

GroupingComparator分组(辅助排序/组内排序)
GroupingComparator分组(辅助排序/组内排序)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
如果我们不希望按照默认的key的比较进行分组时,此时就得启用GroupingComparator分组。
一.GroupingComparator分组概述
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤: (1)自定义类继承WritableComparator (2)重写compare()方法 (3)创建一个构造将比较对象的类传给父类
二.GroupingComparator分组案例
1>.案例需求
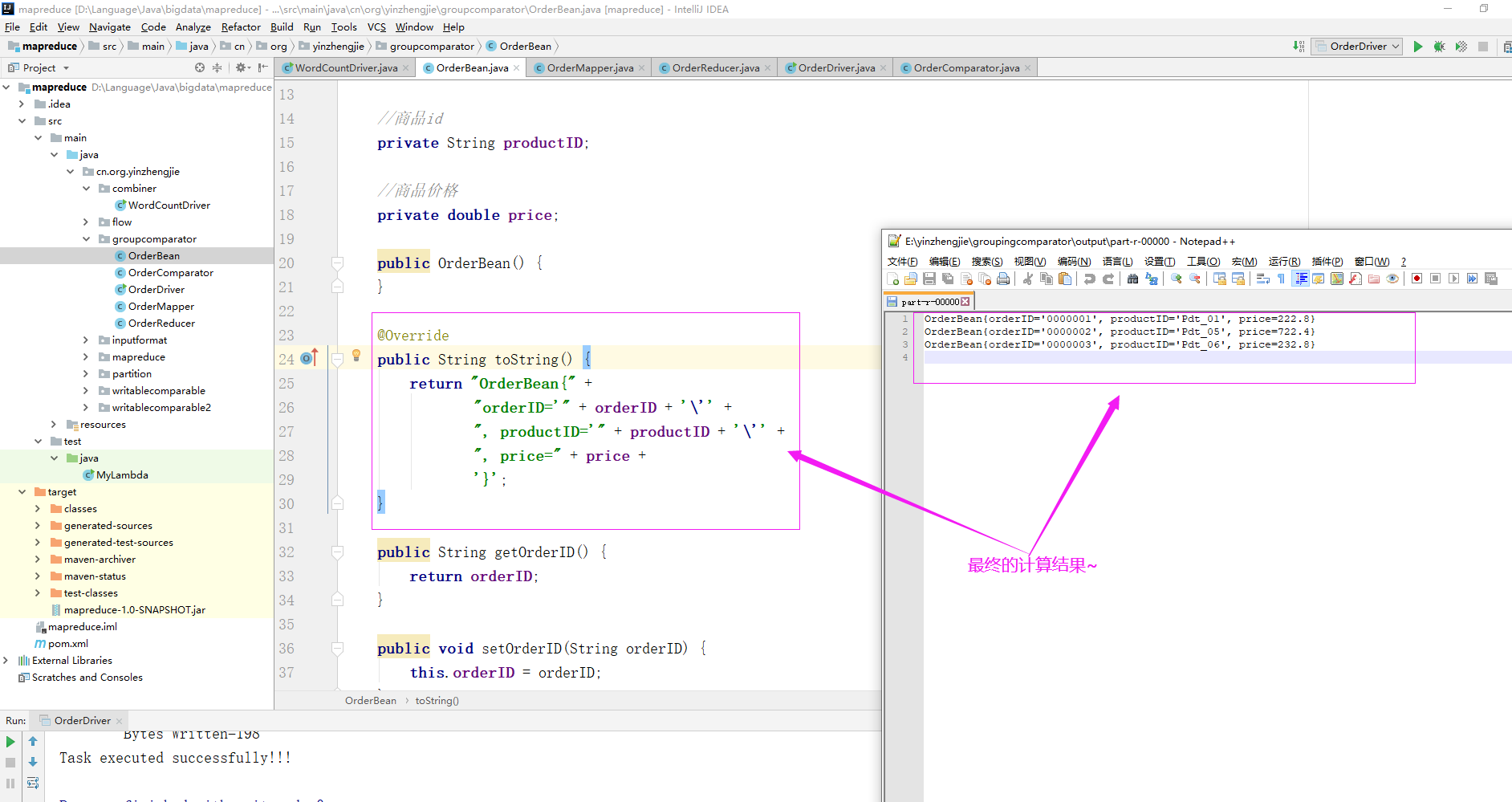
如下图所示,现在需要求出每一个订单中最贵的商品。
需求分析 (1)利用“订单id和成交金额”作为key,可以将Map阶段读取到的所有订单数据按照id升序排序,如果id相同再按照金额降序排序,发送到Reduce。 (2)在Reduce端利用groupingComparator将订单id相同的kv聚合成组,然后取第一个即是该订单中最贵商品。



0000001 Pdt_01 222.8 0000002 Pdt_05 722.4 0000001 Pdt_02 33.8 0000003 Pdt_06 232.8 0000003 Pdt_02 33.8 0000002 Pdt_03 522.8 0000002 Pdt_04 122.4

2>.OrderBean.java
package cn.org.yinzhengjie.groupcomparator; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class OrderBean implements WritableComparable<OrderBean> { //订单id private String orderID; //商品id private String productID; //商品价格 private double price; public OrderBean() { } @Override public String toString() { return "OrderBean{" + "orderID='" + orderID + '\'' + ", productID='" + productID + '\'' + ", price=" + price + '}'; } public String getOrderID() { return orderID; } public void setOrderID(String orderID) { this.orderID = orderID; } public String getProductID() { return productID; } public void setProductID(String productID) { this.productID = productID; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } /* 定义比较方式采用二次排序,即使用2个比较条件:先按照订单排序,再按照价格排序。 */ @Override public int compareTo(OrderBean obj) { //先比较是否是同一个订单id int compare = this.orderID.compareTo(obj.orderID); //再比较价格 if (compare == 0){ return Double.compare(obj.price,this.price); }else { return compare; } } /* 定义序列化方式 */ @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(orderID); dataOutput.writeUTF(productID); dataOutput.writeDouble(price); } /* 定义反序列化方式 */ @Override public void readFields(DataInput dataInput) throws IOException { this.orderID = dataInput.readUTF(); this.productID = dataInput.readUTF(); this.price = dataInput.readDouble(); } }
3>.OrderMapper.java
package cn.org.yinzhengjie.groupcomparator; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; //定义mapper的输入类型是LongWritable,Text,输出的类型是OrderBean,NullWritable,其中OrderBean是咱们自己封装的对象,而NullWritable对应空。 public class OrderMapper extends Mapper<LongWritable,Text,OrderBean,NullWritable> { //初始化一个OrderBean对象 private OrderBean orderBean = new OrderBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split("\t"); orderBean.setOrderID(fields[0]); orderBean.setProductID(fields[1]); orderBean.setPrice(Double.parseDouble(fields[2])); context.write(orderBean,NullWritable.get()); } }
4>.OrderReducer.java
package cn.org.yinzhengjie.groupcomparator; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class OrderReducer extends Reducer<OrderBean,NullWritable,OrderBean,NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } }
5>.OrderComparator.java
package cn.org.yinzhengjie.groupcomparator; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class OrderComparator extends WritableComparator { //使用构造方法生成2个空对象,便于(数据从磁盘中)反序列化,如果不提前声明空对象,在GroupingComparator调用时会抛出空指针异常哟~ protected OrderComparator(){ super(OrderBean.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean oa = (OrderBean)a; OrderBean ob = (OrderBean)b; return oa.getOrderID().compareTo(ob.getOrderID()); } }
6>.OrderDriver.java
package cn.org.yinzhengjie.groupcomparator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class OrderDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(OrderDriver.class); //设置自定义的Mapper和Reducer程序的类路径(classpath) job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReducer.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); //设置自定义的GroupingComparator类路径 job.setGroupingComparatorClass(OrderComparator.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
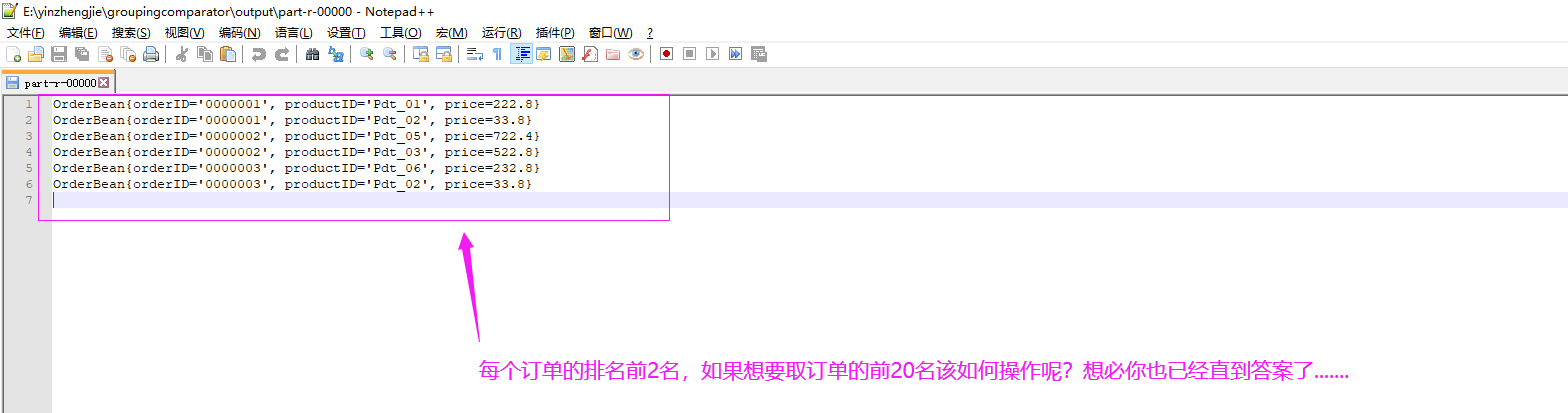
三.取订单价格前两名(复用上面的代码,仅需修改OrderReducer类)
package cn.org.yinzhengjie.groupcomparator; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; public class OrderReducer extends Reducer<OrderBean,NullWritable,OrderBean,NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { Iterator<NullWritable> iterator = values.iterator(); //取订单价格较高的前2个 for (int index =0;index<2;index++){ if (iterator.hasNext()){ context.write(key,iterator.next()); } } } }
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架