


数据采集作业1
作业一
(1)实验内容
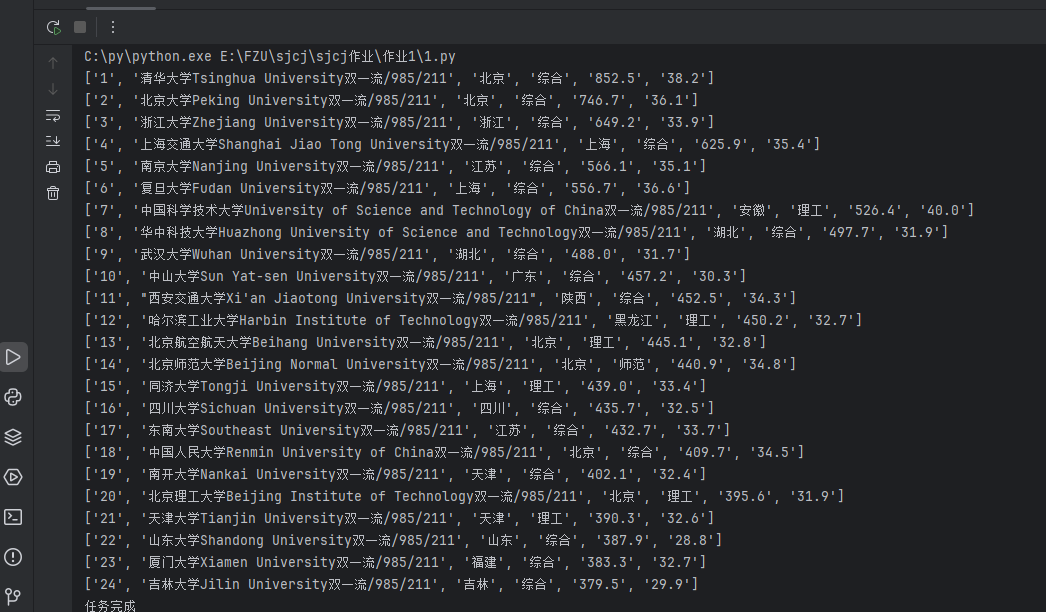
o 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
o 输出信息:
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2 ......
代码如下:
import urllib.request
from bs4 import BeautifulSoup
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.76'
}
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read().decode()
soup = BeautifulSoup(data, "lxml")
fp = open("./程序设计.txt", "w", encoding='utf-8')
fp.write("排名 学校名称 省市 学校类型 总分\n")
body = soup.find("tbody")
for i, row in enumerate(body.find_all('tr')):
if i >= 24: # 输出前24条
break
row_data=[]
for td in row.find_all('td'):
row_data.append(td.get_text(strip=True))
print(row_data)
fp.write(row_data[0]+" "+row_data[1][0:4]+" "+
row_data[2]+" "+row_data[3]+" "+row_data[4]+ "\n")
fp.close()
print("任务完成")
结果如下:
(2)心得体会
遇到网页编码问题时,了解到需要正确识别网页的编码格式才能正确解析文本内容。通过查看响应头信息或者使用自动检测编码的库函数来解决编码不统一导致的乱码问题。这次实践不仅提升了自己的编程技能,尤其是在 Python 网络爬虫领域,还让自己对数据获取和处理有了更深入的理解。同时,也意识到在进行网络爬虫时需要遵守相关法律法规和道德规范,确保数据的合理使用。未来,还可以进一步探索如何对爬取到的数据进行存储、分析和可视化等操作,以发挥数据更大的价值。
作业二
(1)实验内容
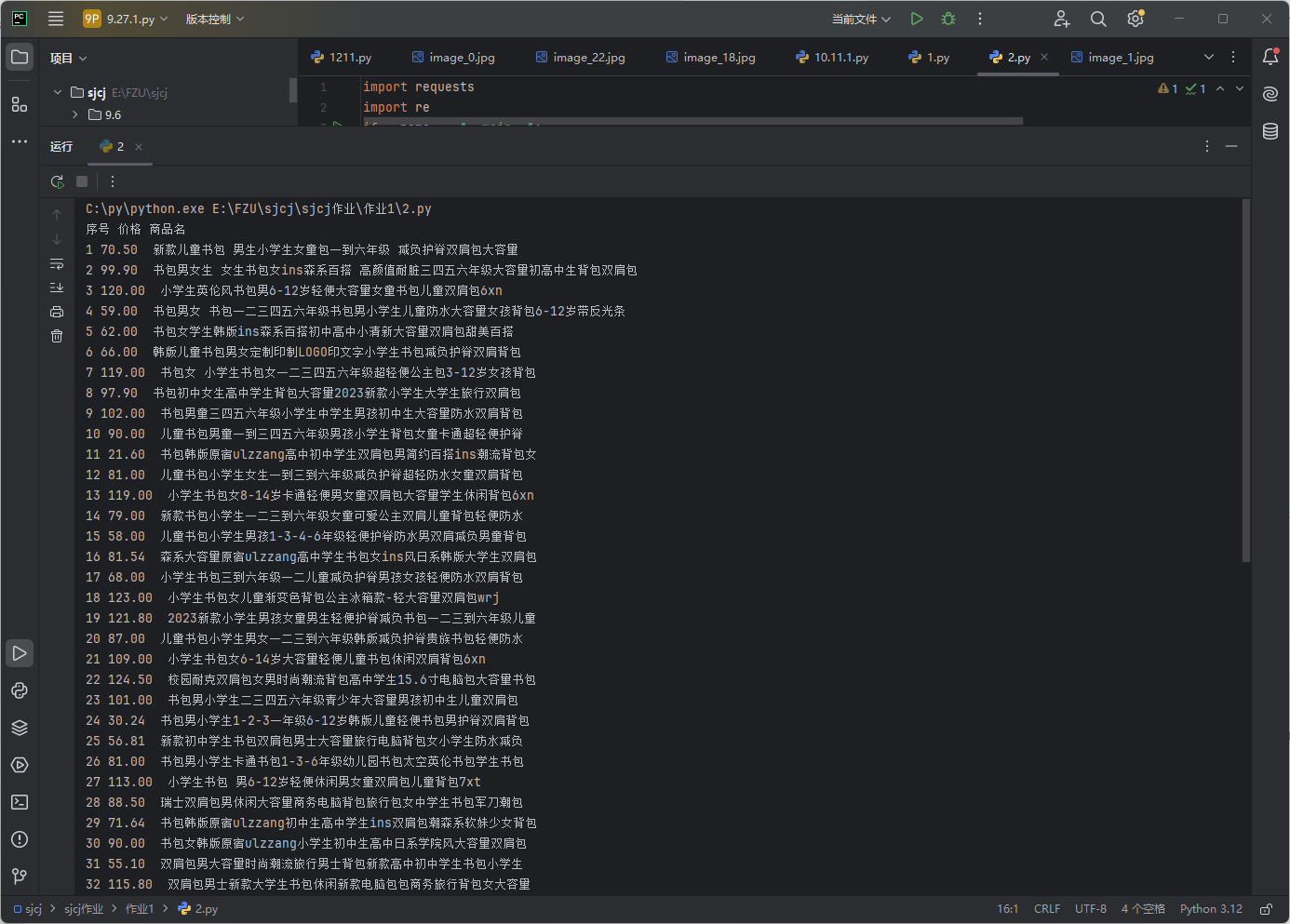
o 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
o 输出信息:
序号 价格 商品名
1 65.00 xxx
2 ......
代码如下:
import requests
import re
if __name__=="__main__":
url="http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36'
}
response=requests.get(url=url,headers=headers).text
ex='<p class="name" name="title" ><a title="(.*?)"'
ey='<span class="price_n">¥(.*?)</span>'
ls1=re.findall(ex,response,re.S)
ls2=re.findall(ey,response,re.S)
print("序号 价格 商品名")
for i in range(0,len(ls1)):
print(str(i+1)+" "+str(ls2[i])+" "+ls1[i])
结果如下:
(2)心得体会
先用BeautifulSoup尝试了一下,挺轻松就做出来了,然后再改用re库,了解了re库search函数的用法。
作业三
(1)实验内容
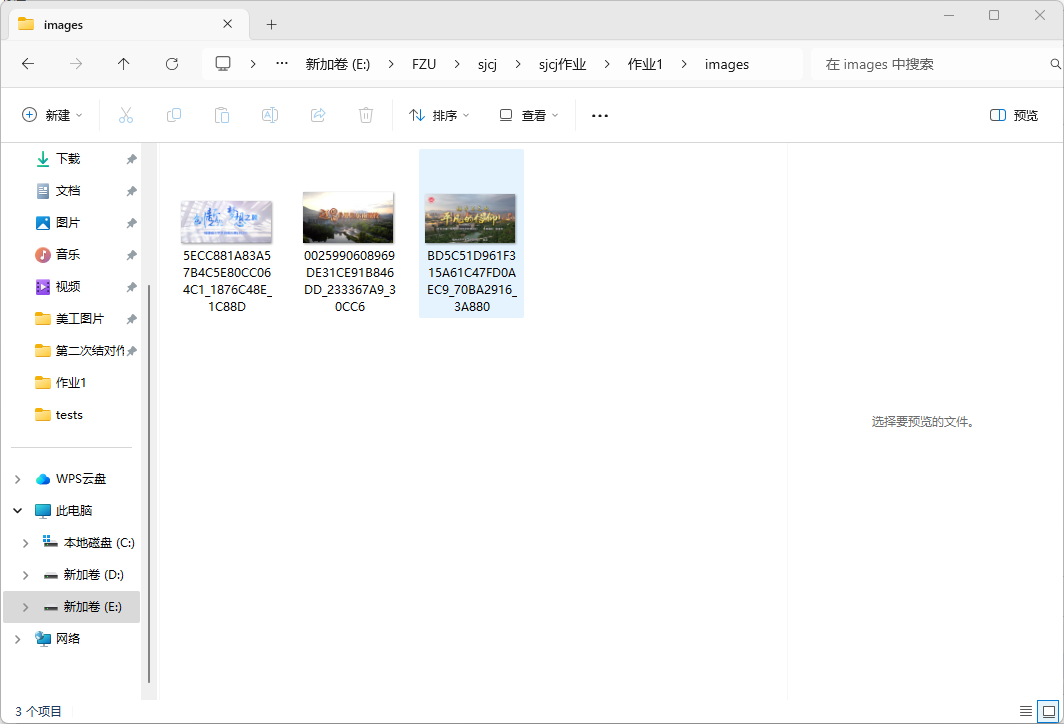
o 要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
o 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码如下:
import requests
from bs4 import BeautifulSoup
import os
# 定义要爬取的网页地址
url = "https://news.fzu.edu.cn/yxfd.htm"
# 发送 HTTP GET 请求获取网页内容,设置为响应对象 response
response = requests.get(url)
# 检查请求是否成功,若不成功则抛出异常
response.raise_for_status()
# 使用 BeautifulSoup 解析网页内容,使用 html.parser 解析器
soup = BeautifulSoup(response.text, "html.parser")
# 创建一个用于保存图片的目录,如果该目录不存在
save_dir = "images"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 查找网页中所有的 <img> 标签
img_tags = soup.find_all("img")
# 遍历找到的每个 <img> 标签
for img_tag in img_tags:
# 获取 <img> 标签的 "src" 属性值,即图片的源地址
img_src = img_tag.get("src")
# 判断图片源地址是否存在且以 ".jpg" 或 ".jpeg" 结尾
if img_src and (img_src.endswith(".jpg") or img_src.endswith(".jpeg")):
# 将网页的基础地址与图片的相对地址拼接,得到完整的图片 URL
img_url = "https://news.fzu.edu.cn" + img_src
# 构建完整的保存路径和文件名,使用 os.path.join 避免路径拼接错误
img_filename = os.path.join(save_dir, os.path.basename(img_src))
# 发送 HTTP GET 请求获取图片内容,设置为响应对象 img_response
img_response = requests.get(img_url)
# 检查图片请求是否成功,若不成功则抛出异常
img_response.raise_for_status()
# 以二进制写入模式打开文件,如果文件不存在则创建,存在则覆盖
with open(img_filename, "wb") as img_file:
# 将获取到的图片内容写入文件
img_file.write(img_response.content)
# 打印已下载的图片文件名,提示下载成功
print(f"已下载: {img_filename}")
结果如下:
(2)心得体会
这题相对比较简单,只需要找到图片的下载网址,然后发起http请求,保存到本地即可


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY