


数据采集作业2
作业一
(1)实验内容
o 要求:要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库
代码如下:
import requests
from lxml import etree
import xlwt
if __name__=='__main__':
url = 'http://www.weather.com.cn/weather/101010100.shtml'
response=requests.get(url=url)
response.encoding = 'utf-8'
response=response.text
tree=etree.HTML(response)
ul=tree.xpath('//*[@id="7d"]/ul')[0]
lis=ul.xpath('./li')
prts=[]#用来存放七天的天气数据
num=1
for li in lis:
prt=[]
day=li.xpath('./h1/text()')[0]
wea=li.xpath('./p[@class="wea"]/text()')[0]
tem=li.xpath('.//i/text()')[0]
prt.append(str(num))
prt.append('北京')
#分别将获得的日期天气和气温存到列表中
prt.append(day)
prt.append(wea)
prt.append(tem)
prts.append(prt)
num+=1
print(prts)
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet('sheet1', cell_overwrite_ok=True)
#将数据写入表格
sheet.write(0, 0, '序号')
sheet.write(0,1,'地区')
sheet.write(0, 2, '日期')
sheet.write(0, 3, '气候')
sheet.write(0,4,'温度')
for i in range(1,len(prts)+1): # 逐行
for j in range(len(prts[0])): # 逐列
sheet.write(i, j, prts[i-1][j]) # 将指定值写入第i行第j列
save_path = 'E:/FZU/sjcj/sjcj作业/作业2/北京天气.xlsx'#保存到本地的excel文件中
book.save(save_path)
结果如下:
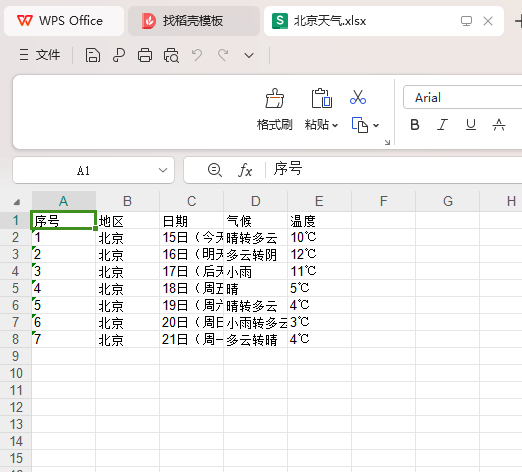
(2)心得体会
进一步的了解了如何用re库便捷的寻找标签,爬取数据,学习了re库的findall函数的基本用法
作业二
(1)实验内容
o 要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
代码如下:
import json
import requests
import pandas as pd
if __name__=="__main__":
page=int(input("请输入你要输入的页数: "))
url='https://77.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408047147985914564_1696660084600&pn=%d&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696660084601'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'
}
datas=[]
s='序号 股票代码 股票名称 最新报价 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收'
for i in range(1,page+1):
newurl=format(url%i)
response=requests.get(url=newurl,headers=headers).text
response=response[42:-2]
data=json.loads(response)
data=data['data']['diff']
datas.extend(data)
ds = pd.DataFrame(datas)
df = ds[["f12", "f14", "f2", "f4", "f5", "f6", "f7", "f15", "f16", "f17","f18"]]
df.columns = ["股票代码", "股票名称", "最新报价", "涨跌额", "成交量(手)", "成交额(手)", "振幅(%)", "最高", "最低","今开","昨收"]
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.set_option('expand_frame_repr', False)
print(df)
df.to_excel("E:/FZU/sjcj/sjcj作业/作业2/股票.xlsx")
print("任务完成")
结果如下:
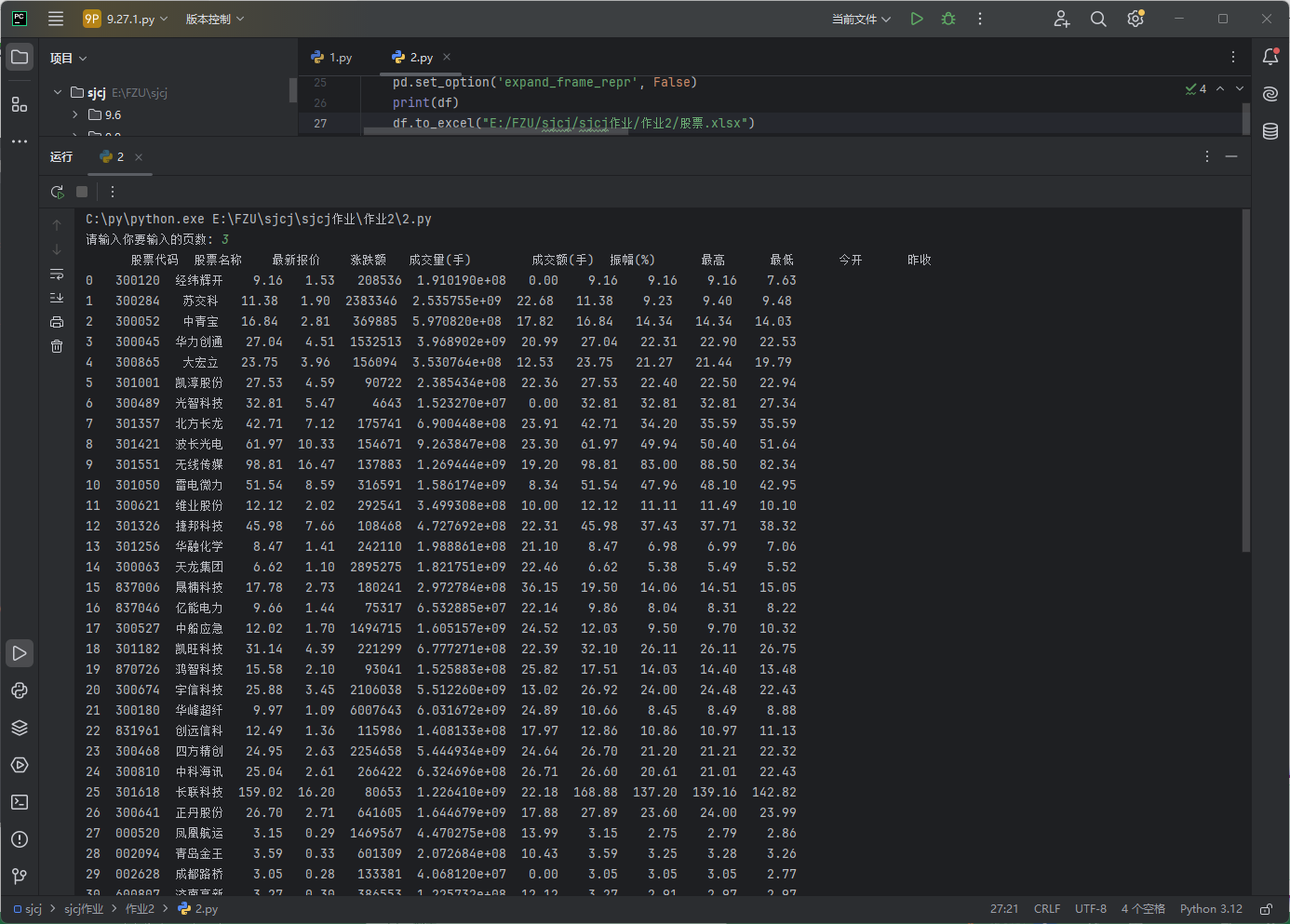

(2)心得体会
了解的如何通过抓包获取网页数据,学习了json库的基本用法
作业三
(1)实验内容
o 要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
代码如下:
import requests
import re
if __name__=="__main__":
url = 'https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2024/payload.js'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/69.0.3947.100 Safari/537.36'
}
response=requests.get(url=url,headers=headers).text
x='univNameCn:"(.*?)"'
y='score:(.*?),'
name=re.findall(x,response,re.S)
score=re.findall(y,response,re.S)
print("排名 学校 总分")
fp = open("./大学排名.txt", "w", encoding='utf-8')
fp.write("排名 学校 总分\n")
for i in range(0,len(name)):
print(str(i+1)+' '+name[i]+' '+score[i])
fp.write(str(i+1)+' '+name[i]+' '+score[i]+'\n')
fp.close()
print("任务完成")
结果如下:
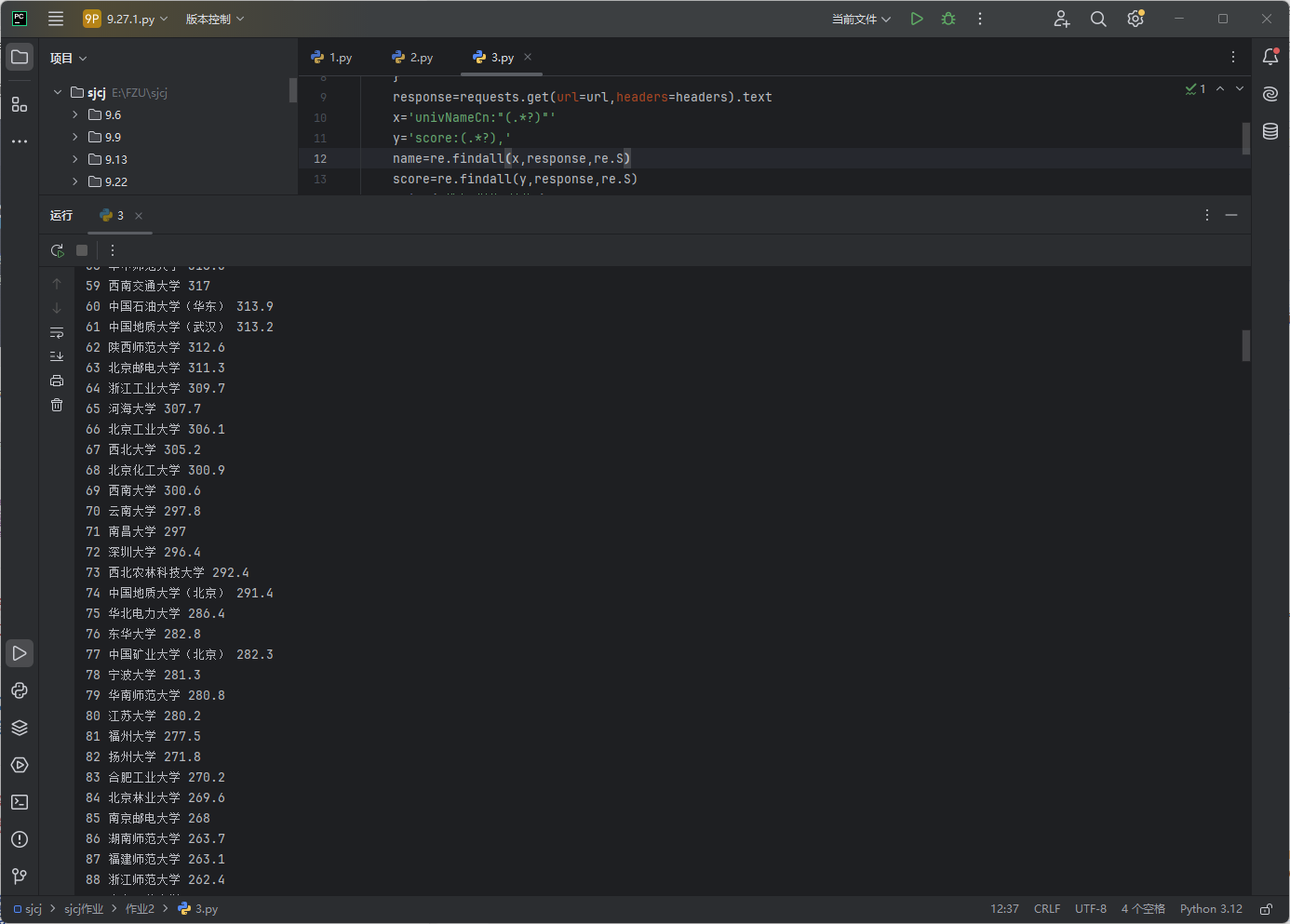

F12调试分析的过程Gif 如下

(2)心得体会
此题与第二题做法类似,不同的是,该题使用字典映射对数据进行了简单的加密,需要对爬取到的数据做进一步处理才能得到正确的结果。
