上图详解:
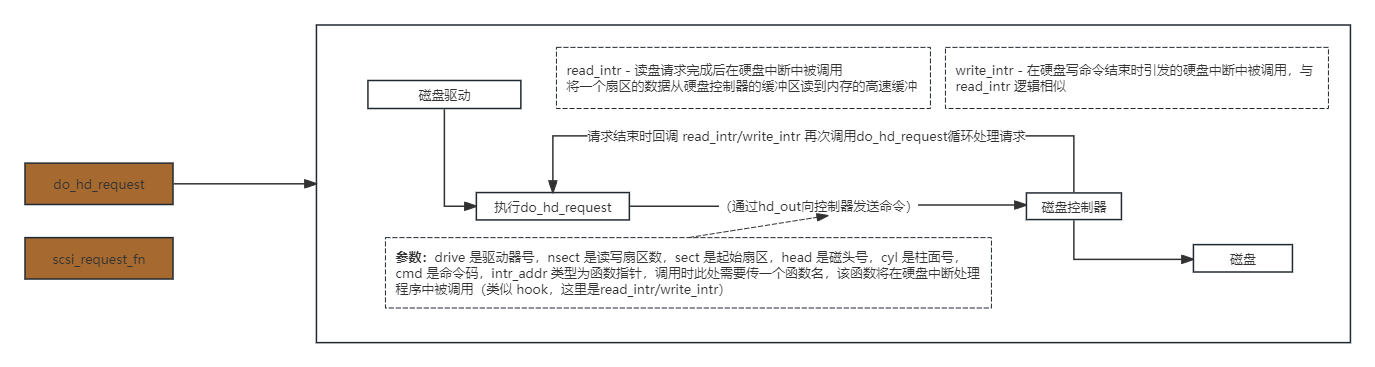
硬盘请求项的操作函数,request_fn 对于硬盘就是do_hd_request(do_hd_request是早期内核版本使用的方法,现在大多为scsi_request_fn或其他接口类型的xxx_request_fn方法,下面主要介绍do_hd_request的流程)
1:检测参数合法性。
:sector(顺序扇区号)/track_secs(每磁道扇区数) = 整数是tracks(当前总磁道数),余数是sec(当前磁道上扇区号 )
:tracks(当前磁道总数)/dev_heads(硬盘磁头总数) = 整数是cyl(柱面号), 余数是head(当前磁头号)
// 指定的硬盘顺序扇区号 = (对应的柱面号*硬盘磁头总数 + 当前磁头号)*每磁道扇区数 + 在当前磁道上的扇区号 - 1
5:向硬盘控制器发送I/O操作信息。如果是写扇区命令,向硬盘控制器发送写命令,然后循环读取状态寄存器,判断请求服务标志(DRQ_STAT)是否置位,若没有置位,则跳转执行出错处理,若可以写入数据,则调用port_write()函数向硬盘控制器数据寄存器端口HD_DATA写入1个扇区的数据。如果是读命令向硬盘控制器发送读扇区命令。
六、设备和驱动
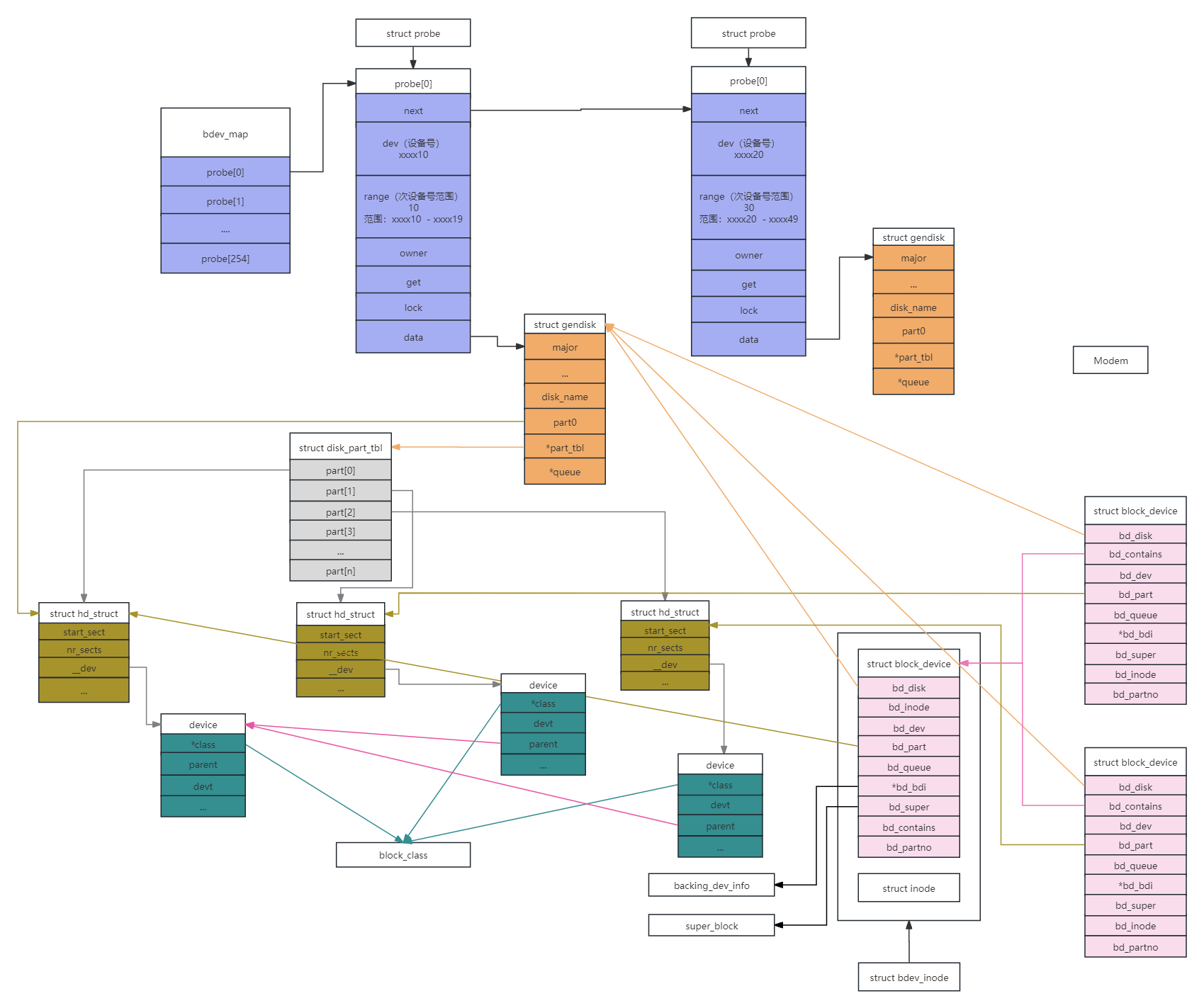
1:申请主设备号
/** * 注册块设备 * @major: 主设备号(0表示由系统自动分配设备号,1~255表示自定义主设备号) * @name: 块设备名称 * * 返回: * 成功返回主设备号,失败返回负值 */ int register_blkdev(unsigned int major, const char *name);
2:申请gendisk
/** * 申请gendisk * @minors 申请的分区数(相当于在告诉内核块设备有多少个分区) * * 返回: * 成功返回gendisk的地址,失败返回NULL */ struct gendisk *alloc_disk(int minors);
上述步骤后会分配gendisk结构,在/sys/block下创建名为disk->name的类,分配device结构并初始化kobj
3:申请并初始化请求队列
/** * 初始化请求队列 * @rfn 请求处理函数 * 函数指针:void (request_fn_proc) (struct request_queue *q) * @lock 自旋锁 * * 返回: * 成功返回请求队列的地址,失败返回NULL */ request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock);
4:初始化gendisk
/** * 设置块设备大小 * @disk gendisk 指针 * @size 块设备大小,单位: 扇区 */ void set_capacity(struct gendisk *disk, sector_t size); /** * 块设备操作函数 * @disk gendisk 指针 * @size 块设备大小,单位: 扇区 */ static struct block_device_operations blkdev_fops = { .owner = THIS_MODULE, }; blkdev.gendisk->major = blkdev.major; // 主设备号 blkdev.gendisk->first_minor = 0; // 起始次设备号 blkdev.gendisk->fops = &blkdev_fops; // 块设备操作函数 blkdev.gendisk->queue = blkdev.queue; // 块设备请求队列 strcpy(blkdev.gendisk->disk_name, blkdev_NAME); // 块设备名称 set_capacity(blkdev.gendisk, DISK_SIZE/512); // 告诉内核块设备大小,单位:扇区
5、向内核注册块设备(磁盘)
/** * 将gendisk添加到内核 * @disk gendisk 指针 */ void add_disk(struct gendisk *disk);
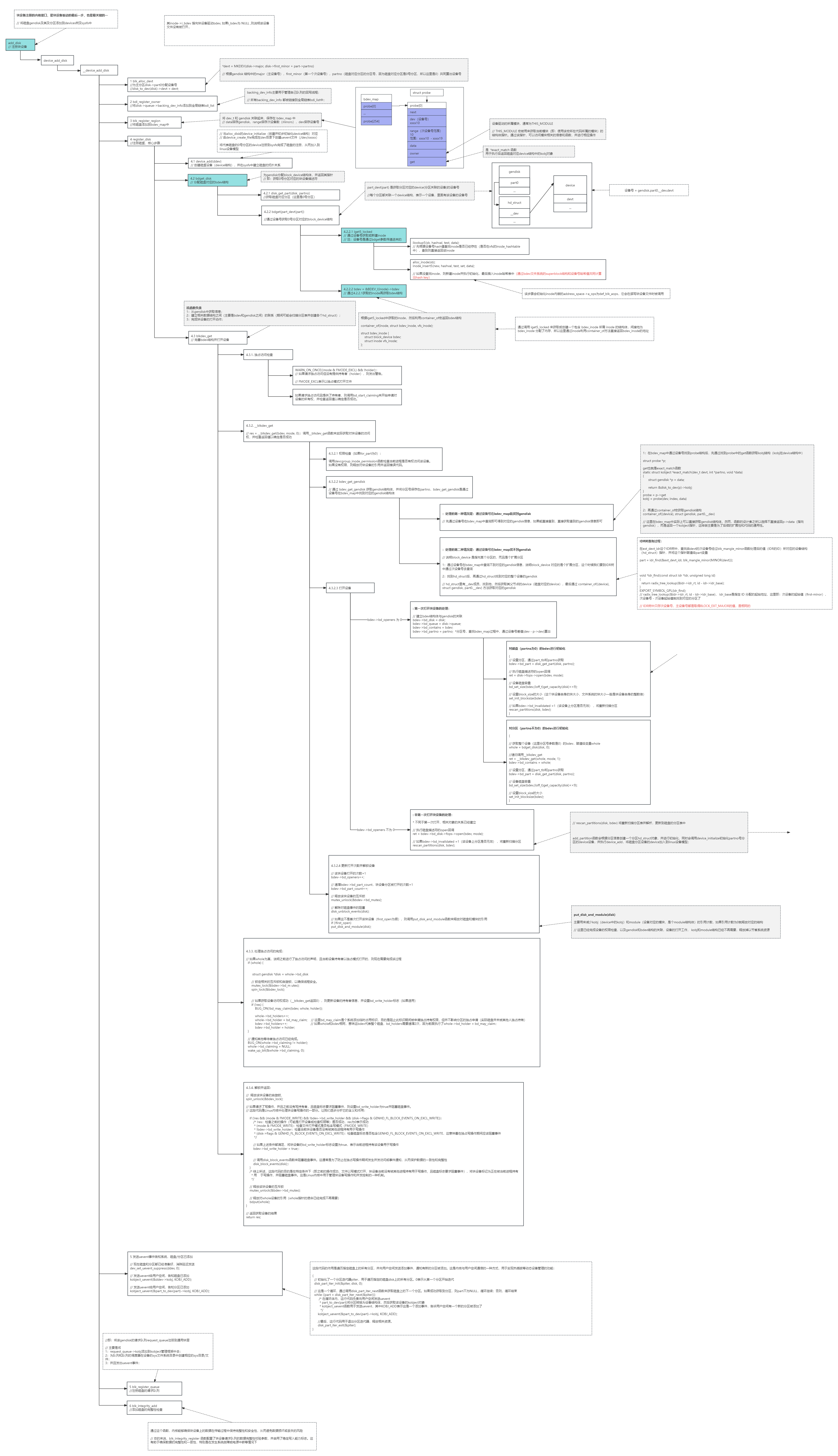
add_disk是块设备注册的内核接口,是块设备驱动的最后一步,也是最关键的一步,将磁盘gendisk及其及分区添加到devices树及sysfs中。
调用链:add_disk -> device_add_disk -> __device_add_disk
__device_add_disk调用过程详解:
1:blk_alloc_devt #为主分区disk->part0分配设备号
2:bdi_register_owner
#将disk->queue->backing_dev_info添加到全局链表bdi_list3:blk_register_region
#将磁盘添加到bdev_map中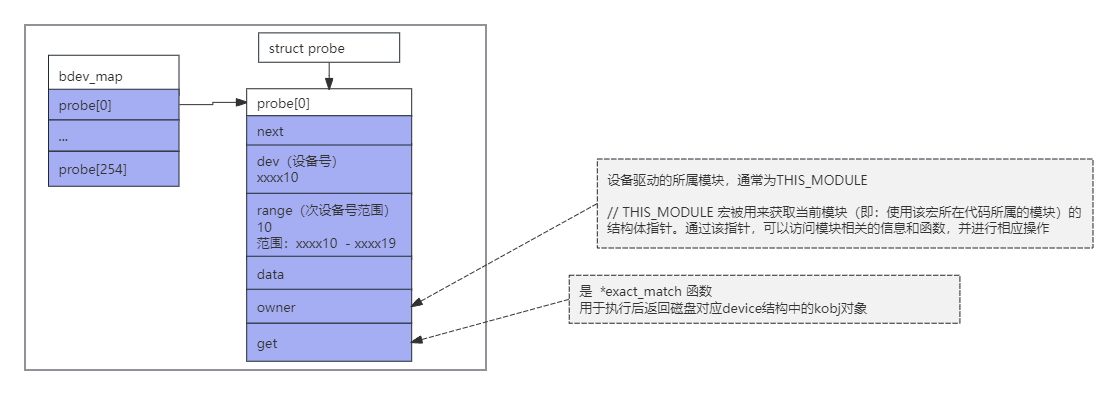
4:register_disk #注册磁盘,核心步骤
ilookup5(sb, hashval, test, data); // 先根据设备号hash值查找inode是否已经存在(是否在vfs的inode_hashtable中),查到则直接返回该inode alloc_inode(sb); inode_insert5(new, hashval, test, set, data);
container_of(inode, struct bdev_inode, vfs_inode); struct bdev_inode { struct block_device bdev; struct inode vfs_inode; };
调用devcgroup_inode_permission函数检查当前进程是否有权访问该设备。
如果没有权限,则释放对块设备的引用并返回错误代码。
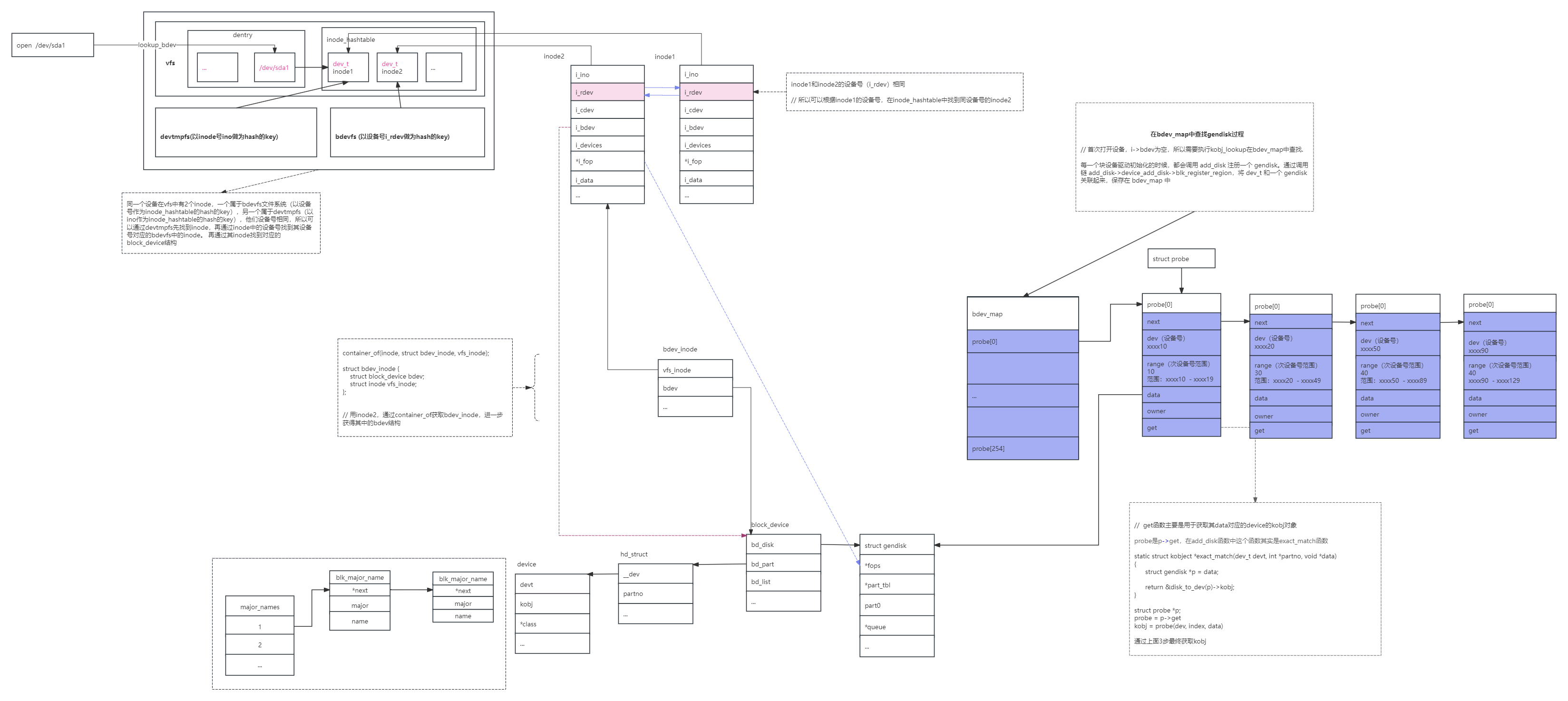
// 先通过设备号在bdev_map中查询即可得到对应的gendisk信息,如果能直接查到,直接获取查到的gendisk信息即可
struct probe *p; get也就是exact_match函数 static struct kobject *exact_match(dev_t devt, int *partno, void *data) { struct gendisk *p = data; return &disk_to_dev(p)->kobj; } probe = p->get kobj = probe(dev, index, data)
1:通过设备号在bdev_map中查询不到对应的gendisk信息,说明block_device 对应的是个扩展分区,这个时候我们要到IDR树中通过次设备号去查询
(hd_struct)指针,并将这个指针赋值给part变量
void *idr_find(const struct idr *idr, unsigned long id) { return radix_tree_lookup(&idr->idr_rt, id - idr->idr_base); } EXPORT_SYMBOL_GPL(idr_find);
bdev->bd_disk = disk;
bdev->bd_queue = disk->queue;
bdev->bd_contains = bdev;
bdev->bd_partno = partno; *分区号,查找bdev_map过程中,通过设备号差值(dev - p->dev)算出
{ // 设置分区,通过part_tbl和partno获取 bdev->bd_part = disk_get_part(disk, partno); // 执行磁盘描述符的open回调 ret = disk->fops->open(bdev, mode); // 设备磁盘容量 bd_set_size(bdev,(loff_t)get_capacity(disk)<<9); // 设置block_size的大小(这个块设备自身的块大小,文件系统的块大小一般是块设备自身的整数倍) set_init_blocksize(bdev); // 如果bdev->bd_invalidated =1(该设备上分区是否无效) ,将重新扫描分区 rescan_partitions(disk, bdev); }
if (ret == -ERESTARTSYS) {
/* Lost a race with 'disk' being
* deleted, try again.
* See md.c
*/
disk_put_part(bdev->bd_part);
bdev->bd_part = NULL;
bdev->bd_disk = NULL;
bdev->bd_queue = NULL;
mutex_unlock(&bdev->bd_mutex);
disk_unblock_events(disk);
put_disk_and_module(disk);
goto restart;
}
对分区(partno不为0)的bdev进行初始化 { // 获取整个设备(这里分区号参数是0)的bdev,赋值给变量whole whole = bdget_disk(disk, 0); //递归调用__blkdev_get ret = __blkdev_get(whole, mode, 1); bdev->bd_contains = whole; // 设置分区,通过part_tbl和partno获取 bdev->bd_part = disk_get_part(disk, partno); // 设备磁盘容量 bd_set_size(bdev,(loff_t)get_capacity(disk)<<9); // 设置block_size的大小 set_init_blocksize(bdev); }
bdev->bd_openers 不为 0
: 非第一次打开块设备的处理:
rescan_partitions(disk, bdev);
disk_unblock_events(disk);
// 如果这不是首次打开该块设备(first_open为假),则调用put_disk_and_module函数来释放对磁盘和模块的引用
if (!first_open)
put_disk_and_module(disk);
// 如果whole为真,说明之前进行了独占访问的声明,且当前设备持有者以独占模式打开的,则现在需要完成该过程
if (whole) { struct gendisk *disk = whole->bd_disk // 锁定相关的互斥锁和自旋锁,以确保线程安全。 mutex_lock(&bdev->bd_m utex); spin_lock(&bdev_lock); // 如果获取设备访问权成功(__blkdev_get返回0),则更新设备的持有者信息,并设置bd_write_holder标志(如果适用) if (!res) { BUG_ON(!bd_may_claim(bdev, whole, holder)); whole->bd_holders++; whole->bd_holder = bd_may_claim; // 这里bd_may_claim是个系统添加临时占用标识,目的是阻止此标识期间被申请独占持有权限,但并不影响分区的独占申请(实际磁盘并未被其他人独占持有) bdev->bd_holders++; // 如果whole和bdev相同,意味这bdev代表整个磁盘,bd_holders需要递增2次,因为前面执行了whole->bd_holder = bd_may_claim; bdev->bd_holder = holder; } // 通知其他等待者独占访问已经完成。 BUG_ON(whole->bd_claiming != holder); whole->bd_claiming = NULL; wake_up_bit(&whole->bd_claiming, 0);
// 如果请求了写操作,并且之前没有写持有者,且磁盘标志要求阻塞事件,则设置bd_write_holder为true并阻塞磁盘事件。
// 这段代码是Linux内核中处理块设备写操作的一部分。让我们逐步分析它的含义和作用:
{
...
{
...
if (!res && (mode & FMODE_WRITE) && !bdev->bd_write_holder && (disk->flags & GENHD_FL_BLOCK_EVENTS_ON_EXCL_WRITE)):
/* !res:检查之前的操作(可能是打开设备或检查权限等)是否成功,res为0表示成功
* (mode & FMODE_WRITE):检查文件打开模式是否包含写模式(FMODE_WRITE)
* !bdev->bd_write_holder:检查当前块设备是否没有被其他进程持有用于写操作
* (disk->flags & GENHD_FL_BLOCK_EVENTS_ON_EXCL_WRITE):检查磁盘标志是否包含GENHD_FL_BLOCK_EVENTS_ON_EXCL_WRITE,这意味着在独占写操作期间应该阻塞事件
*/
// 如果上述条件都满足,将块设备的bd_write_holder标志设置为true,表示当前进程持有该设备用于写操作
bdev->bd_write_holder = true;:
// 调用disk_block_events函数来阻塞磁盘事件。这通常是为了防止在独占写操作期间发生并发访问或事件通知,从而保护数据的一致性和完整性
disk_block_events(disk);:
}
/* 综上所述,这段代码的目的是在特定条件下(即之前的操作成功、文件以写模式打开、块设备当前没有被其他进程持有用于写操作、且磁盘标志要求阻塞事件),将块设备标记为正在被当前进程持有 * 用 于写操作,并阻塞磁盘事件。这是Linux内核中用于管理块设备写操作和并发控制的一种机制。
*/
// 释放该块设备的互斥锁
mutex_unlock(&bdev->bd_mutex);
// 释放对whole设备的引用(whole指针的使命已经完成不再需要)
bdput(whole);
}
// 返回获取设备的结果
return res;
}
七、ext4文件系统
磁盘布局:
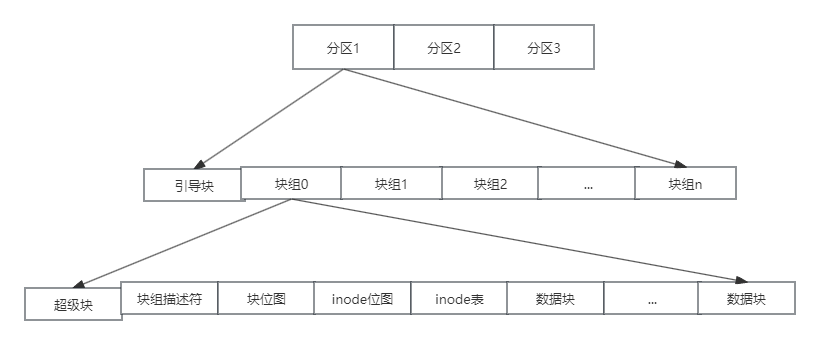
引导块:

档案系统资讯:
- 档案系统 volume 名称 (Filesystem volume name) - 即是档案系统标签 (Filesystem label),用作简述该档案系统的用途或其储存数据。现时 GNU/Linux 都会用 USB 手指/IEEE1394 硬盘等可移除储存装置的档案系统标签作为其挂载目录的名称,方便使用者识别。而个别 GNU/Linux distribution 如 Fedora、RHEL 和 CentOS 等亦在 fstab 取代传统装置档案名称 (即 /dev/sda1 和 /dev/hdc5 等) 的指定开机时要挂载的档案系统,避免偶然因为 BIOS 设定或插入次序的改变而引起的混乱。可以使用命令 e2label 或 tune2fs -L 改变。
- 上一次挂载于 (Last mounted on)' - 上一次挂载档案系统的挂载点路径,此栏一般为空,很少使用。可以使用命令 tune2fs -M 设定。
- 档案系统 UUID (Filesystem UUID) - 一个一般由乱数产生的识别码,可以用来识别档案系统。个别 GNU/Linux distribution 如 Ubuntu] 等亦在 fstab 取代传统装置档案名称 (即 /dev/sda1 和 /dev/hdc5 等) 的指定开机时要挂载的档案系统,避免偶然因为 BIOS 设定或插入次序的改变而引起的混乱。可以使用命令 tune2fs -U 改变。
- (Filesystem magic number) - 用来识别此档案系统为 Ext2/Ext3/Ext4 的签名,位置在档案系统的 0x0438 - 0x0439 (Superblock 的 0x38-0x39),现时必定是 0xEF53。
- 档案系统版本编号 (Filesystem revision #) - 档案系统微版本编号,只可以在格式化时使用 mke2fs -r 设定。现在只支援[1]:
- 0 - 原始格式,Linux 1.2 或以前只支援此格式[2]
- 1 (dymanic) - V2 格式支援动态 inode 大小 (现时一般都使用此版本)
- 档案系统功能 (Filesystem features) - 开启了的档案系统功能,可以使用合令 tune2fs -O 改变。现在可以有以下功能:
- has_journal - 有日志 (journal),亦代表此档案系统必为 Ext3 或 Ext4
- ext_attr - 支援 extended attribute
- resize_inode - resize2fs 可以加大档案系统大小
- dir_index - 支援目录索引,可以加快在大目录中搜索档案。(ext3 ,ext4 支持,ext2 不支持)
- filetype - 目录项目为否记录档案类型
- needs_recovery - e2fsck 检查 Ext3/Ext4 档案系统时用来决定是否需要完成日志纪录中未完成的工作,快速自动修复档案系统
- extent - 支援 Ext4 extent 功能,可以加快档案系系效能和减少 external fragmentation,使用bigalloc 的则必须enable extent
- flex_bg - allows the per-block group metadata (allocation bitmaps and inode tables) to be placed anywhere on the storage ,In addition, mke2fs will place the per-block group metadata together starting at the first block group of each "flex_bg group" ,The size of the flex_bg group can be specified using the -G option.
- sparse_super - 只有少数 superblock 备份,而不是每个区块组都有 superblock 备份,节省空间。
- large_file - 支援大于 2GiB 的档案
- huge_file - allows files to be larger than 2 terabytes in size
- uninit_bg - ext4 file system feature indicates that the block group descriptors will be protected using checksums,making it safe for mke2fs(8) to create a file system without initializing all of the block groups. The kernel will keep a high watermark of unused inodes, and initialize inode tables and block lazily. This feature speeds up the time to check the file system using e2fsck(8), and it also speeds up the time required for mke2fs(8) to create the file system.
- dir_nlink - 每个目录支持65000以上的目录数量
- extra_isize - reserves a specific amount of space in each inode for extended metadata such as nanosecond timestamps and file creation time,inode size must be 256 bytes in size or larger
- 下面的则不是dumpe2fs -h 输出的,而是我在man ext4里面看到的
- bigalloc - enables clustered block allocation, so that the unit of allocation is a power of two number of blocks. That is, each bit in the what had traditionally been known as the block allocation bitmap now indicates whether a cluster is in use or not, where a cluster is by default composed of 16 blocks. This feature can decrease the time spent on doing block allocation and brings smaller fragmentation,especially for large files. The size can be specified using the mke2fs -C option.
- encrypt - This ext4 feature provides file-system level encryption of data blocks and file names. The inode metadata (timestamps, file size, user/group ownership, etc.) is not encrypted.This feature is most useful on file systems with multiple users, or where not all files should be encrypted. In many use cases, especially on single-user systems, encryption at the block device layer using dm-crypt may provide much better security.
- journal_dev - This feature is enabled on the superblock found on an external journal device. The block size for the external journal must be the same as the file system which uses it.
The external journal device can be used by a file system by specifying the -J device= option to mke2fs(8) or tune2fs(8). - mmp - This ext4 feature provides multiple mount protection (MMP). MMP helps to protect the filesystem from being multiply mounted and is useful in shared storage environments
- project - This ext4 feature provides project quota support. With this feature, the project ID of inode will be managed when the filesystem is mounted.
- meta_bg - This ext4 feature allows file systems to be resized on-line without explicitly needing to reserve space for growth in the size of the block group descriptors. This scheme is also used to resize file systems which are larger than 2^32 blocks. It is not recommended that this fea ture be set when a file system is created, since this alternate method of storing the block group descriptors will slow down the time needed to mount the file system, and newer kernels can automatically set this feature as necessary when doing an online resize and no more reserved space is available in the resize inode
- sparse_super2 - This feature indicates that there will only be at most two backup superblocks and block group descriptors. The block groups used to store the backup superblock(s) and blockgroup descriptor(s) are stored in the superblock, but typically, one will be located at the beginning of block group #1, and one in the last block group in the file system. This feature is essentially a more extreme version of sparse_super and is designed to allow a much larger percentage of the disk to have contiguous blocks available for data files.
-
inline_data - Allow data to be stored in the inode and extended attribute area
- 档案系统旗号 (Filesystem flags) - signed_directory_hash
- 缺省挂载选项 (Default mount options) - 挂载此档案系统缺省会使用的选项
- 档案系统状态 (Filesystem state) - 可以为 clean (档案系统已成功地被卸载)、not-clean (表示档案系统挂载成读写模式后,仍未被卸载) 或 erroneous (档案系统被发现有问题)
- 错误处理方案 (Errors behavior) - 档案系统发生问题时的处理方案,可以为 continue (继续正常运作) 、remount-ro (重新挂载成只读模式) 或 panic (即时当掉系统)。可以使用 tune2fs -e 改变。
- 作业系统类型 (Filesystem OS type) - 建立档案系统的作业系统,可以为 Linux/Hurd/MASIX/FreeBSD/Lites[1]
- Inode 数目 (Inode count) - 档案系统的总 inode 数目,亦是整个档案系统所可能拥有档案数目的上限
- 区块数目 (Block count) - 档案系统的总区块数目
- 保留区块数目 (Reserved block count) - 保留给系统管理员工作之用的区块数目
- 未使用区块数目 (Free blocks) - 未使用区块数目
- 未使用 inode 数目 (Free inodes) - 未使用 inode 数目
- 第一个区块编数 (First block) - Superblock 或第一个区块组开始的区块编数。此值在 1 KiB 区块大小的档案系统为 1,大于1 KiB 区块大小的档案系统为 0。(Superblock/第一个区块组一般都在档案系统 0x0400 (1024) 开始)[1]
- 区块大小 (Block size) - 区块大小,可以为 1024, 2048 或 4096 字节 (Compaq Alpha 系统可以使用 8192 字节的区块)
- Fragment 大小 (Fragment size) - 实际上 Ext2/Ext3/Ext4 未有支援 Fragment,所以此值一般和区块大小一样
- 保留 GDT 区块数目 (Reserved GDT blocks) - 保留作在线 (online) 改变档案系统大小的区块数目。若此值为 0,只可以先卸载才可脱机改变档案系统大小[3]
- 区块/组 (Blocks per group) - 每个区块组的区块数目
- Fragments/组 (Fragments per group) - 每个区块组的 fragment 数目,亦用来计算每个区块组中 block bitmap 的大小
- Inodes/组 (Inodes per group) - 每个区块组的 inode 数目
- Inode 区块/组 (Inode blocks per group) - 每个区块组的 inode 区块数目
- (Flex block group size) - 16
- 档案系统建立时间 (Filesystem created) - 格式化此档案系统的时间
- 最后挂载时间 (Last mount time) - 上一次挂载此档案系统的时间
- 最后改动时间 (Last write time) - 上一次改变此档案系统内容的时间
- 挂载次数 (Mount count) - 距上一次作完整档案系统检查后档案系统被挂载的次数,让 fsck 决定是否应进行另一次完整档案系统检查
- 最大挂载次数 (Maximum mount count) - 档案系统进行另一次完整检查可以被挂载的次数,若挂载次数 (Mount count) 大于此值,fsck 会进行另一次完整档案系统检查
- 最后检查时间 (Last checked) - 上一次档案系统作完整检查的时间
- 检查间距 (Check interval) - 档案系统应该进行另一次完整检查的最大时间距
- 下次检查时间 (Next check after) - 下一次档案系统应该进行另一次完整检查的时间
- 保留区块使用者识别码 (Reserved blocks uid) - 0 (user root)
- 保留区块群组识别码 (Reserved blocks gid) - 0 (group root)
- 第一个 inode (First inode) - 第一个可以用作存放正常档案属性的 inode 编号,在原格式此值一定为 11, V2 格式亦可以改变此值[1]
- Inode 大小 (Inode size) - Inode 大小,传统为 128 字节,新系统会使用 256 字节的 inode 令扩充功能更方便
- (Required extra isize) - 28
- (Desired extra isize) - 28
- 日志 inode (Journal inode) - 日志档案的 inode 编号
- 缺省目录 hash 算法 (Default directory hash) - half_md4
- 目录 hash 种子 (Directory Hash Seed) - 17e9c71d-5a16-47ad-b478-7c6bc3178f1d
- 日志备份 (Journal backup) - inode blocks
- 日志大小 (Journal size) - 日志档案的大小
Ext4预留inode:
| Inode号 | 用途 |
|---|---|
| 0 | 不存在0号inode |
| 1 | 损坏数据块链表 |
| 2 | 根目录 |
| 3 | ACL索引 |
| 4 | ACL数据 |
| 5 | Boot loader |
| 6 | 未删除的目录 |
| 7 | 预留的块组描述符inode |
| 8 | 日志inode |
| 11 |
第一个非预留的inode,通常是lost+found目录 |
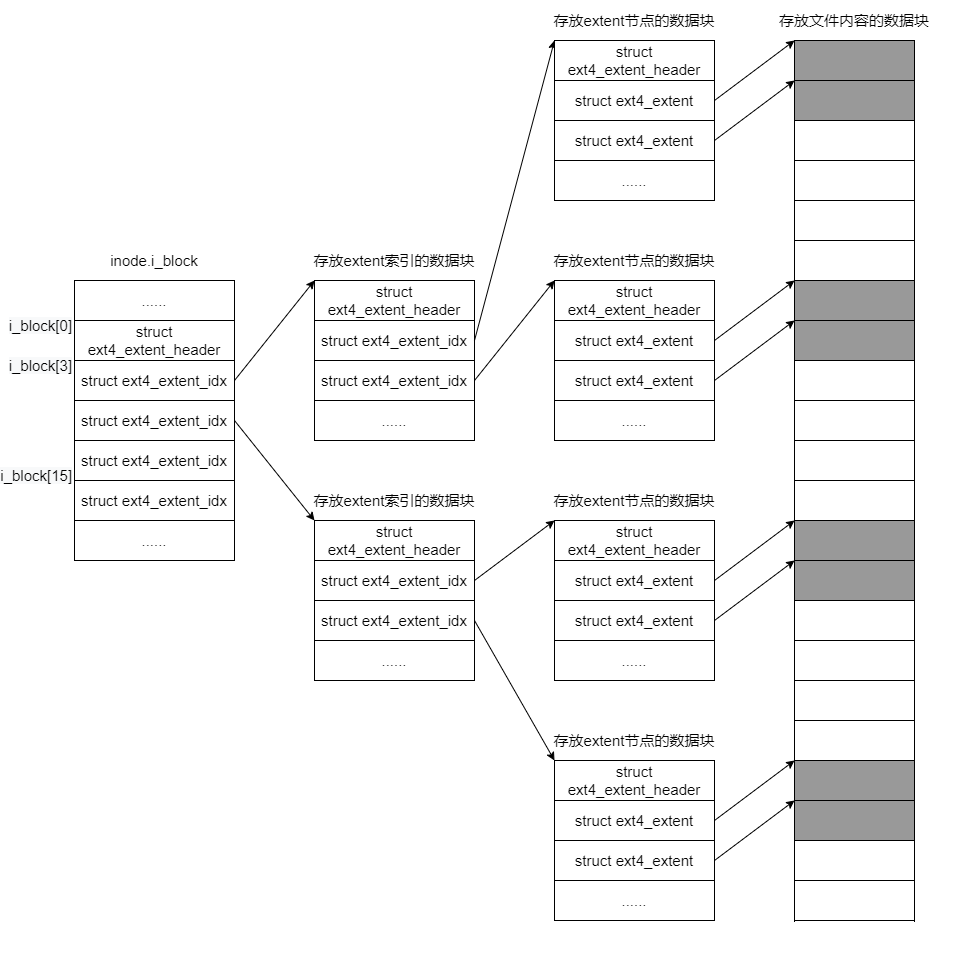
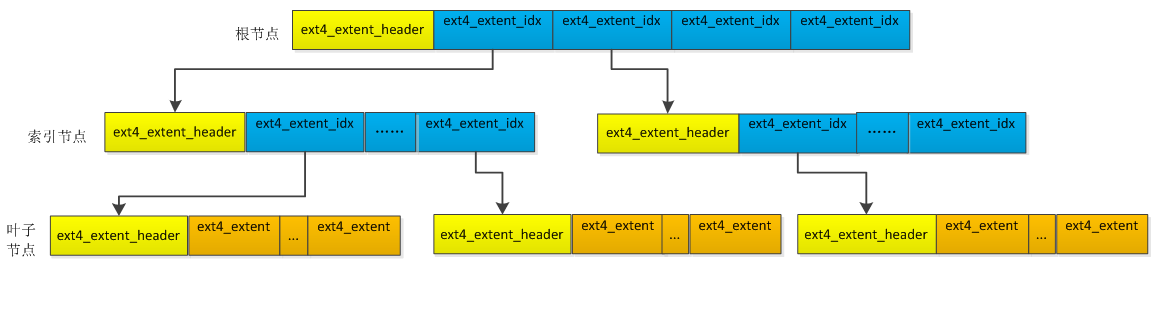
Extents:
dir_index功能:
在目录下查找目录下的文件,正常是一个线性扫描的过程。在目录下文件数目比较少的情况下,这种方法还是不错的,但是如果一个目录下有几万几十万个条目,这个方法就比较慢了, 原因在于线性扫描,而且1个block(4096字节)基本只能放下几十~200个条目,一旦需要几十几百个block,那么为了获取子文件的inode,这个DISK IO的消耗是不能忍受的,因此开发了dir_index的功能。
dir_index是采用hash tree的方式来存放entry,而不是线性往后追加。注意,并不说打开了dir_index功能,所有的目录都一律使用hash tree的方式存储。当目录下的条目并不多的时候,并不采用hash tree,还是采用线性目录。
下图是dir_indexs实现原理图:
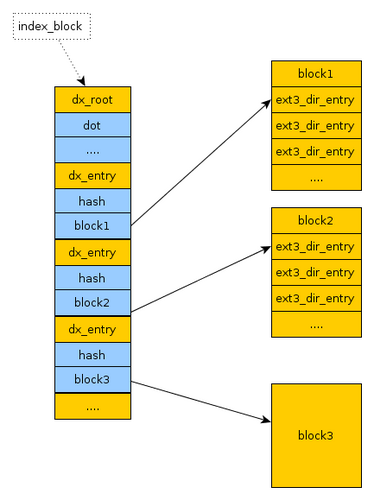
可以看出具体实现是:取文件名的哈希值的几位作为目录名,例如取哈希值的最后两位或四位,这样可以创建256或1024个子目录,文件根据哈希值被分配到这些子目录中。这样减少了在单个目录下进行文件查找时的遍历时间,因为文件系统在查找文件时,需要遍历目录中的每个条目,文件越多,这个过程就越慢。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!