
收包
整体流程图
-
网卡收到数据包,DMA 方式写入Ring Buffer,发出硬中断;
-
内核收到硬中断,NAPI 加入本 CPU 的轮询列表,发出软中断;
-
内核收到软中断,轮询 NAPI 并执行poll函数从Ring Buffer取数据;
-
GRO 操作(默认开启),合并多个数据包为一个数据包,如果 RPS 关闭,则把数据包递交到协议栈;
-
RPS 操作(默认关闭),如果开启,使数据包通过别的(也可能是当前的) CPU 递交到协议栈;
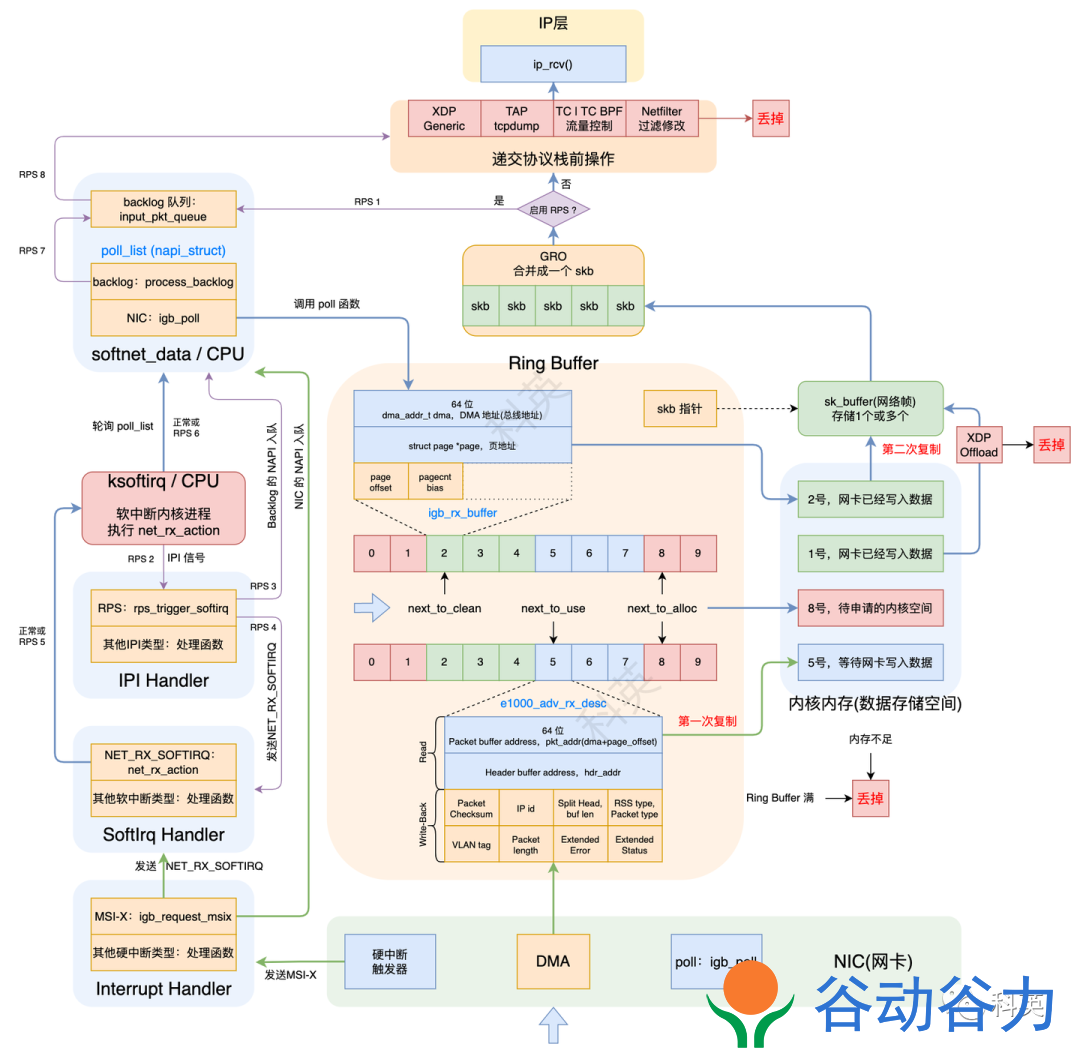
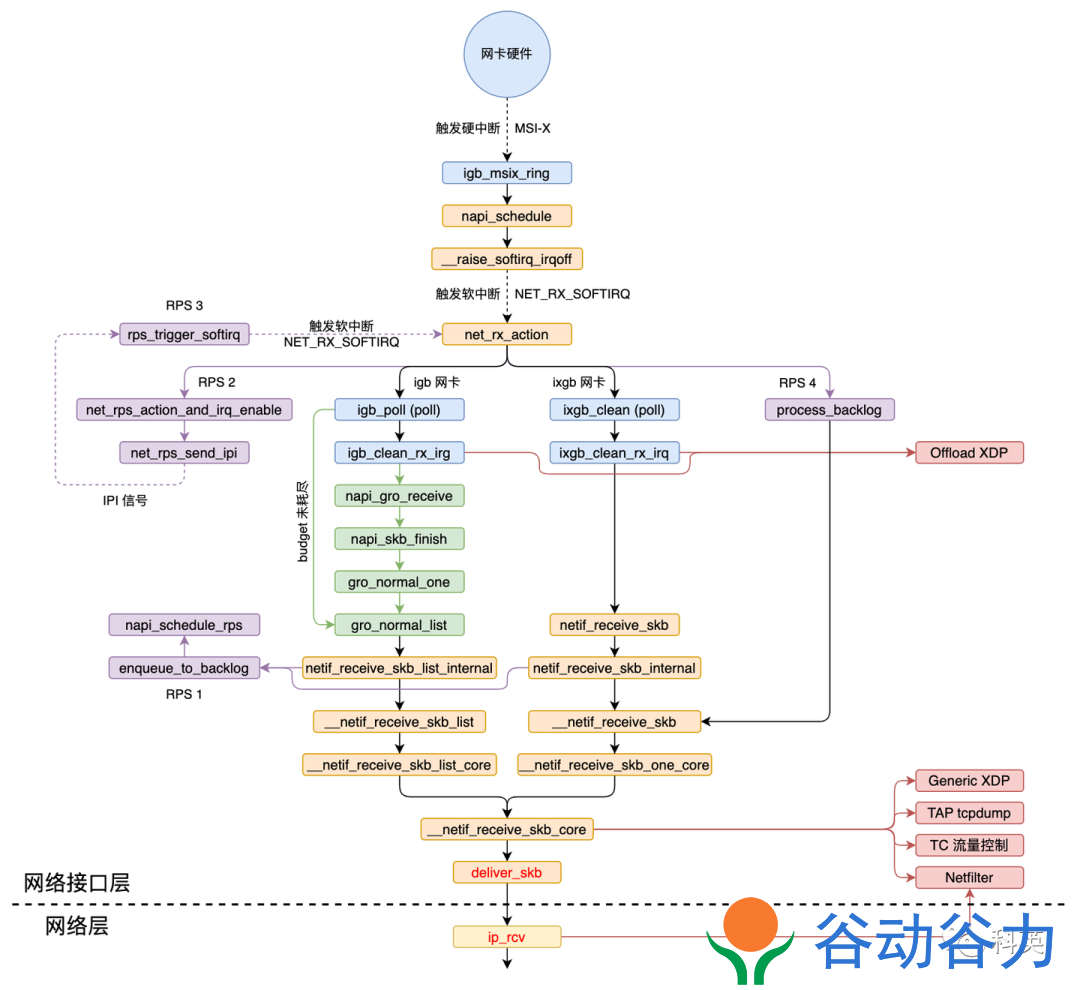
图5 L1调用链
struct igb_rx_buffer {
/* DMA 地址 */
dma_addr_t dma;
/* 物理页,与 dma 指向同一个内存区域 */
struct page *page;
#if (BITS_PER_LONG > 32) || (PAGE_SIZE >= 65536)
__u32 page_offset;
#else
__u16 page_offset;
#endif
__u16 pagecnt_bias;
};
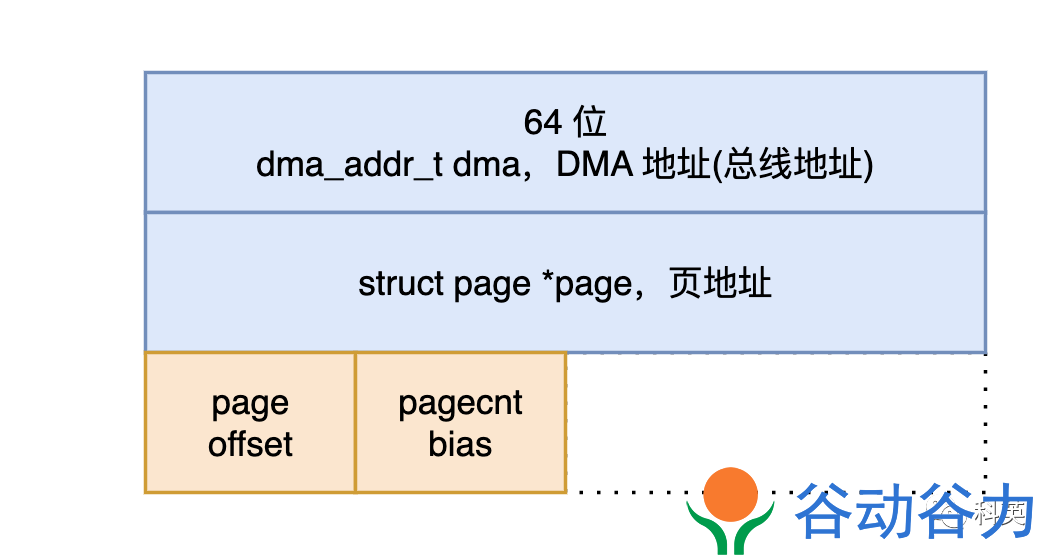
图6
union e1000_adv_rx_desc {
struct {
__le64 pkt_addr; /* Packet buffer address */
__le64 hdr_addr; /* Header buffer address */
} read;
struct {
struct {
struct {
__le16 pkt_info; /* RSS type, Packet type */
__le16 hdr_info; /* Split Head, buf len */
} lo_dword;
union {
__le32 rss; /* RSS Hash */
struct {
__le16 ip_id; /* IP id */
__le16 csum; /* Packet Checksum */
} csum_ip;
} hi_dword;
} lower;
struct {
__le32 status_error; /* ext status/error */
__le16 length; /* Packet length */
__le16 vlan; /* VLAN tag */
} upper;
} wb; /* writeback */
};
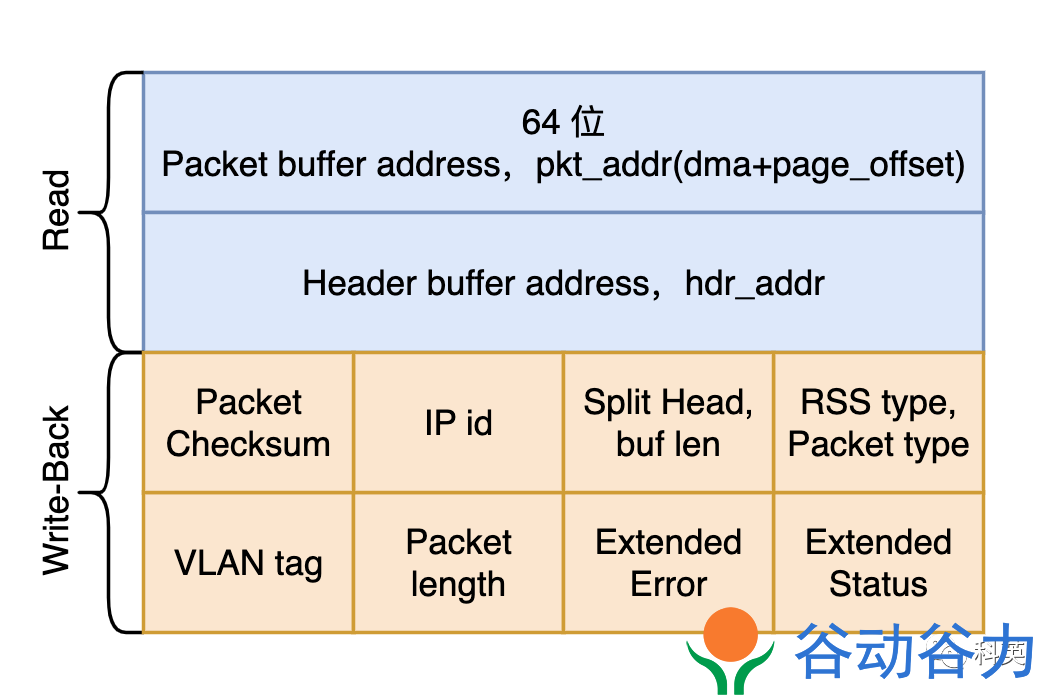
图7
static irqreturn_t igb_msix_ring(int irq, void *data)
{
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
-
把napi_struct结构体的poll_list添加到当前 CPU 所关联的softnet_data结构体的poll_list链表尾部;
-
然后调用 __raise_softirq_irqoff 函数触发NET_RX_SOFTIRQ软中断,从而内核执行网络子系统初始化时注册的 net_rx_action 软中断处理函数。
// 部分代码
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies + usecs_to_jiffies(READ_ONCE(netdev_budget_usecs));
int budget = READ_ONCE(netdev_budget);
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
skb_defer_free_flush(sd);
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto end;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
/* 通过 smp_call_function_single_async 远程激活 sd->rps_ipi_list 中的其他 CPU 的软中断,
* 使其他 CPU 执行初始化时注册的软中断函数 csd = rps_trigger_softirq 来处理数据包 */
net_rps_action_and_irq_enable(sd);
end:;
}
// 部分代码
static int __napi_poll(struct napi_struct *n, bool *repoll)
{
int work, weight;
weight = n->weight;
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n, work, weight);
}
if (likely(work < weight))
return work;
if (unlikely(napi_disable_pending(n))) {
napi_complete(n);
return work;
}
*repoll = true;
return work;
}
// 部分代码
static int igb_poll(struct napi_struct *napi, int budget)
{
struct igb_q_vector *q_vector = container_of(napi, struct igb_q_vector, napi);
bool clean_complete = true;
int work_done = 0;
#ifdef CONFIG_IGB_DCA
if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED)
igb_update_dca(q_vector);
#endif
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector, budget);
if (q_vector->rx.ring) {
int cleaned = igb_clean_rx_irq(q_vector, budget);
work_done += cleaned;
if (cleaned >= budget)
clean_complete = false;
}
/* If all work not completed, return budget and keep polling */
if (!clean_complete)
return budget;
/* Exit the polling mode, but don't re-enable interrupts if stack might
* poll us due to busy-polling
*/
if (likely(napi_complete_done(napi, work_done)))
igb_ring_irq_enable(q_vector);
return work_done;
}
-
如果内核支持 DCA(Direct Cache Access),CPU 缓存命中率将会提升;
-
调用 igb_clean_rx_irq 循环处理数据包,直到处理完毕或者budget耗尽,下面详细解读;
-
检查clean_complete判断是否所有的工作已经完成;
-
如果不是,返回剩下的budget值;
-
否则调用 napi_complete_done 函数继续处理。
-
调用 gro_normal_list 函数,因为数据包处理完了,及时把 igb_clean_rx_irq 处理完的多个包一次性送到协议栈;
-
然后检查 NAPI 的poll_list是否都处理完,如果是则关闭 NAPI,并通过 igb_ring_irq_enable 重新打开硬中断,以保证下次中断会重新打开 NAPI。
//部分代码
static int igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{
struct igb_adapter *adapter = q_vector->adapter;
struct igb_ring *rx_ring = q_vector->rx.ring;
struct sk_buff *skb = rx_ring->skb;
unsigned int total_bytes = 0, total_packets = 0;
u16 cleaned_count = igb_desc_unused(rx_ring);
int rx_buf_pgcnt;
while (likely(total_packets < budget)) {
union e1000_adv_rx_desc *rx_desc;
struct igb_rx_buffer *rx_buffer;
ktime_t timestamp = 0;
unsigned int size;
/* return some buffers to hardware, one at a time is too slow */
if (cleaned_count >= IGB_RX_BUFFER_WRITE) {
/* 1 */
igb_alloc_rx_buffers(rx_ring, cleaned_count);
cleaned_count = 0;
}
/* 2 */
rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean);
size = le16_to_cpu(rx_desc->wb.upper.length);
/* 3 */
rx_buffer = igb_get_rx_buffer(rx_ring, size, &rx_buf_pgcnt);
/* 4 retrieve a buffer from the ring */
if (!skb) {
unsigned char *hard_start = pktbuf - igb_rx_offset(rx_ring);
unsigned int offset = pkt_offset + igb_rx_offset(rx_ring);
xdp_prepare_buff(&xdp, hard_start, offset, size, true);
xdp_buff_clear_frags_flag(&xdp);
#if (PAGE_SIZE > 4096)
/* At larger PAGE_SIZE, frame_sz depend on len size */
xdp.frame_sz = igb_rx_frame_truesize(rx_ring, size);
#endif
skb = igb_run_xdp(adapter, rx_ring, &xdp);
}
/* 5 retrieve a buffer from the ring */
if (skb)
igb_add_rx_frag(rx_ring, rx_buffer, skb, size);
else if (ring_uses_build_skb(rx_ring))
skb = igb_build_skb(rx_ring, rx_buffer, &xdp, timestamp);
else
skb = igb_construct_skb(rx_ring, rx_buffer, &xdp, timestamp);
/* 6 */
igb_put_rx_buffer(rx_ring, rx_buffer, rx_buf_pgcnt);
cleaned_count++;
/* 7 fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
/* 8 verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* 9 probably a little skewed due to removing CRC */
total_bytes += skb->len;
/* 10 populate checksum, timestamp, VLAN, and protocol */
igb_process_skb_fields(rx_ring, rx_desc, skb);
/* 11 GRO,合并数据包 */
napi_gro_receive(&q_vector->napi, skb);
/* reset skb pointer */
skb = NULL;
/* 12 update budget accounting */
total_packets++;
}
/* place incomplete frames back on ring for completion */
rx_ring->skb = skb;
if (cleaned_count)
igb_alloc_rx_buffers(rx_ring, cleaned_count);
return total_packets;
}
-
首先申请一批 rx_buffer 和 rx_desc,通常 IGB_RX_BUFFER_WRITE(16)个,避免一个个申请,效率低,操作由 igb_alloc_rx_buffers 函数完成:使用 dev_alloc_pages 申请新的物理页保存到 rx_buffer->page,然后通过 dma_map_page_attrs 将 page 映射结果保存到 rx_buffer->dma ;修改 rx_desc->read.pkt_addr(rx_buffer->dma + rx_buffer->page_offset),rx_desc->wb.upper.length = 0,方便网卡将收到的数据包 DMA 到 rx_desc->read.pkt_addr 地址,这是第一次复制,从网卡到 Ring Buffer 的复制;
-
从 Ring Buffer 中取出下一个可读位置(next_to_clean)的 rx_desc,检查它状态是否正常,然后从 rx_desc 获取接收的数据 buffer 大小(wb.upper.length);
-
通过 igb_get_rx_buffer 函数将下一个可读位置(next_to_clean)的 rx_buffer 获取到;
-
计算数据包开始地址,page_address(rx_buffer->page) + rx_buffer->page_offset,转换成 xdp_buff 地址,然后交给 BPF 的 xdp 处理;
-
内核把 rx_buffer 的 page(物理页)对应的 buffer 数据拷贝到 Ring Buffer 的 skb(sk_buff)中,然后把 skb 直接传给协议栈,这是第二次复制,从 Ring Buffer 到网络协议栈的复制。为了减少复制次数,skb 直到上层处理完以后才会被 __kfree_skb 释放;
-
通过 igb_put_rx_buffer 函数将 rx_buffer->page=NULL,如果可以重用,将 page、dma 等数据移动到rx_ring->next_to_alloc 位置的 rx_buffer;反之,解除 DMA 映射,回收内存;
-
通过 igb_is_non_eop 函数检查 rx_desc 是不是包含 eop(End of Packet),如果包含,说明 skb 中已经收录一个完整的网络包(帧);反之,需要获取下一个 rx_buffer 里的数据继续复制到 skb 中直到 rx_desc 包含 eop;也就是说一个网络包(存储在 skb 中)可能包含 1 个或多个 rx_buffer 中的 buffer 数据,也可以说 1 个 skb 对应 1 个或多个 Ring Buffer 队列里连续的元素;
-
通过 igb_cleanup_headers 检查网络包(skb)的头部等信息是否正确;
-
把 skb 的长度累计到 total_bytes,用于统计数据;
-
调用 igb_process_skb_fields 设置skb 的 checksum、timestamp、VLAN 和 protocol 等信息,这些信息由硬件提供;
-
将构建好的 skb 通过 napi_gro_receive 函数上交到网络协议栈,具体细节移步 2.4 章节;
-
累加处理数据包个数 total_packets,用于消耗 budget;
-
如果没数据或者 budget 耗尽就退出循环,否则回到 1;
$ sysctl -w net.core.netdev_budget=500
$ ethtool -k eth0 | grep generic-receive-offload
generic-receive-offload: on
$ ethtool -K eth0 gro on
// 部分代码
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb, 0);
ret = napi_skb_finish(napi, skb, dev_gro_receive(napi, skb));
trace_napi_gro_receive_exit(ret);
return ret;
}
-
调用 dev_gro_receive 函数具体完成多个数据包的合并,即把skb加入到 NAPI 中,这个操作调用链很长,根据包类型 TCP/UDP 分别判断数据包的完整性和判断需不需要合并;
-
把上步的返回结果传入 napi_skb_finish 函数继续处理。
static gro_result_t napi_skb_finish(struct napi_struct *napi, struct sk_buff *skb, gro_result_t ret) {
switch (ret) {
case GRO_NORMAL:
gro_normal_one(napi, skb, 1);
break;
case GRO_MERGED_FREE:
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
napi_skb_free_stolen_head(skb);
else if (skb->fclone != SKB_FCLONE_UNAVAILABLE)
__kfree_skb(skb);
else
__kfree_skb_defer(skb);
break;
case GRO_HELD:
case GRO_MERGED:
case GRO_CONSUMED:
break;
}
return ret;
}
-
如果是 ret 是 GRO_MERGED_FREE,说明 skb 已经被合并,释放 skb;
-
如果是 ret 是 GRO_NORMAL,会调用 gro_normal_one,它会更新当前 napi->rx_count 计数, 当数量足够多时,将调用 gro_normal_list 函数,将多个包一次性送到协议栈。
static inline void gro_normal_one(struct napi_struct *napi, struct sk_buff *skb, int segs) {
list_add_tail(&skb->list, &napi->rx_list);
napi->rx_count += segs;
if (napi->rx_count >= READ_ONCE(gro_normal_batch))
gro_normal_list(napi);
}
$ sysctl net.core.gro_normal_batch
net.core.gro_normal_batch = 8
/* Pass the currently batched GRO_NORMAL SKBs up to the stack. */
static inline void gro_normal_list(struct napi_struct *napi)
{
if (!napi->rx_count) // 没有包直接返回
return;
netif_receive_skb_list_internal(&napi->rx_list);
INIT_LIST_HEAD(&napi->rx_list); // 初始化 napi->rx_list
napi->rx_count = 0; // 计数清零
}
// 部分代码
bool napi_complete_done(struct napi_struct *n, int work_done)
{
unsigned long flags, val, new, timeout = 0;
bool ret = true;
if (unlikely(n->state & (NAPIF_STATE_NPSVC | NAPIF_STATE_IN_BUSY_POLL)))
return false;
if (work_done) {
if (n->gro_bitmask)
timeout = READ_ONCE(n->dev->gro_flush_timeout);
n->defer_hard_irqs_count = READ_ONCE(n->dev->napi_defer_hard_irqs);
}
if (n->defer_hard_irqs_count > 0) {
n->defer_hard_irqs_count--;
timeout = READ_ONCE(n->dev->gro_flush_timeout);
if (timeout)
ret = false;
}
if (n->gro_bitmask) {
napi_gro_flush(n, !!timeout);
}
gro_normal_list(n);
...
}
-
因为是软件实现的,所以任何网卡都可以使用 RPS,单队列和多队列网卡都可以使用;
-
RPS 在数据包从 Ring Buffer 中取出来后开始工作,将 Packet hash 到对应 CPU 的 backlog 中,并触发 IPI(Inter-processorInterrupt,进程间中断)告知目标 CPU 来处理 backlog。该 Packet 将被目标 CPU 交到协议栈。从而实现将负载分散到多个 CPU 的目的;
-
单队列网卡使用 RPS 可以提升传输效率,多队列网卡在硬中断不均匀时同样可以使用来提升效率;
IPI 既像软件中断又像硬件中断,它的产生像软件中断,是在程序中用代码发送的,而它的处理像硬件中断
void netif_receive_skb_list_internal(struct list_head *head)
{
#ifdef CONFIG_RPS
if (static_branch_unlikely(&rps_needed)) {
list_for_each_entry_safe(skb, next, head, list) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
/* 目标 CPU 的 id */
int cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
/* Will be handled, remove from list */
skb_list_del_init(skb);
enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
}
}
}
#endif
}
-
如果没有配置 RPS,netif_receive_skb* 将数据包交到网络协议栈;
-
如果配置了 RPS,netif_receive_skb* 调用 get_rps_cpu 来计算网络包的 hash 并决定压入哪个 CPU 的 backlog,具体压入操作由 enqueue_to_backlog 函数完成。
// 部分代码
static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) {
enum skb_drop_reason reason;
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
reason = SKB_DROP_REASON_NOT_SPECIFIED;
sd = &per_cpu(softnet_data, cpu);
rps_lock_irqsave(sd, &flags);
if (!netif_running(skb->dev))
goto drop;
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= READ_ONCE(netdev_max_backlog) && !skb_flow_limit(skb, qlen)) {
if (qlen) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock_irq_restore(sd, &flags);
return NET_RX_SUCCESS;
}
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state))
// 将目标 CPU 的 sd 挂到当前 CPU 的 sd 的 rps_ipi_list 便于后续向目标 CPU 发送 IPI 信号。
napi_schedule_rps(sd);
goto enqueue;
}
reason = SKB_DROP_REASON_CPU_BACKLOG;
drop:
sd->dropped++;
rps_unlock_irq_restore(sd, &flags);
dev_core_stats_rx_dropped_inc(skb->dev);
kfree_skb_reason(skb, reason);
return NET_RX_DROP;
}
-
当目标 CPU 的sd(softnet_data )中input_pkt_queue队列长度同时不超过netdev_max_backlog和flow limit的值,将skb数据包压入input_pkt_queue,否则将会被丢弃。
-
调用 napi_schedule_rps,将目标 CPU 的sd挂到本 CPU 的sd的rps_ipi_list便于后续向目标 CPU 发送 IPI 信号;
-
当返回到 net_rx_action 函数中,最后一步经过调用链 net_rps_action_and_irq_enable -> net_rps_send_ipi -> smp_call_function_single_async 远程激活sd->rps_ipi_list中的其他 CPU 的软中断,使其他 CPU 执行初始化时注册的软中断函数 csd = rps_trigger_softirq 来处理数据包;
-
rps_trigger_softirq 函数将 backlog(napi)加入 poll_list 里,然后发出软中断信号 NET_RX_SOFTIRQ;
-
当处理软中断函数 net_rx_action 处理poll_list时,backlog 的 poll 是 process_backlog 函数,process_backlog 函数消费 CPU 的input_pkt_queue队列数据包,经过 __netif_receive_skb 函数多层调用,最终也调用 __netif_receive_skb_core 函数把数据包递交网络协议栈。

图8
static int softnet_seq_show(struct seq_file *seq, void *v)
{
struct softnet_data *sd = v;
unsigned int flow_limit_count = 0;
#ifdef CONFIG_NET_FLOW_LIMIT
struct sd_flow_limit *fl;
rcu_read_lock();
fl = rcu_dereference(sd->flow_limit);
if (fl)
flow_limit_count = fl->count;
rcu_read_unlock();
#endif
seq_printf(seq, "%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0, 0, 0, 0,
0, /* was fastroute */
0, /* was cpu_collision */
sd->received_rps, flow_limit_count, softnet_backlog_len(sd),
(int)seq->index);
return 0;
}
-
准备工作;
-
XDP 处理;
-
VLAN 标记;
-
TAP 处理;
-
TC 处理;
-
Netfilter 处理;
-
递交协议栈。
有的网卡会在 poll 函数里调用 netif_receive_skb 将数据包交到上层网络栈继续处理。最后发现同样会调用到 __netif_receive_skb_core 函数。
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc, struct packet_type **ppt_prev)
{
struct packet_type *ptype, *pt_prev;
rx_handler_func_t *rx_handler;
struct sk_buff *skb = *pskb;
struct net_device *orig_dev;
bool deliver_exact = false;
int ret = NET_RX_DROP;
__be16 type;
// 检查网络包的时间戳。
net_timestamp_check(!READ_ONCE(netdev_tstamp_prequeue), skb);
// 跟踪网络数据包的接收过程,用于调试和性能分析。
trace_netif_receive_skb(skb);
// 将接收到的数据包的网络设备指针保存到 orig_dev 变量中,以备后续使用。
orig_dev = skb->dev;
// 重置网络头部的偏移量,使其指向正确的位置。
skb_reset_network_header(skb);
if (!skb_transport_header_was_set(skb))
//如果传输头部未设置,则重置传输层头部的偏移量,使其指向正确的位置。
skb_reset_transport_header(skb);
// 重置数据包的 MAC 长度。
skb_reset_mac_len(skb);
// 将 pt_prev 变量初始化为空,用于存储上一个处理函数。
pt_prev = NULL;
another_round: //这是一个标签,用于在处理过程中跳转到此处重新执行一轮处理。
// 设置数据包的 skb_iif 字段,表示skb 是从哪个网络设备接收的。
skb->skb_iif = skb->dev->ifindex;
// 增加当前 CPU 上的 softnet_data.processed 字段的计数。
__this_cpu_inc(softnet_data.processed);
// 如果启用了 Generic XDP(软件实现 XDP 功能),则调用do_xdp_generic()函数执行 XDP 通用程序的处理。
if (static_branch_unlikely(&generic_xdp_needed_key)) {
int ret2;
migrate_disable();
ret2 = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
migrate_enable();
// 如果返回结果不是XDP_PASS,则将返回值设置为NET_RX_DROP并跳转到标签out处。
if (ret2 != XDP_PASS) {
ret = NET_RX_DROP;
goto out;
}
}
// 如果数据包是以太网 VLAN 数据包,则调用skb_vlan_untag()函数将 VLAN 标签从数据包中移除。
if (eth_type_vlan(skb->protocol)) {
skb = skb_vlan_untag(skb);
// 如果 skb 为空,则跳转到 out 标签
if (unlikely(!skb))
goto out;
}
// 如果需要跳过 TC 分类,则直接跳转到 skip_classify 标签。
if (skb_skip_tc_classify(skb))
goto skip_classify;
// 如果 pfmemalloc 为 true,则跳转到 skip_taps 标签。
if (pfmemalloc)
goto skip_taps;
// 这个循环遍历全局的注册的协议处理函数 ptype_all 链表,依次调用 deliver_skb 函数传递数据包给每个注册的协议处理程序。
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev); // 抓包:dev_add_pack(&po->prot_hook) 注册的钩子函数
pt_prev = ptype;
}
// 这个循环遍历接收数据包的网络设备的协议处理函数 ptype_all 链表,同样依次调用 deliver_skb 函数传递数据包给每个注册的协议处理程序。
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev); // 抓包:dev_add_pack(&po->prot_hook) 注册的钩子函数
pt_prev = ptype;
}
skip_taps: // 如果是使用 goto 跳转过来的,那跳过了抓包逻辑(libpcap、tcpdump 等)
#ifdef CONFIG_NET_INGRESS // 这部分代码用于处理网络数据包的入口(ingress)功能,即在数据包进入网络协议栈之前进行处理。
// 如果需要进行 TC ingress 处理
if (static_branch_unlikely(&ingress_needed_key)) {
bool another = false;
// 跳过 egress
nf_skip_egress(skb, true);
// 处理 ingress
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev, &another);
// 如果还需要进行下一轮处理,则跳转到 another_round 标签
if (another) //TC BPF 优化,通过 another round 将包从宿主机网卡直接送到容器 netns 内网卡 ?
goto another_round;
if (!skb)
goto out;
// 跳过 egress
nf_skip_egress(skb, false);
// 处理 Netfilter ingress
if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0)
goto out;
}
#endif
// 重置数据包的重定向标志
skb_reset_redirect(skb);
skip_classify: // 如果是使用 goto 跳转过来的,那跳过了抓包、TC、Netfilter 逻辑
// 如果 pfmemalloc 为 true,并且 skb 没有设置 pfmemalloc 协议,则跳转到 drop 标签
if (pfmemalloc && !skb_pfmemalloc_protocol(skb))
goto drop;
if (skb_vlan_tag_present(skb)) {
// 如果数据包中存在 VLAN 标签,则调用 deliver_skb() 函数将数据包传递给之前注册的协议处理函数进行处理
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
// 调用 vlan_do_receive() 函数处理 VLAN 相关操作
if (vlan_do_receive(&skb))
goto another_round;
else if (unlikely(!skb))
goto out;
}
// 获取接收该数据包的网络设备的接收处理函数(rx_handler)
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
// 如果接收处理函数存在,则调用 deliver_skb() 函数将数据包传递给接收处理函数进行处理
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
// 根据接收处理函数的返回值,有不同的处理逻辑
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto out;
case RX_HANDLER_ANOTHER:
goto another_round;
case RX_HANDLER_EXACT:
deliver_exact = true;
break;
case RX_HANDLER_PASS:
break;
default:
BUG();
}
}
// 如果存在 VLAN 标签,并且网络设备不使用 DSA(Distributed Switch Architecture)
if (unlikely(skb_vlan_tag_present(skb)) && !netdev_uses_dsa(skb->dev)) {
check_vlan_id:
if (skb_vlan_tag_get_id(skb)) {
// VLAN ID 非 0,并且无法找到 VLAN 设备
skb->pkt_type = PACKET_OTHERHOST;
} else if (eth_type_vlan(skb->protocol)) {
// 外部头部是 802.1P 带有 VLAN 0,内部头部是 802.1Q 或 802.1AD,并且无法找到 VLAN ID 0 对应的 VLAN 设备
__vlan_hwaccel_clear_tag(skb);
skb = skb_vlan_untag(skb);
if (unlikely(!skb))
goto out;
if (vlan_do_receive(&skb))
goto another_round;
else if (unlikely(!skb))
goto out;
else
goto check_vlan_id;
}
__vlan_hwaccel_clear_tag(skb);
}
// 获取数据包的协议类型
type = skb->protocol;
if (likely(!deliver_exact))
// 如果没有设置精确匹配,将调用 deliver_ptype_list_skb() 函数传递数据包给指定的注册的协议处理函数处理。
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]);
// 调用 deliver_ptype_list_skb() 函数传递数据包给指定的协议处理函数处理
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &orig_dev->ptype_specific);
if (unlikely(skb->dev != orig_dev))
// 如果数据包的网络设备与接收时的网络设备不一致,将调用 deliver_ptype_list_skb() 函数传递数据包给指定的协议处理函数处理。
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &skb->dev->ptype_specific);
if (pt_prev) {
// 如果存在上一个协议处理函数,将调用该处理函数来处理数据包。说明数据包有未处理的分片数据,调用 skb_orphan_frags_rx 函数处理剩余的分片数据。
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
goto drop;
*ppt_prev = pt_prev;
} else {
// 如果不存在上一个协议处理函数,表示没有合适的处理函数来处理数据包,将丢弃数据包并增加接收丢弃计数。
drop:
if (!deliver_exact)
// 更新网卡的 rx_dropped 统计
dev_core_stats_rx_dropped_inc(skb->dev);
else
// 更新网卡的 rx_nohandler 统计
dev_core_stats_rx_nohandler_inc(skb->dev);
kfree_skb_reason(skb, SKB_DROP_REASON_UNHANDLED_PROTO);
ret = NET_RX_DROP;
}
out:
//将处理完的 skb 赋值回 pskb 指针
*pskb = skb;
return ret;
}
-
处理 skb 时间戳;
-
重置网络头;
-
重置传输头;
-
重置 MAC 长度;
-
设置数据包的接收接口索引。
-
前者早在 igb_clean_rx_irq 中执行(前面讲过)避免了后面很多流程所以效率很高;
-
后者效率低,做了很多无用功,所以主要用来功能验证和测试。
-
如果成功,继续处理去除标记后的数据包;
-
否则,跳过该数据包。
net/packet/af_packet.c: dev_add_pack(&po->prot_hook); //用于抓包
net/packet/af_packet.c: dev_add_pack(&f->prot_hook); //用于抓包
-
以前主要用于限速;
-
5.10 版本之后,可以使用 TC BPF 编程来做流量的透明拦截和负载均衡。
-
例如 packet_type.func = prot_hook,就会递交到 af_packe,可以被 tcpdump 抓包;
-
例如 packet_type.func = ip_rcv,就会递交到协议栈入口。
static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
return -ENOMEM;
refcount_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
posted on 2024-01-30 16:01 yipianchuyun 阅读(651) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号