

numpy
参考文档:https://docs.scipy.org/doc/numpy/reference/
https://yiyibooks.cn/xx/NumPy_v111/index.html
pip install numpy
import numpy as np
一.实例化
1.list实例化一个数组
a= np.array([1,2,3,4,5,3]) print(a) print(type(a)) print(a.shape) print(a[2])
[1 2 3 4 5 3] <class 'numpy.ndarray'> (6,) 3
li=[[1,2,3],[4,5,6]] b=np.array(li) print(type(b)) print(b.shape) print(b.size) print(b.ndim)
<class 'numpy.ndarray'> (2, 3) 6 2
2.内置函数
a=np.zeros((3,4)) print(a)
[[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]]
b = np.zeros(3) #创建1x3全0数组 print(b,b.shape) c = np.zeros((1,3)) print(c,c.shape)
[0. 0. 0.] (3,) [[0. 0. 0.]] (1, 3)
d=np.full((2,3),10) print(d)
[[10 10 10] [10 10 10]]
e=np.empty((4,3))#只分配内存,但不填充,返回的都是一些未经初始化的垃圾值 print(e)
[[2.17e-322 0.00e+000 0.00e+000] [0.00e+000 0.00e+000 0.00e+000] [0.00e+000 0.00e+000 0.00e+000] [0.00e+000 0.00e+000 0.00e+000]]
np.eye(3)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
np.random.random((2,3))
array([[0.49589138, 0.17764052, 0.71689228],
[0.6031477 , 0.26279547, 0.19275625]])
np.random.randn(5)
array([-0.37314198, -1.20433409, -0.1813249 , -0.44703984, 0.39481494])
np.random.randn(2,3)
array([[-0.27027477, 0.33362728, 1.76140551],
[-0.25364338, 0.90426776, -0.47887923]])
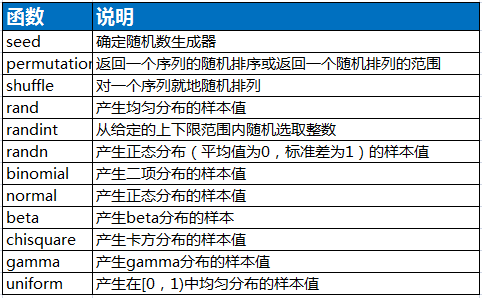
常用:
二.数据类型
a = np.array([1,2,3,4]) print(a.dtype) b=a.astype(np.float64) print(b.dtype)
int32 float64
a = np.arange(0,12,0.5).reshape(2,12) print(a)
[[ 0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5] [ 6. 6.5 7. 7.5 8. 8.5 9. 9.5 10. 10.5 11. 11.5]]
三.取数
1.切片
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) print(a) b = a[0:2, :2] c=a print(b)
[[ 1 2 3 4] [ 5 6 7 8] [ 9 10 11 12]] [[1 2] [5 6]]
a[:,0]=110
print(a)
[[110 2 3 4] [110 6 7 8] [110 10 11 12]]
2.花式索引
a=np.empty((5,4)) #创一个5x4的数组 for i in range(5): a[i]=i print(a) b=a[[4,0,2]]#可以以特定顺序索引 print('\n特定顺序索引如下:') print(b)
[[0. 0. 0. 0.] [1. 1. 1. 1.] [2. 2. 2. 2.] [3. 3. 3. 3.] [4. 4. 4. 4.]] 特定顺序索引如下: [[4. 4. 4. 4.] [0. 0. 0. 0.] [2. 2. 2. 2.]]
arr = np.arange(32).reshape(8,4) print(arr) print('\n传入多个索引数组') d=arr[[1,5,7,2],[0,3,1,2]]#一次传入多个索引数组,最终选出的元素是(1,0)、(5,3)、(7,1)和(2,2) print(d)
[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15] [16 17 18 19] [20 21 22 23] [24 25 26 27] [28 29 30 31]] 传入多个索引数组 [ 4 23 29 10]
e=arr[[1,5,7,2]][:,[0,3,1,2]]#矩阵区域 print(e) f=arr[np.ix_([1,5,7,2],[0,3,1,2])]#根据 print(f)
[[ 4 7 5 6] [20 23 21 22] [28 31 29 30] [ 8 11 9 10]] [[ 4 7 5 6] [20 23 21 22] [28 31 29 30] [ 8 11 9 10]]
#从里到外
3.布尔索引
a = np.arange(1,7).reshape(3,2) print(a) bool_idx = (a > 2) # 就是判定一下是否大于2 print(bool_idx) # 返回一个布尔型的3x2数组 print('\n')
print(a[a > 2])
[[1 2] [3 4] [5 6]] [[False False] [ True True] [ True True]]
names = np.array(['c','b','c','d','d','a','b']) data=np.random.randn(7,4) print(data) print('\n') print(names == 'c') data1 = data[names == 'c',:3]#bool型数组可用于数组索引,bool型数组的长度必须跟索引的轴长度一致 print('\n') print(data1)
[[ 0.73387967 -0.13396742 1.04269156 0.50659247] [-0.29486742 1.01473055 -1.01949127 0.58887479] [-0.36294505 0.63136804 -2.00127891 0.99116987] [-0.25219877 0.05331532 1.12972091 -0.30121878] [-0.0169668 -0.89554822 1.29417633 0.75185205] [ 2.44537039 -0.24624544 1.48954359 0.46221869] [-0.51382063 1.4213907 0.52372427 1.47648197]] [ True False True False False False False] [[ 0.73387967 -0.13396742 1.04269156] [-0.36294505 0.63136804 -2.00127891]]
data2 = data[names == 'c',2:] #布尔型数组可以跟切片、数组混合使用 print(data2) print('\n') data3 = data[names == 'c'][:,2:] print(data3)
[[ 1.04269156 0.50659247] [-2.00127891 0.99116987]] [[ 1.04269156 0.50659247] [-2.00127891 0.99116987]]
#行切片names==‘c’ ,列切片2:
#第二个从里向外切片
四.数学运算
1.shape大小相同数组的运算
arr = np.arange(1.0,7.0,1.0).reshape(2,3) print(arr) # 逐元素求和有下面2种方式 print(arr+arr) print(np.add(arr, arr))
[[1. 2. 3.] [4. 5. 6.]] [[ 2. 4. 6.] [ 8. 10. 12.]] [[ 2. 4. 6.] [ 8. 10. 12.]]
#逐元素相加
#+,-,*,/类似
2.数组和标量的运算
原理:标量扩散
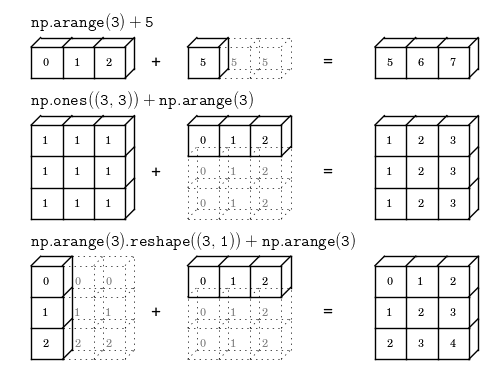
arry = array([[1., 2., 3.],[4., 5., 6.]]) print(arr**0.5) print(np.sqrt(arr))
[[1. 1.41421356 1.73205081] [2. 2.23606798 2.44948974]] [[1. 1.41421356 1.73205081] [2. 2.23606798 2.44948974]]
#先扩散,然后也是逐值计算
常用一元函数:
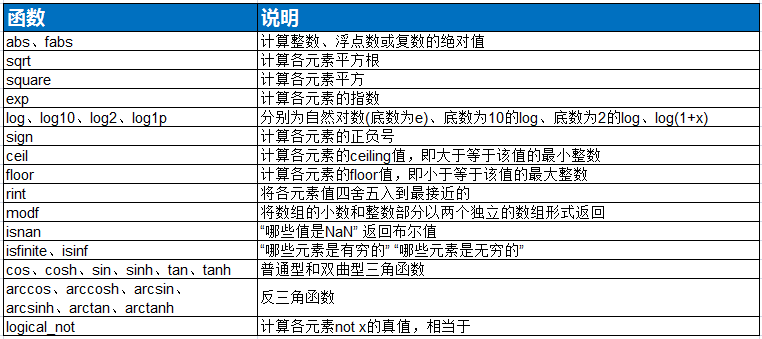
二元函数:
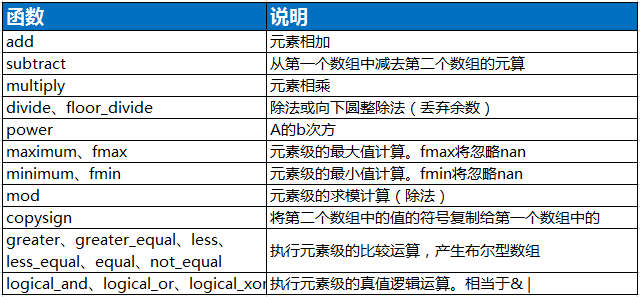
常用的线性代数函数:
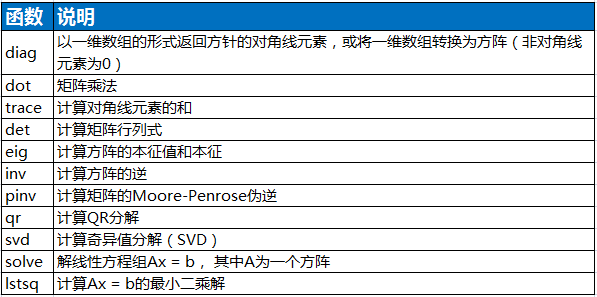
from numpy.linalg import inv,qr X = np.random.randn(5, 5) mat = X.T.dot(X) #求矩阵内积 print(inv(mat)) #求逆 print(mat.dot(inv(mat)))
[[ 0.40675231 0.11183059 -0.08805516 -0.20046372 -1.76301351] [ 0.11183059 1.27798816 -1.10952997 0.1088515 1.81130622] [-0.08805516 -1.10952997 1.29108391 -0.22829939 -2.07593474] [-0.20046372 0.1088515 -0.22829939 0.45621676 2.01392294] [-1.76301351 1.81130622 -2.07593474 2.01392294 16.48229329]] [[ 1.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00 1.77635684e-15] [ 0.00000000e+00 1.00000000e+00 -1.11022302e-16 0.00000000e+00 0.00000000e+00] [ 5.55111512e-17 2.77555756e-16 1.00000000e+00 5.55111512e-17 -8.88178420e-16] [ 2.22044605e-16 -4.44089210e-16 4.44089210e-16 1.00000000e+00 0.00000000e+00] [-1.11022302e-16 1.11022302e-16 -1.11022302e-16 1.11022302e-16 1.00000000e+00]]
五.数据处理
1.where
xarr = np.array([1, 2, 3, 4, 5]) yarr = np.array([6, 7, 8, 9, 19]) cond = np.array([True, False, True, True, False]) # 第一种写法,对大数组的处理速度比较慢 result1 = [(x if c else y) for x, y, c in zip(xarr, yarr, cond)] print(result1) # numpy.where result2 = np.where(cond, xarr, yarr) print(result2)
[1, 7, 3, 4, 19] [ 1 7 3 4 19]
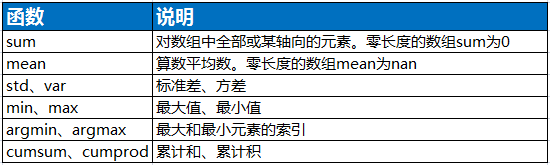
2.统计方法
arr = np.random.randn(5,4)#正态分布数据 print(arr) print(arr.sum()) # 数组/矩阵中所有元素求和,等价于np.sum(arr) print(np.sum(arr, axis=0))# 按列去求和; print(arr.sum(axis=1)) # 按行去求和;
[[ 0.4449193 -0.66455665 -1.29578277 -1.06878059] [-0.65963537 0.56946846 -0.26996897 -0.01304982] [ 1.01504064 1.76185179 -0.11382518 -0.79886855] [ 1.1019393 0.90575985 0.05371195 2.15402914] [ 0.11106307 0.43250148 -0.3535437 -0.21077938]] 3.101494000642924 [ 2.01332694 3.00502494 -1.97940867 0.06255079] [-2.58420071 -0.37318569 1.86419869 4.21544024 -0.02075853]
arr = np.arange(9).reshape(3,3) print(arr) print(np.cumsum(arr,axis=0)) print(arr.cumprod(axis=1))
[[0 1 2] [3 4 5] [6 7 8]] [[ 0 1 2] [ 3 5 7] [ 9 12 15]] [[ 0 0 0] [ 3 12 60] [ 6 42 336]]
3.布尔值中的统计
arr = np.random.randn(5) print(arr) print((arr>0).sum())#正值的数量
[ 1.98521117e+00 -1.30173333e-03 9.80322113e-02 -1.49823134e-01 -3.59224872e-01] 2
4.排序
arr = np.random.randn(5,3) print(arr) arr.sort(0) print(arr) s=-np.sort(-arr,axis=0)#降序 print(s)
[[ 0.17594824 0.22081621 -0.37765592] [-0.10412838 0.06174697 0.78731888] [ 0.05470166 2.212381 -0.71955813] [-0.84793938 0.87390117 -1.14479024] [-0.82463957 -0.23408029 -0.79473045]] [[-0.84793938 -0.23408029 -1.14479024] [-0.82463957 0.06174697 -0.79473045] [-0.10412838 0.22081621 -0.71955813] [ 0.05470166 0.87390117 -0.37765592] [ 0.17594824 2.212381 0.78731888]] [[ 0.17594824 2.212381 0.78731888] [ 0.05470166 0.87390117 -0.37765592] [-0.10412838 0.22081621 -0.71955813] [-0.82463957 0.06174697 -0.79473045] [-0.84793938 -0.23408029 -1.14479024]]
5.唯一化和其他集合逻辑
names = np.array(['Joe','Bob','Joe','Will','Bob','Will','Joe','Joe']) print(np.unique(names))#用np.uniuqe实现 print(sorted(set(names)))
['Bob' 'Joe' 'Will'] ['Bob', 'Joe', 'Will']
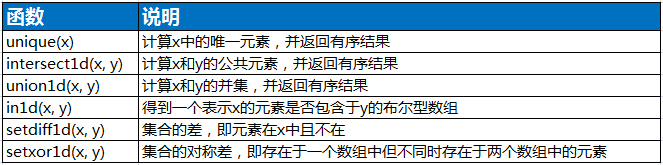
values = np.array([6,0,0,3,2,5,6]) print(np.in1d(values,[2,3,6]))
6.数组文件读写
arr = np.arange(100) np.save('some_array',arr) a = np.load('some_array.npy') print(a)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99]
np.savez('array_archive.npz',a=arr,b=arr) arch = np.load('array_archive.npz') print(arch['b'])
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99]
arr = np.random.randn(6,4) np.savetxt('array_ex.txt',arr,delimiter=',') a = np.loadtxt('array_ex.txt',delimiter=',') print(a)
[[ 0.15184947 -0.84105867 -1.6218855 -0.18569518] [-0.47682835 -0.28225368 -0.89479673 -1.27828212] [-2.27067269 1.10797779 -0.08058106 1.02757754] [ 1.37049964 -0.67386112 -0.20063499 -0.75387849] [-0.80252985 1.00853894 1.04195647 -0.57844144] [-0.25444971 -0.27975726 -1.1304201 0.89591945]]

