
Elastic Stack技术栈概述
Elastic Stack技术栈概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.搜索引擎概述
1>.什么是搜索引擎
搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。目前在全球比较出名的2款搜索引擎莫过于Google和baidu啦!当然,我们站点内部也需要搜索引擎,最常见的比如日志分析系统。搜索引擎是我们常见而且通用的需求。
简单的说,搜索引擎是由索引组件和搜索组件两部分组成。
索引组件是面向数据存储和索引构建,在索引组件比较出名就是Lucene和Sphinx;
搜索组件是面向用户提供搜索功能以及将用户提供的搜索请求转换成可用的查询语句并通过索引完成查询过程(或搜索过程),在搜索组件比较出名的就是ElasticSearch,Solr,Nutch,Hermes。
温馨提示:
对于搜索引擎来讲,有一个著名的索引类型叫做倒排索引。倒排索引的作用主要是通过关键词去查对应文档的。不像我们有一个表去找某一行数据。
2>.优秀的开源搜索引擎
Lucene: (1)Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
(2)Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。 (3)Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。
(4)Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
(5)在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。 Sphinx: (1)Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索;
(2)Sphinx可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索;
(3)Sphinx特别为一些脚本语言设计搜索API接口,如PHP,Python,Perl,Ruby等,同时为MySQL也设计了一个存储引擎插件;
(4)Sphinx 单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级);
(5)Sphinx创建索引的速度为:创建100万条记录的索引只需 3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒; Sphinx的主要特性包括:
高速索引(在新款CPU上,近10 MB/秒);
高速搜索(2-4G的文本量中平均查询速度不到0.1秒);
高可用性(单CPU上最大可支持100 GB的文本,100M文档);
提供良好的相关性排名 支持分布式搜索;
提供文档摘要生成;
提供从MySQL内部的插件式存储引擎上搜索;
支持布尔,短语,和近义词查询;
支持每个文档多个全文检索域(默认最大32个);
支持每个文档多属性;
支持断词;
支持单字节编码与UTF-8编码。
二.Elastic Stack概述
早期Elastic Stack名为ELK,对应Elasticsearch,Logstash,Kibana这三个开源软件,但由于在做日志收集时Logstash过于重量级,因此官方又开发了各种Beat组件,比如FileBeat,PackBeat等等。随着这些角色的加入ELK更名位Elastic Stack。 Elastic Stack组件的主要优点有如下几个: (1)处理方式灵活: Elasticsearch是实时全文索引,具有强大的搜索功能。 (2)配置相对简单: Elasticsearch全部使用JSON接口,Logstash使用模块配置,Kibana的配置文件部分更简单。 (3)检索性能高效: 基于优秀的设计,虽然每次查询都是实时,但是也可以达到百万级数据的查询查询秒级响应。 (4)集群线性扩展: Elasticsearch和Logstash都可以灵活线性扩展。 (5)前端操作绚丽: Kibana的前端设计比较绚丽,而且操作简单。 为什么要用Elastic Stack组件? Elastic Stack组件在海量日志系统运维中,可以用于解决以下主要问题: (1)分布式日志数据统一收集,实现集中式查询和管理; (2)故障排除; (3)安全信息和事件管理; (4)报表功能; Elastic Stack在大数据运维系统中,主要可解决的问题如下: (1)日志查询,问题排查,故障恢复,故障自愈; (2)应用日志分析,错误报警; (3)性能分析,用户行为分析; 官网地址: https://www.elastic.co/cn/ 官方文档: https://www.elastic.co/guide/index.html
三.Elasticsearch概述
1>.什么是ElasticSearch
ElasticSearch就是基于Lucene的API封装成了一个搜索组件。但是除了搜索功能以外,ElasticSearch还提供了一些更强大的功能。ElasticSearch在Lucene所提供的API基础之上又额外新增了把自己构建为分布式。换句话说,ElasticSearch能够分布式的将Lucene所提供的索引组建成Shards的形式,分片分布于多个节点上,从而构建成分布式实时查询组件。 上面我们用自己的话说了一下ES的概念,接下来我们用比较官方的话在来说一下ES的概念。ES是一个基于Lucene实现的开源,分布式,Restful的全文搜索引擎;此外,它还是一个分布式实时文档存储,其中每个文档的每个field均是被索引的数据,且可被搜索,也是一个带实时分析功能的分布式搜索引擎,能够扩展至数以百计的节点实时处理PB级别的数据。
Elasticsearch能做什么? (1)全文检索(全部字段); (2)模糊查询(搜索); (3)数据分析(提供分析语法,例如聚合);
2>.Elasticsearch优点
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,它开实现数据的是实时全文搜索,支持分布式可实现高可用,提供RestFUL API接口,可以处理大规模日志数据,比如Nginx,Tomcat,系统日志等功能。其特点如下: (1)分布式的实时文件存储,每个字段都被索引并可被搜索 (2)分布式的实时分析搜索引擎--做不规则查询 (3)可以扩展到上百台服务器,处理PB级结构化或非结构化数据 Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。 Elasticsearch使用案例: (1)2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”; (2)维基百科:启动以elasticsearch为基础的核心搜索架构SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”; (3)百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据; (4)新浪使用ES 分析处理32亿条实时日志; (5)阿里使用ES 构建挖财自己的日志采集和分析体系;
3>.同类产品对比
Solr: Lucene自己只是一个库,不能单独拿来使用,若要使用它需要对它进行二次开发。若你想使用一套完整的搜索引擎解决方案可以考虑使用Solr。Solr是为非开发人员提供的一套解决方案! Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。 但是巧妇难为无米之炊啊!我们只有Solr是无法帮用户搜索数据的,要想搜索那就得有数据,也就是说你得为Solr提供数据信息以供搜索。 Solr与ElasticSearch的区别: 相同点: 全文检索、搜索、分析。基于lucene。 不同点: Solr利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能; Solr支持更多格式的数据,而Elasticsearch仅支持json文件格式; Solr官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供; Solr在传统的搜索应用中表现好于Elasticsearch,但在处理实时搜索应用时效率明显低于Elasticsearch,比如搜索"附近的人" Hermes: 一个基于大索引技术的海量数据实时检索分析平台。侧重数据分析。 数据规模从几亿到万亿不等。最小的表也是千万级别。 在腾讯17台TS5机器,就可以处理每天450亿的数据(每条数据1kb左右),数据可以保存一个月之久。 Nutch: 更偏向于数据获取组件,一开始只是网络爬虫.
四.Logstash概述
可以通过插件实现日志收集和转发,支持日志过滤,支持普通log,自定义json格式的日志解析。 博主推荐阅读: https://www.elastic.co/guide/en/logstash/index.html
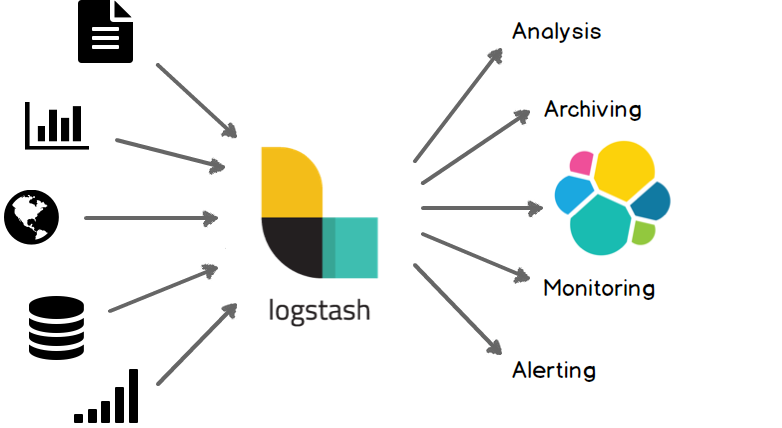
五.Kibana概述
主要是通过调用Elasticsearch的数据,并进行前端数据可视化的展现。
六.查看官方文档
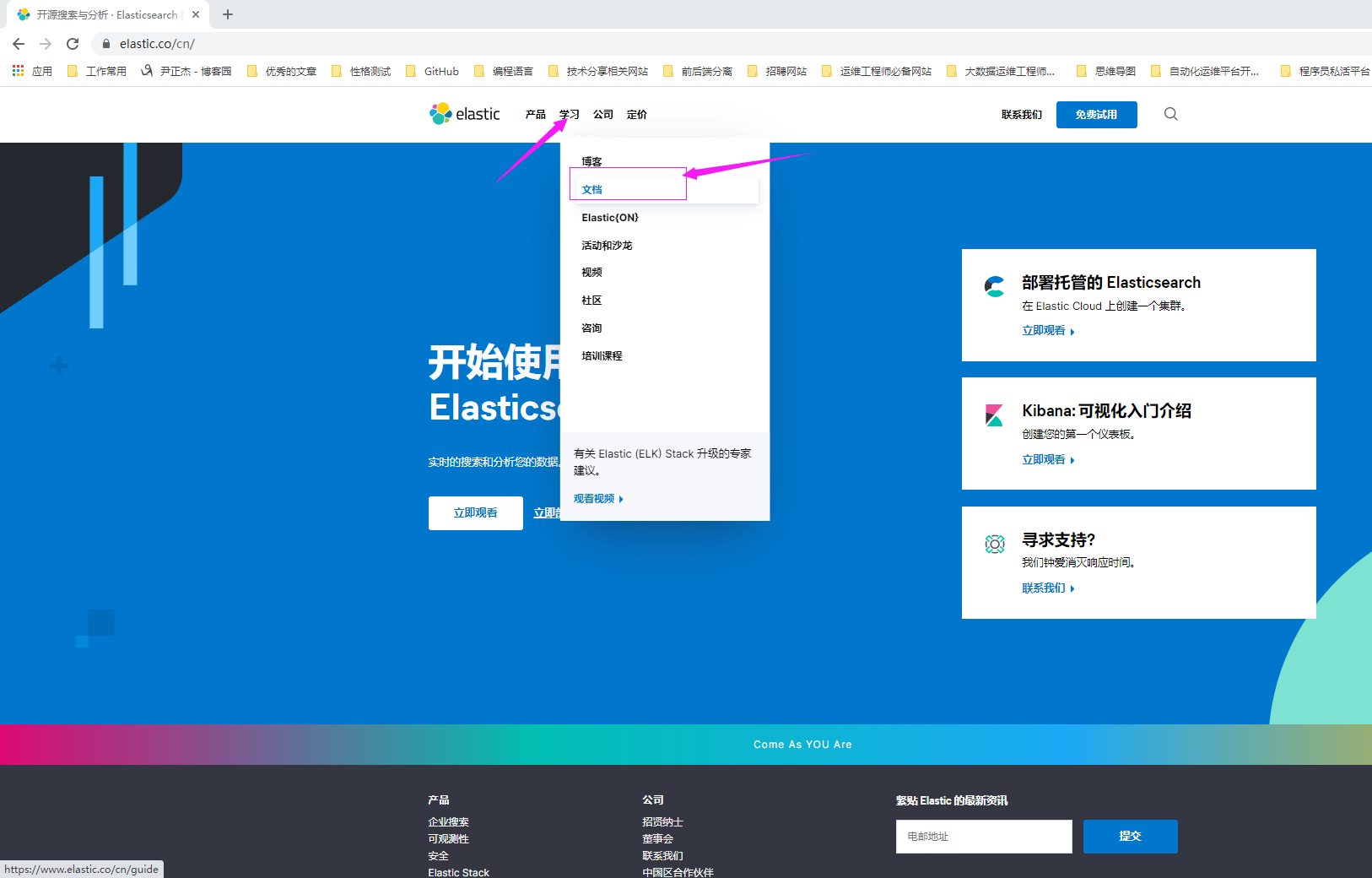
1>.如下图所示,依次点击"学习" ---> "文档"
2>.查看Elastic Stack 的文档
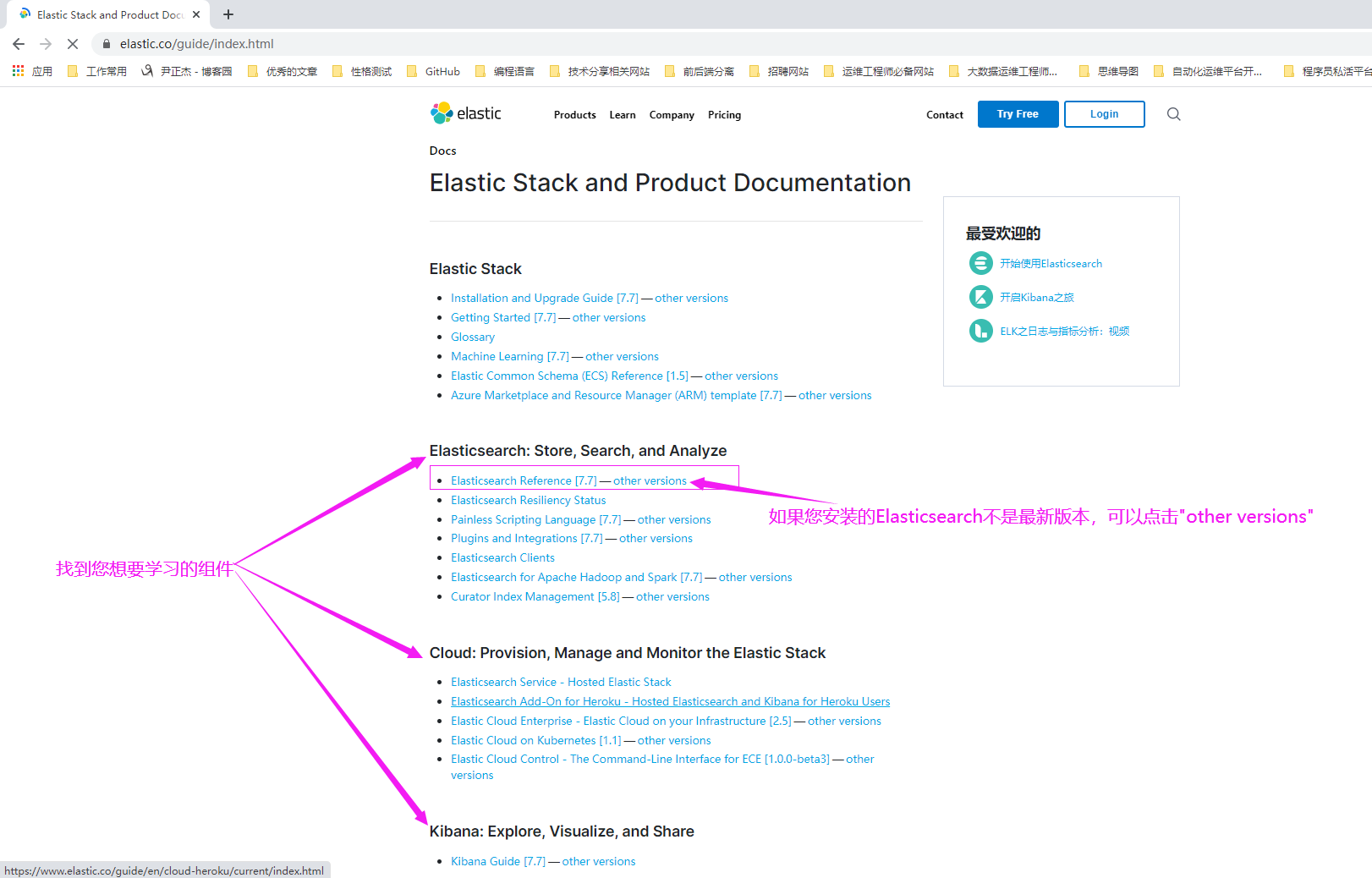
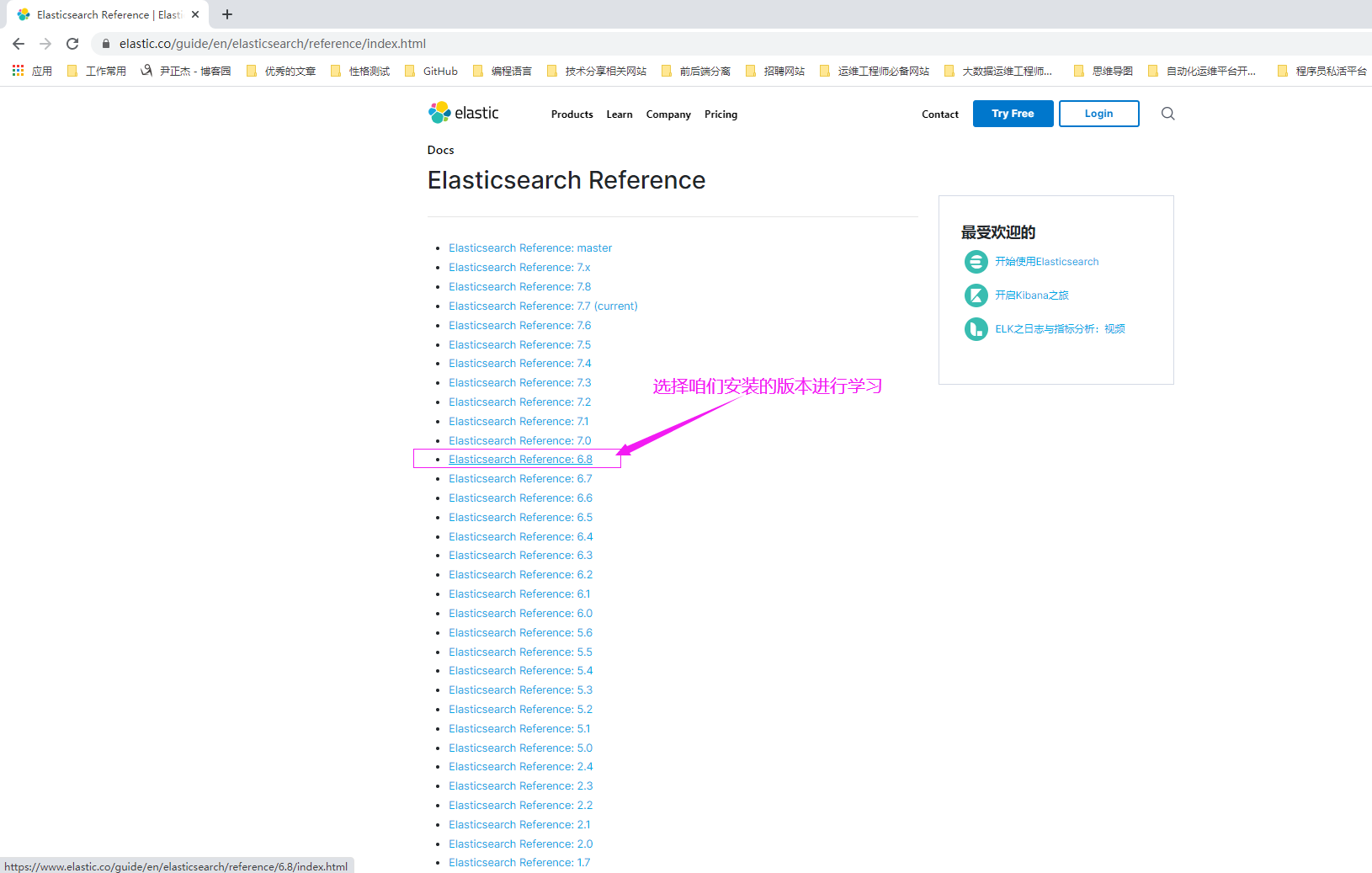
3>.选择已安装对应的版本进行学习
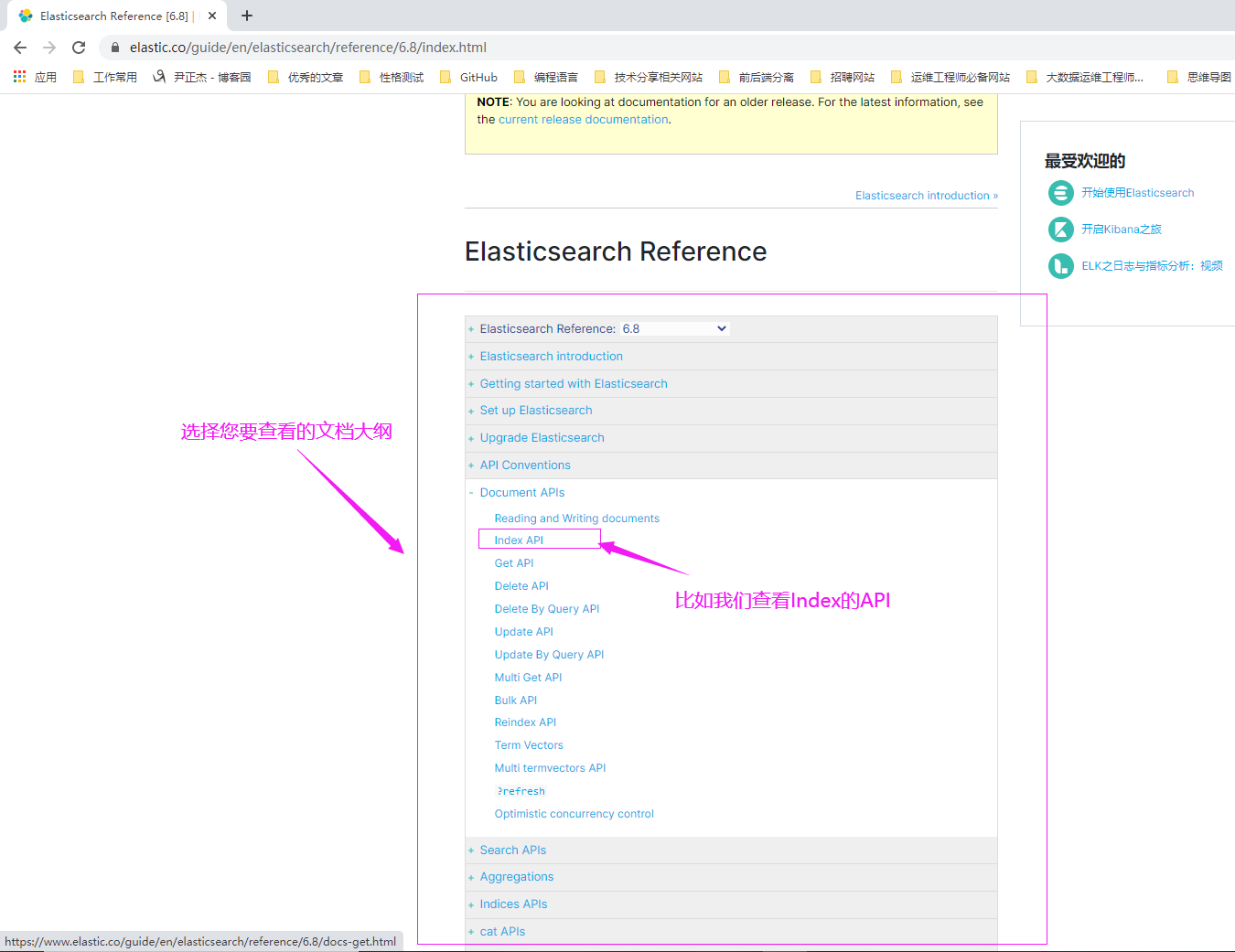
4>.选择要查看的文档的大纲
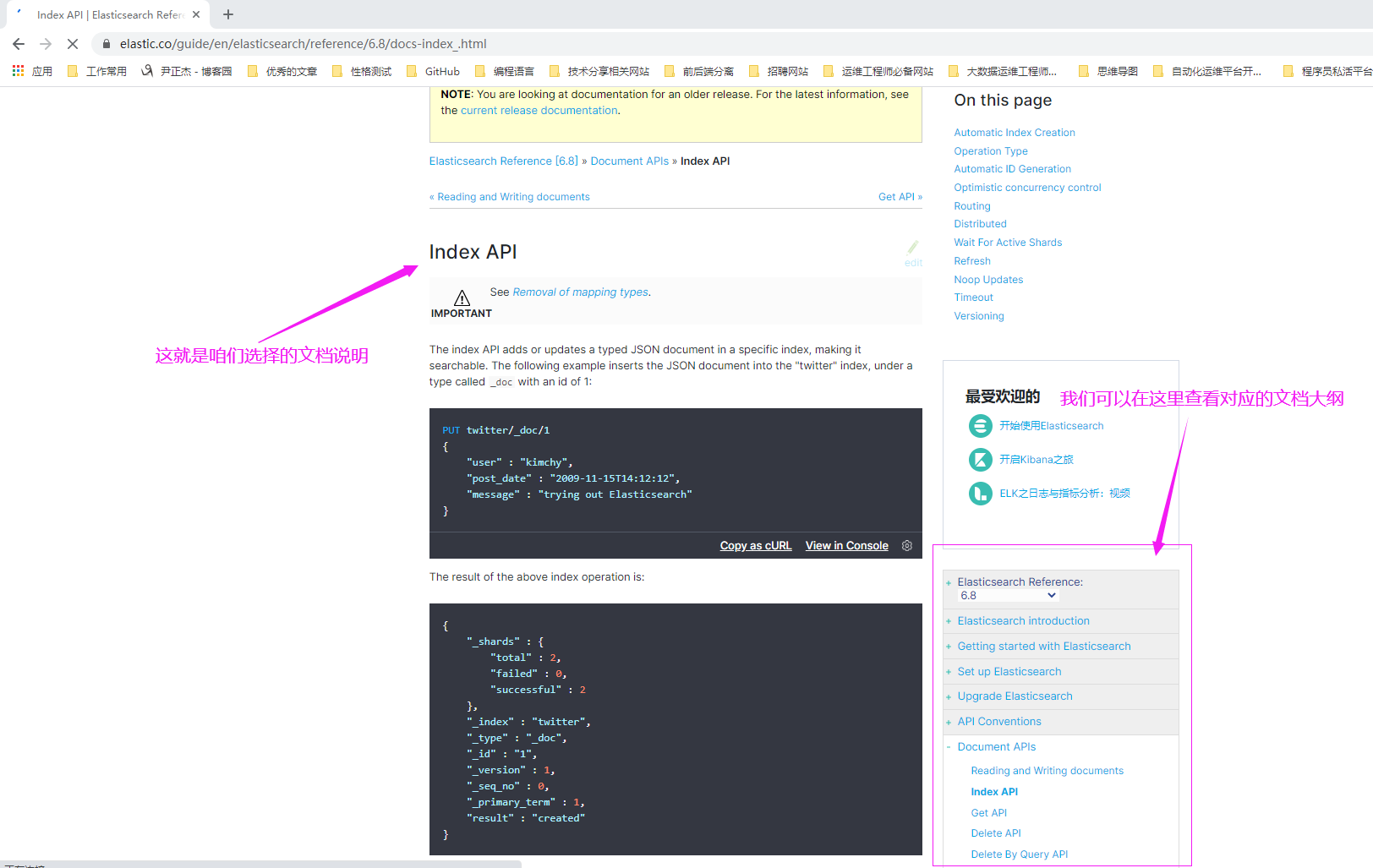
5>.查看文档说明
七.博主推荐阅读
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186
