


数值编码
真值与机器数
计算机使用二进制数的最高位作为符号位,用“0”表示正号,“1”表示负号,用其余位表示数值的大小。
在计算机内部将正、负号数字化后得到的数称为机器数。
将带符号位的机器数对应的真正数值称为机器数的真值。
定点数与浮点数
在计算机中,字长为8位的二进制机器数所能表示的最大值是(01111111) 2,对应十进制数为+127;最小值为(11111111) 2,对应十进制数为-127,超出这个取值范围的称为溢出。为了表示较大的数和较小的数,须引入浮点数的概念。
在计算机中小数点并不占用二进制位,但是规定了小数点的位置。根据对小数点位置的规定,机器数有整数、定点小数和浮点小数之分。整数和定点小数都是定点数。
在机器数中,小数点的位置固定不变的数称为定点数。
若将小数点的位置固定在机器数最低位之后,此时的机器数表示的就是一个纯整数。
对于一台计算机,一旦确定了小数点的位置,就不再改变。
小数点的位置在数中是可以变动的,这种数值表示法称为浮点数。目前的计算机大多采用的是浮点表示法。
浮点表示法与科学计数法类似,即用一个尾数(Mantissa,即有效数字),一个基数(Base),一个指数(Exponent)以及一个表示正负的符号来表达实数。
在IEEE 754标准中,规定浮点数格式为:
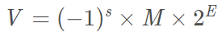
s表示符号位,当s=0,V为正数;当s=1,V为负数;
M表示尾数,2>M>=1;
E表示指数(又称阶码)。
上面为通用标准,实际在32位计算机中,用1位表示数值的正/负,用8位表示指数,用23位表示尾数。

32位数浮点数计算为十进制的公式如下:
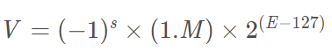
M尾数:IEEE标准要求浮点数必须是规范的,这意味着尾数的小数点左侧必须为1,因此尾数中只存储小数位;
E指数:指数也可以是正数或负数,为了解决负指数的情况,实际的指数值须加上一个偏置(作用类似时间24小时计时制,如下午4点,加上偏置量12,成为16点。),在32位机中,该偏置为2^7-1=127。
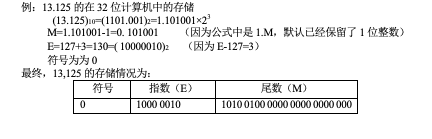
在32位计算机的实际应用中,有两种基本的浮点数:单精度浮点数和双精度浮点数。
其中单精度格式具有24位有效数字(即尾数)精度,总共占用32位;双精度格式具有53位有效数字(即尾数)精度,总共占有64位。
原码、反码和补码
计算机在进行数值运算时,也应考虑到符号位的处理。为了便于计算,机器数一般有三种表示方法:原码、反码和补码。原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值。正数的反码是其本身;负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
正数的补码就是其本身;负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后加1。
非数值型数据编码
非数值型数据包括英文字母、阿拉伯数字、各种标点符号、专用符号、汉字符,以及表示声音、图形、图像等音频、视频信息的数据。
信息交换码
ASCII码
ASCII码即American Standard Code forInformation Interchange(美国信息交换标准代码)。现在已经成为西文字符编码的国际通用标准。
标准ASCII码用7位二进制数表示一个字符。因为2^7=128,所以可以表示128 个不同的字符。英文是符号文字,只要通过二进制编码表示其基本元素,如字母,标点符号等,即可实现英文文字的数字化表示。
在128个字符中,0~31及127(共33个)是控制字符或通信专用字符,如LF(换行)、CR(回车)等、ACK(确认)等;
32~126(共95个)是字符,其中48~57为0到9十个阿拉伯数字;
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
在标准ASCII 码用7位二进制数来表示字符的基础上,将每个字符的第8 位用于确定附加的128个特殊符号字符、外来语字母和图形符号,这新增的128个符号为扩展ASCII码。
汉字交换码
GB2312
是1980年制定的中国汉字编码国家标准。共收录 7445 个字符,其中汉字 6763 个。
GB2312 兼容标准 ASCII码,采用扩展 ASCII 码的编码空间进行编码,一个汉字占用两个字节,每个字节的最高位为1。具体办法是:收集了7445个字符组成 94*94 的方阵,每一行称为一个“区”,每一列称为一个“位”,区号位号的范围均为 01-94,区号和位号组成的代码称为“区位码”。
GBK
《汉字内码扩展规范》(GBK) 于1995年制定,兼容GB2312、GB13000-1、BIG5 编码中的所有汉字,使用双字节编码,编码空间为 0x8140~0xFEFE,共有 23940 个码位,其中 GBK1 区和 GBK2 区也是 GB2312 的编码范围。收录了 21003 个汉字。GBK向下与 GB 2312 编码兼容,向上支持 ISO 10646.1国际标准,是前者向后者过渡过程中的一个承上启下的产物。
Unicode编码
Unicode码扩展自ASCII字元集。在严格的ASCII中每个字符用7位或8位表示,但在Unicode中,使用16位二进制数表示一个字符。这使得Unicode能够表示世界上所有的书写语言中可能用於电脑通讯的字元、象形文字和其他符号。
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
随着互联网的普及,强烈要求一种统一的编码方,UTF-8就是在互联网上使用最广的一种 Unicode 的实现方式,其他方式还有UTF-16和 UTF-32。因此,UTF-8是Unicode的一种实现方式。
多媒体数据编码
媒体(Media),也称为媒介,是信息交流的中介,也就是信息载体。
多媒体是对多种媒体的融合,将文本、声音、图像等通过计算机和通信技术集成在一个数字环境中,以协同表示更多的信息。
计算机采用数字化方式,即以二进制代码的形式存储文本、声音、图像等信息进行表示和处理。以下是几种不同常见媒介数据的编码方式,即数字化方法。
文本
文本的数字化包含多个层次,以汉字为例,包括输入过程中的编码,计算机内部处理时的编码,文本传输过程中的编码以及文本显示时的编码。汉字的特点是象形字,单字单音,而且汉字的输入输出必须用既有的输入、输出设备,因此在输入、输出、处理和存储过程中所使用的汉字编码不同。
声音
声音在传播过程中,是以波的方式传播,从时间维度上看,声波是连续的。但在数字化过程中,即以二进制形式存储时,需要对声波进行采样、量化和编码,最终数字化的声音在时间维度上看,是离散的。
图像
图像数字化是将连续色调的模拟图像经采样量化后转换成数字影像的过程。原始的图片是模拟图像,是在空间上连续/不分割、信号值不分等级的图像。经过采样、量化和编码,获得数字化图片,其在空间上被分割成离散像素,信号值分为有限个等级、用数码0和1表示的图像。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!