网络收包讲解
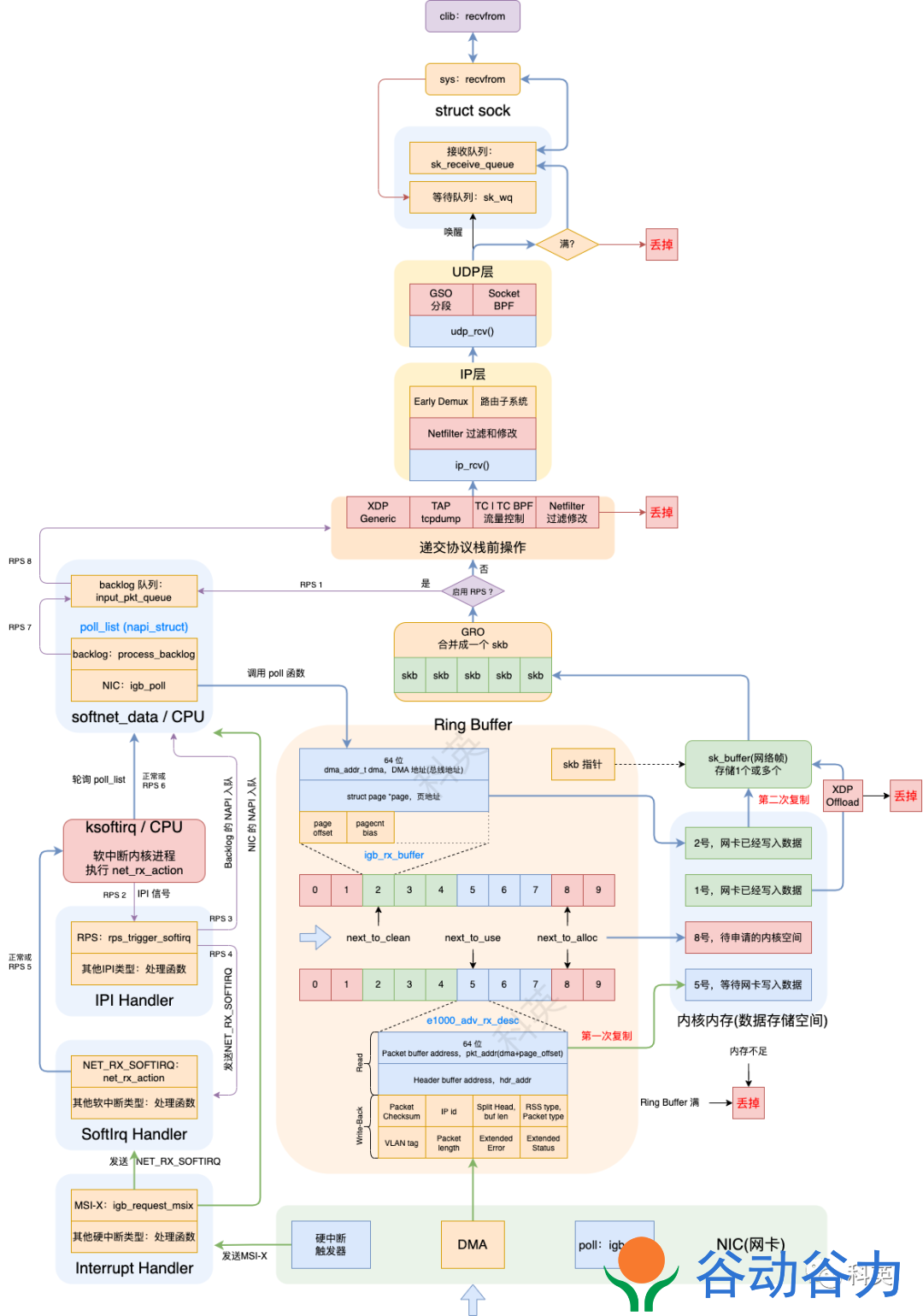
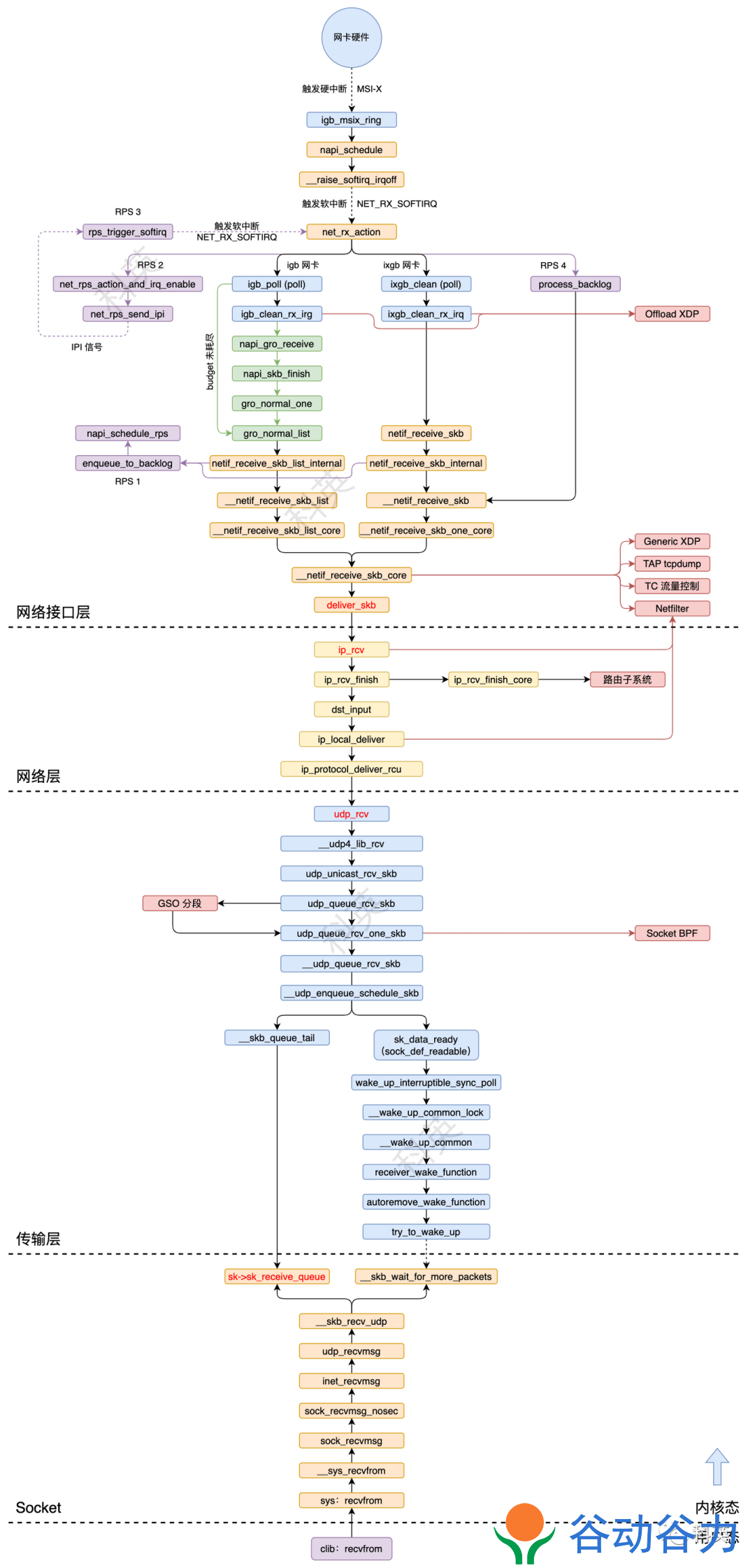
图1 整体流程图
-
网卡驱动的加载
-
网卡驱动的初始化(probe)
-
网卡设备的启用(ndo_open)
-
软中断进程初始化(ksoftirqd)
-
网络子系统初始化(net)
-
网络协议栈初始化
static struct pci_driver igb_driver = {
.name = igb_driver_name, //igb
.id_table = igb_pci_tbl,
.probe = igb_probe,
.remove = igb_remove,
#ifdef CONFIG_PM
.driver.pm = &igb_pm_ops,
#endif
.shutdown = igb_shutdown,
.sriov_configure = igb_pci_sriov_configure,
.err_handler = &igb_err_handler
};
static int __init igb_init_module(void)
{
int ret;
pr_info("%s\n", igb_driver_string);
pr_info("%s\n", igb_copyright);
#ifdef CONFIG_IGB_DCA
dca_register_notify(&dca_notifier);
#endif
ret = pci_register_driver(&igb_driver);
return ret;
}
module_init(igb_init_module);
int __pci_register_driver(struct pci_driver *drv, struct module *owner, const char *mod_name)
{
/* initialize common driver fields */
drv->driver.name = drv->name;
drv->driver.bus = &pci_bus_type;
drv->driver.owner = owner;
drv->driver.mod_name = mod_name;
drv->driver.groups = drv->groups;
drv->driver.dev_groups = drv->dev_groups;
spin_lock_init(&drv->dynids.lock);
INIT_LIST_HEAD(&drv->dynids.list);
/* register with core */
return driver_register(&drv->driver);
}
static const struct pci_device_id igb_pci_tbl[] = {
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_BACKPLANE_1GBPS) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_SGMII) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_BACKPLANE_2_5GBPS) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I211_COPPER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_COPPER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_FIBER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SERDES), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SGMII), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_COPPER_FLASHLESS), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SERDES_FLASHLESS), board_82575 },
/* required last entry */
{0, }
};
-
设置 DMA 寻址限制和缓存一致性;
-
申请内核内存;
-
struct net_device 结构体的创建、初始化和注册;
-
注册 struct net_device_ops (里面有 igb_open ) 到 net_device;
-
注册驱动支持的 ethtool 调用函数;
-
注册 poll 函数到 NAPI 子系统;
static int igb_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
/* 设置 DMA 寻址限制和缓存一致性 */
err = dma_set_mask_and_coherent(&pdev->dev, DMA_BIT_MASK(64));
/* 申请内存 */
err = pci_request_mem_regions(pdev, igb_driver_name);
/* 网络设备 */
netdev = alloc_etherdev_mq(sizeof(struct igb_adapter), IGB_MAX_TX_QUEUES);
/* net_device_ops 结构体,代表一个网络设备 */
netdev->netdev_ops = &igb_netdev_ops;
/* 注册驱动支持的 ethtool 调用函数 */
igb_set_ethtool_ops(netdev);
/* 函数里面注册了 poll 函数 */
err = igb_sw_init(adapter);
}
DMA(Direct Memory Access)顾名思义就是「直接内存访问」,是指一个设备和 CPU 共享内存总线。DMA 主要优点:通过和 CPU 共享内存总线,DMA 可以实现 IO 设备和内存之间快速的数据复制(不论内存到设备还是设备到内存,都能够加速数据传输)。
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_get_stats64 = igb_get_stats64,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address= igb_set_mac,
.ndo_change_mtu = igb_change_mtu,
.ndo_eth_ioctl = igb_ioctl,
.ndo_tx_timeout = igb_tx_timeout,
.ndo_validate_addr = eth_validate_addr,
.ndo_vlan_rx_add_vid= igb_vlan_rx_add_vid,
.ndo_vlan_rx_kill_vid= igb_vlan_rx_kill_vid,
.ndo_set_vf_mac = igb_ndo_set_vf_mac,
.ndo_set_vf_vlan = igb_ndo_set_vf_vlan,
.ndo_set_vf_rate = igb_ndo_set_vf_bw,
.ndo_set_vf_spoofchk= igb_ndo_set_vf_spoofchk,
.ndo_set_vf_trust = igb_ndo_set_vf_trust,
.ndo_get_vf_config = igb_ndo_get_vf_config,
.ndo_fix_features = igb_fix_features,
.ndo_set_features = igb_set_features,
.ndo_fdb_add = igb_ndo_fdb_add,
.ndo_features_check = igb_features_check,
.ndo_setup_tc = igb_setup_tc,
.ndo_bpf = igb_xdp,
.ndo_xdp_xmit = igb_xdp_xmit,
};
static int igb_alloc_q_vector(struct igb_adapter *adapter, int v_count, int v_idx, int txr_count, int txr_idx, int rxr_count, int rxr_idx)
{
/* allocate q_vector and rings */
q_vector = adapter->q_vector[v_idx];
/* 初始化 NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64);
}
-
分配多 TX/RX 队列的内核内存空间;
-
给网卡配置 RX/TX 队列,给 RX 申请 DMA 空间;
-
注册硬中断处理函数;
-
打开 NAPI;
-
打开网卡硬中断;
static int __igb_open(struct net_device *netdev, bool resuming)
{
/* 分配多 TX 队列的内存空间 */
err = igb_setup_all_tx_resources(adapter);
/* 分配多 RX 队列的内存空间 */
err = igb_setup_all_rx_resources(adapter);
/* 给网卡配置 RX/TX 队列,给 RX 申请 DMA 空间 */
igb_configure(adapter);
/* 注册中断处理函数 */
err = igb_request_irq(adapter);
/* 打开 NAPI */
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector->napi));
/* 打开硬中断 */
igb_irq_enable(adapter);
/* 启动所有 TX 队列 */
netif_tx_start_all_queues(netdev);
}
int igb_open(struct net_device *netdev)
{
return __igb_open(netdev, false);
}
static int igb_setup_all_rx_resources(struct igb_adapter *adapter)
{
for (i = 0; i < adapter->num_rx_queues; i++)
err = igb_setup_rx_resources(adapter->rx_ring);
}
int igb_setup_rx_resources(struct igb_ring *rx_ring)
{
/* Ring Buffer 的元素是 struct igb_rx_buffer */
size = sizeof(struct igb_rx_buffer) * rx_ring->count;
/* 申请 Ring Buffer 内存空间 */
rx_ring->rx_buffer_info = vmalloc(size);
/* Round up to nearest 4K */
rx_ring->size = rx_ring->count * sizeof(union e1000_adv_rx_desc);
rx_ring->size = ALIGN(rx_ring->size, 4096);
/* 通过 DMA 申请连续内核空间,数量与 Ring Buffer 长度一致 */
rx_ring->desc = dma_alloc_coherent(dev, rx_ring->size, &rx_ring->dma, GFP_KERNEL);
/* 复位 */
rx_ring->next_to_alloc = 0;
rx_ring->next_to_clean = 0;
rx_ring->next_to_use = 0;
}
struct igb_rx_buffer {
dma_addr_t dma; /* DMA 内核空间地址 */
struct page *page;
__u16 page_offset;
__u16 pagecnt_bias;
};
static void igb_configure(struct igb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
int i;
/* 给网卡配置 TX/RX 队列,收发数据均从一个元素开始 */
igb_configure_tx(adapter);
igb_configure_rx(adapter);
/* 清空网卡内的 RX FIFO */
igb_rx_fifo_flush_82575(&adapter->hw);
/* 给每个 RX 队列分配 DMA 空间,便于网卡硬件接收数据写入其中 */
for (i = 0; i < adapter->num_rx_queues; i++) {
struct igb_ring *ring = adapter->rx_ring;
igb_alloc_rx_buffers(ring, igb_desc_unused(ring));
}
}
void igb_alloc_rx_buffers(struct igb_ring *rx_ring, u16 cleaned_count)
{
union e1000_adv_rx_desc *rx_desc;
struct igb_rx_buffer *bi;
u16 i = rx_ring->next_to_use;
u16 bufsz;
rx_desc = IGB_RX_DESC(rx_ring, i);
bi = &rx_ring->rx_buffer_info;
i -= rx_ring->count;
bufsz = igb_rx_bufsz(rx_ring);
do {
/* 申请 DMA 地址(总线地址)空间供网卡写入接收的数据,sync the buffer for use by the device */
dma_sync_single_range_for_device(rx_ring->dev, bi->dma, bi->page_offset, bufsz, DMA_FROM_DEVICE);
/* Refresh the desc even if buffer_addrs didn't change
* because each write-back erases this info.
*/
rx_desc->read.pkt_addr = cpu_to_le64(bi->dma + bi->page_offset);
rx_desc++;
bi++;
i++;
if (unlikely(!i)) {
rx_desc = IGB_RX_DESC(rx_ring, 0);
bi = rx_ring->rx_buffer_info;
i -= rx_ring->count;
}
/* clear the length for the next_to_use descriptor */
rx_desc->wb.upper.length = 0;
cleaned_count--;
} while (cleaned_count);
}
static int igb_request_irq(struct igb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
int err = 0;
/* MSI-X */
if (adapter->flags & IGB_FLAG_HAS_MSIX) {
err = igb_request_msix(adapter);
if (!err)
goto request_done;
/* fall back to MSI */
}
/* MSI */
if (adapter->flags & IGB_FLAG_HAS_MSI) {
err = request_irq(pdev->irq, igb_intr_msi, 0, netdev->name, adapter);
if (!err)
goto request_done;
/* fall back to legacy interrupts */
}
/* legacy interrupts */
err = request_irq(pdev->irq, igb_intr, IRQF_SHARED, netdev->name, adapter);
}
static int igb_request_msix(struct igb_adapter *adapter)
{
/* 注册 igb_msix_ring 硬中断函数 */
err = request_irq(adapter->msix_entries[vector].vector, igb_msix_ring, 0, q_vector->name, q_vector);
}
/* 打开 NAPI */
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector->napi));
static void igb_irq_enable(struct igb_adapter *adapter)
{
struct e1000_hw *hw = &adapter->hw;
if (adapter->flags & IGB_FLAG_HAS_MSIX) {
u32 ims = E1000_IMS_LSC | E1000_IMS_DOUTSYNC | E1000_IMS_DRSTA;
u32 regval = rd32(E1000_EIAC);
wr32(E1000_EIAC, regval | adapter->eims_enable_mask);
regval = rd32(E1000_EIAM);
wr32(E1000_EIAM, regval | adapter->eims_enable_mask);
wr32(E1000_EIMS, adapter->eims_enable_mask);
if (adapter->vfs_allocated_count) {
wr32(E1000_MBVFIMR, 0xFF);
ims |= E1000_IMS_VMMB;
}
wr32(E1000_IMS, ims);
} else {
wr32(E1000_IMS, IMS_ENABLE_MASK | E1000_IMS_DRSTA);
wr32(E1000_IAM, IMS_ENABLE_MASK | E1000_IMS_DRSTA);
}
}
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
static __init int spawn_ksoftirqd(void) {
cpuhp_setup_state_nocalls(CPUHP_SOFTIRQ_DEAD, "softirq:dead", NULL, takeover_tasklets);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
/* Initialise the packet receive queues. */
for_each_possible_cpu(i) {
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
#ifdef CONFIG_XFRM_OFFLOAD
skb_queue_head_init(&sd->xfrm_backlog);
#endif
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
/* 注册 IPI 信号的处理函数,然后发出 NET_RX_SOFTIRQ 软中断信号 */
INIT_CSD(&sd->csd, rps_trigger_softirq, sd);
sd->cpu = i;
#endif
INIT_CSD(&sd->defer_csd, trigger_rx_softirq, sd);
spin_lock_init(&sd->defer_lock);
init_gro_hash(&sd->backlog);
/* 软中断中通过调用 backlog(napi_struct)的 poll 处理 cpu 的 sd 的 input_pkt_queue(skb) 队列 */
sd->backlog.poll = process_backlog;
/* weight_p 可以调整,网卡的 poll 权重是 hardcode 64 */
sd->backlog.weight = weight_p;
}
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
}
/* 内核通过调用 subsys_initcall 初始化各个子系统 */
subsys_initcall(net_dev_init);
-
注册到该 CPU 的 NAPI 结构体列表(poll_list);
-
接收和发送队列;
-
backlog(napi_struct)初始化;
-
RPS 相关的指针;
struct softnet_data {
struct list_head poll_list;
struct sk_buff_head process_queue;
/* stats */
unsigned int processed;
unsigned int time_squeeze;
unsigned int received_rps;
#ifdef CONFIG_RPS
struct softnet_data *rps_ipi_list;
#endif
#ifdef CONFIG_NET_FLOW_LIMIT
struct sd_flow_limit __rcu *flow_limit;
#endif
struct Qdisc *output_queue;
struct Qdisc **output_queue_tailp;
struct sk_buff *completion_queue;
#ifdef CONFIG_XFRM_OFFLOAD
struct sk_buff_head xfrm_backlog;
#endif
/* written and read only by owning cpu: */
struct {
u16 recursion;
u8 more;
#ifdef CONFIG_NET_EGRESS
u8 skip_txqueue;
#endif
} xmit;
#ifdef CONFIG_RPS
/* input_queue_head should be written by cpu owning this struct,
* and only read by other cpus. Worth using a cache line.
*/
unsigned int input_queue_head ____cacheline_aligned_in_smp;
/* Elements below can be accessed between CPUs for RPS/RFS */
call_single_data_t csd ____cacheline_aligned_in_smp;
struct softnet_data *rps_ipi_next;
unsigned int cpu;
unsigned int input_queue_tail;
#endif
unsigned int dropped;
struct sk_buff_head input_pkt_queue;
struct napi_struct backlog;
/* Another possibly contended cache line */
spinlock_t defer_lock ____cacheline_aligned_in_smp;
int defer_count;
int defer_ipi_scheduled;
struct sk_buff *defer_list;
call_single_data_t defer_csd;
};
open_softirq(NET_TX_SOFTIRQ, net_tc_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
/* softirq_vec 是静态变量 */
softirq_vec[nr].action = action;
}
-
将 TCP、UDP 和 ICMP 的接收函数注册到 inet_protos 数组中;
-
注册 Socket 相关的信息到 inetsw 链表数组中,便于 inet_create 函数创建套接字;
-
将 IP 的接收函数注册到 ptype_base 哈希表中。
static int __init inet_init(void) {
struct inet_protosw *q;
struct list_head *r;
int rc;
sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
raw_hashinfo_init(&raw_v4_hashinfo);
/* 注册各种协议的各种处理函数 */
rc = proto_register(&tcp_prot, 1);
rc = proto_register(&udp_prot, 1);
rc = proto_register(&raw_prot, 1);
rc = proto_register(&ping_prot, 1);
/* Tell SOCKET that we are alive... */
(void)sock_register(&inet_family_ops);
#ifdef CONFIG_SYSCTL
ip_static_sysctl_init();
#endif
/* 添加所有基础网络协议,eg. 添加到 inet_protos[IPPROTO_ICMP] = icmp_protocol 数组里 */
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);
#endif
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
/* 加载 arp 模块 */
arp_init();
/* 加载 ip 模块 */
ip_init();
/* Initialise per-cpu ipv4 mibs */
if (init_ipv4_mibs())
panic("%s: Cannot init ipv4 mibs\n", __func__);
/* Setup TCP slab cache for open requests. */
tcp_init();
/* Setup UDP memory threshold */
udp_init();
/* Add UDP-Lite (RFC 3828) */
udplite4_register();
/* RAW 类型数据包 */
raw_init();
ping_init();
/* 加载 icmp 模块 */
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
/* Initialise the multicast router */
#if defined(CONFIG_IP_MROUTE)
if (ip_mr_init())
pr_crit("%s: Cannot init ipv4 mroute\n", __func__);
#endif
if (init_inet_pernet_ops())
pr_crit("%s: Cannot init ipv4 inet pernet ops\n", __func__);
ipv4_proc_init();
ipfrag_init();
/* 将 IP 的接收函数 ip_rcv 注册到 ptype_base 列表里 */
dev_add_pack(&ip_packet_type);
ip_tunnel_core_init();
rc = 0;
}
fs_initcall(inet_init);
static const struct net_protocol tcp_protocol = {
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.icmp_strict_tag_validation = 1,
};
static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
};
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
};
struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS] __read_mostly;
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol) {
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol], NULL, prot) ? 0 : -1;
}
/* The inetsw table contains everything that inet_create needs to
* build a new socket.
*/
static struct list_head inetsw[SOCK_MAX];
/* Upon startup we insert all the elements in inetsw_array[] into
* the linked list inetsw.
*/
static struct inet_protosw inetsw_array[] = {
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
};
/* Register the socket-side information for inet_create. */
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
void inet_register_protosw(struct inet_protosw *p)
{
struct list_head *lh;
struct inet_protosw *answer;
int protocol = p->protocol;
struct list_head *last_perm;
...
last_perm = &inetsw[p->type];
list_for_each(lh, &inetsw[p->type]) {
answer = list_entry(lh, struct inet_protosw, list);
/* Check only the non-wild match. */
if ((INET_PROTOSW_PERMANENT & answer->flags) == 0)
break;
if (protocol == answer->protocol)
goto out_permanent;
last_perm = lh;
}
...
}
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,// 接收数据
#ifdef CONFIG_MMU
.mmap = tcp_mmap,
#endif
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
.read_sock = tcp_read_sock,
.read_skb = tcp_read_skb,
.sendmsg_locked = tcp_sendmsg_locked,
.sendpage_locked= tcp_sendpage_locked,
.peek_len = tcp_peek_len,
#ifdef CONFIG_COMPAT
.compat_ioctl = inet_compat_ioctl,
#endif
.set_rcvlowat = tcp_set_rcvlowat,
};
const struct proto_ops inet_dgram_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_dgram_connect,
.socketpair = sock_no_socketpair,
.accept = sock_no_accept,
.getname = inet_getname,
.poll = udp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = sock_no_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.read_skb = udp_read_skb,
.recvmsg = inet_recvmsg,// 接收数据
.mmap = sock_no_mmap,
.sendpage = inet_sendpage,
.set_peek_off = sk_set_peek_off,
#ifdef CONFIG_COMPAT
.compat_ioctl = inet_compat_ioctl,
#endif
};
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.bpf_bypass_getsockopt = tcp_bpf_bypass_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,// 接收数据
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.unhash = inet_unhash,
.get_port = inet_csk_get_port,
.put_port = inet_put_port,
#ifdef CONFIG_BPF_SYSCALL
.psock_update_sk_prot = tcp_bpf_update_proto,
#endif
.enter_memory_pressure = tcp_enter_memory_pressure,
.leave_memory_pressure = tcp_leave_memory_pressure,
.stream_memory_free = tcp_stream_memory_free,
.sockets_allocated = &tcp_sockets_allocated,
.orphan_count = &tcp_orphan_count,
.memory_allocated = &tcp_memory_allocated,
.per_cpu_fw_alloc = &tcp_memory_per_cpu_fw_alloc,
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem),
.max_header = MAX_TCP_HEADER,
.obj_size = sizeof(struct tcp_sock),
.slab_flags = SLAB_TYPESAFE_BY_RCU,
.twsk_prot = &tcp_timewait_sock_ops,
.rsk_prot = &tcp_request_sock_ops,
.h.hashinfo = &tcp_hashinfo,
.no_autobind = true,
.diag_destroy = tcp_abort,
};
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.pre_connect = udp_pre_connect,
.connect = ip4_datagram_connect,
.disconnect = udp_disconnect,
.ioctl = udp_ioctl,
.init = udp_init_sock,
.destroy = udp_destroy_sock,
.setsockopt = udp_setsockopt,
.getsockopt = udp_getsockopt,
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,// 接收数据
.sendpage = udp_sendpage,
.release_cb = ip4_datagram_release_cb,
.hash = udp_lib_hash,
.unhash = udp_lib_unhash,
.rehash = udp_v4_rehash,
.get_port = udp_v4_get_port,
.put_port = udp_lib_unhash,
#ifdef CONFIG_BPF_SYSCALL
.psock_update_sk_prot = udp_bpf_update_proto,
#endif
.memory_allocated = &udp_memory_allocated,
.per_cpu_fw_alloc = &udp_memory_per_cpu_fw_alloc,
.sysctl_mem = sysctl_udp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_udp_wmem_min),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_udp_rmem_min),
.obj_size = sizeof(struct udp_sock),
.h.udp_table = &udp_table,
.diag_destroy = udp_abort,
};
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
extern struct list_head ptype_all __read_mostly;
struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
void dev_add_pack(struct packet_type *pt) {
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
static inline struct list_head *ptype_head(const struct packet_type *pt) {
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific : &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
$ grep -R dev_add_pack net/{ipv4,packet}/*
net/ipv4/af_inet.c: dev_add_pack(&ip_packet_type); //IP
net/ipv4/arp.c: dev_add_pack(&arp_packet_type); //ARP
net/ipv4/ipconfig.c: dev_add_pack(&rarp_packet_type);
net/ipv4/ipconfig.c: dev_add_pack(&bootp_packet_type);
net/packet/af_packet.c: dev_add_pack(&po->prot_hook); //用于抓包
net/packet/af_packet.c: dev_add_pack(&f->prot_hook); //用于抓包
$ cat /proc/net/ptype # packet type (skb->protocol)
Type Device Function
0800 ip_rcv
0806 arp_rcv
86dd ipv6_rcv
posted on 2024-01-30 15:58 yipianchuyun 阅读(305) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号