

HDFS元数据管理实战篇
HDFS元数据管理实战篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS元数据概述
1>.什么是HDFS元数据

NameNode的主要工作是存储HDFS命名空间,HDFS元数据(或HDFS命名空间)是由inode(其存储属性,如权限,修改,访问时间和磁盘空间配额)表示的文件和目录的层次结构。命名空间还包括文件到块ID的映射关系。
NameNode存储HDFS元数据,而DataNode存储实际的HDFS数据。当客户端连接到Hadoop读取和写入数据时,它们首先连接到NameNode,从而直到实际数据块存储在哪里或往哪个DataNode写入其数据。。
HDFS元数据包括以下信息:
(1)HDFS文件位置(持久化);
(2)HDFS文件的所有权和权限(持久化);
(3)HDFS数据块的名称(持久化);
(4)HDFS数据块的位置(为持久化,仅在内存中存储,该信息由集群的所有DataNodes节点汇报而来);
温馨提示:
除了上面的第4条,元数据文件fsimage包括以上列出的所有元数据。
2>.检查点
NameNode维护命名空间树,以及将数据块映射到集群中的DataNode。inode和块列表一起定义命名空间的元数据,称为映像(fsimage)。
NameNode将整个映像存储在其内存中,并在NameNode文件系统上存储该映像的记录。命名空间的这个持久记录称为检查点。
NameNode将对HDFS文件系统的更改写入日志,命名为编辑日志。很重要的一点是,仅当NameNode启动,用户请求或者辅助节点或Standby NameNode创建新的检查点时才会改变检查点,否则NameNode在运行时不会改变它的检查点。
当NameNode启动时,它会从磁盘上的检查点初始化命名空间映像,并重播日志中的所有更改。在开始为客户端提供服务之前,他会创建一个新的检查点(fsimage文件)和一个空编辑日志文件。
温馨提示:
fsimage文件包含存储在DataNode上的数据块和HDFS文件之间的映射信息。如果这个文件丢失或损坏,则存储在DataNode上的HDFS数据无法被访问,好像所有的数据已经消失了!
3>.fsimage和编辑日志
当客户端将数据写入HDFS时,写操作会更改HDFS元数据,当然,这些更改将由NameNode记录到编辑日志中。同时,NameNode还将更新其元数据的内存。 每个客户端事务由NameNode记录在预写日志中,NameNode在向客户端发送确认之前刷新并同步编辑日志。 NameNode处理来自集群中多个客户端的请求,因此为了优化将这些事务保存到磁盘的过程,它批处理多个客户端事务。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/13364108.html
二.下载最新的fsimage文件
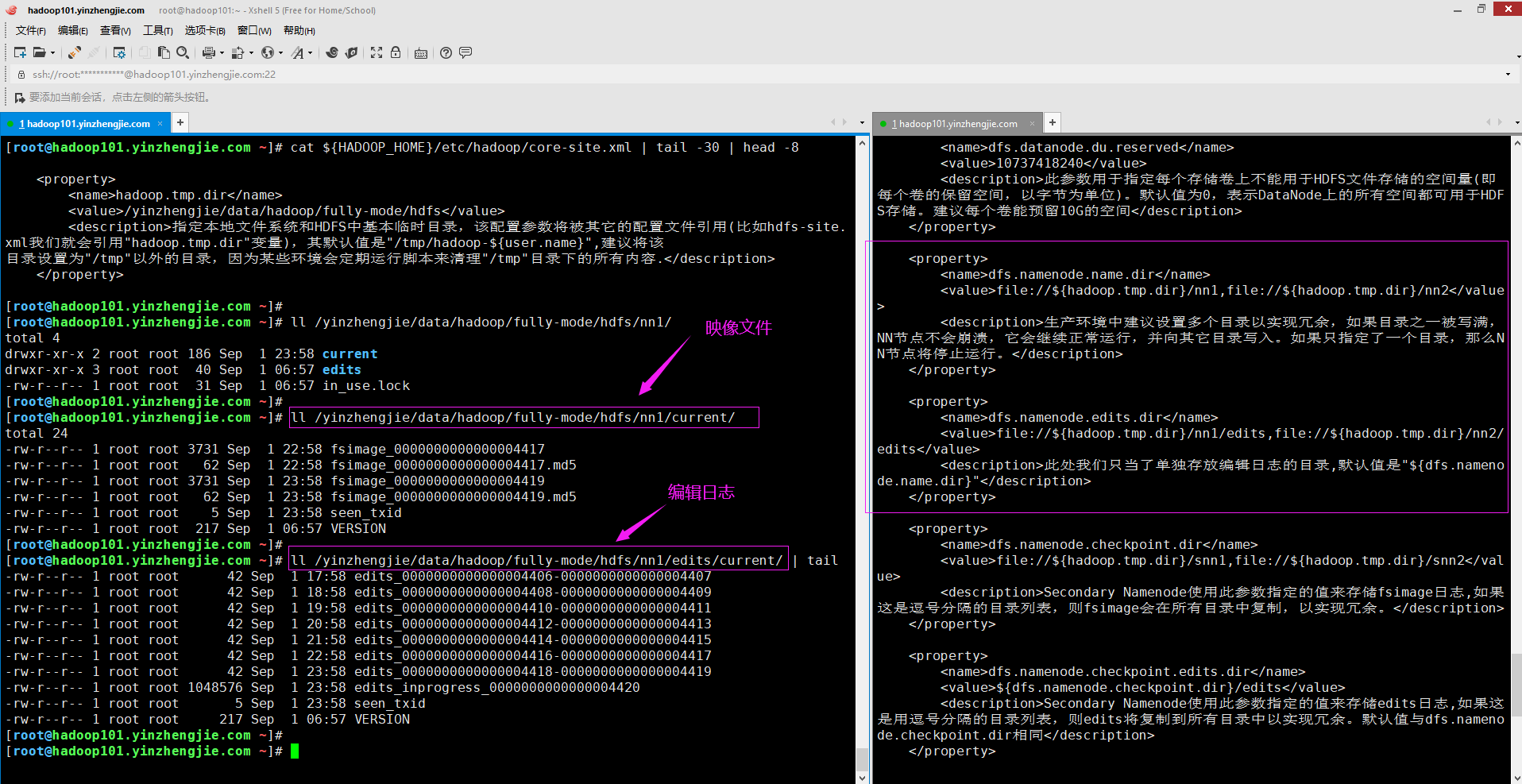
1>.fsimage和编辑日志的存储位置
fsimage和编辑日志时与HDFS元数据相关联的两个关键结构。NameNode将这了两个结构存储在由hdfs-site.xml文件中的配置参数"dfs.namenode.name.dir"(映像文件)和"dfs.namenode.edits.dir"(编辑文件)指定的存储路径。
如下图所示,是我们上面提到的两个参数指定的目录内容。
温馨提示:
Secondary NameNode(或Standby NameNode)具有相同的文件结构。
另外需要注意的是,编辑日志由多个编辑段组成的,每个段都是以"edits_*"开头的文件;fsimage文件当然以"fsimage_*"开头。
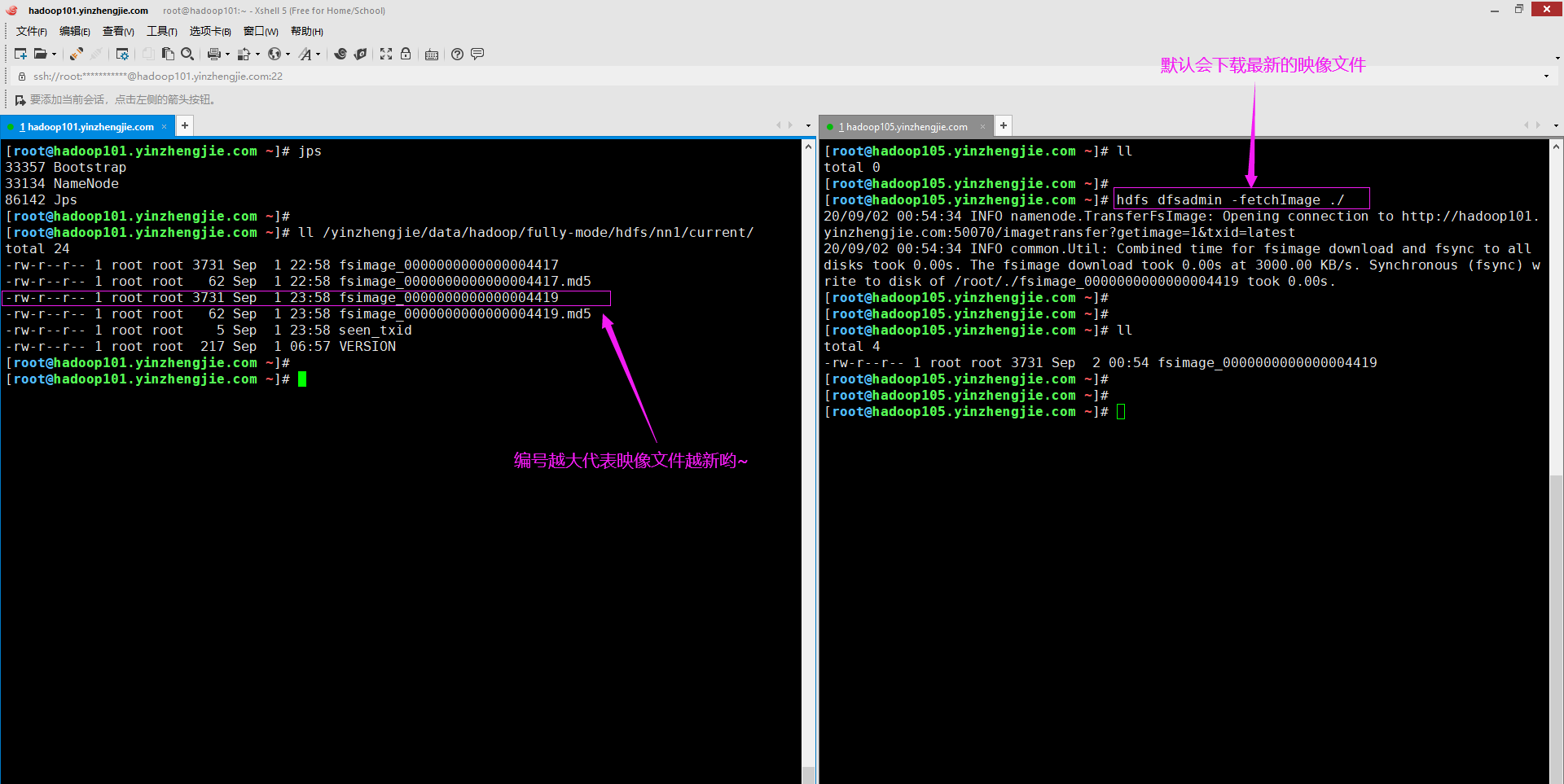
2>.下载最新的映像(fsimage)文件


[root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -help fetchImage -fetchImage <local directory>: Downloads the most recent fsimage from the Name Node and saves it in the specified local directory. [root@hadoop105.yinzhengjie.com ~]#
[root@hadoop105.yinzhengjie.com ~]# ll total 0 [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -fetchImage ./ #下载最新的映像文件到当前目录 20/09/02 00:54:34 INFO namenode.TransferFsImage: Opening connection to http://hadoop101.yinzhengjie.com:50070/imagetransfer?getimage=1&txid=latest 20/09/02 00:54:34 INFO common.Util: Combined time for fsimage download and fsync to all disks took 0.00s. The fsimage download took 0.00s at 3000.00 KB/s. Synchronous (fsync) write to disk of /root/./fsimage_0000000000000004419 took 0.00s. [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# ll total 4 -rw-r--r-- 1 root root 3731 Sep 2 00:54 fsimage_0000000000000004419 [root@hadoop105.yinzhengjie.com ~]#
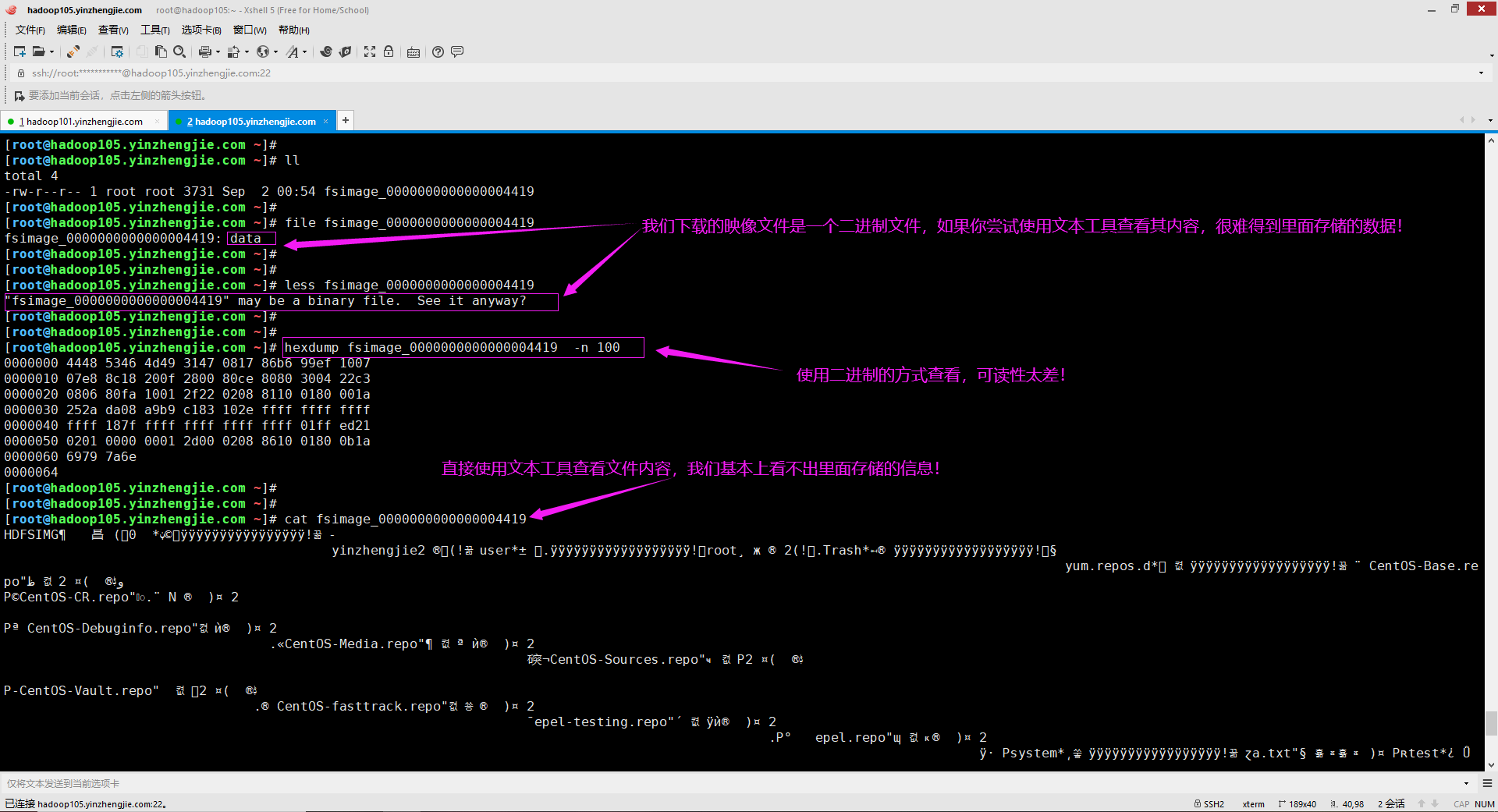
3>.温馨提示
NameNode仅存储文件系统元数据,例如磁盘上fsimage文件中的文件,块,目录和权限信息,它将实际块位置信息保留在内存中。
当客户端读取数据时,NmaeNode会高速客户端文件块所在位置。在这一点上,客户端不需要进一步与NameNode进行关于数据本身传送的通信。
由于NameNode元数据具有的关键性质,因此应配置多个目录作为dfs.namenode.name.dir配置参数的值。在理想情况下,推荐使用NFS设备挂载点,这样做的目的是可以保证数据的冗余性。
三.离线(脱机)映像文件查看器(Offline Image Viewer,简称"oiv")和离线编辑日志查看器(Offline Edits Viewer,简称"oev")
1>.如何查看映像文件的内容呢?
下载映像文件后, 如何查看其内容呢?如下图所示,下载的映像文件其是一个二进制文件,我们不能使用文本工具去查看相应的内容(如果您强行这样做,根本得不到该文件存储的正确信息,如下图所示)。 可以使用离线映像查看器(全称为"Offline Image Viewer",简称"oiv")查看fsimage文件的内容,从而了解集群的命名空间。此工具将fsimage文件的内容转换为人类可读的格式,并允许通过只读WebHDFS API检查HDFS的命名空间。 生产环境中fsimage文件一般都相当大(如果您的集群数据量在刚刚达到PB级别,那么映像文件通常都能达到GB的容量),OIV可以帮助您快速处理文件的内容。正如其名,它可以离线帮咱们查看映像文件。 温馨提示: 上面我们提到了如何下载映像文件,细心的小伙伴估计已经发现了,如果你可以直接登录到NameNode节点,压根就无需下载映像文件。只要到对应的存储目录拷贝一份即可,千万别试图去修改它!(如果你之意要这样做,修改前最好做好备份哟~)
2>.映像文件离线查看器的常见处理器概述
oiv实用程序将尝试解析格式正确的图像文件,如果图像文件格式不正确,则会中止。 该工具脱机工作,不需要在中运行群集以处理图像文件。 提供以下5种常见的映像处理器: XML: 这个处理器创建一个XML文档,其中包含fsimage枚举,适合用XML进一步分析工具。 ReverseXML: 这个处理器接受一个XML文件并创建一个包含相同元素的二进制fsimage。说白了就是XML的反向操作,该工具使用场景相对较少(我直接使用上面XML处理器生成的xml文件作为输入文件来将其转换为映像文件发现有出现失败的迹象)。 FileDistribution: 这个处理器可以分析映像文件的指定内容,可结合以下参数使用: -maxSize: 指定文件大小的范围[0,maxSize]已分析(默认128GB)。 -step: 定义了分发的粒度。(默认为2MB) -format: 以人类可读的方式格式化输出结果而不是字节数。(默认为false)
Web: 运行查看器以公开只读webhdfsapi。可以使用"-addr"指定要侦听的地址。(默认值为"localhost:5978") Delimited(实验性): 生成一个包含所有公共元素的文本文件连接到正在构建的inode和inode,用分隔符分割(默认的分隔符是\t),可以通过-delimiter参数更改。
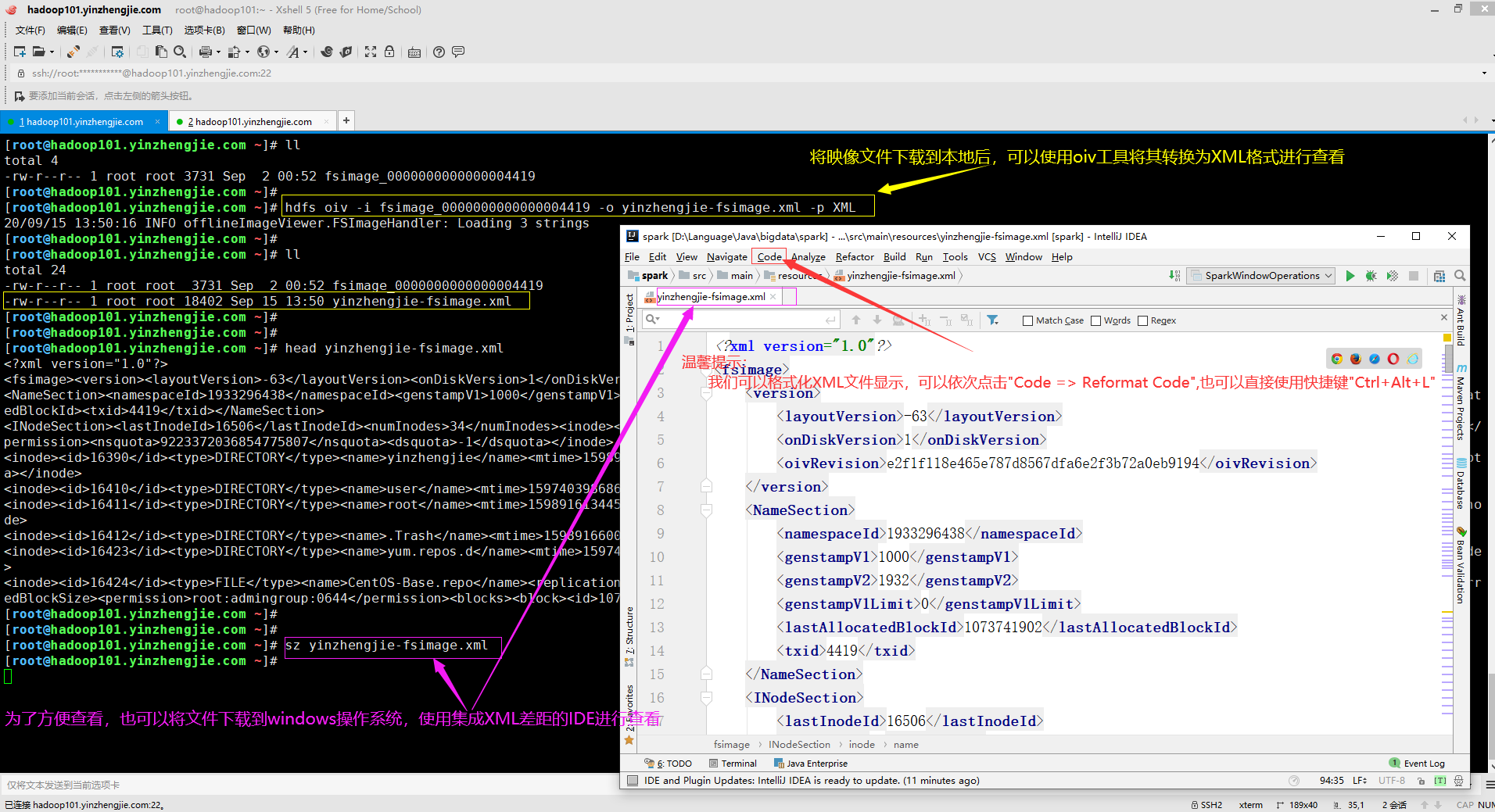
3>.使用oiv工具查询hadoop镜像文件(指定映像处理器为"XML"案例)
[root@hadoop101.yinzhengjie.com ~]# hdfs oiv --help Usage: bin/hdfs oiv [OPTIONS] -i INPUTFILE -o OUTPUTFILE Offline Image Viewer View a Hadoop fsimage INPUTFILE using the specified PROCESSOR, saving the results in OUTPUTFILE. The oiv utility will attempt to parse correctly formed image files and will abort fail with mal-formed image files. The tool works offline and does not require a running cluster in order to process an image file. The following image processors are available: * XML: This processor creates an XML document with all elements of the fsimage enumerated, suitable for further analysis by XML tools. * ReverseXML: This processor takes an XML file and creates a binary fsimage containing the same elements. * FileDistribution: This processor analyzes the file size distribution in the image. -maxSize specifies the range [0, maxSize] of file sizes to be analyzed (128GB by default). -step defines the granularity of the distribution. (2MB by default) -format formats the output result in a human-readable fashion rather than a number of bytes. (false by default) * Web: Run a viewer to expose read-only WebHDFS API. -addr specifies the address to listen. (localhost:5978 by default) * Delimited (experimental): Generate a text file with all of the elements common to both inodes and inodes-under-construction, separated by a delimiter. The default delimiter is \t, though this may be changed via the -delimiter argument. Required command line arguments: -i,--inputFile <arg> FSImage or XML file to process. Optional command line arguments: -o,--outputFile <arg> Name of output file. If the specified file exists, it will be overwritten. (output to stdout by default) If the input file was an XML file, we will also create an <outputFile>.md5 file. -p,--processor <arg> Select which type of processor to apply against image file. (XML|FileDistribution| ReverseXML|Web|Delimited) The default is Web. -delimiter <arg> Delimiting string to use with Delimited processor. -t,--temp <arg> Use temporary dir to cache intermediate result to generate Delimited outputs. If not set, Delimited processor constructs the namespace in memory before outputting text. -h,--help Display usage information and exit [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# ll total 4 -rw-r--r-- 1 root root 3731 Sep 2 00:52 fsimage_0000000000000004419 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs oiv -i fsimage_0000000000000004419 -o yinzhengjie-fsimage.xml -p XML 20/09/15 13:50:16 INFO offlineImageViewer.FSImageHandler: Loading 3 strings [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll total 24 -rw-r--r-- 1 root root 3731 Sep 2 00:52 fsimage_0000000000000004419 -rw-r--r-- 1 root root 18402 Sep 15 13:50 yinzhengjie-fsimage.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# head yinzhengjie-fsimage.xml <?xml version="1.0"?> <fsimage><version><layoutVersion>-63</layoutVersion><onDiskVersion>1</onDiskVersion><oivRevision>e2f1f118e465e787d8567dfa6e2f3b72a0eb9194</oivRevision></version> <NameSection><namespaceId>1933296438</namespaceId><genstampV1>1000</genstampV1><genstampV2>1932</genstampV2><genstampV1Limit>0</genstampV1Limit><lastAllocatedBlockId>1073741902</lastAllocat edBlockId><txid>4419</txid></NameSection><INodeSection><lastInodeId>16506</lastInodeId><numInodes>34</numInodes><inode><id>16385</id><type>DIRECTORY</type><name></name><mtime>1598003240154</mtime><permission>root:admingroup:0755</ permission><nsquota>9223372036854775807</nsquota><dsquota>-1</dsquota></inode><inode><id>16390</id><type>DIRECTORY</type><name>yinzhengjie</name><mtime>1598917806068</mtime><permission>root:admingroup:0755</permission><nsquota>50</nsquota><dsquota>10737418240</dsquot a></inode><inode><id>16410</id><type>DIRECTORY</type><name>user</name><mtime>1597403986865</mtime><permission>root:admingroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16411</id><type>DIRECTORY</type><name>root</name><mtime>1598916134456</mtime><permission>root:admingroup:0700</permission><nsquota>50</nsquota><dsquota>10737418240</dsquota></ino de><inode><id>16412</id><type>DIRECTORY</type><name>.Trash</name><mtime>1598916600051</mtime><permission>root:admingroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16423</id><type>DIRECTORY</type><name>yum.repos.d</name><mtime>1597417995606</mtime><permission>root:admingroup:0755</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode ><inode><id>16424</id><type>FILE</type><name>CentOS-Base.repo</name><replication>2</replication><mtime>1597417995351</mtime><atime>1598855537752</atime><preferredBlockSize>536870912</preferr edBlockSize><permission>root:admingroup:0644</permission><blocks><block><id>1073741839</id><genstamp>1015</genstamp><numBytes>1664</numBytes></block>[root@hadoop101.yinzhengjie.com ~]#
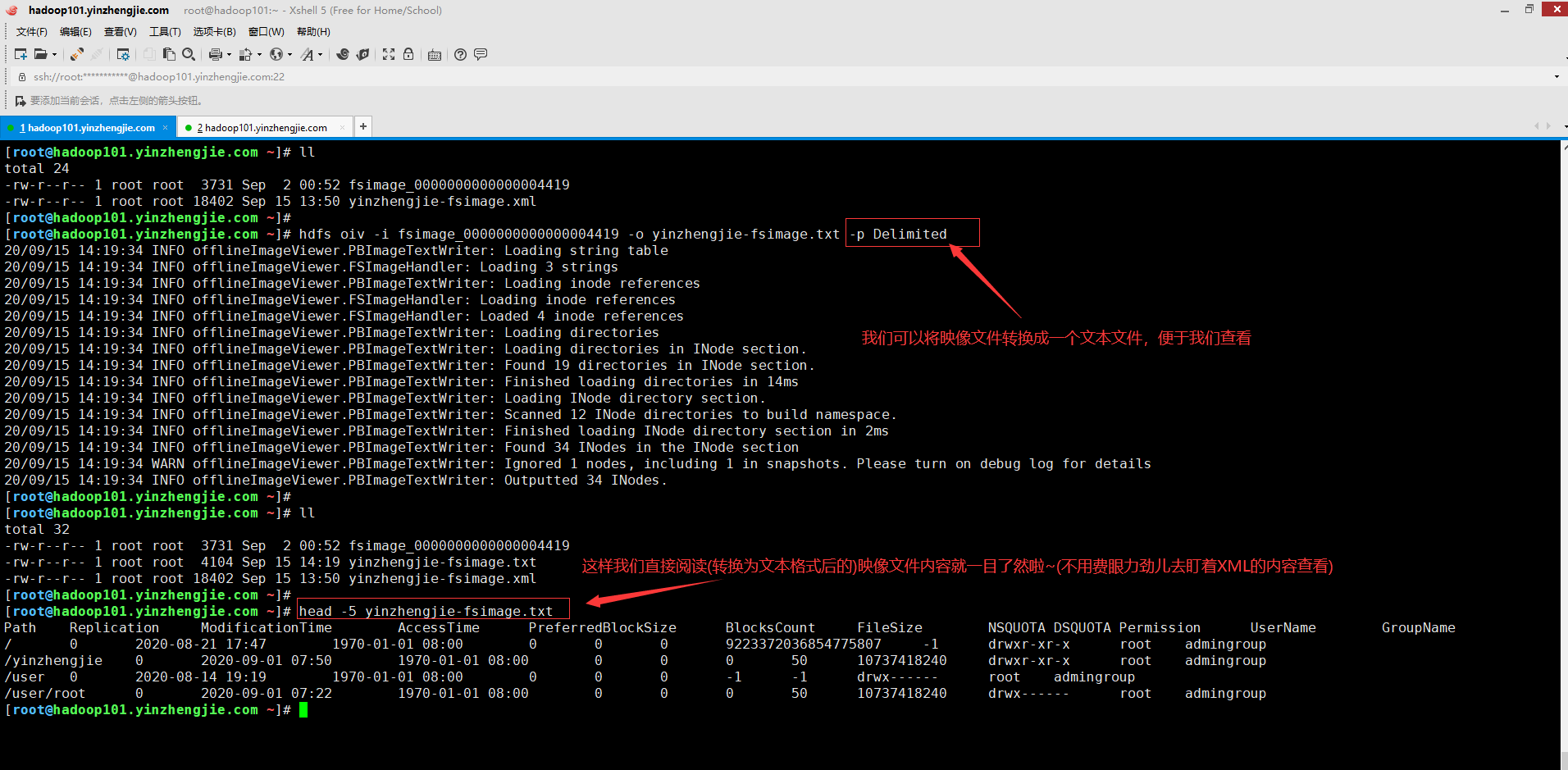
4>.使用oiv工具查询hadoop镜像文件(指定映像处理器为"Delimited "案例)
[root@hadoop101.yinzhengjie.com ~]# ll total 24 -rw-r--r-- 1 root root 3731 Sep 2 00:52 fsimage_0000000000000004419 -rw-r--r-- 1 root root 18402 Sep 15 13:50 yinzhengjie-fsimage.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs oiv -i fsimage_0000000000000004419 -o yinzhengjie-fsimage.txt -p Delimited 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Loading string table 20/09/15 14:19:34 INFO offlineImageViewer.FSImageHandler: Loading 3 strings 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Loading inode references 20/09/15 14:19:34 INFO offlineImageViewer.FSImageHandler: Loading inode references 20/09/15 14:19:34 INFO offlineImageViewer.FSImageHandler: Loaded 4 inode references 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Loading directories 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Loading directories in INode section. 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Found 19 directories in INode section. 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Finished loading directories in 14ms 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Loading INode directory section. 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Scanned 12 INode directories to build namespace. 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Finished loading INode directory section in 2ms 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Found 34 INodes in the INode section 20/09/15 14:19:34 WARN offlineImageViewer.PBImageTextWriter: Ignored 1 nodes, including 1 in snapshots. Please turn on debug log for details 20/09/15 14:19:34 INFO offlineImageViewer.PBImageTextWriter: Outputted 34 INodes. [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll total 32 -rw-r--r-- 1 root root 3731 Sep 2 00:52 fsimage_0000000000000004419 -rw-r--r-- 1 root root 4104 Sep 15 14:19 yinzhengjie-fsimage.txt -rw-r--r-- 1 root root 18402 Sep 15 13:50 yinzhengjie-fsimage.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# head -5 yinzhengjie-fsimage.txt Path Replication ModificationTime AccessTime PreferredBlockSize BlocksCount FileSize NSQUOTA DSQUOTA Permission UserName GroupName / 0 2020-08-21 17:47 1970-01-01 08:00 0 0 0 9223372036854775807 -1 drwxr-xr-x root admingroup /yinzhengjie 0 2020-09-01 07:50 1970-01-01 08:00 0 0 0 50 10737418240 drwxr-xr-x root admingroup /user 0 2020-08-14 19:19 1970-01-01 08:00 0 0 0 -1 -1 drwx------ root admingroup /user/root 0 2020-09-01 07:22 1970-01-01 08:00 0 0 0 50 10737418240 drwx------ root admingroup [root@hadoop101.yinzhengjie.com ~]#
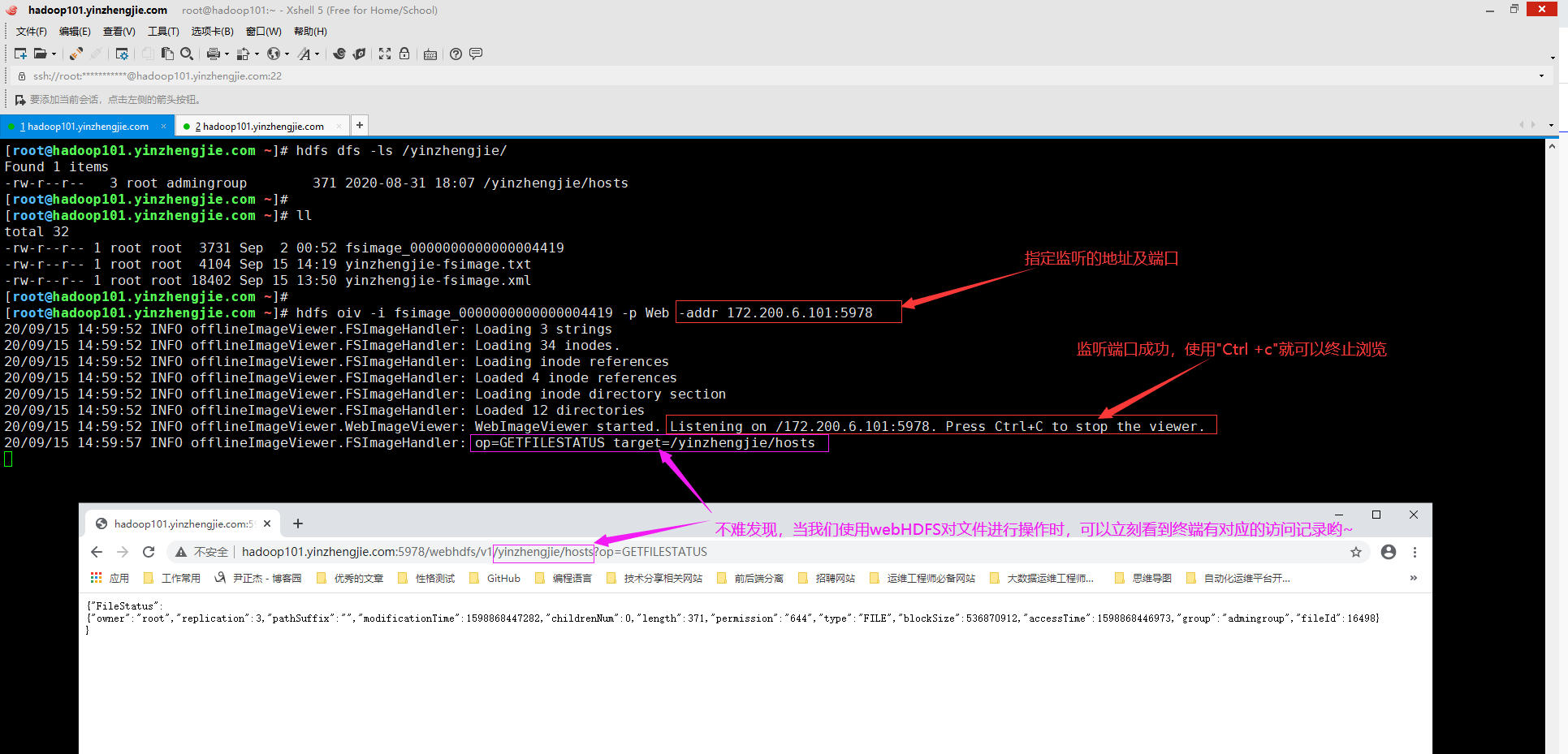
5>.使用oiv工具查询hadoop镜像文件(指定映像处理器为"Web"案例)
[root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls /yinzhengjie/ #首先向大家确认我的集群是有该文件的,然后将最新的镜像文件下载到本地进行下面的操作即可 Found 1 items -rw-r--r-- 3 root admingroup 371 2020-08-31 18:07 /yinzhengjie/hosts [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hostname -i 172.200.6.101 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll total 32 -rw-r--r-- 1 root root 3731 Sep 2 00:52 fsimage_0000000000000004419 -rw-r--r-- 1 root root 4104 Sep 15 14:19 yinzhengjie-fsimage.txt -rw-r--r-- 1 root root 18402 Sep 15 13:50 yinzhengjie-fsimage.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs oiv -i fsimage_0000000000000004419 -p Web -addr 172.200.6.101:5978 20/09/15 14:59:52 INFO offlineImageViewer.FSImageHandler: Loading 3 strings 20/09/15 14:59:52 INFO offlineImageViewer.FSImageHandler: Loading 34 inodes. 20/09/15 14:59:52 INFO offlineImageViewer.FSImageHandler: Loading inode references 20/09/15 14:59:52 INFO offlineImageViewer.FSImageHandler: Loaded 4 inode references 20/09/15 14:59:52 INFO offlineImageViewer.FSImageHandler: Loading inode directory section 20/09/15 14:59:52 INFO offlineImageViewer.FSImageHandler: Loaded 12 directories 20/09/15 14:59:52 INFO offlineImageViewer.WebImageViewer: WebImageViewer started. Listening on /172.200.6.101:5978. Press Ctrl+C to stop the viewer. 20/09/15 14:59:57 INFO offlineImageViewer.FSImageHandler: op=GETFILESTATUS target=/yinzhengjie/hosts
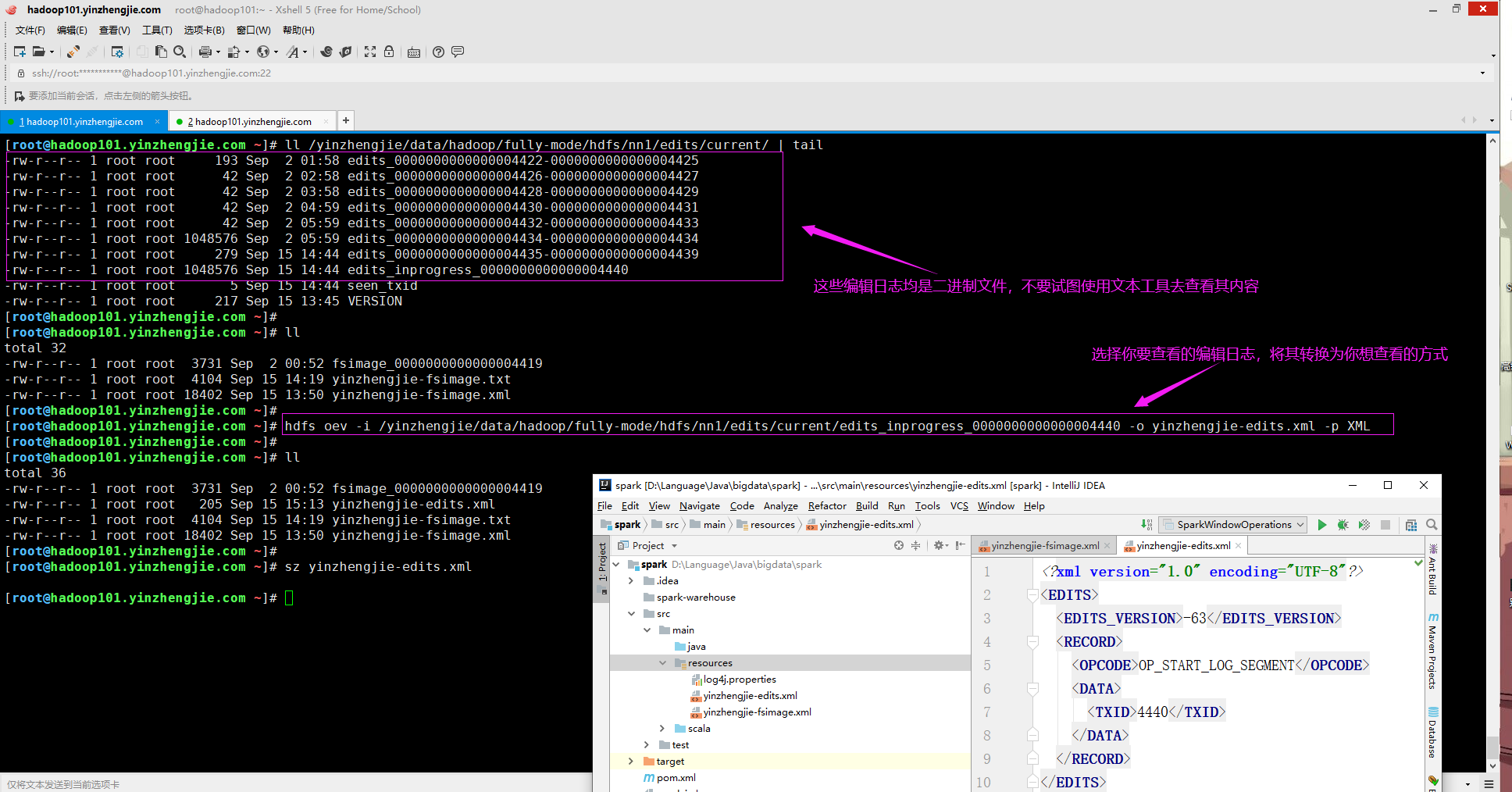
6>.使用oev工具查询hadoop的编辑日志文件
[root@hadoop101.yinzhengjie.com ~]# hdfs oev --help Usage: bin/hdfs oev [OPTIONS] -i INPUT_FILE -o OUTPUT_FILE Offline edits viewer Parse a Hadoop edits log file INPUT_FILE and save results in OUTPUT_FILE. Required command line arguments: -i,--inputFile <arg> edits file to process, xml (case insensitive) extension means XML format, any other filename means binary format. XML/Binary format input file is not allowed to be processed by the same type processor. -o,--outputFile <arg> Name of output file. If the specified file exists, it will be overwritten, format of the file is determined by -p option Optional command line arguments: -p,--processor <arg> Select which type of processor to apply against image file, currently supported processors are: binary (native binary format that Hadoop uses), xml (default, XML format), stats (prints statistics about edits file) -h,--help Display usage information and exit -f,--fix-txids Renumber the transaction IDs in the input, so that there are no gaps or invalid transaction IDs. -r,--recover When reading binary edit logs, use recovery mode. This will give you the chance to skip corrupt parts of the edit log. -v,--verbose More verbose output, prints the input and output filenames, for processors that write to a file, also output to screen. On large image files this will dramatically increase processing time (default is false). Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines The general command line syntax is: command [genericOptions] [commandOptions] [root@hadoop101.yinzhengjie.com ~]#
root@hadoop101.yinzhengjie.com ~]# ll /yinzhengjie/data/hadoop/fully-mode/hdfs/nn1/edits/current/ | tail -rw-r--r-- 1 root root 193 Sep 2 01:58 edits_0000000000000004422-0000000000000004425 -rw-r--r-- 1 root root 42 Sep 2 02:58 edits_0000000000000004426-0000000000000004427 -rw-r--r-- 1 root root 42 Sep 2 03:58 edits_0000000000000004428-0000000000000004429 -rw-r--r-- 1 root root 42 Sep 2 04:59 edits_0000000000000004430-0000000000000004431 -rw-r--r-- 1 root root 42 Sep 2 05:59 edits_0000000000000004432-0000000000000004433 -rw-r--r-- 1 root root 1048576 Sep 2 05:59 edits_0000000000000004434-0000000000000004434 -rw-r--r-- 1 root root 279 Sep 15 14:44 edits_0000000000000004435-0000000000000004439 -rw-r--r-- 1 root root 1048576 Sep 15 14:44 edits_inprogress_0000000000000004440 -rw-r--r-- 1 root root 5 Sep 15 14:44 seen_txid -rw-r--r-- 1 root root 217 Sep 15 13:45 VERSION [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll total 32 -rw-r--r-- 1 root root 3731 Sep 2 00:52 fsimage_0000000000000004419 -rw-r--r-- 1 root root 4104 Sep 15 14:19 yinzhengjie-fsimage.txt -rw-r--r-- 1 root root 18402 Sep 15 13:50 yinzhengjie-fsimage.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs oev -i /yinzhengjie/data/hadoop/fully-mode/hdfs/nn1/edits/current/edits_inprogress_0000000000000004440 -o yinzhengjie-edits.xml -p XML [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll total 36 -rw-r--r-- 1 root root 3731 Sep 2 00:52 fsimage_0000000000000004419 -rw-r--r-- 1 root root 205 Sep 15 15:13 yinzhengjie-edits.xml -rw-r--r-- 1 root root 4104 Sep 15 14:19 yinzhengjie-fsimage.txt -rw-r--r-- 1 root root 18402 Sep 15 13:50 yinzhengjie-fsimage.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# sz yinzhengjie-edits.xml [root@hadoop101.yinzhengjie.com ~]#
四.备份和恢复NameNode元数据
由于NameNode元数据对集群操作是非常关键的数据,因此应该定期备份。接下来我们来实战操作一下如何备份数据。
1>.将集群置于安全模式
关于HDFS集群的安全模式可以参考我之前的笔记,我这里就不罗嗦啦。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/13378967.html
[root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -safemode get Safe mode is OFF [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -safemode enter Safe mode is ON [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -safemode get Safe mode is ON [root@hadoop105.yinzhengjie.com ~]#

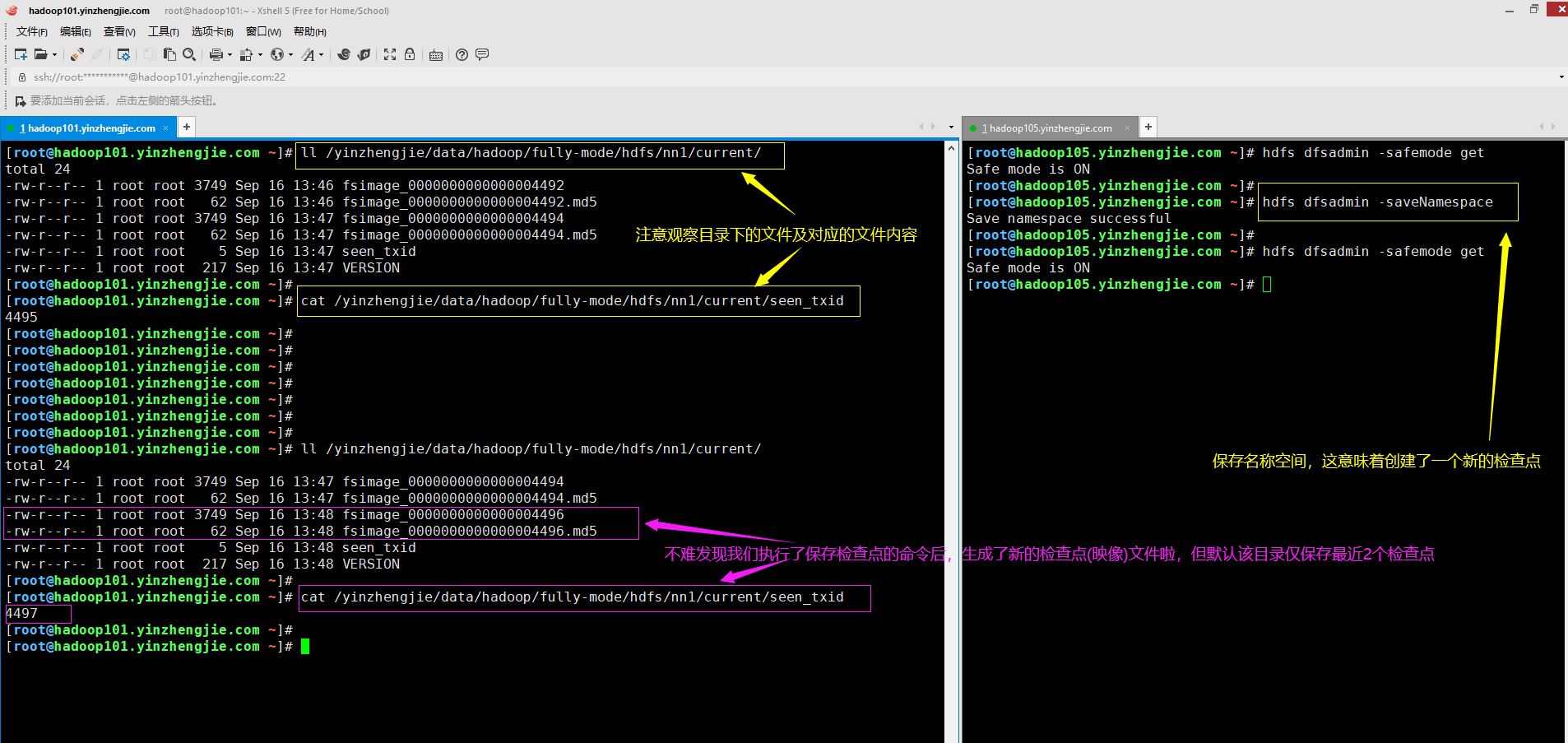
2>.使用"-saveNamespace"命令备份元数据(手动生成新的检查点,即fsimage文件)
温馨提示: "-saveNamespace"命令将当前命名空间(HDFS在内存中的元数据)保存到磁盘,并重置编辑日志。
由于此命令要求HDFS处于安全模式,因此必须在执行"-saveNamespace"命令行确保退出安全模式。
[root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -help saveNamespace -saveNamespace: Save current namespace into storage directories and reset edits log. Requires safe mode. [root@hadoop105.yinzhengjie.com ~]#
[root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -safemode get Safe mode is ON [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -saveNamespace Save namespace successful [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -safemode get Safe mode is ON [root@hadoop105.yinzhengjie.com ~]#
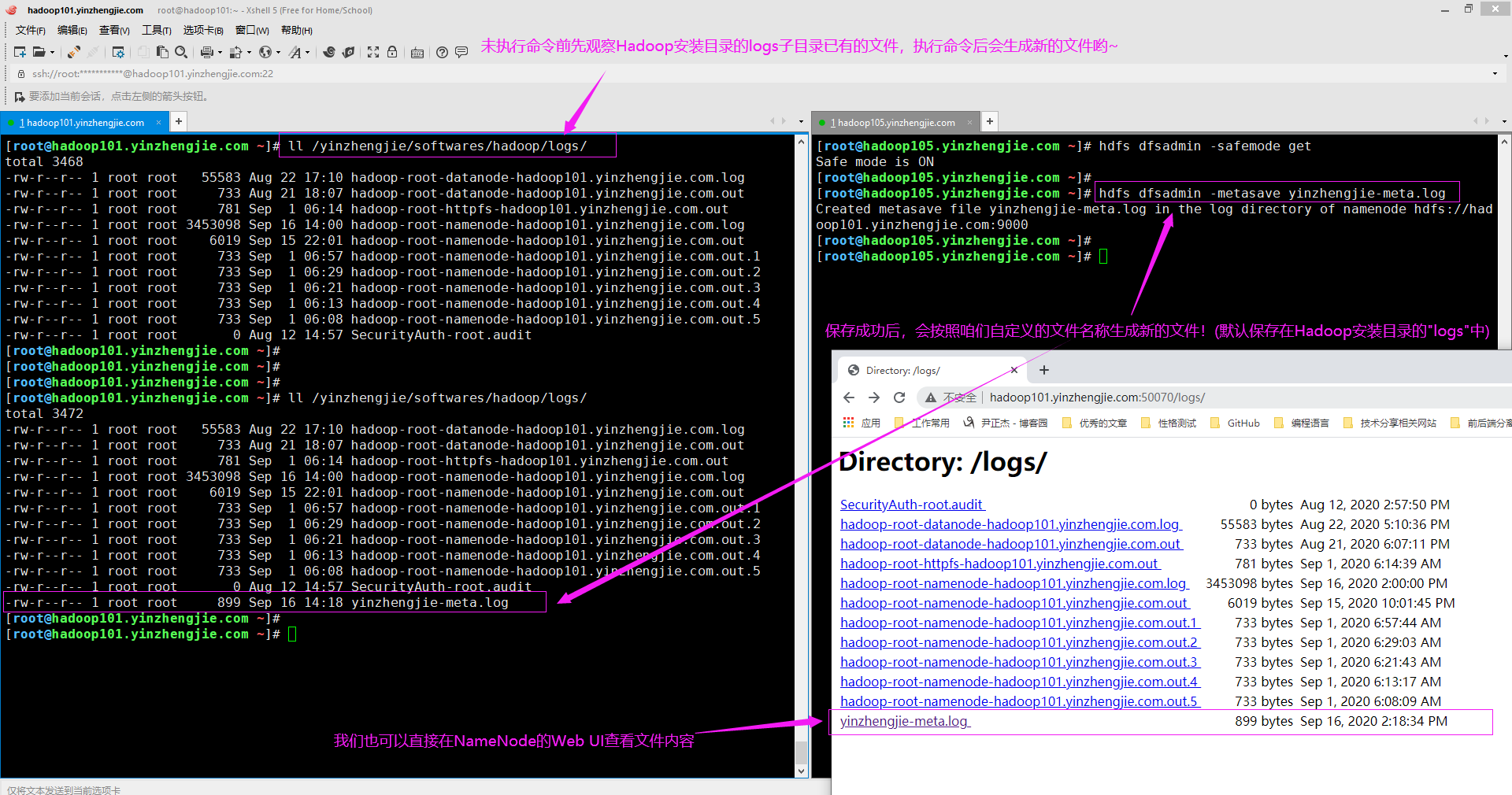
3>.使用"-metasave"命令将NameNode主结构保存到文本文件
温馨提示:
如下图所示,在此示例中,dfsadmin -metasave命令将以下初始数据结构存储到"${HADOOP_HOME}/logs/"目录中名为"yinzhengjie-meta.log"的文件中。
编辑元数据文件不是一个好的习惯,因为可能会丢失数据。例如,VERSION文件保护在NameNode上注册的不同命名空间的DataNode信息。这是一个内置的安全机制,通过编辑VERSION文件来匹配DataNode和NameNode的命名空间ID,可能会破坏数据哟。
[root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -help metasave -metasave <filename>: Save Namenode's primary data structures to <filename> in the directory specified by hadoop.log.dir property. <filename> is overwritten if it exists. <filename> will contain one line for each of the following 1. Datanodes heart beating with Namenode 2. Blocks waiting to be replicated 3. Blocks currrently being replicated 4. Blocks waiting to be deleted [root@hadoop105.yinzhengjie.com ~]#
[root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -safemode get Safe mode is ON [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# hdfs dfsadmin -metasave yinzhengjie-meta.log Created metasave file yinzhengjie-meta.log in the log directory of namenode hdfs://hadoop101.yinzhengjie.com:9000 [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]#
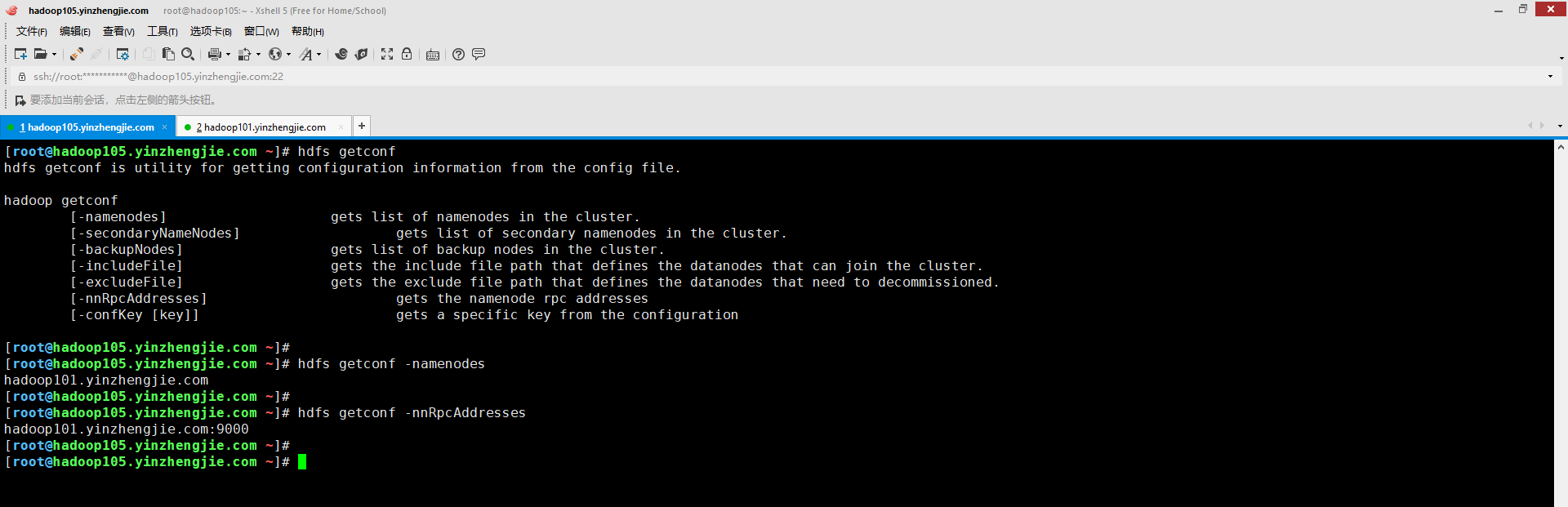
五.使用getconf命令获取NameNode配置信息
可使用hdfs getconf使用程序来获取NameNode配置信息,如下图所示。
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架