

numpy和pandas axis的差异
1.numpy
numpy.sum(a, axis=None, dtype=None, out=None, keepdims=<class 'numpy._globals._NoValue'>)[source]
Sum of array elements over a given axis.
| Parameters: |
a : array_like
axis : None or int or tuple of ints, optional
|
|---|
arr = np.random.randn(5,4)#正态分布数据 print(arr) print(arr.sum()) # 数组/矩阵中所有元素求和,等价于np.sum(arr) print(np.sum(arr, axis=0))# 按列去求和; print(arr.sum(axis=1)) # 按行去求和;
[[ 0.04154798 0.25697028 2.36239272 -1.72886735] [ 0.50448843 -0.63285194 2.9090727 0.61004107] [ 0.10730241 -0.13162546 -0.67925053 0.12864452] [ 0.04125252 -0.03968486 -0.60453958 0.94637586] [ 1.65060502 -0.18266035 -1.06259085 0.18515147]] 4.681774035077944 [ 2.34519635 -0.72985234 2.92508445 0.14134557] [ 0.93204362 3.39075026 -0.57492907 0.34340393 0.59050528]
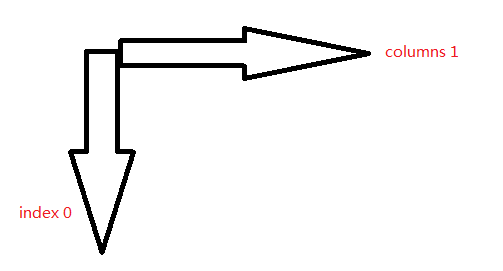
2.pandasDataFrame.sum(axis=None, skipna=None, level=None, numeric_only=None, min_count=0, **kwargs)[source]
axis : {index (0), columns (1)}
df
one two a 1.40 NaN b 7.10 -4.5 c NaN NaN d 0.75 -1.3
df.sum(axis=1)
a 1.40 b 2.60 c 0.00 d -0.55 dtype: float64
pandas.DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)[source]
axis : {0 or ‘index’, 1 or ‘columns’}, default 0
Determine if rows or columns which contain missing values are removed.
- 0, or ‘index’ : Drop rows which contain missing values.
- 1, or ‘columns’ : Drop columns which contain missing value.
Deprecated since version 0.23.0:: Pass tuple or list to drop on multiple
axes.
how : {‘any’, ‘all’}, default ‘any’
df
| id | date | city | category | age | price | |
|---|---|---|---|---|---|---|
| one | 1001 | 2013-01-02 | Beijing | 100-A | 23 | 1200.0 |
| two | 1002 | 2013-01-03 | NaN | 100-B | 44 | NaN |
| three | 1003 | 2013-01-04 | guangzhou | 110-A | 54 | 2133.0 |
| four | 1004 | 2013-01-05 | Shenzhen | 110-C | 32 | 5433.0 |
| five | 1005 | 2013-01-06 | shanghai | 210-A | 34 | NaN |
| six | 1006 | 2013-01-07 | BEIJING | 130-F | 32 | 4432.0 |
df.dropna(axis=1)#针对列向有nan值的情况
| id | date | category | age | |
|---|---|---|---|---|
| one | 1001 | 2013-01-02 | 100-A | 23 |
| two | 1002 | 2013-01-03 | 100-B | 44 |
| three | 1003 | 2013-01-04 | 110-A | 54 |
| four | 1004 | 2013-01-05 | 110-C | 32 |
| five | 1005 | 2013-01-06 | 210-A | 34 |
| six | 1006 | 2013-01-07 | 130-F | 32 |

