
Spark Streaming概述
Spark Streaming概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Spark Streaming概览
1>.什么是Spark Streaming
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。
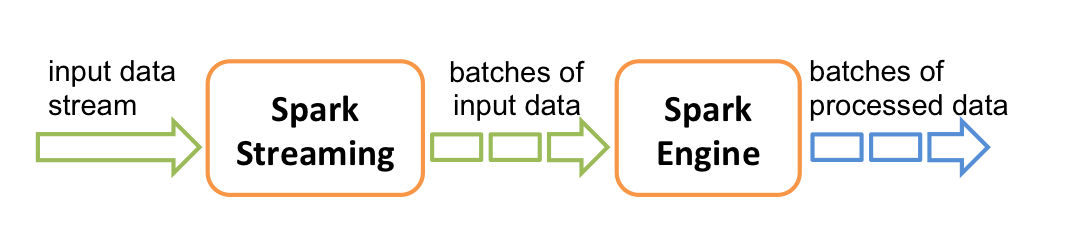
如下图所示,Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ,Kinesis,HDFS,简单的TCP套接字,甚至你还可以自定义数据源等等。
数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。
最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。
实际上,您可以在数据流上应用Spark的机器学习和图形处理算法。

在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分为批次,然后由Spark引擎进行处理,以生成批次的最终结果流。
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而DStream是由这些RDD所组成的序列(因此得名“离散化”)。 Spark Streaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。DStreams可以根据来自Kafka和Kinesis等来源的输入数据流来创建,也可以通过对其他DStreams应用高级操作来创建。在内部,DStream表示为RDD序列。 博主推荐阅读: http://spark.apache.org/docs/latest/streaming-programming-guide.html
2>.Spark Streaming的特点
易用:
Spark Streaming将Apache Spark的 语言集成API 引入流处理,使您可以像编写批处理作业一样编写流作业。它支持Java,Scala和Python。
容错:
Spark Streaming可以立即恢复丢失的工作和操作员状态(例如,滑动窗口),而无需任何额外的代码。
易整合到Spark体系:
通过在Spark上运行,Spark Streaming可让您将相同的代码重用于批处理,针对历史数据加入流或对流状态运行临时查询。构建功能强大的交互式应用程序,而不仅仅是分析。
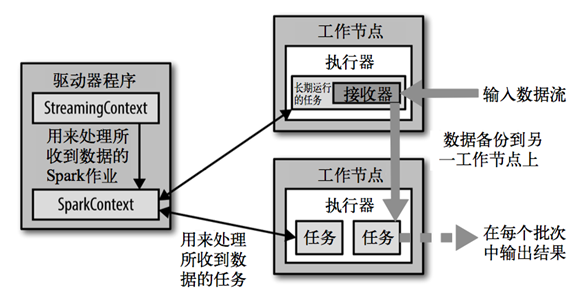
3>.Spark Streaming架构
二.DStream入门案例(wordcount)
需求说明:
使用netcat工具向8888端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数。
1>.添加依赖关系
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.1.1</version> </dependency>
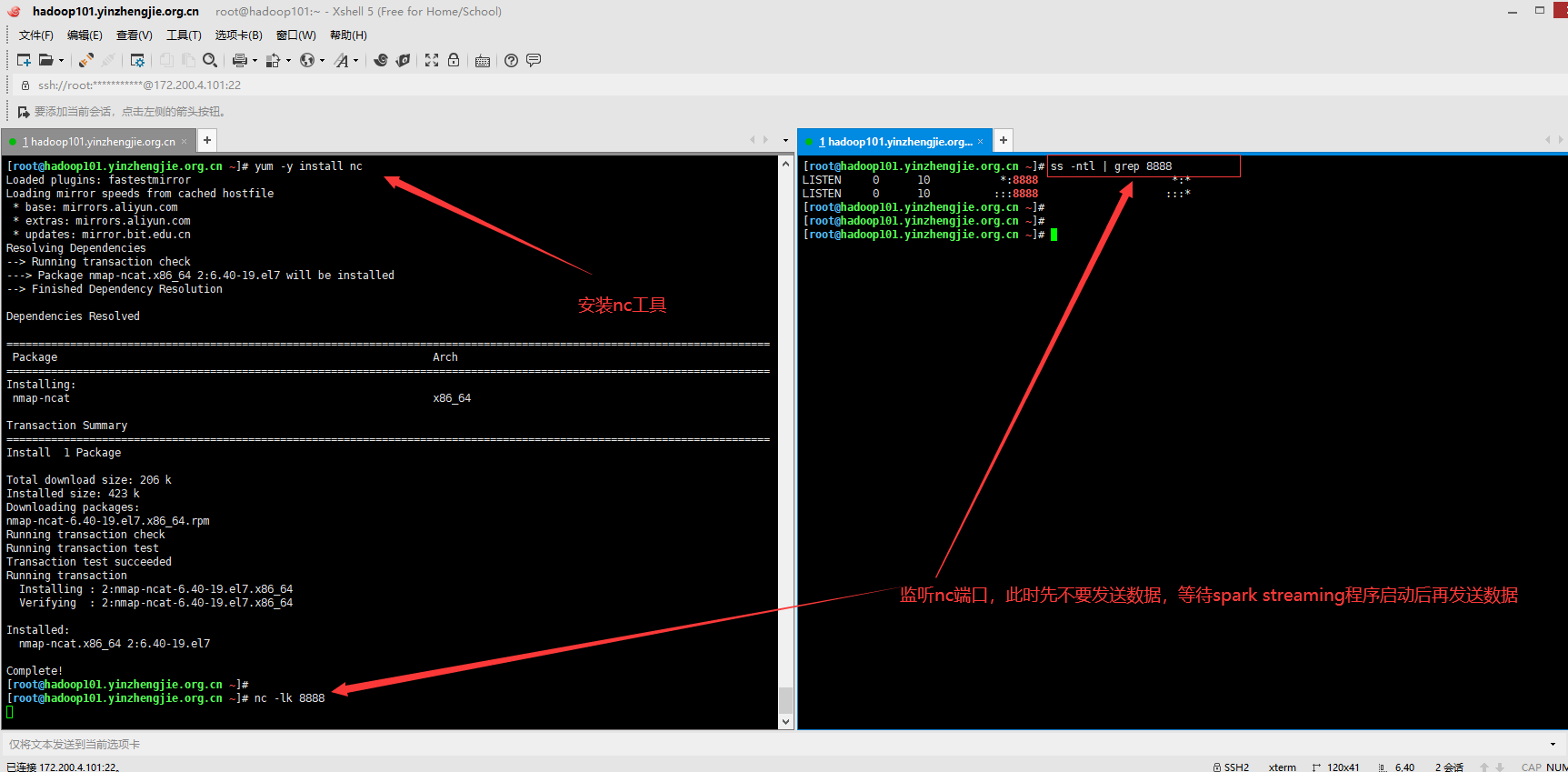
2>.安装netcat工具并监听相应端口


[root@hadoop101.yinzhengjie.org.cn ~]# yum -y install nc Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirror.bit.edu.cn Resolving Dependencies --> Running transaction check ---> Package nmap-ncat.x86_64 2:6.40-19.el7 will be installed --> Finished Dependency Resolution Dependencies Resolved ============================================================================================================================================================================================================================================================================== Package Arch Version Repository Size ============================================================================================================================================================================================================================================================================== Installing: nmap-ncat x86_64 2:6.40-19.el7 base 206 k Transaction Summary ============================================================================================================================================================================================================================================================================== Install 1 Package Total download size: 206 k Installed size: 423 k Downloading packages: nmap-ncat-6.40-19.el7.x86_64.rpm | 206 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : 2:nmap-ncat-6.40-19.el7.x86_64 1/1 Verifying : 2:nmap-ncat-6.40-19.el7.x86_64 1/1 Installed: nmap-ncat.x86_64 2:6.40-19.el7 Complete! [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# nc -lk 8888 #监听端口
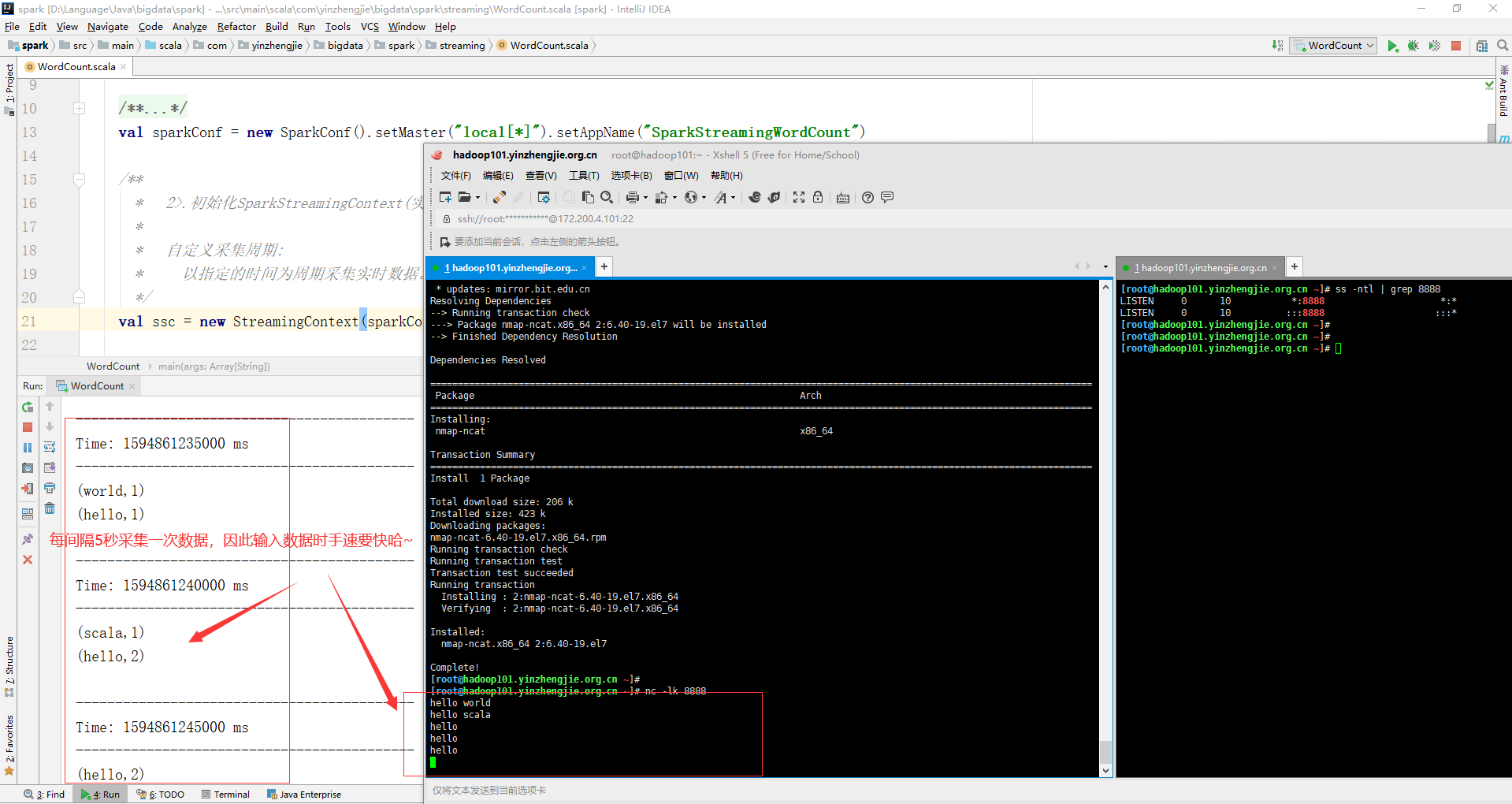
3>.编写wordcount代码
package com.yinzhengjie.bigdata.spark.streaming import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} object WordCount { def main(args: Array[String]): Unit = { /** * 1>.初始化Spark配置信息 */ val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingWordCount") /** * 2>.初始化SparkStreamingContext(实时数据分析环境对象) * * 自定义采集周期: * 以指定的时间为周期采集实时数据。我这里指定采集周期是5秒.生产环境中我们可以将这个值改小,比如每秒采集一次. */ val ssc = new StreamingContext(sparkConf, Seconds(5)) /** * 3>.通过监控端口创建DStream,读进来的数据为一行行(即从指定端口中采集数据) */ val socketLineDStream:ReceiverInputDStream[String] = ssc.socketTextStream("hadoop101.yinzhengjie.org.cn", 8888) /** * 4>.将采集的数据进行扁平化操作(即将每一行数据做切分,形成一个个单词) */ val wordDStreams:DStream[String] = socketLineDStream.flatMap(_.split(" ")) /** * 5>.将数据进行结构的转换方便统计分析(即将单词映射成元组(word,1)) */ val wordAndOneStreams:DStream[(String,Int)] = wordDStreams.map((_, 1)) /** * 6>.将相同的单词次数做统计 */ val wordToCountDStream:DStream[(String,Int)] = wordAndOneStreams.reduceByKey(_+_) /** * 7>.将结果打印出来 */ wordToCountDStream.print() /** * 8>.启动(SparkStreamingContext)采集器 */ ssc.start() /** * 9>.Driver等待采集器的执行(即禁止main线程主动退出) */ ssc.awaitTermination() /** * 温馨提示: * 咱们的程序是实时处理数据的,因此生产环境中不能停止采集程序,因此不建议使用哟~ */ // ssc.stop() } }
三.博主推荐阅读
Spark Streaming-DStream实战案例: https://www.cnblogs.com/yinzhengjie2020/p/13233192.html
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186
