
线上服务Java进程假死快速排查、分析
引用
https://zhuanlan.zhihu.com/p/529350757
最近我们有一台服务器上的Java进程总是在运行个两三天后就无法响应请求了,具体现象如下:
- 请求业务返回状态码502,查看进程还在,意味着Java进程假死,无法响应请求了;
- 该Java进程占比CPU较高,高达132.8%。
所以再次发生的时候我摘了这台服务器,保留现场排查该Java应用程序存在什么问题。
使用top命令查看服务器整体运行情况:
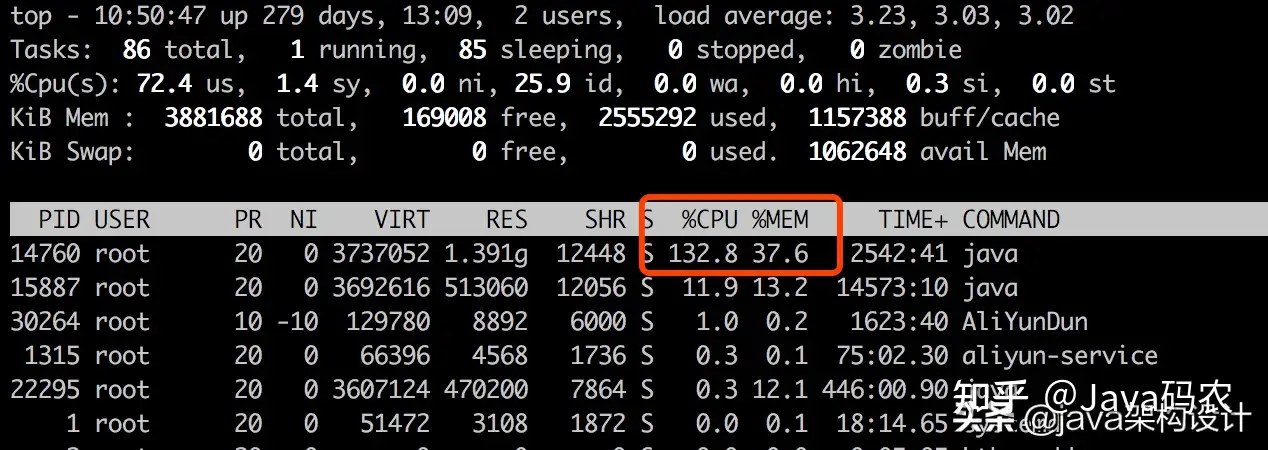
可以看到PID为14760的Java进程CPU占比132.8%,内存占用37.6%,内存倒是在合理范围内,但是这个CPU就太高了。
接下来我们就根据线上的真实情况来一步一步排查出所运行程序的问题代码。
建议大家收藏此文,以便大家遇到类似问题后可以参考排查步骤快速排查服务性能问题。
查看进程14760的线程堆栈信息
执行命令:
top -Hp 14760打印出当前进程的所有线程的运行情况:
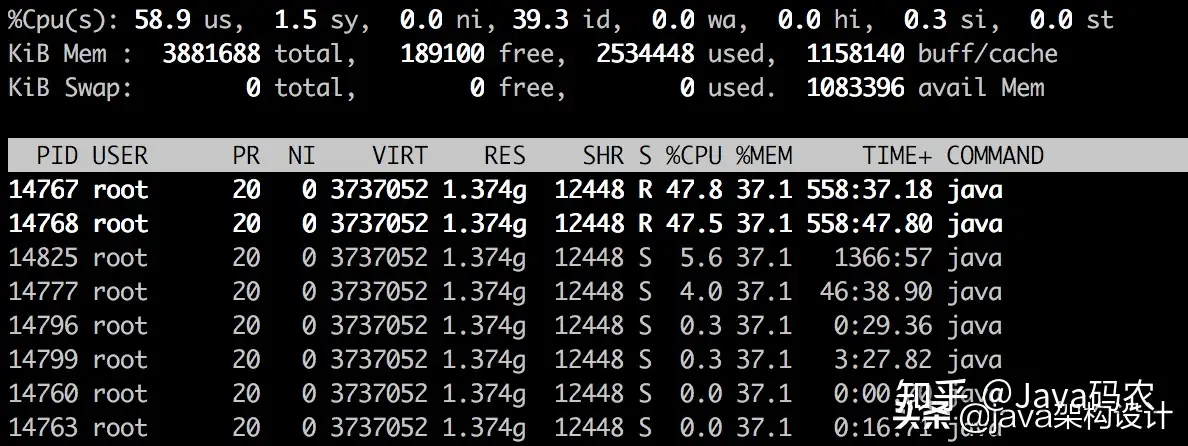
发现PID为14767和14768的两个线程的CPU占比分别为47.8%和47.5%,而且TIME+占比较大,说明这两个线程一直在运行。
继续使用jstack命令来查看这两个线程的堆栈信息,jstack的基本命令格式如下:
jstack <pid> | grep '16进制的线程Id'可以通过如下命令获取14767这个线程的16进制数值:
printf '%x\n' 14767输出:740f,执行jstack相关命令:
jstack 14760 | grep -a 0x39af -C20 --color其中这个-C20是显示当前行的上下20行 ,如果没有这个命令就只有孤零零的当前行,看不出更多有效的信息,输出内容如下:
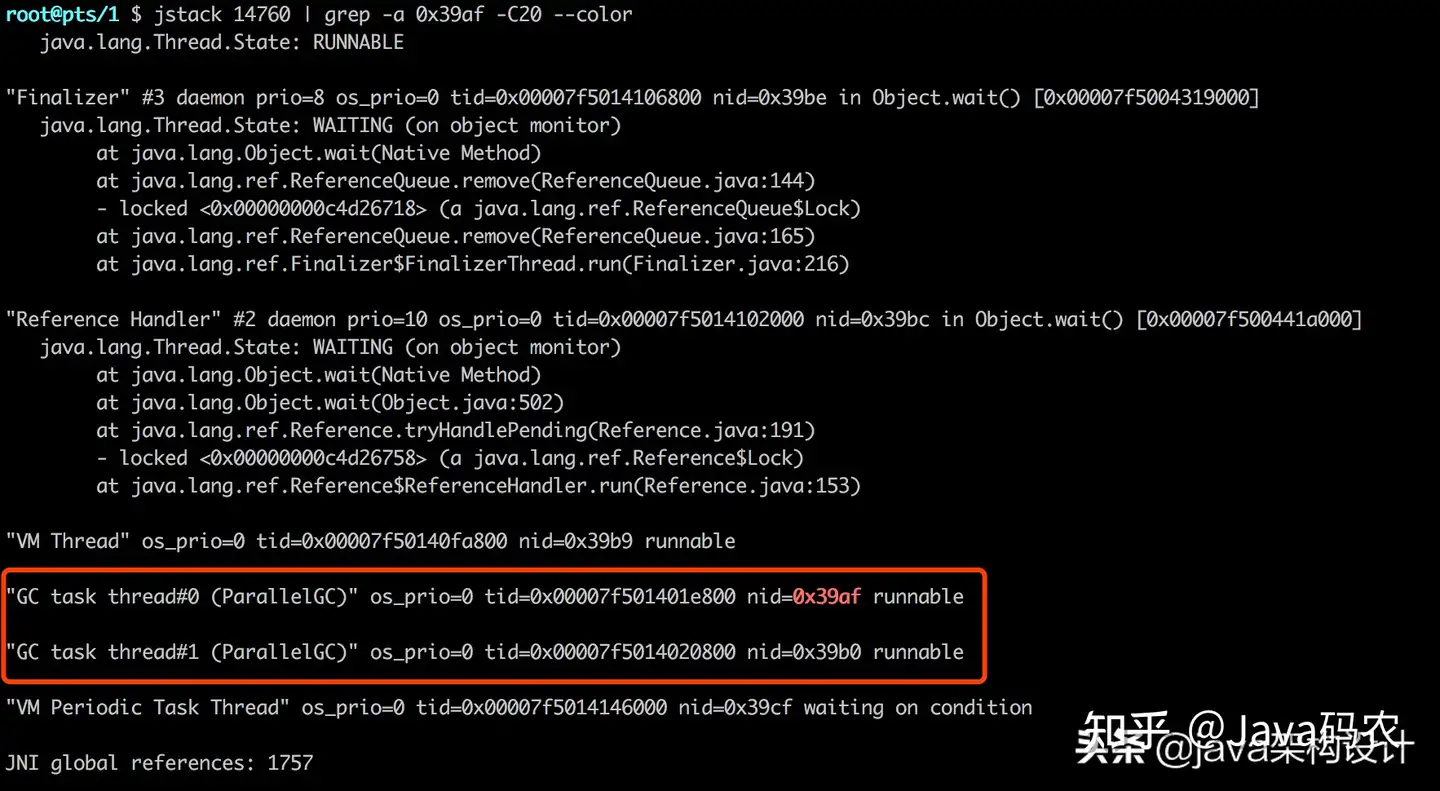
通过上图就可以看到线程为什么吃CPU了,如果显示的是大家自己开发的业务代码,相信大家直接就可以review代码找出问题所在了。
但是有时候我们并不能根据线程Id就能查出有问题的代码在哪里,比如上图这种情况,红框里的两个线程是GC task Thread,说明线程一直在进行GC,而上面的其他线程则是出于WAITING等待状态,也就是说造成Java服务进程假死的原因是因为JVM的长时间GC导致的Stop The World!
所以我们要找出来到底是什么原因导致的进程一直在GC,而无法响应业务请求。
jstat命令排查GC信息
既然是GC有问题,那么我们继续使用jstat命令来查看JVM heap的信息。
先来快速了解一下jstat命令的介绍和用法。
jstat命令格式如下:
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]相关参数:
- -class:显示加载class的数量以及所占空间信息
- -compiled:显示VM实时编译的数量信息
- -gc:显示gc的信息,查看gc的次数、时间
- -gccapacity:显示VM内存中三代(young、old、perm)对象的使用和占用大小
- -gcutil:统计gc信息
- -gcnew:统计VM年轻代信息
- -gcnewcapacity:VM年轻代对象的信息及占用量
- -gcold:VM年老代信息
- -gcoldcapacity:VM年老代对象的信息及占用量
- -gcpermcapacity:VM中永久代的信息及占用量
- -printcompilation:当前VM执行的信息。
执行命令:
jstat -gcutil 14760 1000得出的GC Heap数据如图所示:
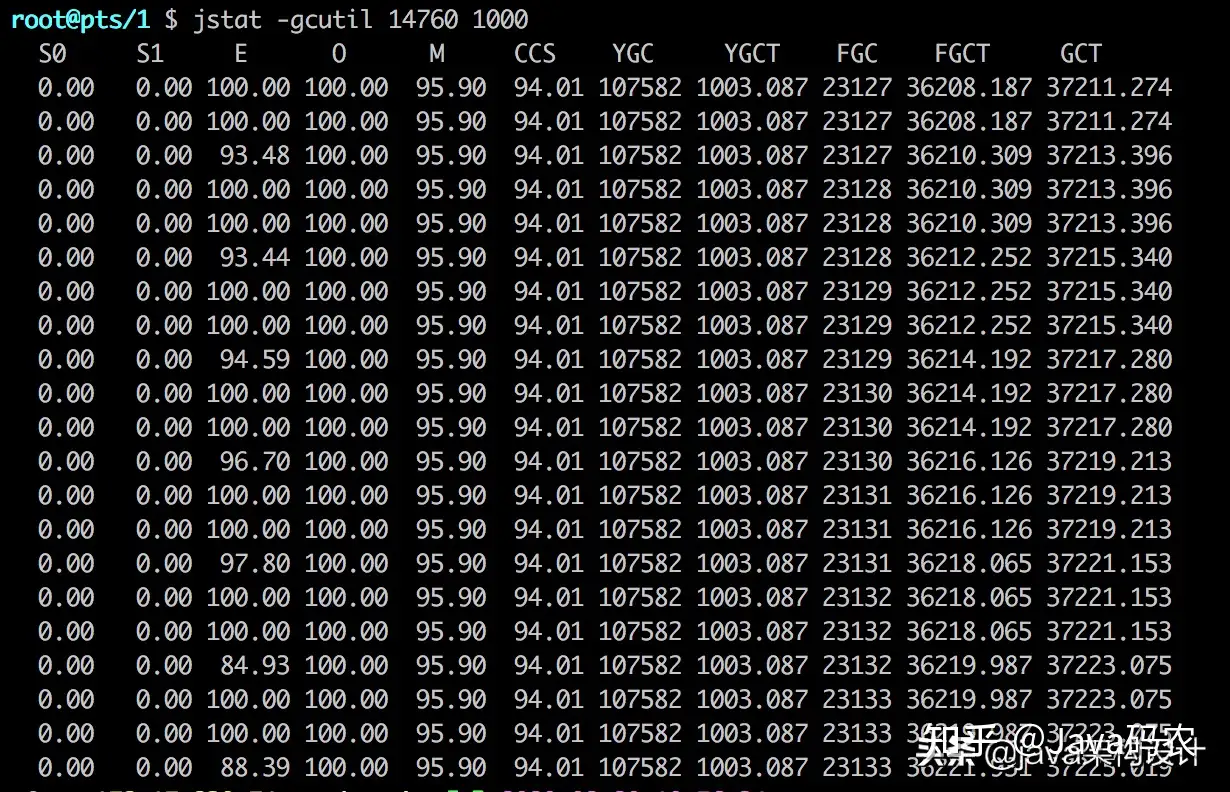
其中:
- S0:幸存1区当前使用比例
- S1:幸存2区当前使用比例
- E:伊甸园区使用比例
- O:老年代使用比例
- M:元数据区使用比例
- CCS:压缩使用比例
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
从图中的数据可以发现E(Eden区)和O(Old区)的内存已经被耗尽了,占比高达100%,FGC(Full GC)的次数高达23133次,FGCT(Full GC Time)总时间高达36221.931秒,每次FGC耗时36221.931/23133≈1.6秒,很显然Java进程都把时间花在FGC上了。
jmap命令拿到dump日志文件
通过以上数据分析,可以初步定为问题发生在程序的内存泄漏上。这时候就需要使用到jmap的命令了,我们可以通过jmap命令输出指定Java进程的dump二进制文件:
jmap -dump:format=b,file=heap.bin <pid>

导出的heap二进制文件大小竟然高达1.2G!
接下来开始用MAT工具分析拿到的dump文件,关于如何使用MAT(Memory Analyzer Tools)分析dump文件,可以查阅我的另一篇文章:
MAT(Memory Analyzer Tool)-Java内存分析入门实践
由于文件超过1个G,Mac下MAT的默认Xmx是1024m,所以我们需要加大MAT的最大可用内存,否则无法分析这么大的文件。
打开MAT找到MAT在mac中的安装位置:
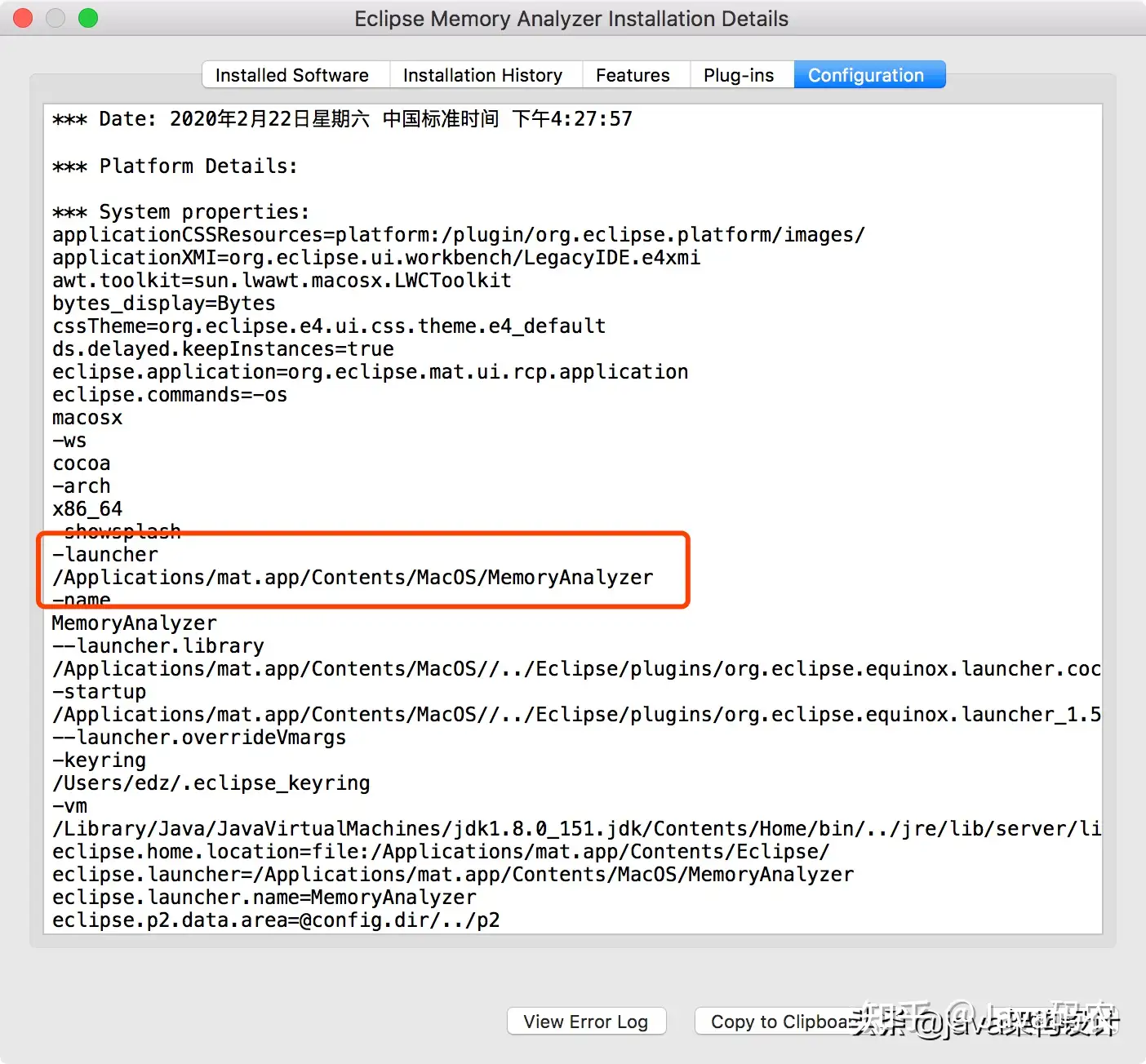
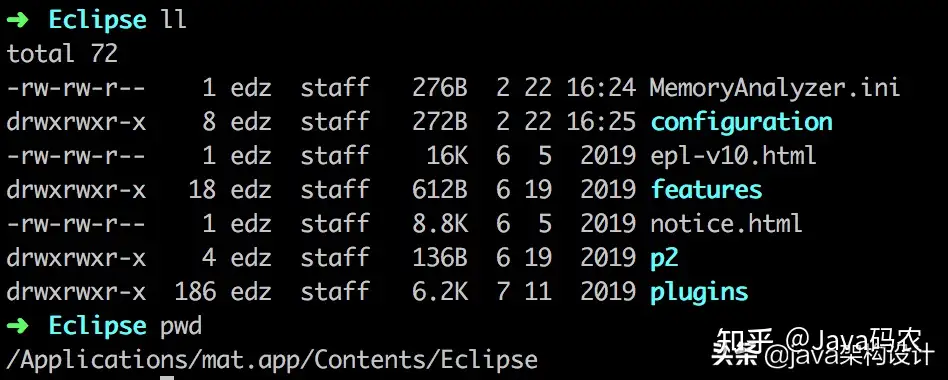
编辑MemoryAnalyzer.ini文件里面的xmx1024m为4096m:
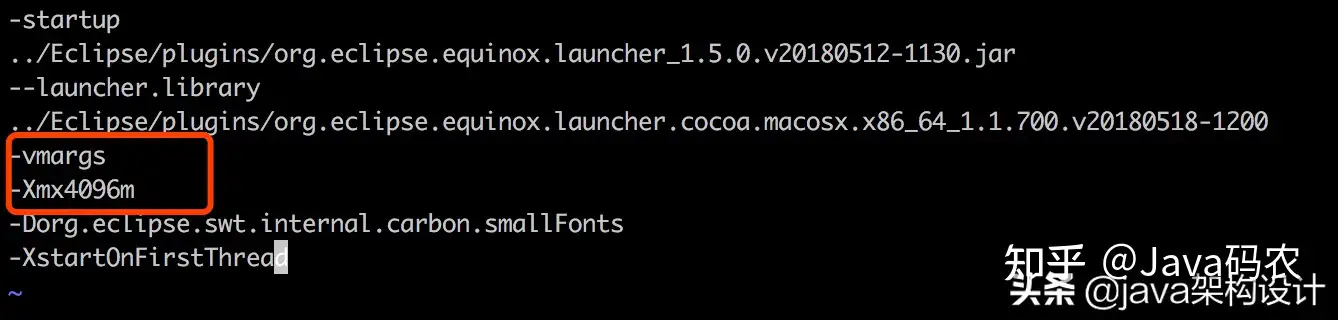
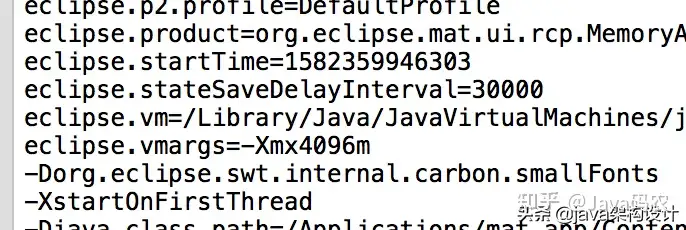
保存后重启MAT,查看原来的位置可以看见内容已经更改了:
开始分析dump文件!分析后得到的结果如图所示:
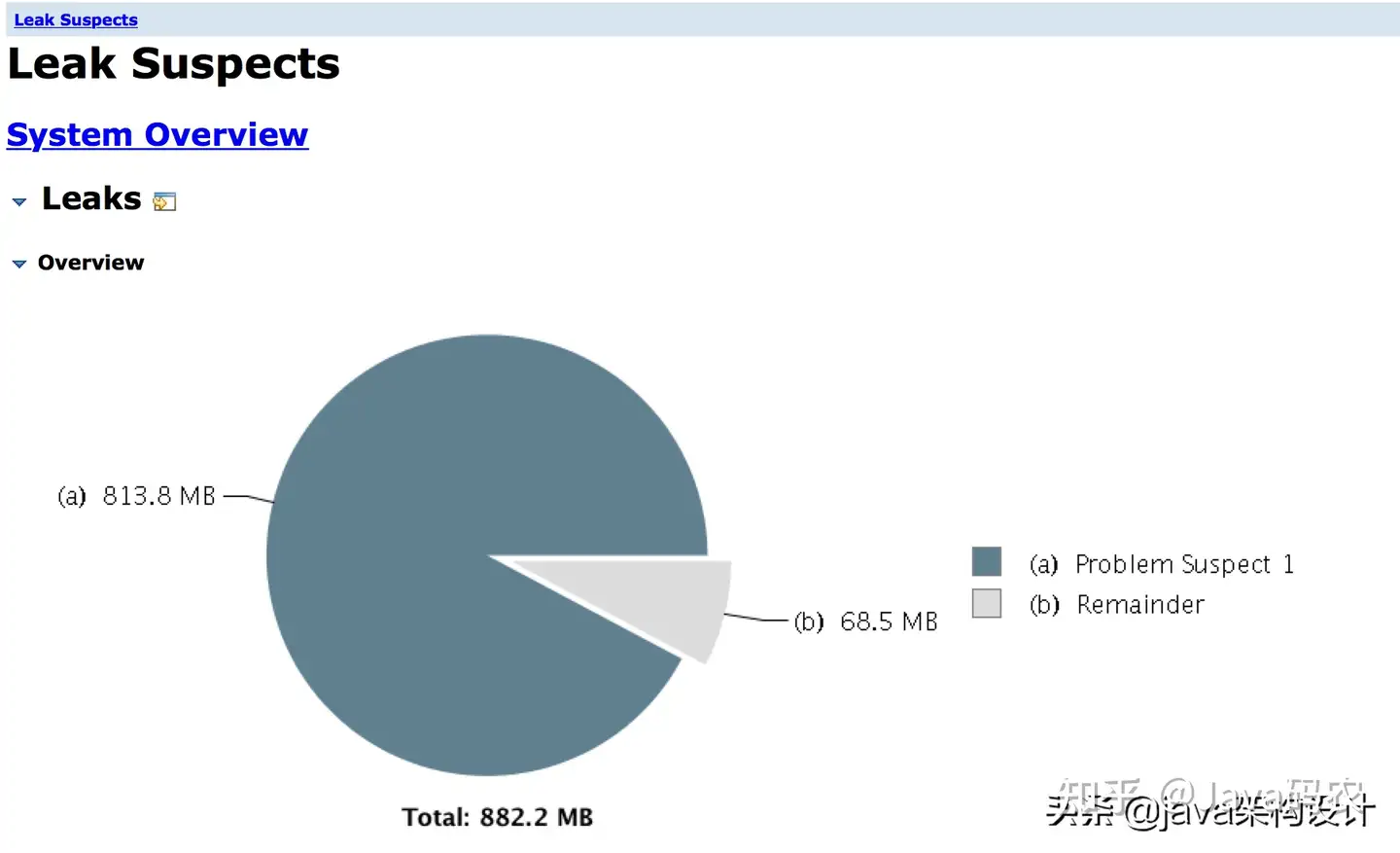
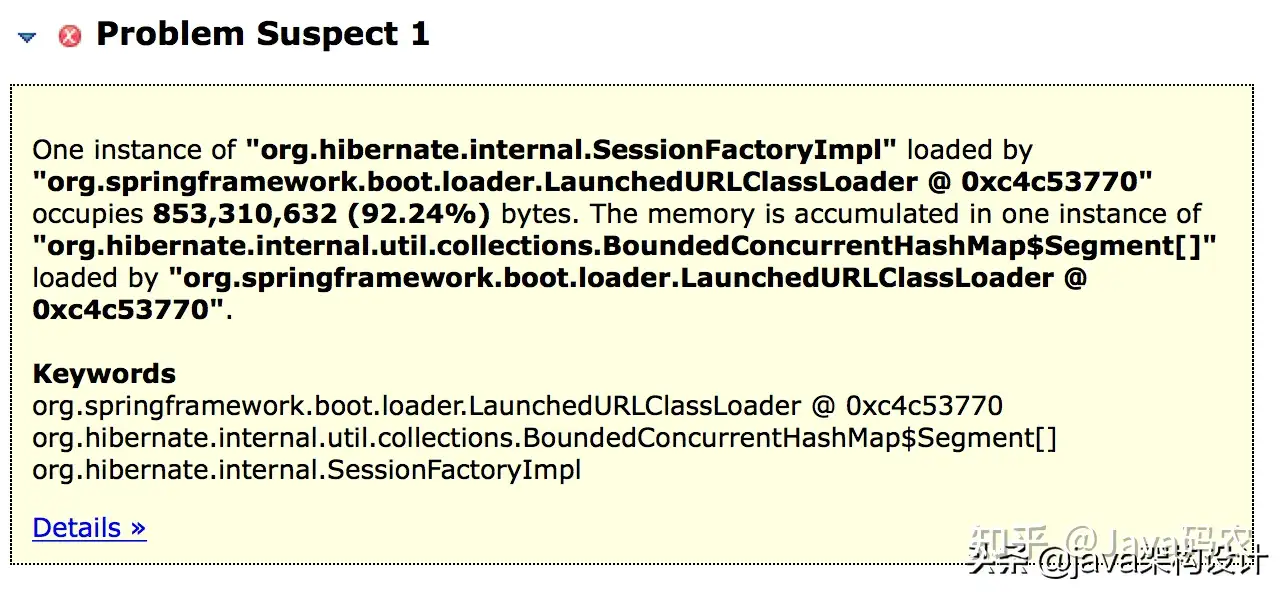
可以看到
org.hibernate.internal.SessionFactoryImpl这个实例占用了853,310,632 (92.24%) 字节,共813.3MB!目前可以知道的是在Hibernate数据查询这块有问题,具体点击Details继续跟进去找问题代码:]
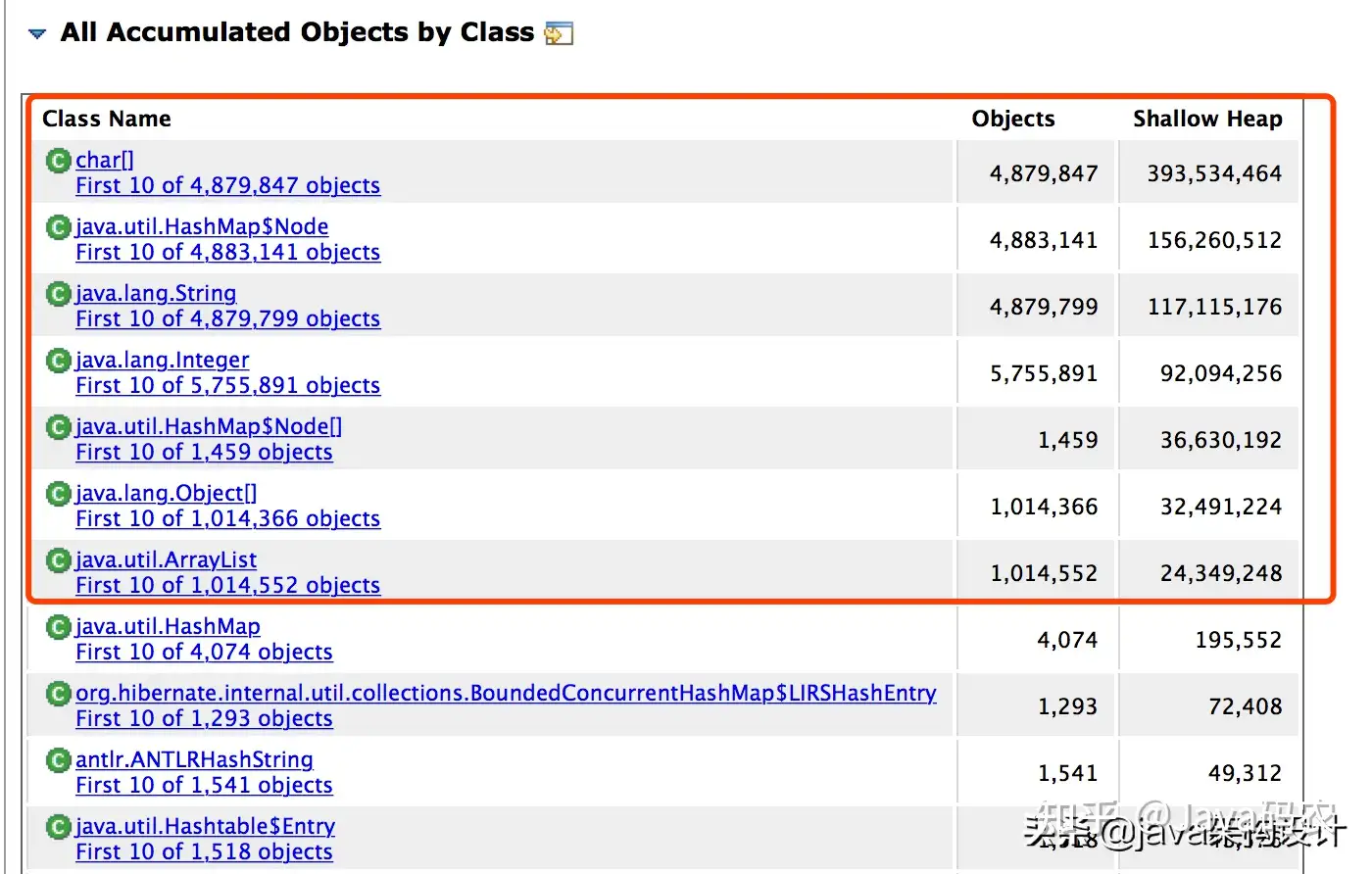
图中可以看到有问题的对象好几个,占用的内存也比较大。再来看下面一张图:

Accumulated Objects by Class in Dominator Tree是支配树中按类累积对象,可以看到BoundedConcurrentHashMap只有32个对象示例,其对象树却占据了853241512字节的堆大小。我们点击进去看看这个HashMap里面都存储了什么数据:
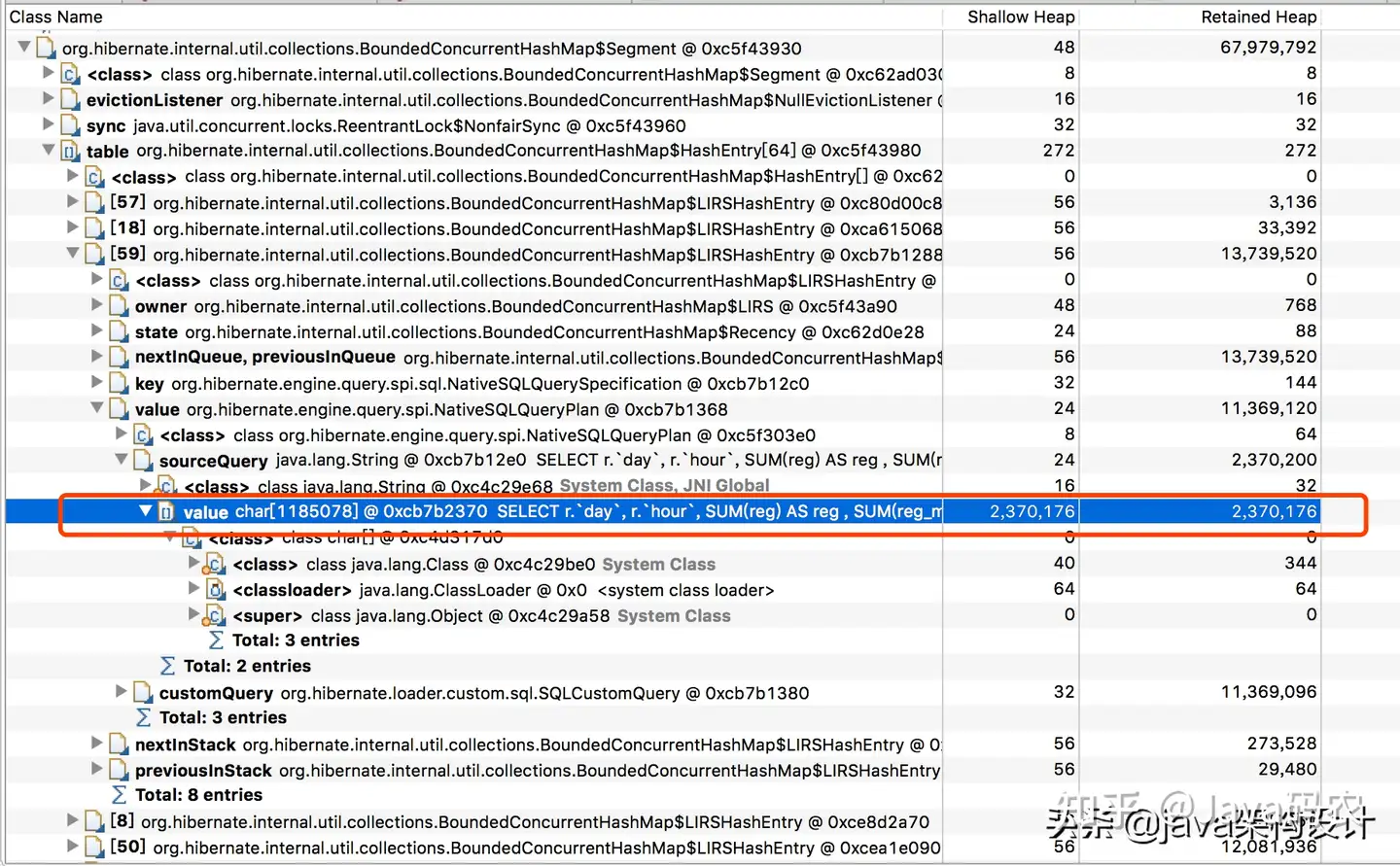
把这个value拷贝出来,是我们业务的sql,看到这个sql我就惊讶了,这个sql传了91976个参数!
至此,我们便找出了造成Java进程假死的代码在这个SQL上。
毋庸置疑,这个SQL存在两个大问题:
- SQL本身是慢SQL,不能迅速查出来;
- SQL本身查出来的数据需要分配更多的内存。
内存不足,需要回收对象,但是查询SQL有需要更多的对象空间来存储。因此这边一直在GC,但是有回收不出来有效的空间,那就需要继续GC。所以进程一直在FULL GC,导致一直stop the world。
以上就是本次线上生产环境关于Java进程假死的问题排查分析的步骤。
大家在遇到这种问题的时候,建议大家在不影响业务正常服务的情况下,保存好现场,把握住机会,然后迅速的找到本篇文章,按照上述排查步骤快速排查出问题代码。
大家自己也可以写一段有内存泄漏问题的程序,然后参考本文练习排查,提高自己排查问题的熟练度。避免临阵磨枪,不慢也慌。
当然,线上问题排查也是一名高级工程师应该具备的能力之一。想进入一线互联网公司,BAT大厂,这些技能必知必会!


