Clickhouse 分布式表&本地表
CK 分布式表和本地表
ck的表分为两种:
-
分布式表
一个逻辑上的表, 可以理解为数据库中的视图, 一般查询都查询分布式表. 分布式表引擎会将我们的查询请求路由本地表进行查询, 然后进行汇总最终返回给用户.
-
本地表:
实际存储数据的表
1. 不写分布式表的原因
- 分布式表接收到数据后会将数据拆分成多个parts, 并转发数据到其它服务器, 会引起服务器间网络流量增加、服务器merge的工作量增加, 导致写入速度变慢, 并且增加了Too many parts的可能性.
- 数据的一致性问题, 先在分布式表所在的机器进行落盘, 然后异步的发送到本地表所在机器进行存储,中间没有一致性的校验, 而且在分布式表所在机器时如果机器出现down机, 会存在数据丢失风险.
- 数据写入默认是异步的,短时间内可能造成不一致.
- 对zookeeper的压力比较大(待验证). 没经过正式测试, 只是看到了有人提出.
2. Replication & Sharding
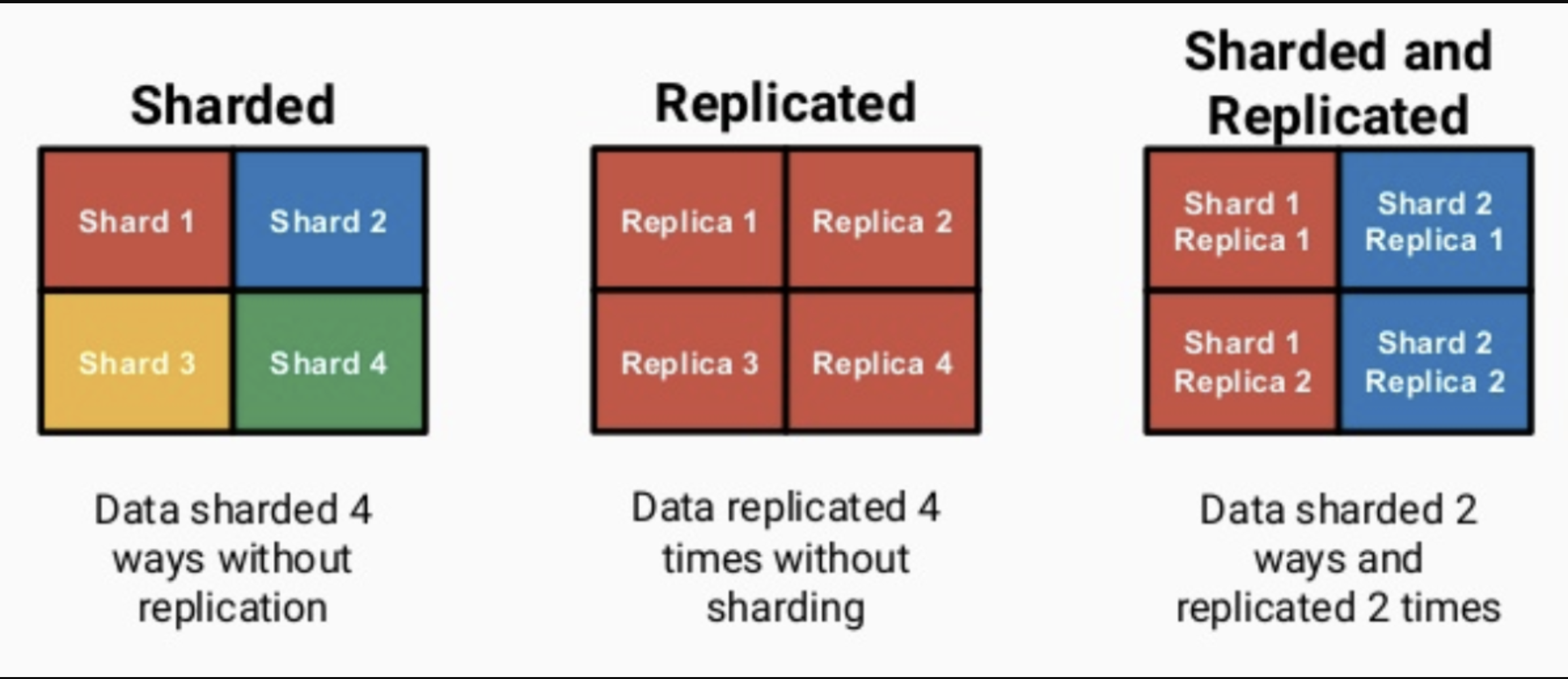
ClickHouse依靠ReplicatedMergeTree引擎族与ZooKeeper实现了复制表机制, 成为其高可用的基础.
ClickHouse像ElasticSearch一样具有数据分片(shard)的概念, 这也是分布式存储的特点之一, 即通过并行读写提高效率. ClickHouse依靠Distributed引擎实现了分布式表机制, 在所有分片(本地表)上建立视图进行分布式查询.
3. Replicated Table & ReplicatedMergeTree Engines
不同于HDFS的副本机制(基于集群实现), Clickhouse的副本机制是基于表实现的. 用户在创建每张表的时候, 可以决定该表是否高可用.
Local_table
CREATE TABLE IF NOT EXISTS {local_table} ({columns})
ENGINE = ReplicatedMergeTree('/clickhouse/tables/#_tenant_id_#/#__appname__#/#_at_date_#/{shard}/hits', '{replica}')
partition by toString(_at_date_) sample by intHash64(toInt64(toDateTime(_at_timestamp_)))
order by (_at_date_, _at_timestamp_, intHash64(toInt64(toDateTime(_at_timestamp_))))
支持复制表的引擎都是ReplicatedMergeTree引擎族, 具体可以查看官网:
ReplicatedMergeTree引擎族接收两个参数:
- ZK中该表相关数据的存储路径, ClickHouse官方建议规范化, 例如:
/clickhouse/tables/{shard}/[database_name]/[table_name]. - 副本名称, 一般用
{replica}即可.
ReplicatedMergeTree引擎族非常依赖于zookeeper, 它在zookeeper中存储了大量的数据:
表结构信息、元数据、操作日志、副本状态、数据块校验值、数据part merge过程中的选主信息...
同时, zookeeper又在复制表急之下扮演了三种角色:
元数据存储、日志框架、分布式协调服务
可以说当使用了ReplicatedMergeTree时, zookeeper压力特别重, 一定要保证zookeeper集群的高可用和资源.
3.1. 数据同步的流程
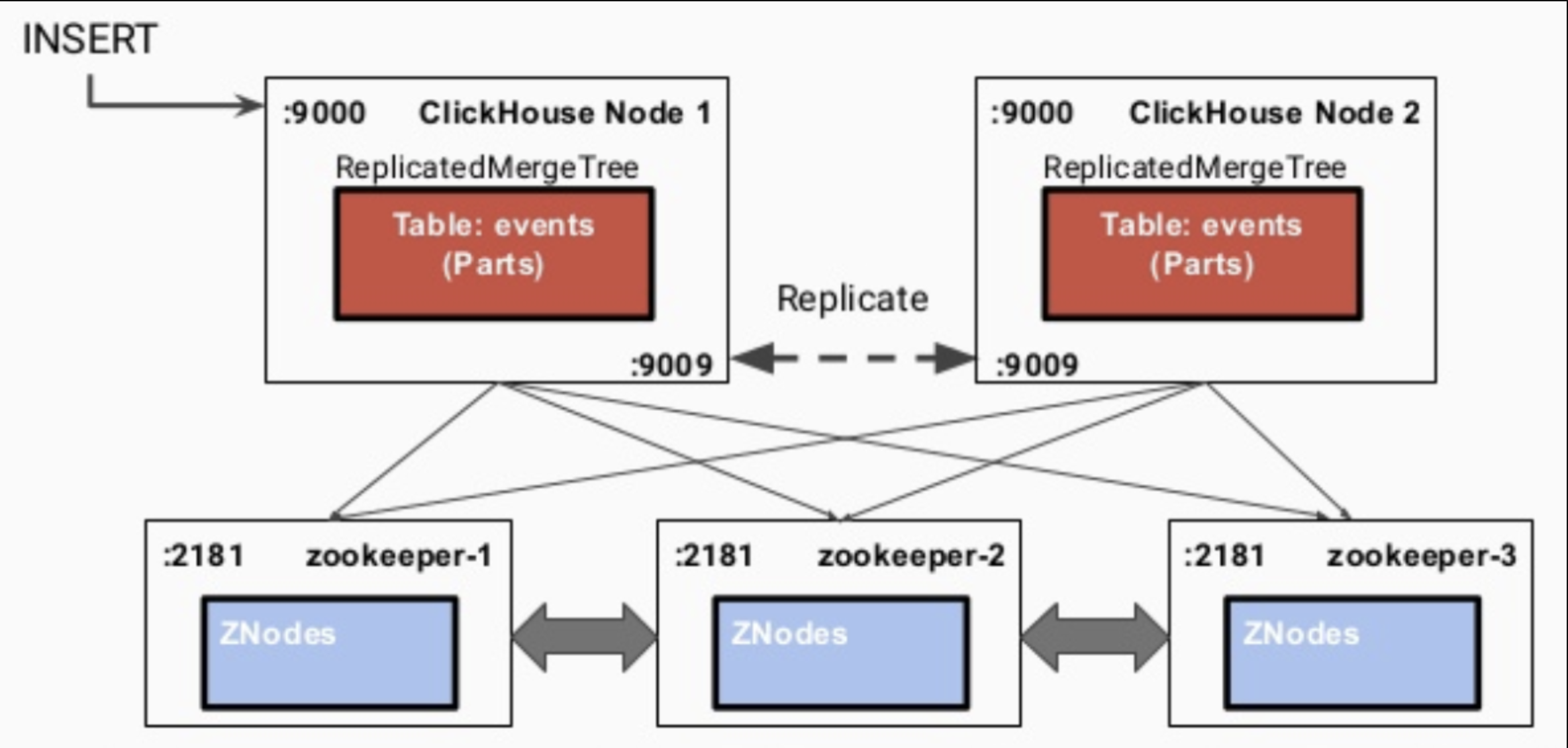
- 写入到一个节点
- 通过
interserver HTTP port端口同步到其他实例上 - 更新zookeeper集群记录的信息
3.2. 重度依赖Zookeeper导致的问题
ck的replicatedMergeTree引擎方案有太多的信息存储在zk上, 当数据量增大, ck节点数增多, 会导致服务非常不稳定, 目前我们的ck集群规模还小, 这个问题还不严重, 但依旧会出现很多和zk有关的问题(详见遇到的问题).
实际上 ClickHouse 把 ZK 当成了三种服务的结合, 而不仅把它当作一个 Coordinate service(协调服务), 可能这也是大家使用 ZK 的常用用法。ClickHouse 还会把它当作 Log Service(日志服务),很多行为日志等数字的信息也会存在 ZK 上;还会作为表的 catalog service(元数据存储),像表的一些 schema 信息也会在 ZK 上做校验,这就会导致 ZK 上接入的数量与数据总量会成线性关系。
目前针对这个问题, clickhouse社区提出了一个mini checksum方案, 但是这并没有彻底解决 znode 与数据量成线性关系的问题. 目前看到比较好的方案是字节的:
我们就基于 MergeTree 存储引擎开发了一套自己的高可用方案。我们的想法很简单,就是把更多 ZK 上的信息卸载下来,ZK 只作为 coordinate Service。只让它做三件简单的事情:行为日志的 Sequence Number 分配、Block ID 的分配和数据的元信息,这样就能保证数据和行为在全局内是唯一的。
关于节点,它维护自身的数据信息和行为日志信息,Log 和数据的信息在一个 shard 内部的副本之间,通过 Gossip 协议进行交互。我们保留了原生的 multi-master 写入特性,这样多个副本都是可以写的,好处就是能够简化数据导入。图 6 是一个简单的框架图。
以这个图为例,如果往 Replica 1 上写,它会从 ZK 上获得一个 ID,就是 Log ID,然后把这些行为和 Log Push 到集群内部 shard 内部活着的副本上去,然后当其他副本收到这些信息之后,它会主动去 Pull 数据,实现数据的最终一致性。我们现在所有集群加起来 znode 数不超过三百万,服务的高可用基本上得到了保障,压力也不会随着数据增加而增加。
4. Distributed Table & Distributed Engine
ClickHouse分布式表的本质并不是一张表, 而是一些本地物理表(分片)的分布式视图,本身并不存储数据. 分布式表建表的引擎为Distributed.
Distrbuted_table
CREATE TABLE IF NOT EXISTS {distributed_table} as {local_table}
ENGINE = Distributed({cluster}, '{local_database}', '{local_table}', rand())
Distributed引擎需要以下几个参数:
- 集群标识符
- 本地表所在的数据库名称
- 本地表名称
- 分片键(sharding key) - 可选
该键与config.xml中配置的分片权重(weight)一同决定写入分布式表时的路由, 即数据最终落到哪个物理表上. 它可以是表中一列的原始数据(如site_id), 也可以是函数调用的结果, 如上面的SQL语句采用了随机值rand(). 注意该键要尽量保证数据均匀分布, 另外一个常用的操作是采用区分度较高的列的哈希值, 如intHash64(user_id).
4.1. 数据查询的流程
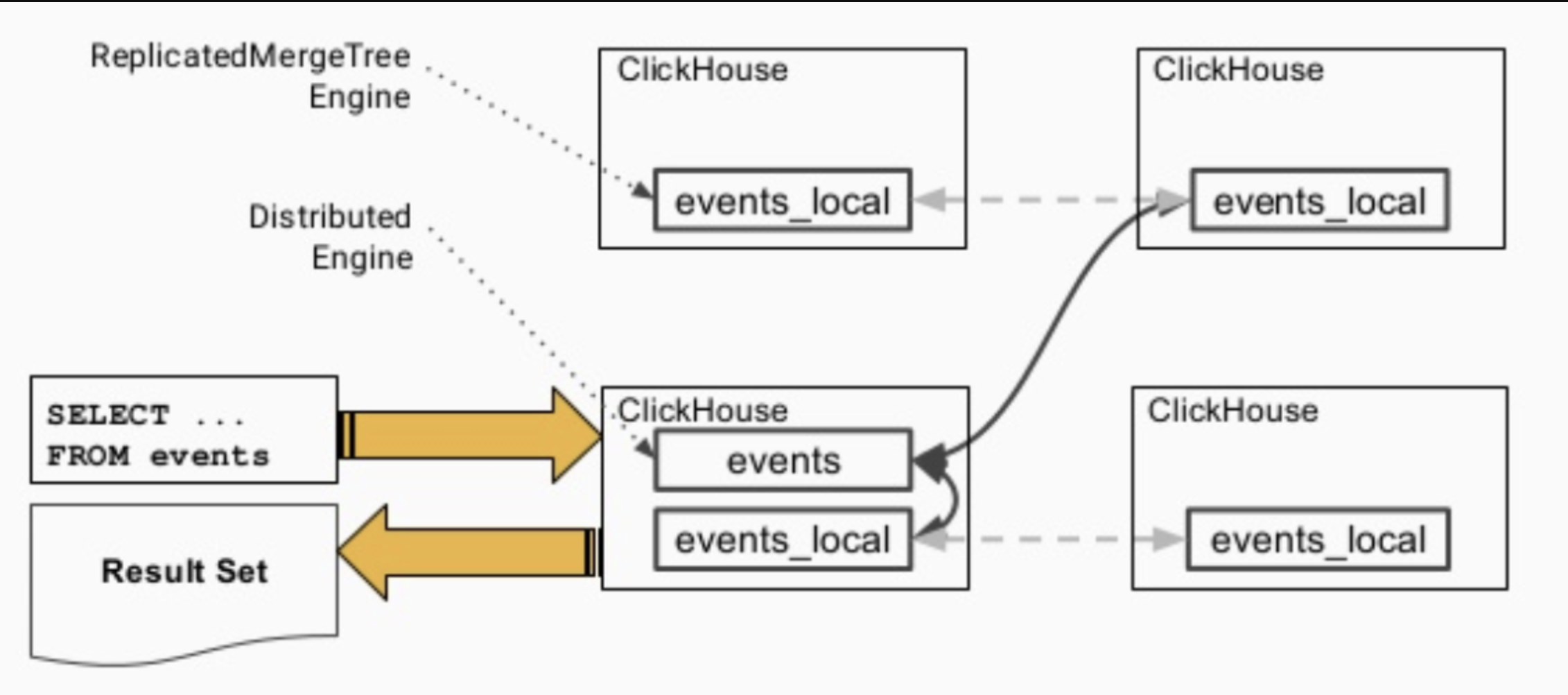
- 各个实例之间会交换自己持有的分片的表数据
- 汇总到同一个实例上返回给用户

