
分区(Partitioner)
分区(Partitioner)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
分区可以决定MapTask的处理的数据每一组<K,V>去往哪个ReduceTask。默认是HashPartition哟~
一.查看默认的Partition
1>.测试代码


package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(WordCountDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(WordCountMapper.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(WordCountReducer.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置Reduce数量 job.setNumReduceTasks(5); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /* 用户自定义的Mapper要继承自己的父类。 接下来我们就要对"Mapper<LongWritable,Text,Text,IntWritable>"解释如下: 前两个参数表示定义输出的KV类型 LongWritable: 用于定义行首之间的偏移量,用于定义某一行的位置。 Text: 我们知道LongWritable可以定位某一行的偏移量,那Text自然是该行的内容。 后两个参数表示定义输出的KV类型: Text: 用于定义输出的Key类型 IntWritable: 用于定义输出的Value类型 */ public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> { //注意哈,我们这里仅创建了2个对象,即word和one。 private Text word = new Text(); private IntWritable one = new IntWritable(1); /* Mapper中的业务逻辑写在map()方法中; 接下来我们就要对"map(LongWritable key, Text value, Context context)"中个参数解释如下: key: 依旧是某一行的偏移量 value: 对应上述偏移量的行内容 context: 整个任务的上下文环境,我们写完Mapper或者Reducer都需要交给context框架去执行。 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到行数据 String line = value.toString(); //将行数据按照逗号进行切分 String[] words = line.split(","); //遍历数组,把单词变成(word,1)的形式交给context框架 for (String word:words){ /* 我们将输出KV发送给context框架,框架所需要的KV类型正式我们定义在继承Mapper时指定的输出KV类型,即Text和IntWritable类型。 为什么不能写"context.write(new Text(word),new IntWritable(1));"? 上述写法并不会占用过多的内存,因为JVM有回收机制; 但是上述写法的确会大量生成对象,这回导致回收垃圾的时间占比越来越长,从而让程序变慢。 因此,生产环境中并不推荐大家这样写。 推荐大家参考apache hadoop mapreduce官方程序的写法,提前创建2个对象(即上面提到的word和one),然后利用这两个对象来传递数据。 */ this.word.set(word); context.write(this.word,this.one); } } }
package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /* 用户自定义Reducer要继承自己的父类; 根据Hadoop MapReduce的运行原理,再写自定义的Reducer类时,估计你已经猜到了Reducer<Text,IntWritable,Text,IntWritable>的泛型。 前两个输入参数就是咱们自定义Mapper的输出泛型的类型,即: Text: 自定义Mapper输出的Key类型。 IntWritable: 自定义Mapper输出的Value类型 后两个参数表示定义输出的KV类型: Text: 用于定义输出的Key类型 IntWritable: 用于定义输出的Value类型 */ public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> { //定义一个私有的对象,避免下面创建多个对象 private IntWritable total = new IntWritable(); /* Reducer的业务逻辑在reduce()方法中; 接下来我们就要对"reduce(Text key, Iterable<IntWritable> values, Context context)"中个参数解释如下: key: 还记得咱们自定义写的"context.write(this.word,this.one);"吗? 这里的key指的是同一个单词(word),即相同的单词都被发送到同一个reduce函数进行处理啦。 values: 同理,这里的values指的是很多个数字1组成,每一个数字代表同一个key出现的次数。 context: 整个任务的上下文环境,我们写完Mapper或者Reducer都需要交给context框架去执行。 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //定义一个计数器 int sum = 0; //对同一个单词做累加操作,计算该单词出现的频率。 for (IntWritable value:values){ sum += value.get(); } //包装结果 total.set(sum); //将计算的结果交给context框架 context.write(key,total); } }
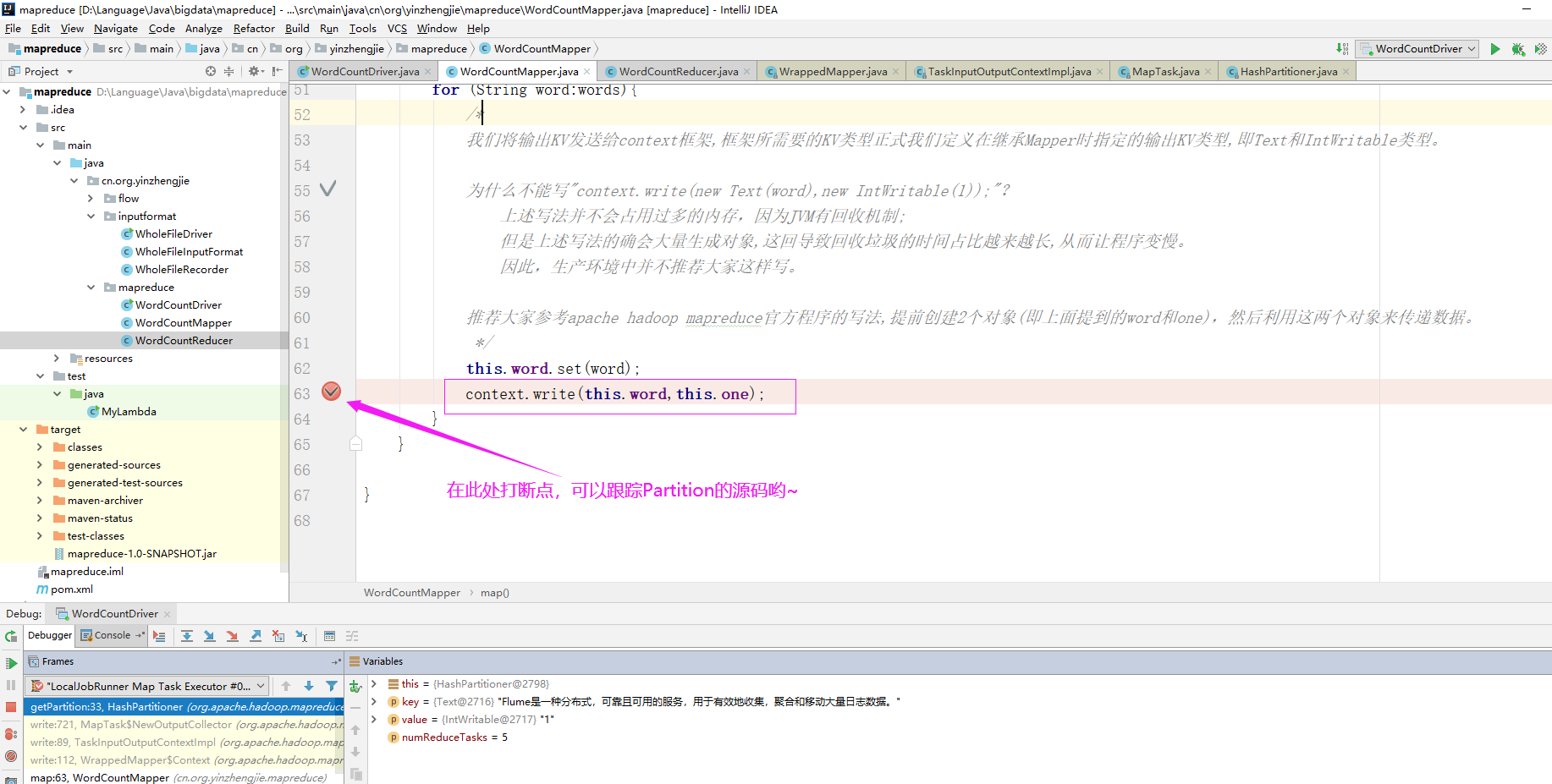
2>.查看默认Partitioner
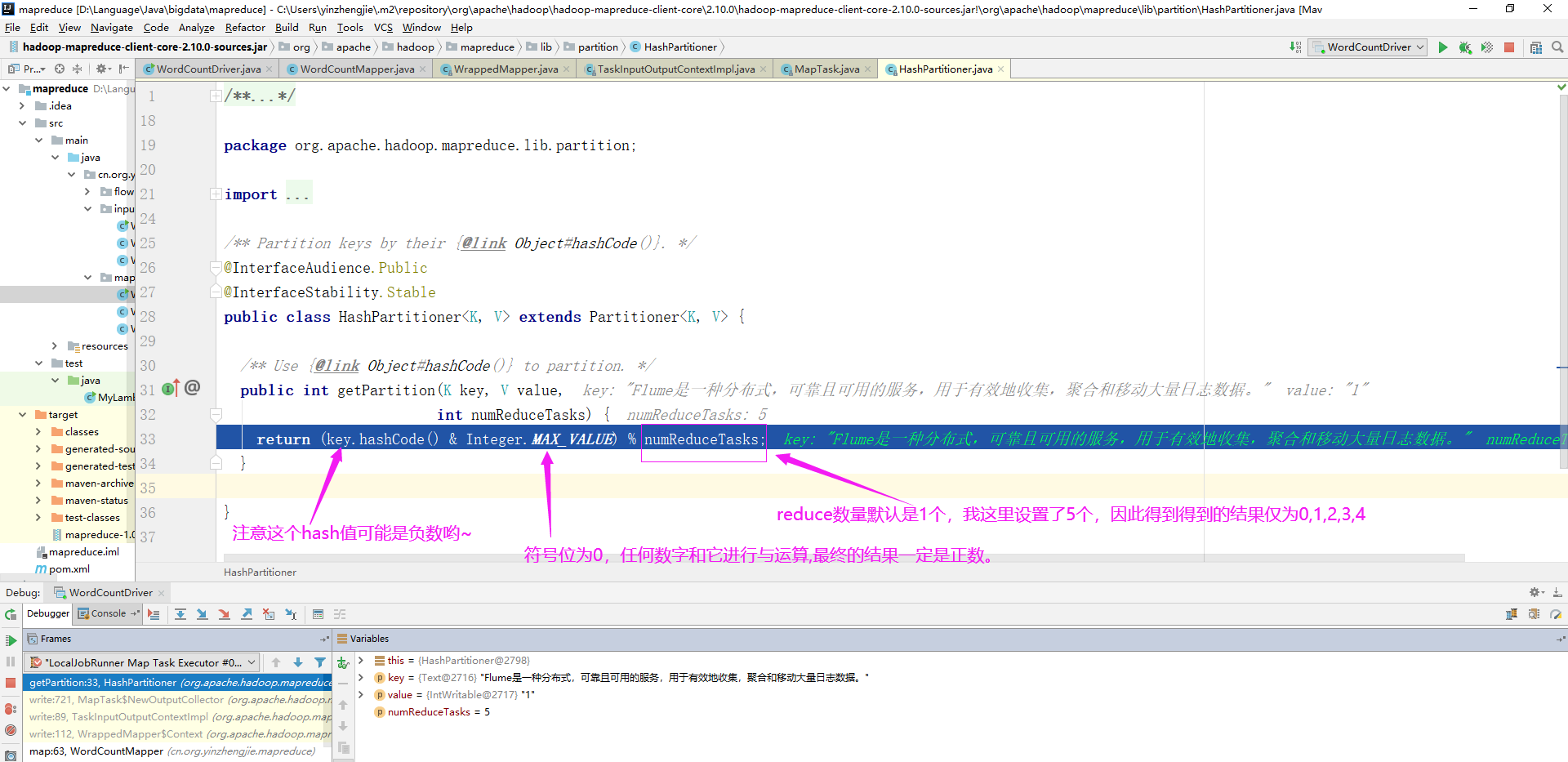
如下图所示,默认Partitioner时根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
二.自定义Partitioner
1>.测试数据及参考代码
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12520516.html
1 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 7441 4386 200 2 13946532415 172.200.100.21 thrift.apache.org/docs/ 2134 6419 200 3 13856432639 172.200.30.101 www.cnblogs.com/yinzhengjie2020 2158 7532 200 4 13511251143 172.200.100.13 developers.google.com 3210 1213 404 5 18371172953 172.200.30.101 2790 3726 200 6 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 3712 5923 200 7 13590412962 172.200.30.2 avro.apache.org 5136 2914 200 8 15812353247 172.200.100.91 www.hao123.com 7216 5936 200 9 13539119499 172.200.100.61 thrift.apache.org/docs/ 3410 7210 200 10 13830544951 172.200.100.39 www.shouhu.com 7170 3290 403 11 13843685338 172.200.100.181 5139 2678 200 12 13341330521 172.200.100.29 www.cnblogs.com/yinzhengjie/ 3128 2980 500 13 13562439731 172.202.100.110 avro.apache.org 1948 2978 200 14 13071253242 172.200.100.210 thrift.apache.org/docs/ 3124 2130 200 15 13782846535 172.200.100.120 www.qq.com 2918 3716 200 16 13892314333 172.200.30.101 www.cnblogs.com/yinzhengjie2020 6128 6781 200 17 15309468723 172.200.100.34 www.qinghua.com 3345 80349 404 18 13901737821 172.200.100.95 www.sogou.com 6521 4312 200 19 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie2020 12058 18243 200 20 13268738793 172.200.100.217 avro.apache.org 1230 1520 200 21 13768434152 172.200.100.118 www.alibaba.com 24181 2481 200 22 13168435653 172.200.30.101 1216 1954 200 23 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 7441 4386 200 24 13946532415 172.200.100.21 thrift.apache.org/docs/ 2134 6419 200 25 13856432639 172.200.30.101 www.cnblogs.com/yinzhengjie2020 2158 7532 200 26 13511251143 172.200.100.13 developers.google.com 3210 1213 404 27 18371172953 172.200.30.101 2790 3726 200 28 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 3712 5923 200 29 13590412962 172.200.30.2 avro.apache.org 5136 2914 200 30 15812353247 172.200.100.91 www.hao123.com 7216 5936 200 31 13539119499 172.200.100.61 thrift.apache.org/docs/ 3410 7210 200 32 13830544951 172.200.100.39 www.shouhu.com 7170 3290 403 33 13843685338 172.200.100.181 5139 2678 200 34 13341330521 172.200.100.29 www.cnblogs.com/yinzhengjie/ 3128 2980 500 35 13562439731 172.202.100.110 avro.apache.org 1948 2978 200 36 13071253242 172.200.100.210 thrift.apache.org/docs/ 3124 2130 200 37 13782846535 172.200.100.120 www.qq.com 2918 3716 200 38 13892314333 172.200.30.101 www.cnblogs.com/yinzhengjie2020 6128 6781 200 39 15309468723 172.200.100.34 www.qinghua.com 3345 80349 404 40 13901737821 172.200.100.95 www.sogou.com 6521 4312 200 41 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie2020 12058 18243 200 42 13268738793 172.200.100.217 avro.apache.org 1230 1520 200 43 13768434152 172.200.100.118 www.alibaba.com 24181 2481 200 44 13168435653 172.200.30.101 1216 1954 200
2>. 自定义Parition代码
package cn.org.yinzhengjie.partition; import cn.org.yinzhengjie.flow.FlowBean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class MyPartition extends Partitioner<Text,FlowBean> { @Override public int getPartition(Text text, FlowBean flowBean, int numPartitions) { String phone = text.toString(); /* * 根据电话号码首字母进行不同的分区,最后根据分区编号不同个数据会进入到不同的ReduceTask哟~ */ switch (phone.substring(0,3)){ case "133": return 0; case "135": return 1; case "137": return 2; case "138" : return 3; default: return 4; } } }
3>.编写Driver类调用自定义的Paritinoner类
package cn.org.yinzhengjie.partition; import cn.org.yinzhengjie.flow.FlowBean; import cn.org.yinzhengjie.flow.FlowDriver; import cn.org.yinzhengjie.flow.FlowMapper; import cn.org.yinzhengjie.flow.FlowReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class PartitionerDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取Job实例 Job job = Job.getInstance(new Configuration()); //设置类路径 job.setJarByClass(PartitionerDriver.class); //设置Mapper和Reducer job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); //设置输入输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //自定义Reducer的个数 job.setNumReduceTasks(5); //自定义分区信息 job.setPartitionerClass(MyPartition.class); //设置输入输出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
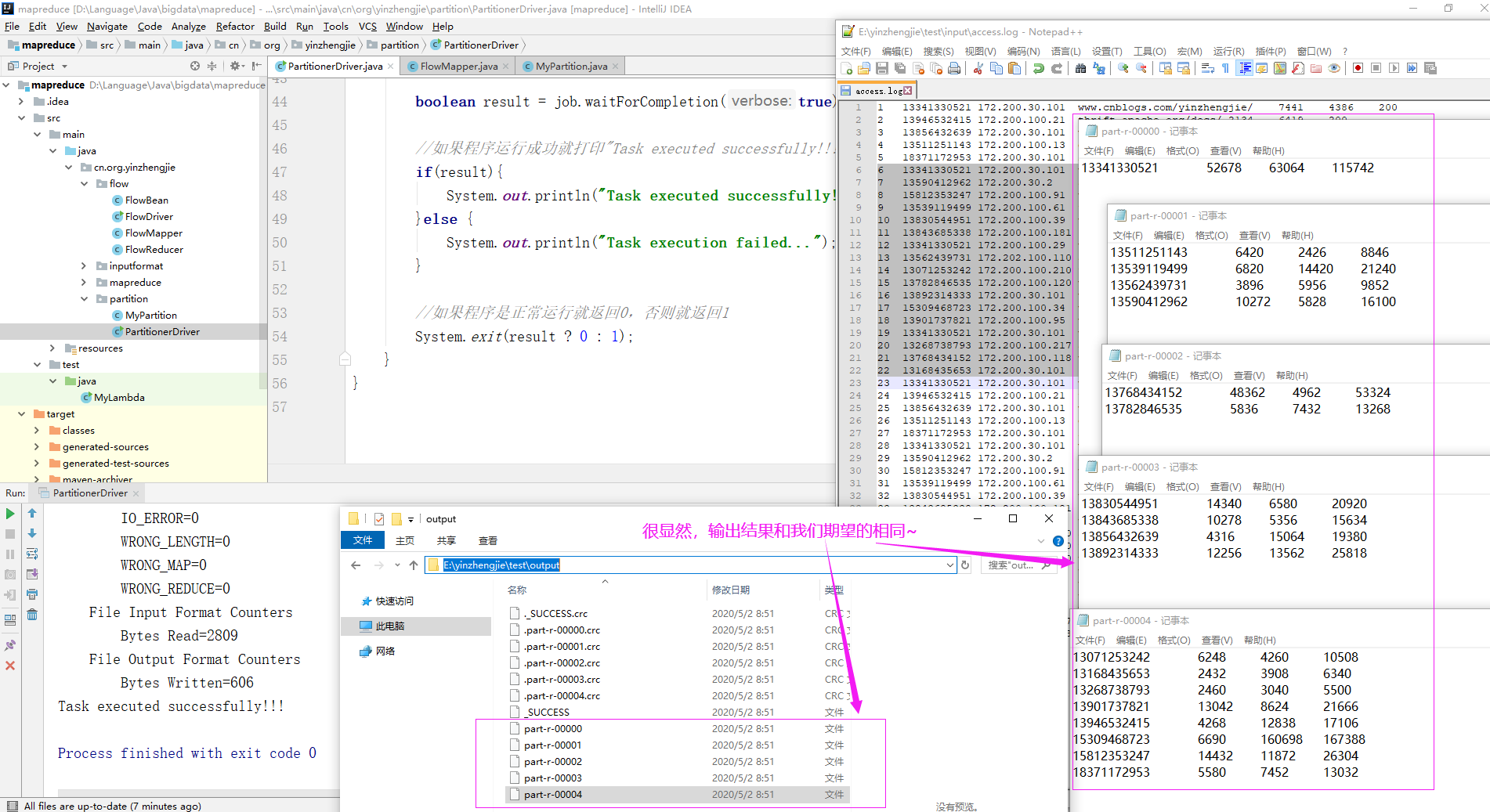
三.分区总结
(1)如果ReduceTask的数量大于getPartition的接过数,则会产生几个空的输出文件,换句话说,当自定义的Partition数量小于我们在Driver类中定义的ReduceTask数量时,则多余的Reducer个数是空文件; (2)如果小于ReduceTask的数量(前提是大于1),大于getPartition的结果数,则有一部分分区数量无处安放,会抛出异常;换句话说,当自定义的Partition数量大于我们在Driver类中定义的ReduceTask数量时会报错; (3)如果ReduceTask的数量等于1,则不管MapTask端输出多少个分区,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件,即"part-r-00000" (4)分区号必须从零开始,逐一累加; 举个例子: 假设自定义分区数是5,则: job.setNumReduceTasks(1); 会正常运行,只不过只会产生一个输出文件哟。 job.setNumReduceTasks(2~4); 无论设置的是2-4任意一个数字,都会报错,因为自定义的分区数大于配置的Reducer数量。 job.setNumReduceTasks(5); 会正常运行,每个Reducer基本上都有数据。 job.setNumReduceTasks(6); 大于自定义分区数后,程序会正常运行,但是会有空文件产生哟~
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186
