HashMap 的理解与结构
hashMap 1.8版本:
底层是数组+链表+红黑树
数组中存的是对象(node)对象里面有key value 和 next 是指向下一个的标记 还有一个int 类型的hash值
hashmap插入链表的时候采用的是 尾插法。
需要找一个中间的平衡点, 当我们的数组长度小于平衡值 用链表, 大于平衡值用 红黑树
什么时候使用链表:当我们的链表的个数小于8 的时候使用链表
什么时候使用红黑树:当我们的链表个数大于8的时候就转成红黑树
为什么是链表个数是8 , 因为在源代码中了解到, 使用的是(泊松分布 poisson distribution)当链表个数是8 的时候 重复的概率是一亿个中只有6个重复的
链表和红黑树的转换:
当数组长度不够的时候怎么扩容: 会创建一个是原来2倍的数组 , len = 2的n次幂 原来的数据的 0.75f 倍
当我们的数组长度的扩容之后:
需要把原来的数据存在新的数组中, 需要今天判断当 我们的链表 hash & oldcap 等于0 放到原有的位置, 不等于0的时候就放早老数组加1的位置上,
当的数组是红黑树的时候: 就重新打乱重新放在新的数组中
hashMap 1.7 的理解:
hashMap 的底层是数组+ 链表, 又称为 链地址法。
HashMap 是继承了map的接口,允许null键和null值。map放入的值得顺序是无序的。 HashMap的线程是不安全的。
HashMap 需要重新计算 hash 值。
hashmap在取值的时候 get方面根据 key(hashcode)–>hash–>indexFor–>最终索引位置 e.hash == hash 没有必要 ,如果没这个判断可以可能到的数据是null的,
如果传入的key对象重写了equals方法却没有重写hashCode,而恰巧此对象定位到这个数组位置,如果仅仅用equals判断可能是相等的,但其hashCode和当前对象不一致,这种情况,根据Object的hashCode的约定,不能返回当前对象,而应该返回null。
对红黑树的理解:
主要就是recolor 标色 和 rotation 旋转 , 旋转分为 左旋转 和右旋转。
根节点 是黑色的 ; 相邻的父节点和子节点不能同时为红
hashMap 的遍历方法一:
效率高。
Map map = new HashMap(); Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); Object key = entry.getKey(); Object val = entry.getValue(); }
hashMap 遍历方法二:
效率低, 尽量不采用。
Map map = new HashMap(); Iterator iter = map.keySet().iterator(); while (iter.hasNext()) { Object key = iter.next(); Object val = map.get(key); }
hashMap的put过程:
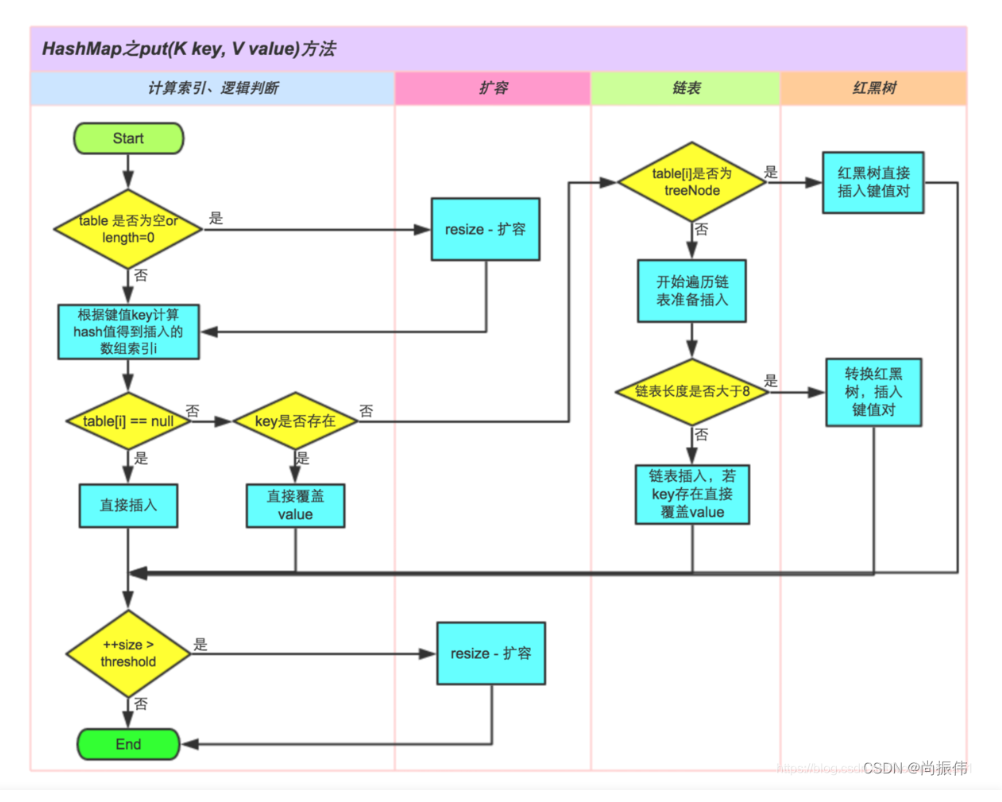
HashMap的数据结构在jdk1.8之前是数组+链表,为了解决数据量过大、链表过长是查询效率会降低的问题变成了数组+链表+红黑树的结构,利用的是红黑树自平衡的特点。
链表的平均查找时间复杂度是O(n),红黑树是O(log(n))。
HashMap中的put方法执行过程大体如下:
1、判断键值对数组table[i]是否为空(null)或者length=0,是的话就执行resize()方法进行扩容。
2、不是就根据键值key计算hash值得到插入的数组索引i。
3、判断table[i]==null,如果是true,直接新建节点进行添加,如果是false,判断table[i]的首个元素是否和key一样,一样就直接覆盖。
4、判断table[i]是否为treenode,即判断是否是红黑树,如果是红黑树,直接在树中插入键值对。
5、如果不是treenode,开始遍历链表,判断链表长度是否大于8,如果大于8就转成红黑树,在树中执行插入操作,如果不是大于8,就在链表中执行插入;在遍历过程中判断key是否存在,存在就直接覆盖对应的value值。
6、插入成功后,就需要判断实际存在的键值对数量size是否超过了最大容量threshold,如果超过了,执行resize方法进行扩容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号