
(七)
一、使用scrapy框架
首先键入"Scrapy"

进入到我们的目标文件夹


之后我们在F盘scrapy文件夹建好了dangdang项目。

二、 编辑items.py
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
link=scrapy.Field()
comment=scrapy.Field()
再打开spiders/dd.py,修改起始进行爬取的网页
start_urls = ['http://category.dangdang.com/pg1-cid10010336.html']
接下来,需要导入items.py中的内容。
都是从核心目录开始定位,文件夹文件之间用 "." 隔开。
from items import DangdangItem
def parse(self, response):
item=DangdangItem() #实例化,方便表示。 item["title"] 即提取的标题
response.xpath("").extract()
<a title=" 美特斯邦威男短袖恤2016常年款男常年款净色V领短袖恤226251"
ddclick="act=normalResult_picture&pos=1341935830_3_1_m"
class="pic"
name="itemlist-picture"
dd_name="单品图片"
href="http://product.dangdang.com/1341935830.html"
target="_blank" >
<img src='http://img3m0.ddimg.cn/37/35/1341935830-1_b_2.jpg' alt=' 美特斯邦威男短袖恤2016常年款男常年款净色V领短袖恤226251' />
</a>
...
<span class="price_n">
¥39.00
</span>
...
在<a>和</a>之间,是商品图片。 而在<a>中由很多字段的描述,例如name="itemlist-picture"
而价格信息则在<span>和</span>标签之间
def parse(self, response):
item=DangdangItem()
item["title"]=response.xpath("//a[@name='itemlist-picture']/@title").extract()
同理,利用response.xpath("...").extract()提取剩下的元素,并赋值给DangdangItem()["..."],或本处实例化后item["..."]
关于xpath的补充:
/ 逐层提取
text() 提取标签下面的文本
//标签名 xx 提取所有名为xx的标签
//标签名[@属性=“属性值”] 提取属性为xx的标签
@属性名 代表取某个属性值
为获取评论,要先获取跳转的链接
item["link"]=response.xpath("//a[@name='itemlist-picture']/@href").extract()
<a href="http://product.dangdang.com/1345630530.html?point=comment_point" target="_blank" name="itemlist-review" dd_name="单品评论" ddclick="act=click_review_count&pos=1345630530_0_1_m"> 108条评论 </a>
同理,在name=“tiemlist-review”的a标签下,其文本内容为评论数
 之后回到dangdang目录,
之后回到dangdang目录,
...出了一些问题。无法找到items module

重新建立了dangdang2 project,注意包含cfg文件
同时,在存放spiders的spiders文件夹右键,mark directory as.. 选择 as source root,此时spiders文件夹会变成浅蓝色
现测试能否爬取商品标题
print(item["title"])

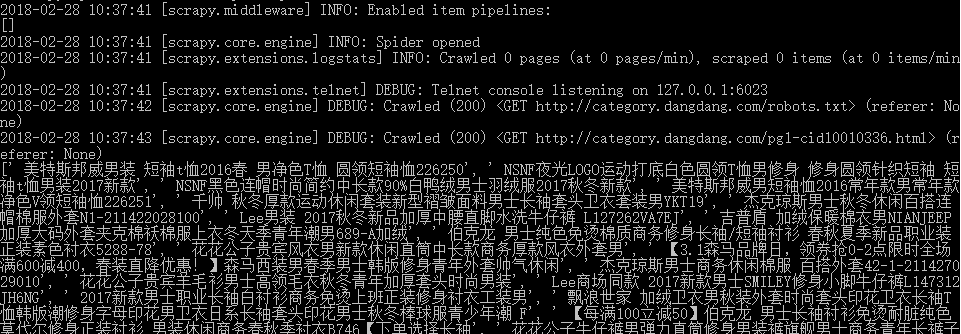
测试成功
spider爬取的信息,通过yield提交给pipeline
yield item
之后在settings中开启pipeline,定位configure item pipelines
取消其注释的部分
ITEM_PIPELINES = {
'dangdang2.pipelines.Dangdang2Pipeline': 300,
}
测试pipelines.py中的Dangdang2Pipeline类是否能正常运行
class Dangdang2Pipeline(object):
def process_item(self, item, spider):
for i in range(len(item["title"])):
title=item["title"][i]
link=item["link"][i]
comment=item["comment"][i]
print(title,link,comment)
return item
