

Hive的JDBC环境部署
Hive的JDBC环境部署
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HiveJDBC概述
说白了hive它就是一个本地的命令行工具,但是你若想在其它节点来操作当前节点的Hive环境,比如基于JDBC的方式连接hive,则需要使用到HiveJDBC服务啦~
今天我们要说的HiveJDBC的服务端就是HiveServer2,而对应HiveJDBC的客户端就是beeline命令。
二.使用hive命令导入初始化数据
1>.创建测试数据(数据各字段用"\t"隔开,具体的分隔符可以指定,如果此处使用"\t"隔开的,则下面建表时要使用"\t"作为分隔符哟~)

[root@hadoop105.yinzhengjie.com ~]# vim students.txt [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# cat students.txt 1 Jason BeiJing 2 YinZhengjie ShanXi 3 Dilraba XinJiang [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# ll total 4 -rw-r--r-- 1 root root 56 Nov 17 01:53 students.txt [root@hadoop105.yinzhengjie.com ~]#
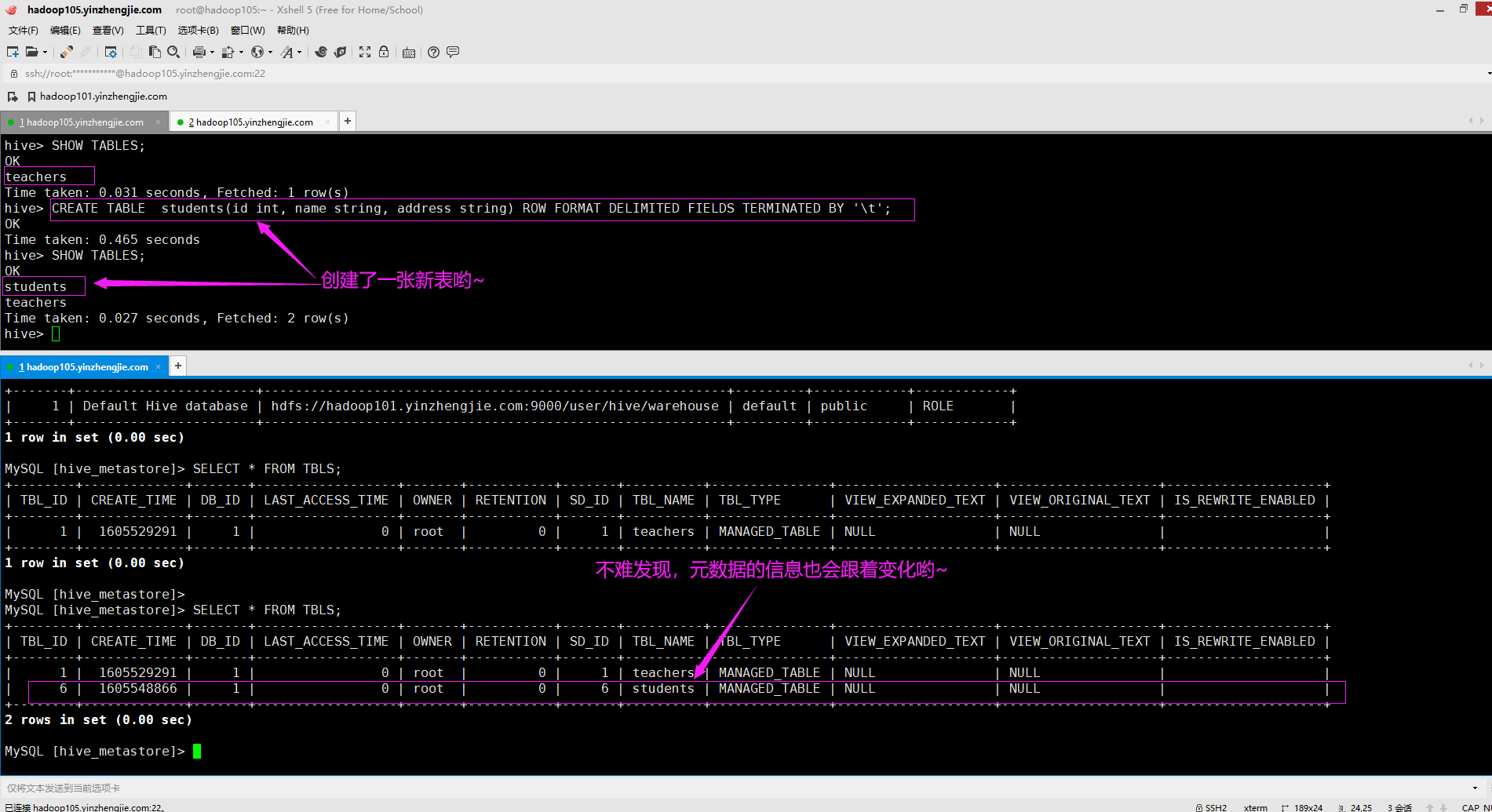
2>.创建一张表,观察元数据库及HDFS集群中的变化(如下图所示)
CREATE TABLE students(id int, name string, address string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
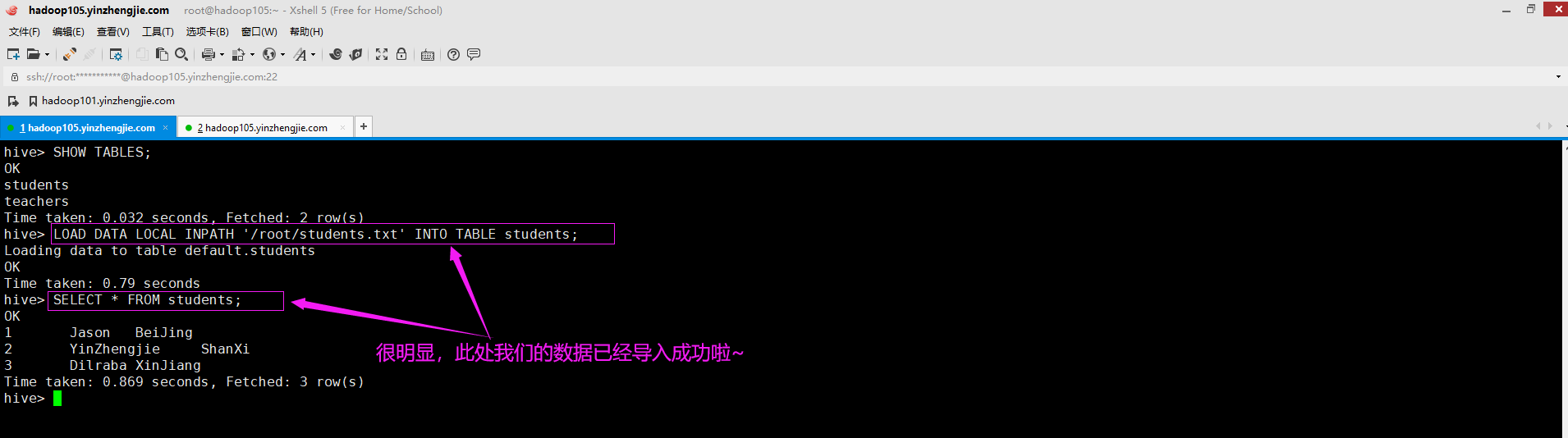
3>.通过hive命令导入数据
LOAD DATA LOCAL INPATH '/root/students.txt' INTO TABLE students;
三.使用beeline连接HiveServer2服务
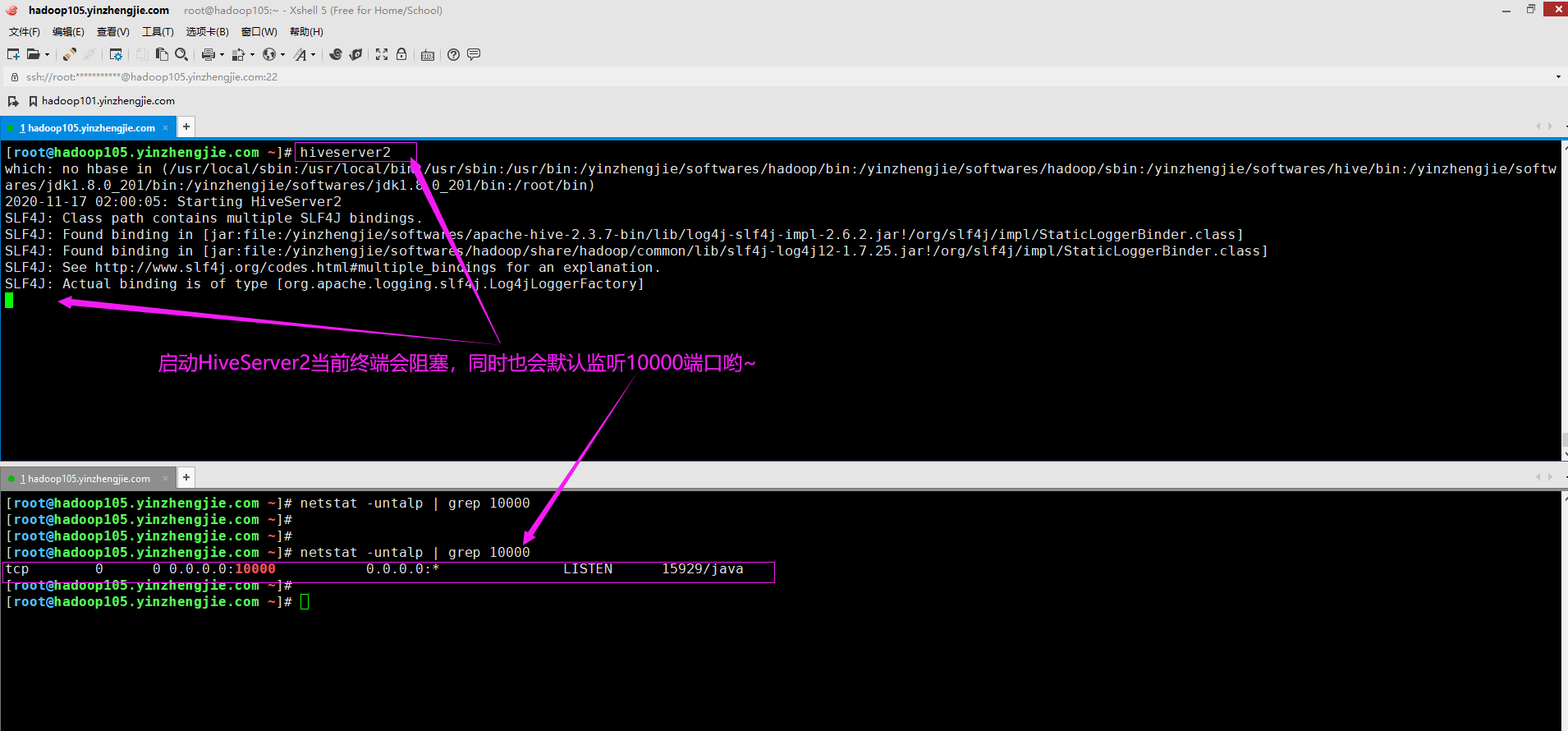
1>.启动HiveJDBC的服务端,即运行HiveServer2程序
[root@hadoop105.yinzhengjie.com ~]# hiveserver2 # 注意哈,此时先不要着急后台运行HiveServer2进程,便于beeline客户端连接时容易观察哟~
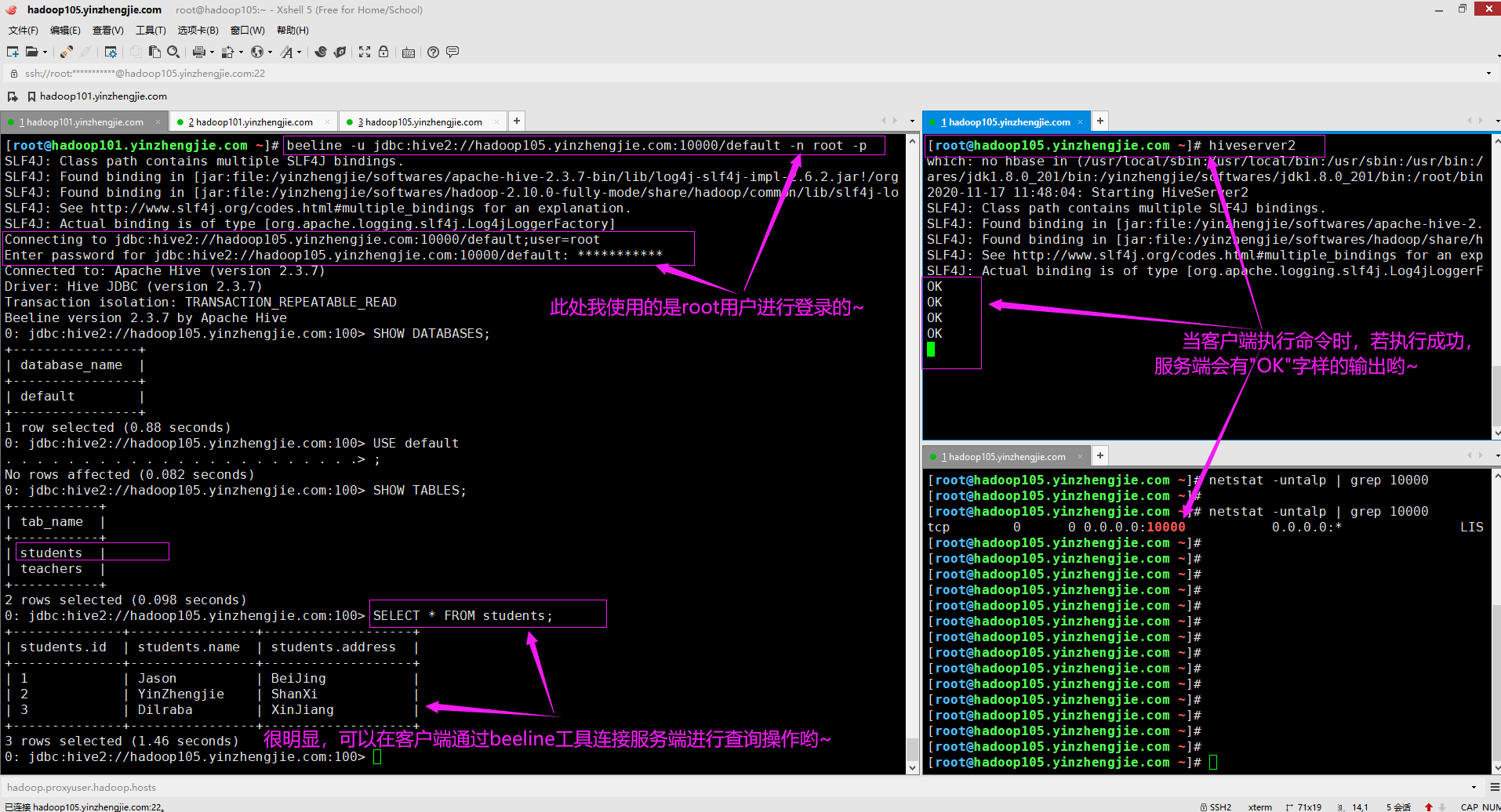
2>.使用beeline客户端进行连接
[root@hadoop101.yinzhengjie.com ~]# beeline -u jdbc:hive2://hadoop105.yinzhengjie.com:10000/default # 我们可以不输入-n和-p选项,若你想要输入root密码也可以参考下图哟~
3>.温馨提示
如果连接失败,请检查Hadoop的核心配置文件是否缺少下面2行参数,若没有请自行添加即可,添加后要重启Hadoop集群,否则可能并不生效哟~ [root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/core-site.xml ...... <!-- 当配置Hive时需要使用下面2个参数哟 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> <description>指定超级用户的代理主机,如果是"*"号,表示所有主机均可,此处的root对应的是root用户,你可以根据实际情况来进行修改哟~</description> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> <description>指定超级用户组,此处的root对应的是root组,你可以根据实际情况来进行修改哟~</description> </property> ...... [root@hadoop101.yinzhengjie.com ~]# 博主推荐阅读: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/Superusers.html
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架