
函数(函数基础、装饰器、递归、匿名函数)
1. 函数知识体系-python代码缩进
什么是函数? 为什么要用函数? 函数的分类:内置函数与自定义函数 如何自定义函数 语法 定义有参数函数,及有参函数的应用场景 定义无参数函数,及无参函数的应用场景 定义空函数,及空函数的应用场景 调用函数 如何调用函数 函数的返回值 函数参数的应用:形参和实参,位置参数,关键字参数,默认参数,*args,**kwargs 高阶函数(函数对象) 函数嵌套 作用域与名称空间 装饰器 迭代器与生成器及协程函数 三元运算,列表解析、生成器表达式 函数的递归调用 内置函数 面向过程编程与函数式编程
Python中的代码缩进
Python中,是通过代码的缩进,来决定代码的逻辑的。(同缩进的先执行完,再执行更多缩进的代码块)
通俗的说,Python中的代码的缩进,不是为了好看,而是觉得代码的含义,上下行代码之间的关系。
缩进弄错了,就会导致程序出错,执行结果变成不是你想要的了。
参考: https://www.crifan.com/tutorial_python_indent/
如下:
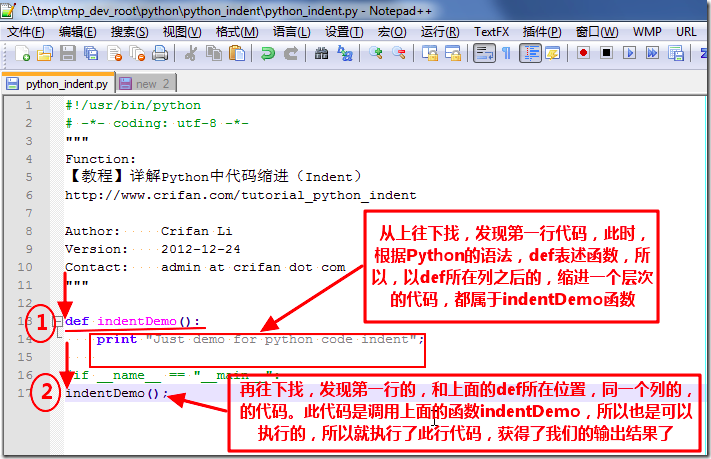
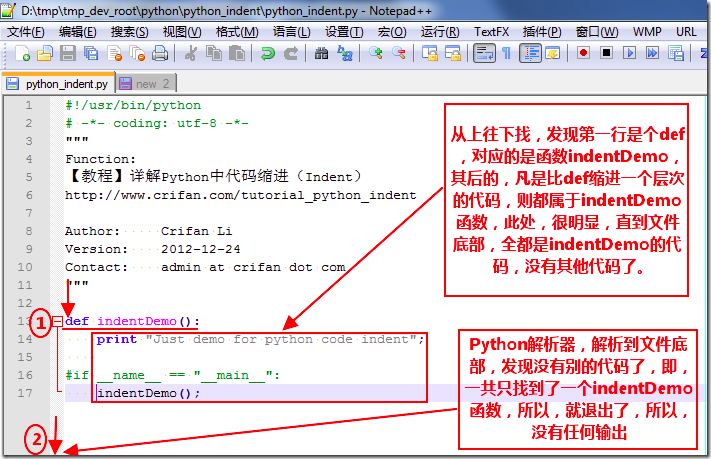

代码块
对应的,上述几个图解中,def indentDemo后面的代码,也就被因此成为代码块:
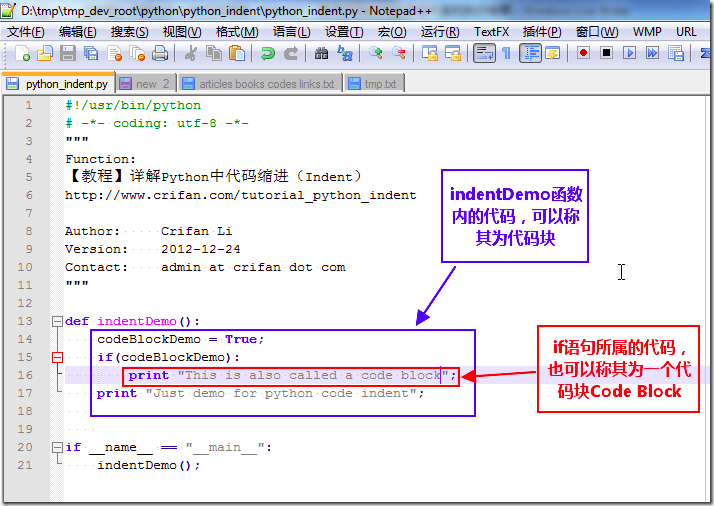
说白了,就是一个逻辑上的概念,可以简单理解为其他语言中的,一个函数内的代码,一个if判断内的代码等等相应的概念;
其他语言中的代码缩进:只是决定了是否好看,不影响代码逻辑和运行结果
2. 函数基础
2.1 引子
为何要用函数之不用函数的问题
#1、代码的组织结构不清晰,可读性差 #2、遇到重复的功能只能重复编写实现代码,代码冗余 #3、功能需要扩展时,需要找出所有实现该功能的地方修改之,无法统一管理且维护难度极大
函数是什么
针对二中的问题,想象生活中的例子,修理工需要实现准备好工具箱里面放好锤子,扳手,钳子等工具,然后遇到锤钉子的场景,拿来锤子用就可以,而无需临时再制造一把锤子。 修理工===>程序员 具备某一功能的工具===>函数 要想使用工具,需要事先准备好,然后拿来就用且可以重复使用 要想用函数,需要先定义,再使用
函数分类
#1、内置函数 为了方便我们的开发,针对一些简单的功能,python解释器已经为我们定义好了的函数即内置函数。对于内置函数,我们可以拿来就用而无需事先定义,如len(),sum(),max() ps:我们将会在最后详细介绍常用的内置函数。 #2、自定义函数 很明显内置函数所能提供的功能是有限的,这就需要我们自己根据需求,事先定制好我们自己的函数来实现某种功能,以后,在遇到应用场景时,调用自定义的函数即可。例如
2.2. 函数定义
如何自定义函数
#语法 def 函数名(参数1,参数2,参数3,...): '''注释''' 函数体 return 返回的值 #函数名要能反映其意义 def auth(user:str,password:str): ''' auth function :param user: 用户名 :param password: 密码 :return: 认证结果 ''' if user == 'egon' and password == '123': return 1 # print(auth.__annotations__) #{'user': <class 'str'>, 'password': <class 'str'>, 'return': <class 'int'>} user=input('用户名>>: ').strip() pwd=input('密码>>: ').strip() res=auth(user,pwd) print(res)
函数使用的原则:先定义,再调用


函数即“变量”,“变量”必须先定义后引用。未定义而直接引用函数,就相当于在引用一个不存在的变量名 #测试一 def foo(): print('from foo') bar() foo() #报错 #测试二 def bar(): print('from bar') def foo(): print('from foo') bar() foo() #正常 #测试三 def foo(): print('from foo') bar() def bar(): print('from bar') foo() #会报错吗? #结论:函数的使用,必须遵循原则:先定义,后调用 #我们在使用函数时,一定要明确地区分定义阶段和调用阶段 #定义阶段 def foo(): print('from foo') bar() def bar(): print('from bar') #调用阶段 foo()
函数定义的3中形式
#1、无参:应用场景仅仅只是执行一些操作,比如与用户交互,打印 #2、有参:需要根据外部传进来的参数,才能执行相应的逻辑,比如统计长度,求最大值最小值 #3、空函数:设计代码结构
#定义阶段 def tell_tag(tag,n): #有参数 print(tag*n) def tell_msg(): #无参数 print('hello world') #调用阶段 tell_tag('*',12) tell_msg() tell_tag('*',12) ''' ************ hello world ************ ''' #结论: #1、定义时无参,意味着调用时也无需传入参数 #2、定义时有参,意味着调用时则必须传入参数 无参、有参
def auth(user,password): ''' auth function :param user: 用户名 :param password: 密码 :return: 认证结果 ''' pass def get(filename): ''' :param filename: :return: ''' pass def put(filename): ''' :param filename: :return: ''' def ls(dirname): ''' :param dirname: :return: ''' pass #程序的体系结构立见 空函数
2.3 函数调用
函数调用的三种形式
1 语句形式:foo() 2 表达式形式:3*len('hello') 3 当中另外一个函数的参数:range(len('hello'))
函数返回值
无return->None return 1个值->返回1个值 return 逗号分隔多个值->元组
什么时候该有返回值?
调用函数,经过一系列的操作,最后要拿到一个明确的结果,则必须要有返回值
通常有参函数需要有返回值,输入参数,经过计算,得到一个最终的结果
什么时候不需要有返回值?
调用函数,仅仅只是执行一系列的操作,最后不需要得到什么结果,则无需有返回值
通常无参函数不需要有返回值
2.4 函数参数
#1、位置参数:按照从左到右的顺序定义的参数 位置形参:必选参数 位置实参:按照位置给形参传值 #2、默认参数:形参在定义时就已经为其赋值 可以传值也可以不传值,经常需要变得参数定义成位置形参,变化较小的参数定义成默认 参数(形参) 注意的问题: 1. 只在定义时赋值一次 2. 默认参数的定义应该在位置形参右面 3. 默认参数通常应该定义成不可变类型 #3.可变参数:可变长指的是实参值的个数不固定 #4、关键字参数:按照key=value的形式定义的实参 无需按照位置为形参传值 注意的问题: 1. 关键字实参必须在位置实参右面 2. 对同一个形参不能重复传值 #5、命名关键字参数:*后定义的参数,必须被传值(有默认值的除外),且必须按照关键字实参的形式传递 可以保证,传入的参数中一定包含某些关键字
函数参数几点总结:
1.必选参数: 有必选参数,调用时候就必须跟参数个数一致,也不能为空
def test(a,b): print(a,b) test(1) 结果: TypeError: test() takes exactly 2 arguments (1 given) test(1,2) #结果 (1,2)
2.当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。(选参数在前,默认参数在后)
把年龄和城市设为默认参数,name和gender是必选参数 def enroll(name, gender, age=6, city='Beijing'): print('name:', name) print('gender:', gender) print('age:', age) print('city:', city)
3.牢记:默认参数必须指向不变对象!
def add_end(L=[]): L.append("END") return L #正常调用结果是正常的,函数的默认参数没有变化 print add_end([1,2,3]) print add_end(['a','b','c'])
#默认参数调用,第一次正常,第二次调用的时候,默认参数就已经变成了['ENd']. print add_end() print add_end() 结果: [1, 2, 3, 'END'] ['a', 'b', 'c', 'END'] ['END'] ['END', 'END']
分析:Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,
默认参数的内容就变了,不再是函数定义时的[]了。
4. 可变参数。可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去。可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。
def foo1(x,y,*args): print(args) foo1(1,2,3,4,5) #从左到右依次给传参,剩余的参数自动作为可变参数args foo1(1,2,*[3,4,5,6]) #一般用这种调用方式 foo1(*[1,2,3,4])
foo1(*[1,2]) 结果: (3, 4, 5) (3, 4, 5, 6) (3, 4)
()
#一般常见可变参数使用
>>> nums = [1, 2, 3] >>> calc(*nums)
5.关键字参数:允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def foo(x, y, **kwargs): print(x, y) print(kwargs) foo(1, y=2, a=1, b=2, c=3) #从左到右依次给传参,剩余的参数自动作为关键字参数kwargs
结果: (1, 2) {'a': 1, 'c': 3, 'b': 2} foo(1,y=2,**{'a':1,'b':2}) 结果: (1, 2) {'a': 1, 'b': 2} foo(**{'x':1,'y':2,'other':3}) 结果: (1, 2) {'other': 3}
#关键字参数一般使用
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
6.命名关键字参数:和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。(python 2中没有)
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
仍以person()函数为例,我们希望检查是否有city和job参数:
def person(name, age, **kw): if 'city' in kw: # 有city参数 pass if 'job' in kw: # 有job参数 pass print('name:', name, 'age:', age, 'other:', kw) 但是调用者仍可以传入不受限制的关键字参数: >>> person('Jack', 24, city='Beijing', addr='Chaoyang', zipcode=123456)
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job): print(name, age, city, job)
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job): print(name, age, args, city, job)
参数组合:
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
3.函数对象、函数嵌套、名称空间与作用域、装饰器
3.1 函数对象
函数是第一类对象,即函数可以当作数据传递
#1 可以被引用 #2 可以当作参数传递 #3 返回值可以是函数 #3 可以当作容器类型的元素
3.2 函数嵌套
#函数嵌套定义 def f1(): ------------- 1 函数定义 def f2(): --------------3 调用函数进入函数内部代码块,定义f2 def f3(): ------------ 5 定义f3 print('from f3') -----------------7 进入f3,执行print f3() ----------------6 嗲用f3 f2() --------------------4 调用f2 f1() ----------------2 调用f1
注意: 根据代码缩进来执行,如上
改写一下上面的代码: 装饰器的调用差不多可以这样理解.外函数返回内函数的引用.
def father(name):
print('from father %s' %name)
def son():
print('from son')
def grandson():
print('from grandson')
return 1111111
return grandson
return son
print father('林海峰')()()
结果:
from father 林海峰
from son
from grandson
1111111
#函数嵌套调用 def max(x,y): return x if x > y else y def max4(a,b,c,d): res1=max(a,b) res2=max(res1,c) res3=max(res2,d) return res3 print(max4(1,2,3,4))
3.3 名称空间与作用域
什么是名称空间?
#名称空间:存放名字的地方,三种名称空间,(之前遗留的问题x=1,1存放于内存中,那名字x存放在哪里呢?名称空间正是存放名字x与1绑定关系的地方)
名称空间的加载顺序
python test.py #1、python解释器先启动,因而首先加载的是:内置名称空间 #2、执行test.py文件,然后以文件为基础,加载全局名称空间 #3、在执行文件的过程中如果调用函数,则临时产生局部名称空间
名字的查找顺序
局部名称空间--->全局名称空间--->内置名称空间 #需要注意的是:在全局无法查看局部的,在局部可以查看全局的,如下示例 # max=1 def f1(): # max=2 def f2(): # max=3 print(max) f2() f1() print(max)
作用域
#1、作用域即范围 - 全局范围(内置名称空间与全局名称空间属于该范围):全局存活,全局有效 - 局部范围(局部名称空间属于该范围):临时存活,局部有效 #2、作用域关系是在函数定义阶段就已经固定的,与函数的调用位置无关,如下 x=1 def f1(): def f2(): print(x) return f2 x=100 def f3(func): x=2 func() x=10000 f3(f1()) #3、查看作用域:globals(),locals() LEGB 代表名字查找顺序: locals -> enclosing function -> globals -> __builtins__ locals 是函数内的名字空间,包括局部变量和形参 enclosing 外部嵌套函数的名字空间(闭包中常见) globals 全局变量,函数定义所在模块的名字空间 builtins 内置模块的名字空间
3.4 闭包函数
在函数内部定义的函数和外部定义的函数是一样的,只是他们无法被外部访问
将 g 的定义移入函数 f 内部,防止其他代码调用 g: def f(): print 'f()...' def g(): print 'g()...' return g
参考: https://www.cnblogs.com/Lin-Yi/p/7305364.html
闭包:
闭包(closure)是函数式编程的重要的语法结构。函数式编程是一种编程范式 (而面向过程编程和面向对象编程也都是编程范式)。在面向过程编程中,我们见到过函数(function);在面向对
象编程中,我们见过对象(object)。函数和对象的根本目的是以某种逻辑方式组织代码,并提高代码的可重复使用性(reusability)。闭包也是一种组织代码的结构,它同样提高了代码的可重
复使用性。
def line_conf(a, b):
def line(x):
return a*x + b
return line
line1 = line_conf(1, 1)
line2 = line_conf(4, 5)
print(line1(5), line2(5))
这个例子中,函数line与环境变量a,b构 成闭包。在创建闭包的时候,我们通过line_conf的参数a,b说明了这两个环境变量的取值,这样,我们就确定了函数的最终形式(y = x + 1和y = 4x + 5)。我们只需要变换参数a,b,就可以获得不同的直线表达函数。由此,我们可以看到,闭包也具有提高代码可复用性的作用。
如果没有闭包,我们需要每次创建直线函数的时候同时说明a,b,x。这样,我们就需要更多的参数传递,也减少了代码的可移植性。利用闭包,我们实际上创建了泛函。line函数定义一种广泛意义的函数。这个函数的一些方面已经确定(必须是直线),但另一些方面(比如a和b参数待定)。随后,我们根据line_conf传递来的参数,通过闭包的形式,将最终函数确定下来。
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的
临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。因此,返回函数不要引用任何循环变量,或者后续会发生变化的变量。
# 希望一次返回3个函数,分别计算1x1,2x2,3x3:
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果全部都是 9。
返回闭包不能引用循环变量,请改写count()函数,让它正确返回能计算1x1、2x2、3x3的函数。
def count():
fs = []
for i in range(1, 4):
#问题的产生是因为函数只在执行时才去获取外层参数i,若函数定义时可以获取到i,问题便可解决。
#而默认参数正好可以完成定义时获取i值且运行函数时无需参数输入的功能,
#所以在函数f()定义中改为f(m = i),函数f返回值改为m*m即可.
def f(m = i):
return m * m
fs.append(f)
return fs
f1, f2, f3 = count()
print f1(), f2(), f3()
#闭包函数的实例 # outer是外部函数 a和b都是外函数的临时变量 def outer( a ): b = 10 # inner是内函数 def inner(): #在内函数中 用到了外函数的临时变量 print(a+b) # 外函数的返回值是内函数的引用 return inner if __name__ == '__main__': # 在这里我们调用外函数传入参数5 #此时外函数两个临时变量 a是5 b是10 ,并创建了内函数,然后把内函数的引用返回存给了demo # 外函数结束的时候发现内部函数将会用到自己的临时变量,这两个临时变量就不会释放,会绑定给这个内部函数 demo = outer(5) # 我们调用内部函数,看一看内部函数是不是能使用外部函数的临时变量 # demo存了外函数的返回值,也就是inner函数的引用,这里相当于执行inner函数 demo() # 15 demo2 = outer(7) demo2()#17
从上面例子是我写的一个最简单的很典型的闭包。我估计如果是初学的小伙伴,可能很多名词都不明白是什么意思,没关系,我把这些名词按照自己的理解去解释一下~
1 外函数返回了内函数的引用:
当我们进行a=1的时候,实际上在内存当中有一个地方存了值1,然后用a这个变量名存了1所在内存位置的引用。引用就好像c语言里的指针,大家可以把引用理解成地址。a只不过是一个变量名字,
a里面存的是1这个数值所在的地址,就是a里面存了数值1的引用。 相同的道理,当我们在python中定义一个函数def demo(): 的时候,内存当中会开辟一些空间,存下这个函数的代码、内部的局部变量等等。这个demo只不过是一个变量名字,它里面存了
这个函数所在位置的引用而已。我们还可以进行x = demo, y = demo, 这样的操作就相当于,把demo里存的东西赋值给x和y,这样x 和y 都指向了demo函数所在的引用,在这之后我们可以
用x() 或者 y() 来调用我们自己创建的demo() ,调用的实际上根本就是一个函数,x、y和demo三个变量名存了同一个函数的引用。
同时我们发现,一个函数,如果函数名后紧跟一对括号,相当于现在我就要调用这个函数,如果不跟括号,相当于只是一个函数的名字,里面存了函数所在位置的引用。
2 外函数把临时变量绑定给内函数:
按照我们正常的认知,一个函数结束的时候,会把自己的临时变量都释放还给内存,之后变量都不存在了。一般情况下,确实是这样的。但是闭包是一个特别的情况。外部函数发现,自己
的临时变量会在将来的内部函数中用到,自己在结束的时候,返回内函数的同时,会把外函数的临时变量送给内函数绑定在一起。所以外函数已经结束了,调用内函数的时候仍然能够使用外
函数的临时变量。
3 闭包中内函数修改外函数局部变量:
在基本的python语法当中,一个函数可以随意读取全局数据,但是要修改全局数据的时候有两种方法:1 global 声明全局变量 2 全局变量是可变类型数据的时候可以修改 在闭包内函数也是类似的情况。在内函数中想修改闭包变量(外函数绑定给内函数的局部变量)的时候: 1 在python3中,可以用nonlocal 关键字声明 一个变量, 表示这个变量不是局部变量空间的变量,需要向上一层变量空间找这个变量。 2 在python2中,没有nonlocal这个关键字,我们可以把闭包变量改成可变类型数据进行修改,比如列表。 #修改闭包变量的实例 # outer是外部函数 a和b都是外函数的临时变量 def outer( a ): b = 10 # a和b都是闭包变量 c = [a] #这里对应修改闭包变量的方法2 # inner是内函数 def inner(): #内函数中想修改闭包变量 # 方法1 nonlocal关键字声明 nonlocal b b+=1 # 方法二,把闭包变量修改成可变数据类型 比如列表 c[0] += 1 print(c[0]) print(b) # 外函数的返回值是内函数的引用 return inner if __name__ == '__main__': demo = outer(5) demo() # 6 11
还有一点需要注意:使用闭包的过程中,一旦外函数被调用一次返回了内函数的引用,虽然每次调用内函数,是开启一个函数执行过后消亡,但是闭包变量实际上只有一份,每次开启内函数都在使用同一份闭包变量
#coding:utf8 def outer(x): def inner(y): nonlocal x x+=y return x return inner a = outer(10) print(a(1)) //11 print(a(3)) //14
两次分别打印出11和14,由此可见,每次调用inner的时候,使用的闭包变量x实际上是同一个。
闭包有啥用
3.1装饰器!!!装饰器是做什么的??其中一个应用就是,我们工作中写了一个登录功能,我们想统计这个功能执行花了多长时间,我们可以用装饰器装饰这个登录模块,装饰器帮我
们完成登录函数执行之前和之后取时间。 3.2面向对象!!!经历了上面的分析,我们发现外函数的临时变量送给了内函数。大家回想一下类对象的情况,对象有好多类似的属性和方法,所以我们创建类,用类创建出
来的对象都具有相同的属性方法。闭包也是实现面向对象的方法之一。在python当中虽然我们不这样用,在其他编程语言入比如avaScript中,经常用闭包来实现面向对象编程 3.3实现单利模式!! 其实这也是装饰器的应用。单利模式毕竟比较高大,,需要有一定项目经验才能理解单利模式到底是干啥用的,我们就不探讨了。
4. 装饰器
参考: http://python.jobbole.com/85056/
http://www.cnblogs.com/linhaifeng/articles/7532497.html#_label5
http://python.jobbole.com/82344/
4.1 什么是装饰器
器即函数
装饰即修饰,意指为其他函数添加新功能
装饰器定义:本质就是函数,功能是为其他函数添加新功能
4.2 装饰器遵循原则
1.不修改被装饰函数的源代码(开放封闭原则)
2.为被装饰函数添加新功能后,不修改被修饰函数的调用方式
4.3 实现装饰器知识储备
装饰器=高阶函数+函数嵌套+闭包
4.4 高阶函数
高阶函数定义:
1.函数接收的参数是一个函数名
2.函数的返回值是一个函数名
3.满足上述条件任意一个,都可称之为高阶函数
def foo(): print('我的函数名作为参数传给高阶函数') def gao_jie1(func): print('我就是高阶函数1,我接收的参数名是%s' %func) func() def gao_jie2(func): print('我就是高阶函数2,我的返回值是%s' %func) return func gao_jie1(foo) gao_jie2(foo) 高阶函数示范
#高阶函数应用1:把函数当做参数传给高阶函数 import time def foo(): print('from the foo') def timmer(func): start_time=time.time() func() stop_time=time.time() print('函数%s 运行时间是%s' %(func,stop_time-start_time)) timmer(foo) #总结:我们确实为函数foo增加了foo运行时间的功能,但是foo原来的执行方式是foo(),现在我们需要调用高阶函数timmer(foo),改变了函数的调用方式 把函数当做参数传给高阶函数
#高阶函数应用2:把函数名当做参数传给高阶函数,高阶函数直接返回函数名 import time def foo(): print('from the foo') def timmer(func): start_time=time.time() return func stop_time=time.time() print('函数%s 运行时间是%s' %(func,stop_time-start_time)) foo=timmer(foo) foo() #总结:我们确实没有改变foo的调用方式,但是我们也没有为foo增加任何新功能 函数返回值是函数名
高阶函数总结
1.函数接收的参数是一个函数名
作用:在不修改函数源代码的前提下,为函数添加新功能,
不足:会改变函数的调用方式
2.函数的返回值是一个函数名
作用:不修改函数的调用方式
不足:不能添加新功能
4.5 函数嵌套
def father(name): print('from father %s' %name) def son(): print('from son') def grandson(): print('from grandson') grandson()
print locals() ##打印当前层的局部变量,同层的函数也属于 son() father('林海峰')
from father 林海峰
{'name': '\xe6\x9e\x97\xe6\xb5\xb7\xe5\xb3\xb0', 'son': <function son at 0x201e0c8>} #print locals()结果
from son
from grandson
4.6 无参装饰器
无参装饰器=高级函数+函数嵌套
基本框架
#这就是一个实现一个装饰器最基本的架子 def timer(func): def wrapper(): #该内函数引用了外函数的变量fun,所以说装饰器是闭包的一种应用. func() return wrapper #外函数返回内函数的引用,同理,内函数里面可以再返回另一个函数的引用或者返回值。所以装饰器实际最后执行的是最内层函数。最内层函数给原函数加上新功能.
加上参数
def timer(func): def wrapper(*args,**kwargs): func(*args,**kwargs) return wrapper
加上功能
import time def timer(func): def wrapper(*args,**kwargs): start_time=time.time() func(*args,**kwargs) stop_time=time.time() print('函数[%s],运行时间是[%s]' %(func,stop_time-start_time)) return wrapper
加上返回值,如果要想得到被装饰函数的返回值
import time def timer(func): def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) # 被装饰函数返回值 stop_time=time.time() print('函数[%s],运行时间是[%s]' %(func,stop_time-start_time)) return res #返回被装饰函数的返回值 return wrapper
使用装饰器
def cal(array): res=0 for i in array: res+=i return res cal=timer(cal) cal(range(10))
语法糖@
@timer #@timer就等同于cal=timer(cal) def cal(array): res=0 for i in array: res+=i return res cal(range(10))
4.7 装饰器应用示例
装饰器为函数加上验证功能
user_list=[ {'name':'alex','passwd':'123'}, {'name':'linhaifeng','passwd':'123'}, {'name':'wupeiqi','passwd':'123'}, {'name':'yuanhao','passwd':'123'}, ] current_user={'username':None,'login':False} def auth_deco(func): def wrapper(*args,**kwargs): if current_user['username'] and current_user['login']: res=func(*args,**kwargs) return res username=input('用户名: ').strip() passwd=input('密码: ').strip() for index,user_dic in enumerate(user_list): if username == user_dic['name'] and passwd == user_dic['passwd']: current_user['username']=username current_user['login']=True res=func(*args,**kwargs) return res break else: print('用户名或者密码错误,重新登录') return wrapper @auth_deco def index(): print('欢迎来到主页面') @auth_deco def home(): print('这里是你家') def shopping_car(): print('查看购物车啊亲') def order(): print('查看订单啊亲') print(user_list) # index() print(user_list) home() 无参装饰器
装饰器模拟session
user_list=[ {'name':'alex','passwd':'123'}, {'name':'linhaifeng','passwd':'123'}, {'name':'wupeiqi','passwd':'123'}, {'name':'yuanhao','passwd':'123'}, ] current_user={'username':None,'login':False} #保存用户是否登录 def auth(auth_type='file'): def auth_deco(func): def wrapper(*args,**kwargs): if auth_type == 'file': if current_user['username'] and current_user['login']: #登录了直接执行 res=func(*args,**kwargs) return res username=input('用户名: ').strip() passwd=input('密码: ').strip() for index,user_dic in enumerate(user_list):#没登录验证用户密码 if username == user_dic['name'] and passwd == user_dic['passwd']: current_user['username']=username #更改登录状态 current_user['login']=True res=func(*args,**kwargs) return res else: print('用户名或者密码错误,重新登录') elif auth_type == 'ldap': print('巴拉巴拉小魔仙') res=func(*args,**kwargs) return res return wrapper return auth_deco #auth(auth_type='file')就是在运行一个函数,然后返回auth_deco,所以@auth(auth_type='file') #就相当于@auth_deco,只不过现在,我们的auth_deco作为一个闭包的应用,外层的包auth给它留了一个auth_type='file'参数 @auth(auth_type='ldap') def index(): print('欢迎来到主页面') @auth(auth_type='ldap') def home(): print('这里是你家') def shopping_car(): print('查看购物车啊亲') def order(): print('查看订单啊亲') # print(user_list) index() # print(user_list) home() 带参装饰器
4.8 超时装饰器
import sys,threading,time class KThread(threading.Thread): """A subclass of threading.Thread, with a kill() method. Come from: Kill a thread in Python: http://mail.python.org/pipermail/python-list/2004-May/260937.html """ def __init__(self, *args, **kwargs): threading.Thread.__init__(self, *args, **kwargs) self.killed = False def start(self): """Start the thread.""" self.__run_backup = self.run self.run = self.__run # Force the Thread to install our trace. threading.Thread.start(self) def __run(self): """Hacked run function, which installs the trace.""" sys.settrace(self.globaltrace) self.__run_backup() self.run = self.__run_backup def globaltrace(self, frame, why, arg): if why == 'call': return self.localtrace else: return None def localtrace(self, frame, why, arg): if self.killed: if why == 'line': raise SystemExit() return self.localtrace def kill(self): self.killed = True class Timeout(Exception): """function run timeout""" def timeout(seconds): """超时装饰器,指定超时时间 若被装饰的方法在指定的时间内未返回,则抛出Timeout异常""" def timeout_decorator(func): """真正的装饰器""" def _new_func(oldfunc, result, oldfunc_args, oldfunc_kwargs): result.append(oldfunc(*oldfunc_args, **oldfunc_kwargs)) def _(*args, **kwargs): result = [] new_kwargs = { # create new args for _new_func, because we want to get the func return val to result list 'oldfunc': func, 'result': result, 'oldfunc_args': args, 'oldfunc_kwargs': kwargs } thd = KThread(target=_new_func, args=(), kwargs=new_kwargs) thd.start() thd.join(seconds) alive = thd.isAlive() thd.kill() # kill the child thread if alive: raise Timeout(u'function run too long, timeout %d seconds.' % seconds) else: return result[0] _.__name__ = func.__name__ _.__doc__ = func.__doc__ return _ return timeout_decorator @timeout(5) def method_timeout(seconds, text): print('start', seconds, text) time.sleep(seconds) print('finish', seconds, text) return seconds method_timeout(6,'asdfasdfasdfas')
4.9 类装饰器
参考: https://blog.csdn.net/hesi9555/article/details/70224911
def decorate(cls): print('类的装饰器开始运行啦------>') return cls @decorate #无参:People=decorate(People) class People: def __init__(self,name,age,salary): self.name=name self.age=age self.salary=salary p1=People('egon',18,3333.3) 类的装饰器:无参
def typeassert(**kwargs): def decorate(cls): print('类的装饰器开始运行啦------>',kwargs) return cls return decorate @typeassert(name=str,age=int,salary=float) #有参:1.运行typeassert(...)返回结果是decorate,此时参数都传给kwargs 2.People=decorate(People) class People: def __init__(self,name,age,salary): self.name=name self.age=age self.salary=salary p1=People('egon',18,3333.3) 类的装饰器:有参
class Typed: def __init__(self,name,expected_type): self.name=name self.expected_type=expected_type def __get__(self, instance, owner): print('get--->',instance,owner) if instance is None: return self return instance.__dict__[self.name] def __set__(self, instance, value): print('set--->',instance,value) if not isinstance(value,self.expected_type): raise TypeError('Expected %s' %str(self.expected_type)) instance.__dict__[self.name]=value def __delete__(self, instance): print('delete--->',instance) instance.__dict__.pop(self.name) def typeassert(**kwargs): def decorate(cls): print('类的装饰器开始运行啦------>',kwargs) for name,expected_type in kwargs.items(): setattr(cls,name,Typed(name,expected_type)) return cls return decorate @typeassert(name=str,age=int,salary=float) #有参:1.运行typeassert(...)返回结果是decorate,此时参数都传给kwargs 2.People=decorate(People) class People: def __init__(self,name,age,salary): self.name=name self.age=age self.salary=salary print(People.__dict__) p1=People('egon',18,3333.3) 刀光剑影
def typed(**kwargs): def deco(cls): for key,value in kwargs.items(): setattr(cls,key,value) return cls return deco @typed(name="che") class Foo(object): pass print Foo.name print Foo.__dict__
class Typed: def __init__(self,name,expected_type): self.name=name self.expected_type=expected_type def __get__(self, instance, owner): print('get--->',instance,owner) if instance is None: return self return instance.__dict__[self.name] def __set__(self, instance, value): print('set--->',instance,value) if not isinstance(value,self.expected_type): raise TypeError('Expected %s' %str(self.expected_type)) instance.__dict__[self.name]=value def __delete__(self, instance): print('delete--->',instance) instance.__dict__.pop(self.name) def typeassert(**kwargs): def decorate(cls): print('类的装饰器开始运行啦------>',kwargs) for name,expected_type in kwargs.items(): setattr(cls,name,Typed(name,expected_type)) return cls return decorate @typeassert(name=str,age=int,salary=float) #有参:1.运行typeassert(...)返回结果是decorate,此时参数都传给kwargs 2.People=decorate(People) class People: def __init__(self,name,age,salary): self.name=name self.age=age self.salary=salary print(People.__dict__) p1=People('egon',18,3333.3)
====================================================================================================
装饰器就是闭包函数的一种应用场景
为何使用装饰器: 开放封闭原则:对修改封闭,对扩展开放
什么是装饰器:
装饰其他人的器具,本身可以是任意可调用对象,被装饰者也可以是任意可调用对象。 强调装饰器的原则: 1 不修改被装饰对象的源代码 2 不修改被装饰对象的调用方式 装饰器的目标:在遵循1和2的前提下,为被装饰对象添加上新功能
装饰器语法:
被装饰函数的正上方,单独一行 @deco1 @deco2 @deco3 def foo(): pass foo=deco1(deco2(deco3(foo)))
装饰器例子:
被装饰的函数带参数(未使用语法糖调用): import time def deco(fun): #fun接收函数名 def warp(a,b): #a,b啊接收被装饰函数的参数 start = time.time() fun(a,b) end = time.time() alltime = end - start print 'run myfun() cost %0.2f s' %alltime return warp def myfun(a,b): print 'myfun() called and a + b = %d!' %(a+b) time.sleep(1.5) print "myfun is :", myfun.__name__ myfun = deco(myfun) #将myfun重新赋值,”@deco”的本质就是”myfunc = deco(myfunc)” print "myfun is:",myfun.__name__ print myfun(1,2) 输出如下: myfun is : myfun myfun is: warp myfun() called and a + b = 3! run myfun() cost 1.50 s 使用语法糖: @deco #@deco”的本质就是”myfunc = deco(myfunc) def myfun(a,b): print 'myfun() called and a + b = %d!' %(a+b) time.sleep(1.5) myfun(1,2) #这里返回的是deco中的warp函数,相当于myfun的代码没变,现在在原有基础上添加了 时间测试的功能。 注意:对于被装饰函数需要支持参数的情况,我们只要使装饰器的内嵌函数支持同样的签名即可。
带参数的装饰器 import time def deco(arg=True): #arg 为装饰器参数 if arg: def _deco(fun):# fun 接收被装饰的函数名 def warp(*args,**kwargs): #*args,**kwargs 接收被装饰函数的参数
start = time.time()
fun(*args,**kwargs)
end = time.time()
alltime = end - start
print 'run myfun() cost %0.2f s' %alltime
return warp
else:
def _deco(fun):
return fun
return _deco
@deco(True) #相当于 myfun = deco(True)(myfun)
def myfun(a,b):
print 'myfun() called and a + b = %d!' %(a+b)
time.sleep(1.5)
myfun(1,2) 注意:如果装饰器本身需要支持参数,那么装饰器就需要多一层的内嵌函数。这时候, myfun = deco(True)(myfun)
装饰器是可以叠加使用的,那么这是就涉及到装饰器调用顺序了。对于Python中的”@”语法糖, 装饰器的调用顺序与使用 @ 语法糖声明的顺序相反。
5. 递归
递归调用的定义
#递归调用是函数嵌套调用的一种特殊形式,函数在调用时,直接或间接调用了自身,就是递归调用
递归分为两个阶段:递推,回溯
#图解。。。 # salary(5)=salary(4)+300 # salary(4)=salary(3)+300 # salary(3)=salary(2)+300 # salary(2)=salary(1)+300 # salary(1)=100 # # salary(n)=salary(n-1)+300 n>1 # salary(1) =100 n=1 def salary(n): if n == 1: return 100 return salary(n-1)+300 print(salary(5))
python中的递归效率低且没有尾递归优化
#python中的递归 python中的递归效率低,需要在进入下一次递归时保留当前的状态,在其他语言中可以有解决方法:尾递归优化,即在函数的最后一步(而非最后一行)调用自己,
尾递归优化:http://egon09.blog.51cto.com/9161406/1842475 但是python又没有尾递归,且对递归层级做了限制 #总结递归的使用: 1. 必须有一个明确的结束条件 2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少 3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,
栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
6. 匿名函数
什么是匿名函数?
匿名就是没有名字 def func(x,y,z=1): return x+y+z 匿名 lambda x,y,z=1:x+y+z #与函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放,除非让其有名字 func=lambda x,y,z=1:x+y+z func(1,2,3) #让其有名字就没有意义
匿名函数lambda. 关键字lambda表示匿名函数,冒号前面的表示函数参数。不用写return,返回值就是该表达式的结果。
有名字的函数与匿名函数的对比
#有名函数与匿名函数的对比 有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能 匿名函数:一次性使用,随时随时定义 应用:max,min,sorted,map,reduce,filter
7. 内置函数
#enumerate() >>> for i in enumerate([0,1,2,3]): ... print i ... ... (0, 0) (1, 1) (2, 2) (3, 3) #eval 1. 提取出字符串中的数据结构 >>> dict_str = "{'a':1,'b':2}" >>> eval(dict_str) {'a': 1, 'b': 2} 2.把字符串表达式进行运算 >>> eval("1+2/3*4") 1 #zip,像拉链一样将2个序列一一对应组成元组 >>> list(zip(('a','b','c'),(1,2,3))) [('a', 1), ('b', 2), ('c', 3)] >>> p = {'name':'che','age':18,'gender':'male'} >>> list(zip(p.keys(),p.values())) [('gender', 'male'), ('age', 18), ('name', 'che')] >>> list(zip("hellp",(1,2,3))) [('h', 1), ('e', 2), ('l', 3)] #max() min(),同类型比较,是对序列进行for循环来比较 >>> max((5,5),(4,5)) (5, 5) 例子: 找出字典中年龄最大的人,zip结合使用 >>> d {'age4': 100, 'age3': 100, 'age2': 20, 'age1': 18} >>> max(zip(d.values(),d.keys())) (100, 'age4') 例子:找出一个一个班级年龄最大的学生信息 d = [ {'name':'che','age':12}, {'name':'che1','age':20}, {'name':'che2','age':100}, ] print(max(d,key=lambda dic:dic['age'])) #sorted 排序,同类型排序,也是for循环比较 d = [ {'name':'che','age':12}, {'name':'che1','age':20}, {'name':'che2','age':100}, ] print sorted(d,key=lambda dic:dic['age'])

