分布式定时任务调度框架选型
分布式定时任务调度框架选型
背景
业务场景
- 定期执行任务:如每天0点做资源稽查;
需求和痛点
- 集群部署服务时,如何确保任务不被重复执行?---最急迫
- 如何监控、告警等;
- 高可用、无单点故障;
- 优秀的并行处理能力、分片能力;
自研 or 开源
任何工具的使用都要结合自身的业务场景,脱落业务场景谈技术选型就是耍流氓。
考虑私有云场景业务量一般,高并发场景很少遇到,同一时间也不会有超大量定时任务同时需要执行,所以考虑自研也未尝不可。
目前自研最急需解决的问题并不是高并发,而是如何避免任务被重复执行;
场景就变成了:
多个应用在同一个时间都尝试去执行任务,但最终只有一个应用真正执行。
这样的话,立马就会让人联想到使用锁去解决,因为是多个应用,所以就是分布式锁。那么,场景又变了:
多个应用在同一个时间都尝试去获取
分布式锁,只有一个应用能抢到这把锁,抢到锁的应用可以执行定时任务,其他应用则直接放弃,等待下一次执行时间。
抢锁的时机是每次定时任务执行之前,这又让我联想到了AOP,那么利用注解也就顺理成章了。
下面的 ShedLock就是基于AOP + 注解的思想。
ShedLock
与Spring的集成挺方便;
Distributed lock for your scheduled tasks
Github: start: 1K Fork: 192,最近一次代码提交 6months ago
ShedLock makes sure that your scheduled tasks are executed at most once at the same time. If a task is being executed on one node, it acquires a lock which prevents execution of the same task from another node (or thread). Please note, that if one task is already being executed on one node, execution on other nodes does not wait, it is simply skipped.
ShedLock uses external store like Mongo, JDBC database, Redis, Hazelcast, ZooKeeper or others for coordination.
ShedLock is not a distributed scheduler
Please note that ShedLock is not and will never be full-fledged scheduler, it's just a lock. If you need a distributed scheduler, please use another project. ShedLock is designed to be used in situations where you have scheduled tasks that are not ready to be executed in parallel, but can be safely executed repeatedly.
重要信息:
- ShedLock可使用MongoDB、JDBC-DB、Redis或Zookeeper等来实现分布式锁,具体采用哪种方式,由使用者决定;
- 它仅仅是一个分布式锁,并不是调度程序;
与Spring的集成很简单(官方文档的示例,自己并未测试过),示例:
假设一个task每15分钟执行一次,每次运行的时间都不是很长(即:应该在15min分钟内可以运行完),更重要的是,不管起多少个实例,都只希望在15分钟内该任务有且只被运行一次!
//示例:与Spring的原生注解 @Scheduled配合使用
import net.javacrumbs.shedlock.core.SchedulerLock;
@Scheduled(cron = "0 */15 * * * *")//每15分钟运行一次
@SchedulerLock(name = "scheduledTaskName", lockAtMostFor = "14m", lockAtLeastFor = "14m")
public void scheduledTask() {
// do something
}
//lockAtMostFor : 表示最多锁定14分钟,主要用于防止执行任务的节点挂掉(即使这个节点挂掉,在14分钟后,锁也被释放),一般将其设置为明显大于任务的最大执行时长;如果任务运行时间超过该值(即任务14分钟没有执行完),则该任务可能被重复执行!
//lockAtLeastFor : 至少锁定时长,确保在15分钟内,该任务不会运行超过1次;
额外补充一句,关于 @Scheduled的一些不注意的细节(单线程执行),需要特别注意:SpringTask实现定时任务
Configure LockProvider
使用JdbcTemplete来实现分布式锁
CREATE TABLE shedlock(
name VARCHAR(64),
lock_until TIMESTAMP(3) NULL,
locked_at TIMESTAMP(3) NULL,
locked_by VARCHAR(255),
PRIMARY KEY (name)
)
依赖
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-jdbc-template</artifactId>
<version>4.5.1</version>
</dependency>
配置
import net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider;
...
@Bean
public LockProvider lockProvider(DataSource dataSource) {
return new JdbcTemplateLockProvider(dataSource);
}
@Bean
public ScheduledLockConfiguration scheduledLockConfiguration(LockProvider lockProvider) {
return ScheduledLockConfigurationBuilder
.withLockProvider(lockProvider)
.withPoolSize(10)
.withDefaultLockAtMostFor(Duration.ofMinutes(10))
.build();
}
基于Piston的思路(异步监控),重写一个
todo
思路:
- 还是基于Innodb引擎的行锁;
- 状态:应该基于调度时间去判断状态;
选型参考
- 简单、易上手;
- 额外依赖较少,比如是否需要依赖MQ、Zookeeper等;
- 是否方便集成;
开源产品对比
Quartz
Java事实上的定时任务标准。但Quartz关注点在于定时任务而非数据,并无一套根据数据处理而定制化的流程。虽然Quartz可以基于数据库实现作业的高可用,但缺少分布式并行调度的功能
原理

独立的Quratz节点之间是不需要通信的,不同节点之间是通过数据库表来感知另一个应用,只有使用持久的JobStore才能完成Quartz集群。如果某一个节点失效,那么Job会在其他节点上执行。
如何保证只在一台机器上触发?
- 数据库悲观锁
- 一旦某一节点线程获取了该锁,那么Job就会在这台机器上被执行,其他节点进行锁等待;
缺点
- 不适合大量的短任务 & 不适合过多节点部署;
- 解决了高可用的问题,并没有解决任务分片的问题,存在单机处理的极限(即:不能实现水平扩展)。
- 需要把任务信息持久化到业务数据表,和业务有耦合
- 调度逻辑和执行逻辑并存于同一个项目中,在机器性能固定的情况下,业务和调度之间不可避免地会相互影响。
- quartz集群模式下,是通过数据库独占锁来唯一获取任务,任务执行并没有实现完善的负载均衡机制。
Elastic-Job

GitHub: star 5.7K Fork:2.6K
Elastic-Job is a distributed scheduled job framework, based on Quartz and Zookeeper
Elastic Job是当当网架构师开发,是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成;定位为轻量级无中心化解决方案,使用 jar 包的形式提供分布式任务的协调服务。支持分布式调度协调、弹性扩容缩容、失效转移、错过执行作业重触发、并行调度、自诊断和修复等等功能特性。
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务;Elastic-Job-Cloud采用自研Mesos Framework的解决方案,额外提供资源治理、应用分发以及进程隔离等功能;
Elastic-Job-Lite并没有宿主程序,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。它的开发也比较简单,引用Jar包实现一些方法即可,最后编译成Jar包运行。Elastic-Job-Lite的分布式部署全靠ZooKeeper来同步状态和原数据。实现高可用的任务只需将分片总数设置为1,并把开发的Jar包部署于多个服务器上执行,任务将会以1主N从的方式执行。一旦本次执行任务的服务器崩溃,其他执行任务的服务器将会在下次作业启动时选择一个替补执行。如果开启了失效转移,那么功能效果更好,可以保证在本次作业执行时崩溃,备机之一立即启动替补执行。
Elastic-Job-Lite的任务分片也是通过ZooKeeper来实现,Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与真实数据的对应关系。框架也预置了一些分片策略:平均分配算法策略,作业名哈希值奇偶数算法策略,轮转分片策略。同时也提供了自定义分片策略的接口。
另外Elastic-Job-Lite还提供了一个任务监控和管理界面:Elastic-Job-Lite-Console。它和Elastic-Job-Lite是两个完全不关联的应用程序,使用ZooKeeper来交换数据,管理人员可以通过这个界面查看、监控和管理Elastic-Job-Lite的任务,必要的时候还能手动触发任务
功能列表
- 分布式调度协调
- 弹性扩容缩容
- 失效转移
- 错过执行作业重触发
- 作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
- 自诊断并修复分布式不稳定造成的问题
- 支持并行调度
- 支持作业生命周期操作
- 丰富的作业类型
- Spring整合以及命名空间提供
- 运维平台
优缺点
优点:
- 基于成熟的定时任务作业框架Quartz cron表达式执行定时任务;
- 支持任务分片:可以拆分任务,分别由不同节点执行;
- 官网文档齐全,全中文;
- 弹性扩容缩容:运行中的作业服务器崩溃,或新增N台作业服务器,作业框架将在下次作业执行前重新分片,不影响当前作业执行;
- 任务监控和管理界面;
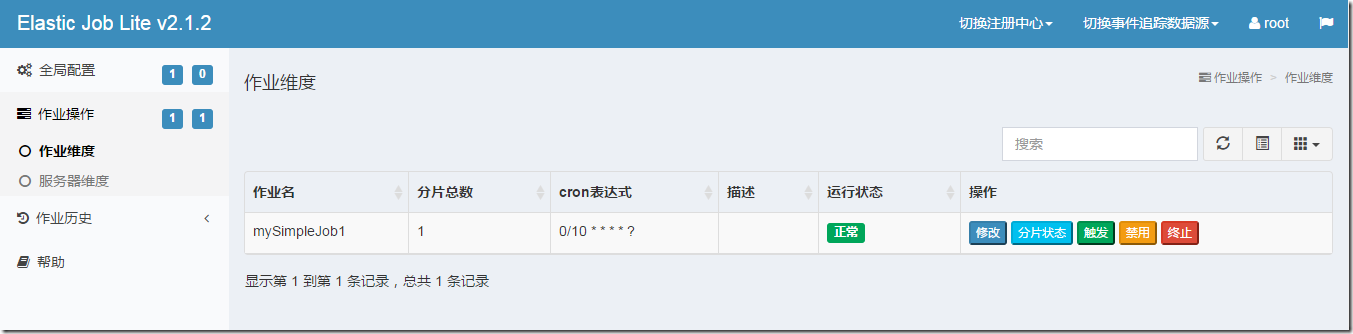
缺点:
- 依赖Zookeeper;
XXL-JOB
GitHub: star: 12.9K Fork:5.5K
使用该框架的公司:>300家
XXL-Job官网是大众点评员工徐雪里于2015年发布的分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
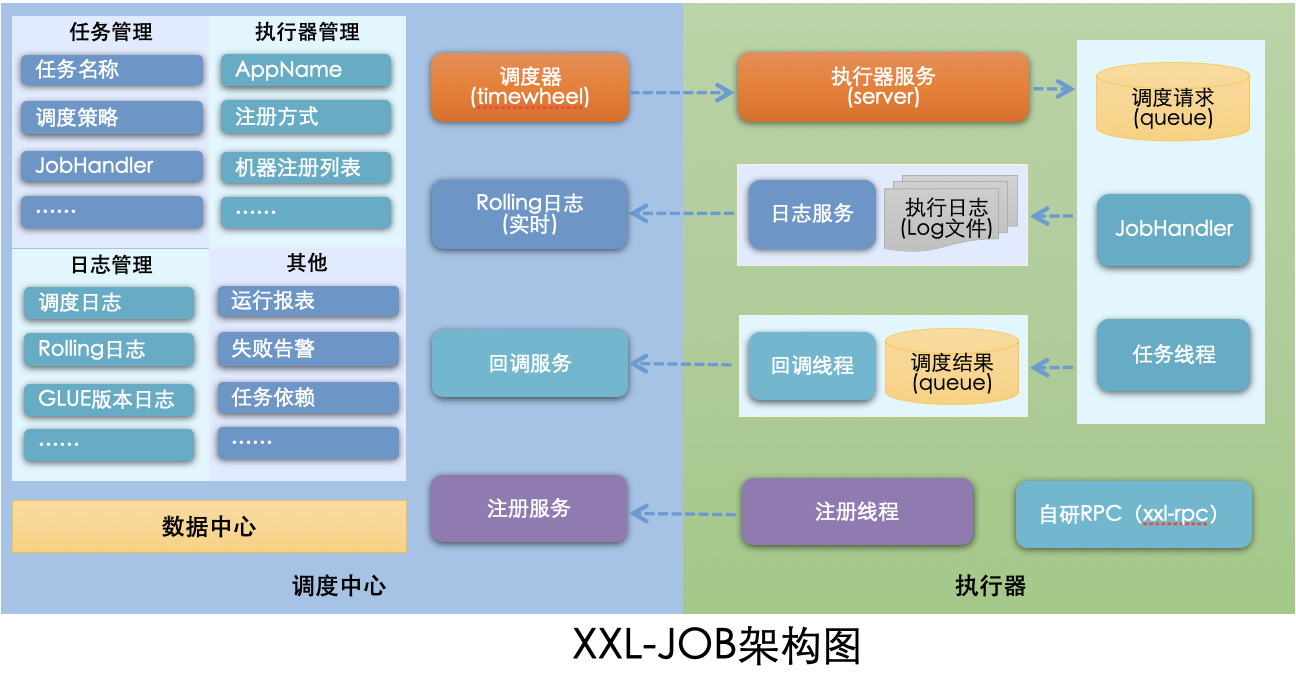
设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
系统组成
- 调度模块(调度中心):
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。 - 执行模块(执行器):
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
其他
uncode-schedule
基于zookeeper,比较小众,不推荐
基于zookeeper+spring task/quartz的分布式任务调度组件,确保所有任务在集群中不重复,不遗漏的执行。支持动态添加和删除任务。
LTS
最近一次更新在2年前,目前不是很活跃;也比较小众,不推荐
LTS(light-task-scheduler)主要用于解决分布式任务调度问题,支持实时任务,定时任务和Cron任务。有较好的伸缩性,扩展性;
TBSchedule
阿里早期开源的分布式任务调度系统。代码略陈旧,使用timer而非线程池执行任务调度。众所周知,timer在处理异常状况时是有缺陷的。而且TBSchedule作业类型较为单一,只能是获取/处理数据一种模式。还有就是文档缺失比较严重。
依赖Zookeeper;
TBSchedule是一款非常优秀的高性能分布式调度框架,广泛应用于阿里巴巴、淘宝、支付宝、京东、聚美、汽车之家、国美等很多互联网企业的流程调度系统。tbschedule在时间调度方面虽然没有quartz强大,但是它支持分片功能。和quartz不同的是,tbschedule使用ZooKeeper来实现任务调度的高可用和分片。
TBSchedule的分布式机制是通过灵活的Sharding方式实现的,分片的规则由客户端决定,比如可以按所有数据的ID按10取模分片、按月份分片等等。TBSchedule的宿主服务器可以进行动态扩容和资源回收,这个特点主要是因为它后端依赖的ZooKeeper,这里的ZooKeeper对于TBSchedule来说是一个NoSQL,用于存储策略、任务、心跳信息数据,它的数据结构类似文件系统的目录结构,它的节点有临时节点、持久节点之分。调度引擎启动后,随着业务量数据量的增多,当前Cluster可能不能满足目前的处理需求,那么就需要增加服务器数量,一个新的服务器上线后会在ZooKeeper中创建一个代表当前服务器的一个唯一性路径(临时节点),并且新上线的服务器会和ZooKeeper保持长连接,当通信断开后,节点会自动摘除。
TBSchedule会定时扫描当前服务器的数量,重新进行任务分配。TBSchedule不仅提供了服务端的高性能调度服务,还提供了一个scheduleConsole的war包,随着宿主应用的部署直接部署到服务器,可以通过web的方式对调度的任务、策略进行监控管理,以及实时更新调整。
Saturn
Saturn是唯品会在github开源的一款分布式任务调度产品。它是基于当当elastic-job 1.0版本来开发的,其上完善了一些功能和添加了一些新的feature。
亮点:
支持多语言开发 python、Go、Shell、Java、Php。
管理控制台和数据统计分析更加完善
缺点:
技术文档较少 , 该框架是2016年由唯品会的研发团队基于elastic-job开发而来
Opencron
比较小众,不推荐
Antares
Antares 是一款基于 Quartz 机制的分布式任务调度管理平台,内部重写执行逻辑,一个任务仅会被服务器集群中的某个节点调度。用户可通过对任务预分片,有效提升任务执行效率;也可通过控制台 antares-tower 对任务进行基本操作,如触发,暂停,监控等。
Antares 是基于 Quartz 的分布式调度,支持分片,支持树形任务依赖,但是不是跨平台的
sia-task
没有仔细研究,依赖Zookeeper,感觉更偏向于解决编排和跨平台
无论是互联网应用或者企业级应用,都充斥着大量的批处理任务。我们常常需要一些任务调度系统帮助我们解决问题。随着微服务化架构的逐步演进,单体架构逐渐演变为分布式、微服务架构。在此的背景下,很多原先的任务调度平台已经不能满足业务系统的需求。于是出现了一些基于分布式的任务调度平台。这些平台各有其特点,但各有不足之处,比如不支持任务编排、与业务高耦合、不支持跨平台等问题。不是非常符合公司的需求,因此我们开发了微服务任务调度平台(SIA-TASK)。
SIA是我们公司基础开发平台Simple is Awesome的简称,SIA-TASK(微服务任务调度平台)是其中的一项重要产品,SIA-TASK契合当前微服务架构模式,具有跨平台,可编排,高可用,无侵入,一致性,异步并行,动态扩展,实时监控等特点。
对比和结论

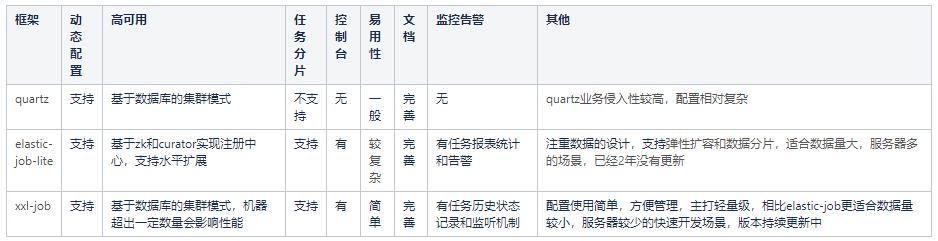

XXL-Job 侧重的业务实现的简单和管理的方便,学习成本简单,失败策略和路由策略丰富。推荐使用在“用户基数相对少,服务器数量在一定范围内”的情景下使用
Elastic-Job 关注的是数据,增加了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源。但是学习成本相对高些,推荐在“数据量庞大,且部署服务器数量较多”时使用
对于并发场景不是特别高的系统来说,xxl-job配置部署简单易用,不需要引入多余的组件,同时提供了可视化的控制台,使用起来非常友好,是一个比较好的选择。
Elastic-Job
这个框架大概在2年前很火,当时使用的公司很多,想必很多人也听过了,但是很可惜现在已经不在维护了,代码已经有2年没有更新了,这里违反了更新频率的原则,如果出现问题可能都没什么人帮助你,所以并不是很推荐使用。
更倾向于选择XXL-JOB:
- 轻量级,支持通过Web页面对任务进行动态CRUD操作,操作简单
- 只依赖数据库作为集群注册中心,接入开发简单,不需要ZK
- 高可用、解耦、高性能、监控报警、分片、重试、故障转移
- 团队持续开发,社区活跃
- 支持后台直接查看每个任务执行实时日志,ELASTIC-JOB中应该是没有这个功能
ShedLock集成更简单,如果验证通过,也未必不是一个好选择!
其他
中心化调度 vs 去中心化调度
| 中心化 | 去中心化 | |
|---|---|---|
| 实现难度 | 高 | 低 |
| 部署难度 | 高 | 低 |
| 触发时间统一控制 | 可以 | 不可以 |
| 触发延迟 | 有 | 无 |
| 异构语言支持 | 容易 | 不容易 |
中心化调度
- XXL-Job:有调度中心;
去中心化调度
- Quartz
- Elastic-Job:实现时,就是基于Quartz的基于数据库的分布式思想;
参考
posted on 2022-04-07 18:25 yipianchuyun 阅读(782) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号