HDFS集群的API常见操作
HDFS集群的API常见操作
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.环境配置
1>.自行配置Hadoop和Java环境
此步骤相对简单,略过。
2>.配置maven环境


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.org.yinzhengjie</groupId> <artifactId>hdfs</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> </dependencies> </project>
3>.创建项目并在"src/main/resources"目录下创建"log4j.properties"配置
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
二.下载文件到本地
1>.访问NameNode的WebUI
[root@hadoop101.yinzhengjie.org.cn ~]# hadoop version Hadoop 2.10.0 Subversion ssh://git.corp.linkedin.com:29418/hadoop/hadoop.git -r e2f1f118e465e787d8567dfa6e2f3b72a0eb9194 Compiled by jhung on 2019-10-22T19:10Z Compiled with protoc 2.5.0 From source with checksum 7b2d8877c5ce8c9a2cca5c7e81aa4026 This command was run using /yinzhengjie/softwares/hadoop-2.10.0/share/hadoop/common/hadoop-common-2.10.0.jar [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -text /host.log 172.200.4.107 hadoop107.yinzhengjie.org.cn 172.200.4.108 hadoop108.yinzhengjie.org.cn [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#
2>.编写JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.Test; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class HdfsClient { @Test public void get() throws IOException, URISyntaxException, InterruptedException { /* 还记得咱们在搭建集群时修改过"core-site.xml","hdfs-site.xml","mapred-site.xml","yarn-site.xml"这四个文件吗? 我们在配置上述四个文件时将所有的配置都放在一个"<configuration></configuration>"标签中。 其实"new Configuration()"可以理解为创建一个空的"<configuration></configuration>"标签,接下来我们为其配置参数。 */ Configuration conf = new Configuration(); /* 既然理解了上面的"new Configuration()"其实就是一个空的"<configuration></configuration>"标签,那么接下来就好理解了: "fs.defaultFS": 就对应着我们配置"<name></name>"标签 "hdfs://hadoop101.yinzhengjie.org.cn:9000": 就对应着我们配置的"<value></value>"标签 "指定HDFS中NameNode的RPC地址": 就对应"<description></description>"标签 */ conf.set("fs.defaultFS","hdfs://hadoop101.yinzhengjie.org.cn:9000","指定HDFS中NameNode的RPC地址"); //获取一个HDFS的抽象封装对象 FileSystem fs = FileSystem.get(conf); //用上面创建的对象来操作文件系统,比如我们将HDFS集群的"/host.log"下载到本地的"E:\yinzhengjie\"路径下。 fs.copyToLocalFile(new Path("/host.log"),new Path("E:\\yinzhengjie\\")); //关闭资源,我们知道HDFS的同一个文件是不支持并发的,因此使用完要记得释放资源,否则别人没法写入。 fs.close(); } }
3>.查看代码是否成功下载本地

三.修改文件名称
1>.访问NameNode的WebUI
2>.编写JAVA代码
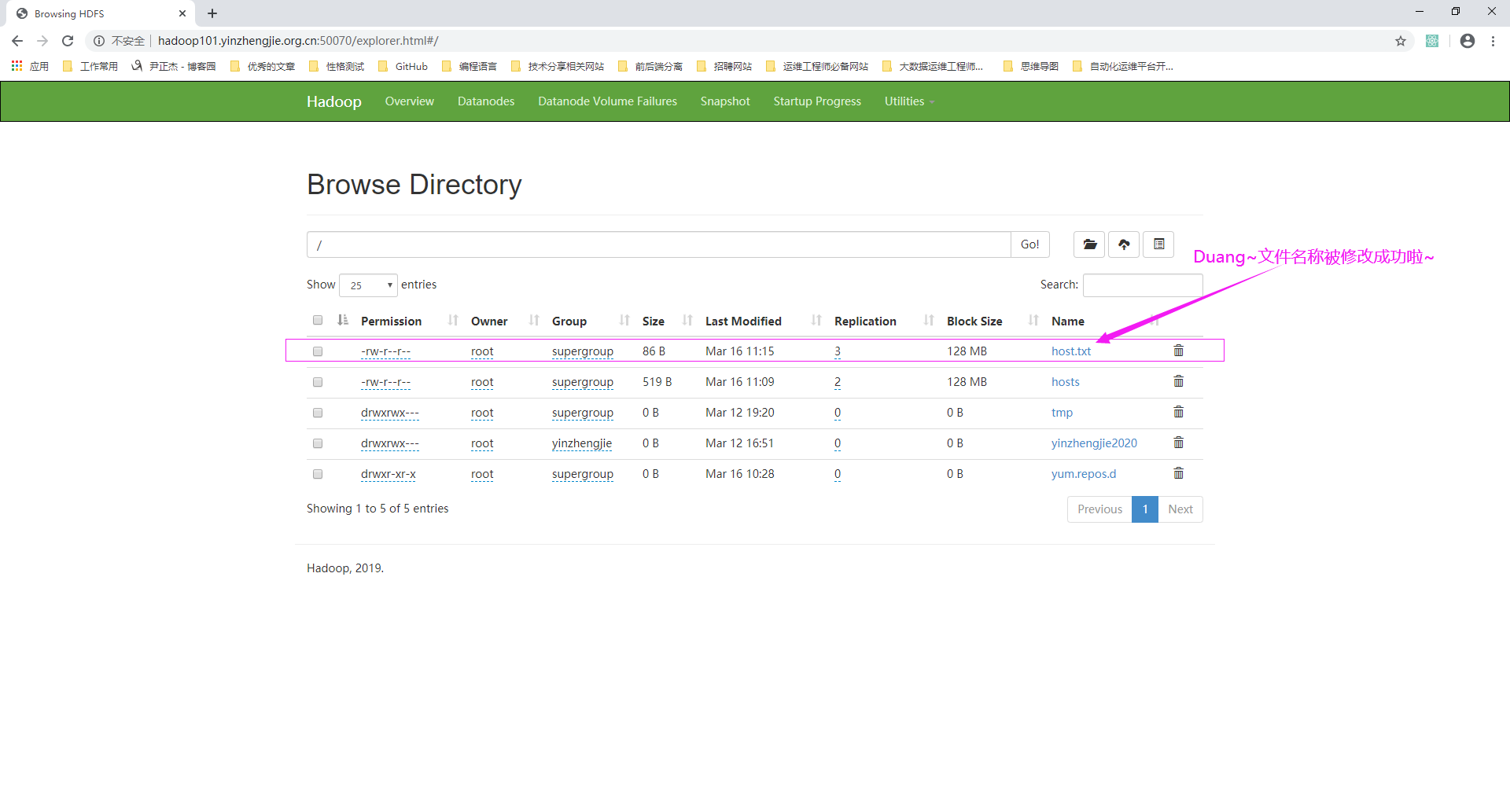
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.Test; import java.io.IOException; import java.net.URI; public class HdfsClient2 { @Test public void rename() throws IOException, InterruptedException { /* 我们这一步骤主要是获取文件系统对象,使用"FileSystem.get"方法需要传递三个参数,这三个参数说明如下: URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"): HDFS集群的RPC地址 new Configuration(): 创建Configuration对象,而且会自动将上面HDFS集群的RPC地址自动配置进去 "root": 主要指定以那个用户身份访问HDFS集群 */ FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),new Configuration(),"root"); //将HDFS集群中的"/host.log"重命名为"/host.txt" fs.rename(new Path("/host.log"),new Path("/host.txt")); //记得释放资源哟~ fs.close(); } }
3>.再次访问NameNode的WebUI
四.删除文件内容
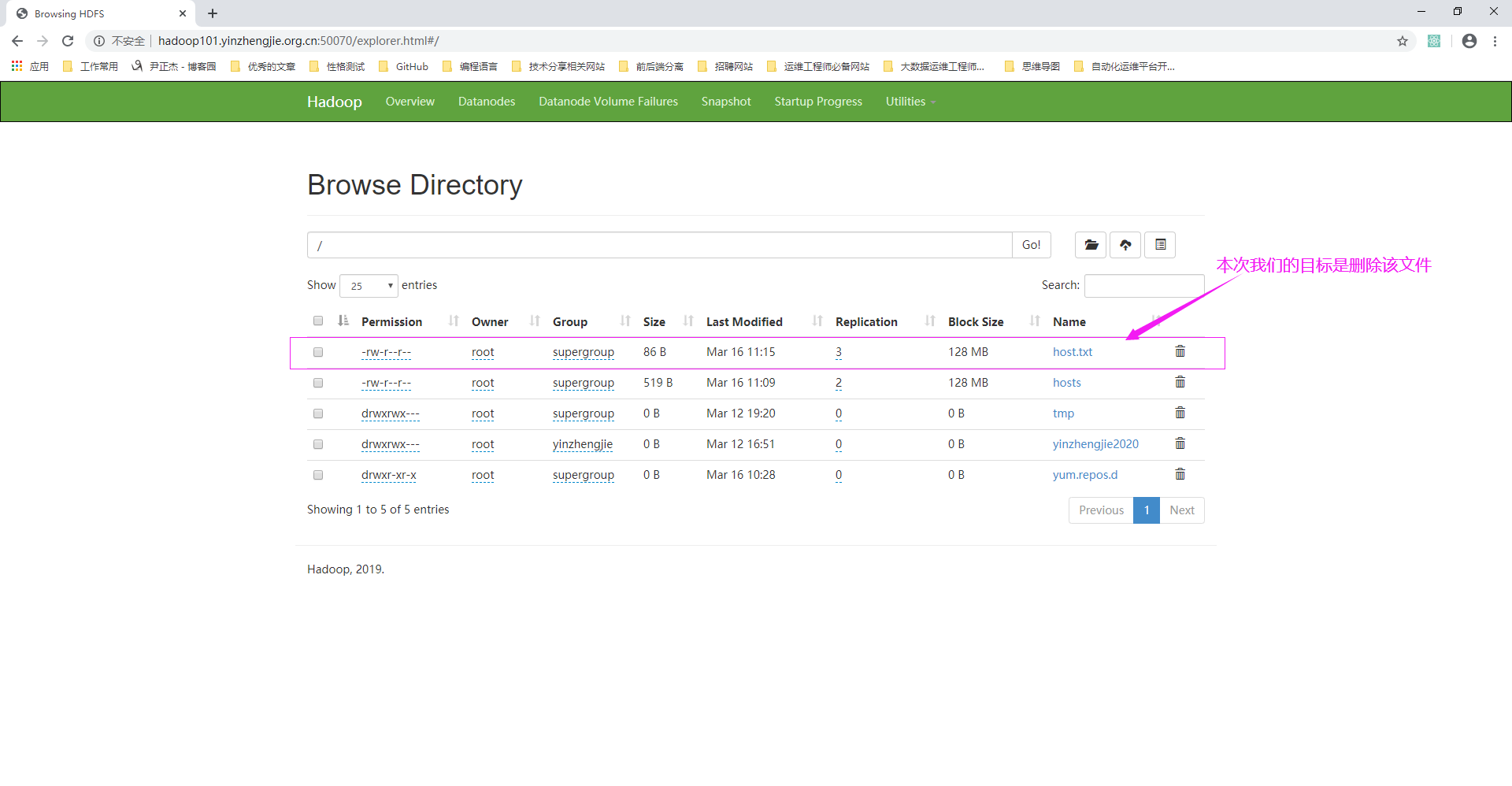
1>.访问NameNode的WebUI
2>.编写JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; public class HdfsClient3 { private FileSystem fs; //注意哈,执行单元测试之前会执行"Before"方法 @Before public void before() throws IOException, InterruptedException { //获取文件对象 fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),new Configuration(),"root"); System.out.println("Before..."); } //编写单元测试方法,即尽管没有main放啊也可以执行该delete方法哟~ @Test public void delete() throws IOException { /* 删除HDFS集群的"/host.txt"文件,如果该文件是目录的话,第二个参数是"ture"表示递归删除,如果为"false"则只能删除空目录。 */ boolean result = fs.delete(new Path("/host.txt"), true); if (result){ System.out.println("Delete successful !"); }else { System.out.println("Delete failed!"); } } //注意哈,执行Test单元测试后会执行"After"方法 @After public void after() throws IOException { fs.close(); System.out.println("After..."); } }
3>.再次访问NameNode的WebUI

五.在HDFS集群中已经存在的文件追加内容
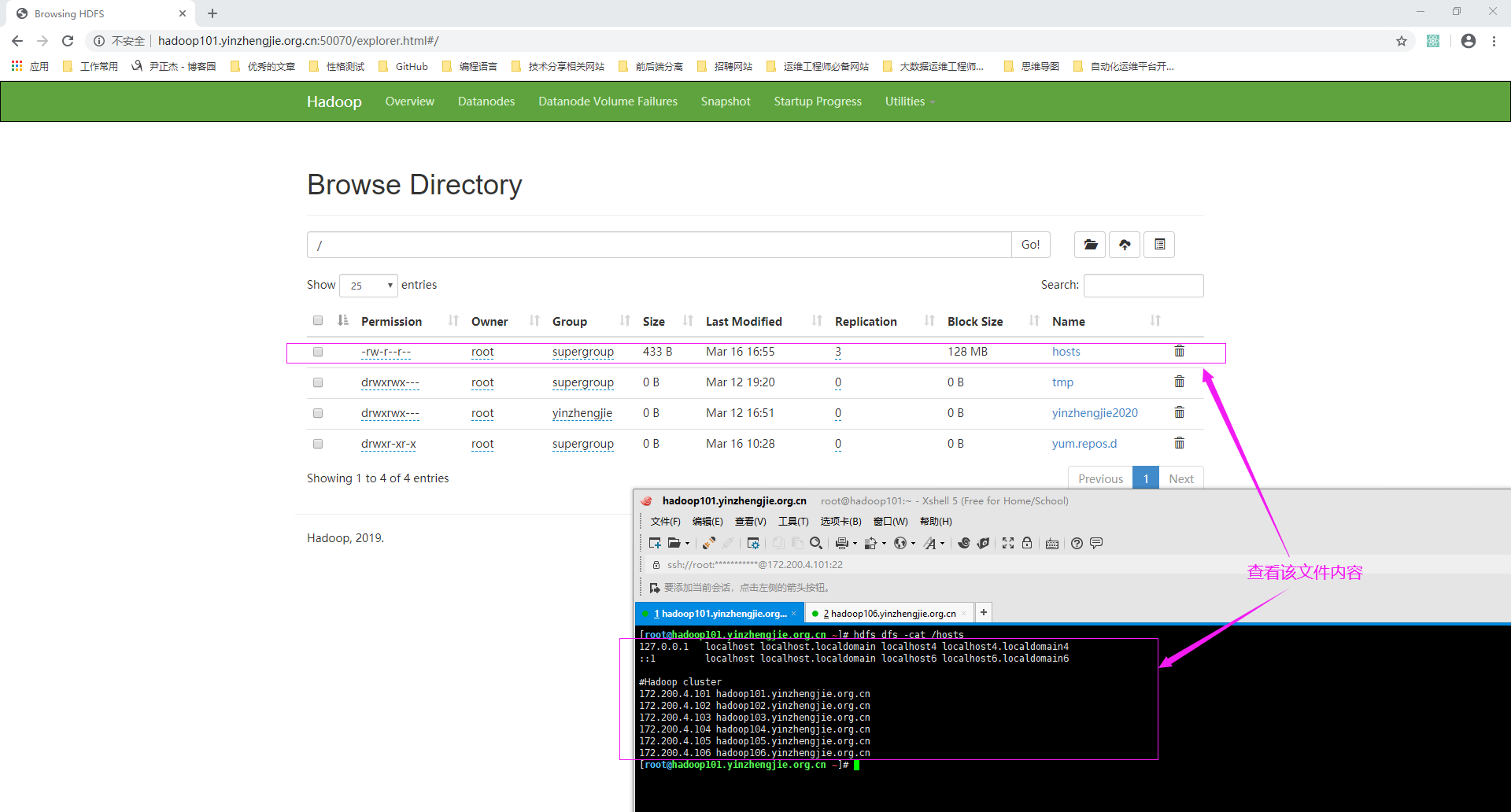
1>.访问NameNode的WebUI并查看"/hosts"文件内容
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -cat /hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 #Hadoop cluster 172.200.4.101 hadoop101.yinzhengjie.org.cn 172.200.4.102 hadoop102.yinzhengjie.org.cn 172.200.4.103 hadoop103.yinzhengjie.org.cn 172.200.4.104 hadoop104.yinzhengjie.org.cn 172.200.4.105 hadoop105.yinzhengjie.org.cn 172.200.4.106 hadoop106.yinzhengjie.org.cn [root@hadoop101.yinzhengjie.org.cn ~]#
2>.编写JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.junit.Test; import java.io.FileInputStream; import java.io.IOException; import java.net.URI; public class HdfsClient4 { @Test public void append() throws IOException, InterruptedException { FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),new Configuration(),"root"); //获取HDFS的文件流 FSDataOutputStream output = fs.append(new Path("/hosts"), 4096); //获取本地的文件流 FileInputStream input = new FileInputStream("E:\\yinzhengjie\\host.log"); //使用hadoop提供的流拷贝工具,将我们本地的文件内容追加到HDFS集群的指定文件中。 IOUtils.copyBytes(input,output,4096,true); fs.close(); } }
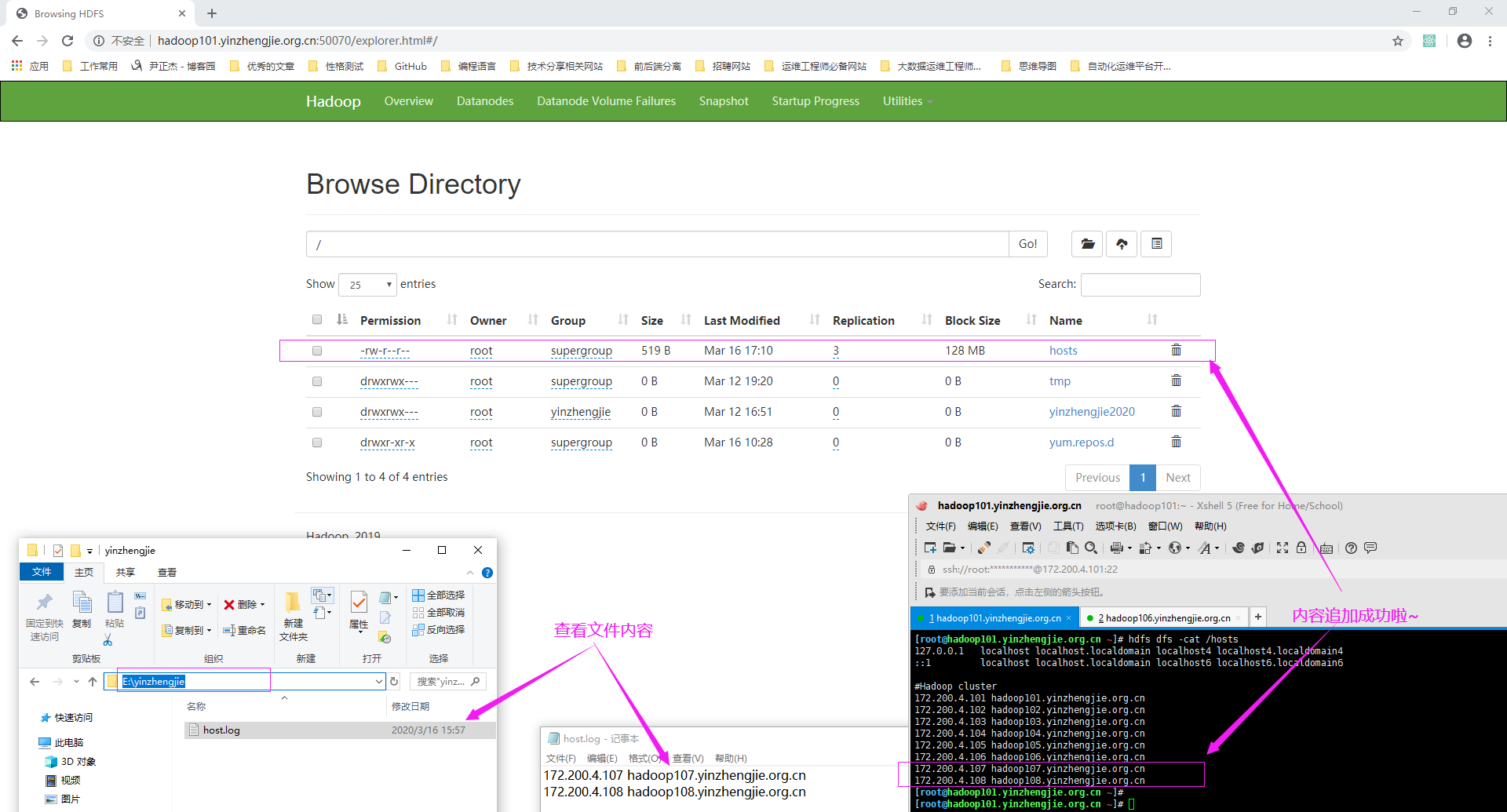
3>.再次访问NameNode的WebUI并查看文件内容
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -cat /hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 #Hadoop cluster 172.200.4.101 hadoop101.yinzhengjie.org.cn 172.200.4.102 hadoop102.yinzhengjie.org.cn 172.200.4.103 hadoop103.yinzhengjie.org.cn 172.200.4.104 hadoop104.yinzhengjie.org.cn 172.200.4.105 hadoop105.yinzhengjie.org.cn 172.200.4.106 hadoop106.yinzhengjie.org.cn 172.200.4.107 hadoop107.yinzhengjie.org.cn 172.200.4.108 hadoop108.yinzhengjie.org.cn [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#
六.将本地文件上传到HDFS集群
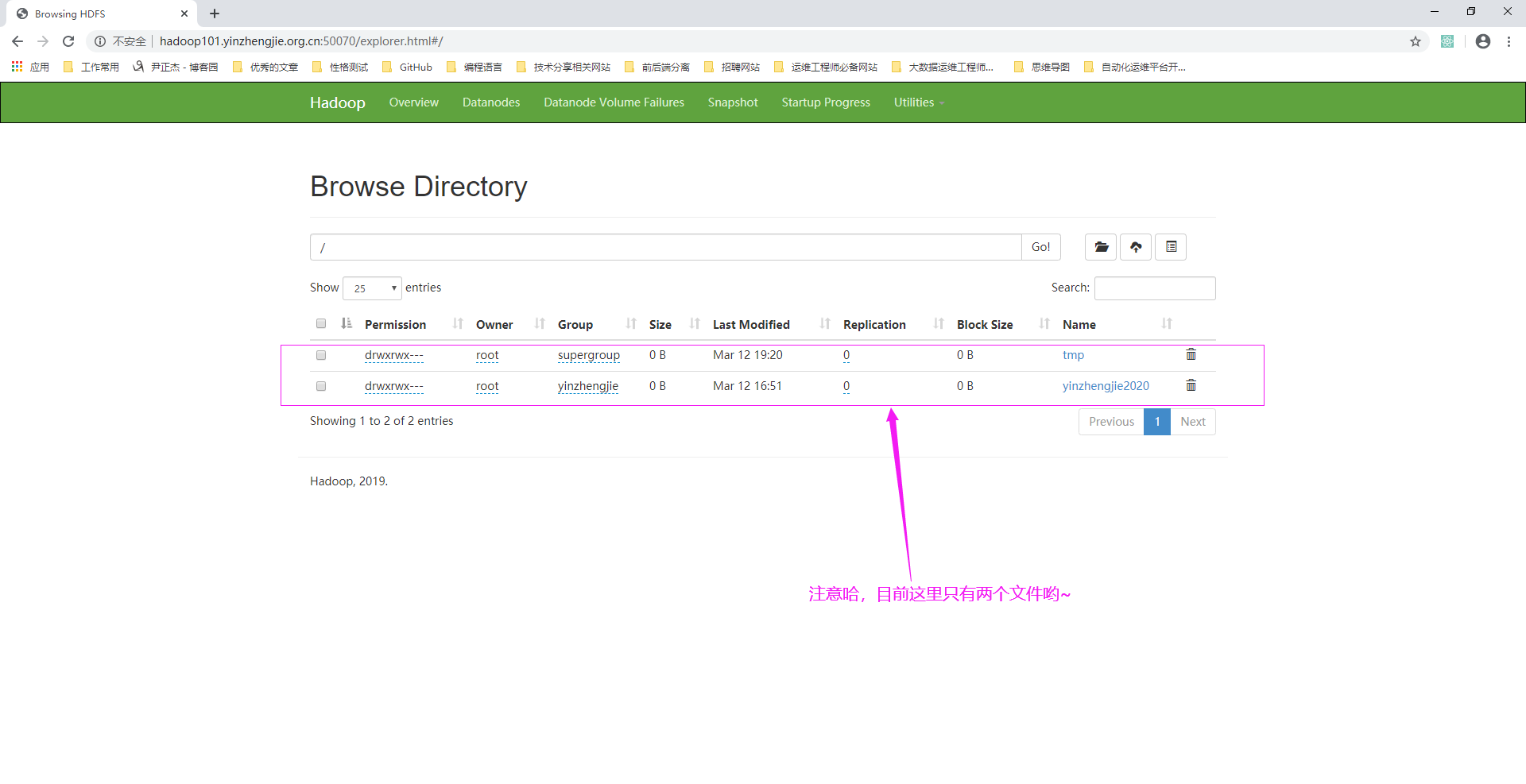
1>.访问NameNode的WebUI
2>.编写JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.Test; import java.io.IOException; import java.net.URI; public class HdfsClient5 { @Test public void put() throws IOException, InterruptedException { FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),new Configuration(),"root"); //将本地的"E:\yinzhengjie\host.log"文件拷贝到HDFS集群的"/"路径下 fs.copyFromLocalFile(new Path("E:\\yinzhengjie\\host.log"),new Path("/")); //释放资源 fs.close(); } }
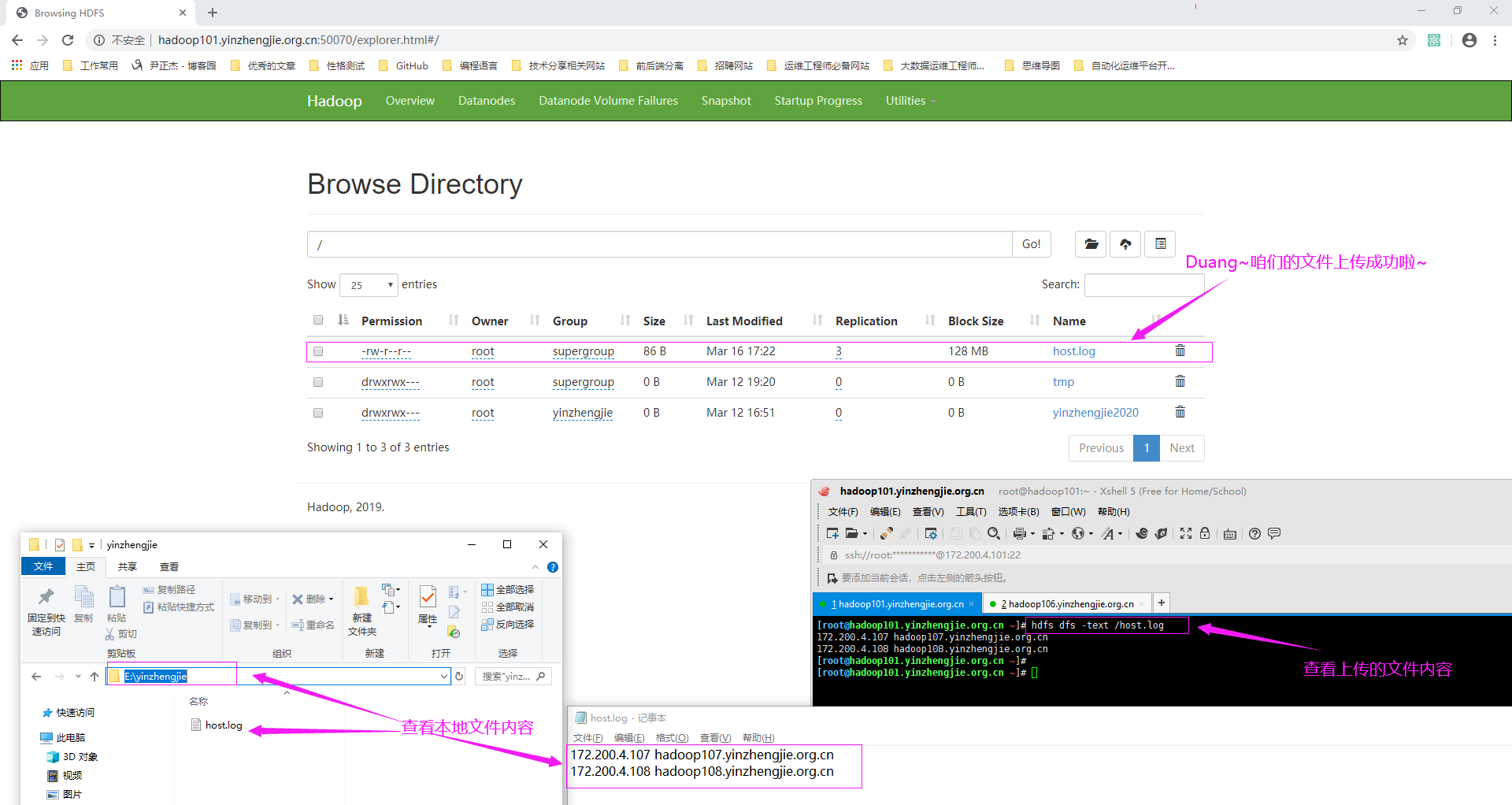
3>.再次访问NameNode的WebUI
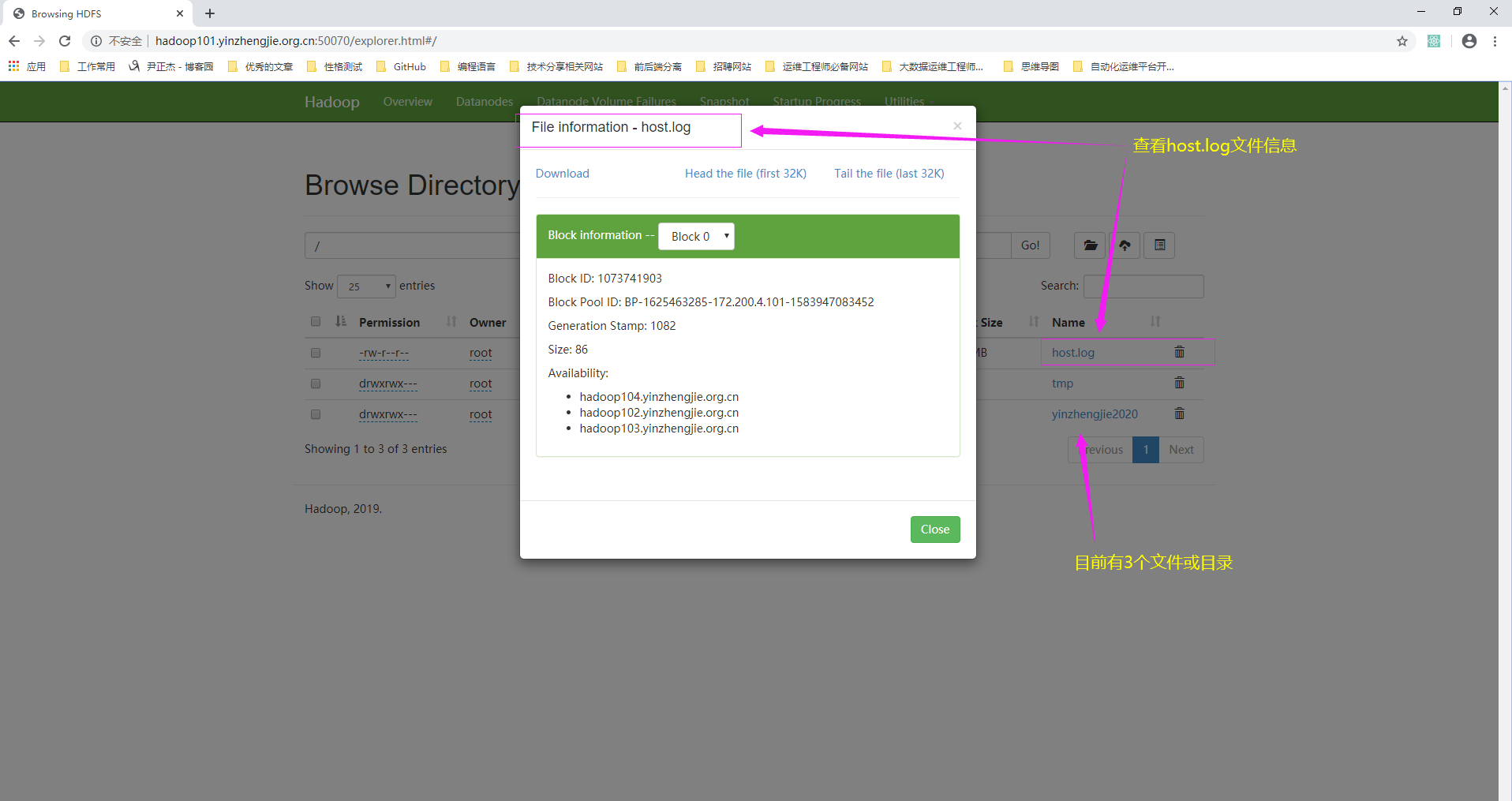
七.获取HDFS文件详情
1>.访问NameNode的WebUI及命令行递归查看文件列表
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls -R / -rw-r--r-- 3 root supergroup 86 2020-03-16 17:22 /host.log drwxrwx--- - root supergroup 0 2020-03-12 19:20 /tmp drwxrwx--- - root supergroup 0 2020-03-12 15:40 /tmp/hadoop-yarn drwxrwx--- - root supergroup 0 2020-03-12 16:22 /tmp/hadoop-yarn/staging drwxrwx--- - root supergroup 0 2020-03-12 15:40 /tmp/hadoop-yarn/staging/history drwxrwx--- - root supergroup 0 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done drwxrwx--- - root supergroup 0 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done/2020 drwxrwx--- - root supergroup 0 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done/2020/03 drwxrwx--- - root supergroup 0 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done/2020/03/12 drwxrwx--- - root supergroup 0 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done/2020/03/12/000000 -rwxrwx--- 3 root supergroup 33748 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done/2020/03/12/000000/job_1583999614207_0001-1584001369965-root-word+count-1584001390351-1-1-SUCCEEDED-defau lt-1584001376310.jhist-rwxrwx--- 3 root supergroup 203051 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done/2020/03/12/000000/job_1583999614207_0001_conf.xml drwxrwxrwt - root supergroup 0 2020-03-12 16:22 /tmp/hadoop-yarn/staging/history/done_intermediate drwxrwx--- - root supergroup 0 2020-03-12 16:23 /tmp/hadoop-yarn/staging/history/done_intermediate/root drwx------ - root supergroup 0 2020-03-12 16:22 /tmp/hadoop-yarn/staging/root drwx------ - root supergroup 0 2020-03-12 19:20 /tmp/hadoop-yarn/staging/root/.staging drwxrwxrwt - root root 0 2020-03-12 19:20 /tmp/logs drwxrwx--- - root root 0 2020-03-12 19:20 /tmp/logs/root drwxrwx--- - root root 0 2020-03-12 19:20 /tmp/logs/root/logs drwxrwx--- - root root 0 2020-03-12 19:21 /tmp/logs/root/logs/application_1584011863930_0001 -rw-r----- 3 root root 58844 2020-03-12 19:21 /tmp/logs/root/logs/application_1584011863930_0001/hadoop103.yinzhengjie.org.cn_25441 -rw-r----- 3 root root 53748 2020-03-12 19:21 /tmp/logs/root/logs/application_1584011863930_0001/hadoop104.yinzhengjie.org.cn_34288 drwxrwx--- - root yinzhengjie 0 2020-03-12 16:51 /yinzhengjie2020 drwxrwx--- - root yinzhengjie 0 2020-03-12 16:51 /yinzhengjie2020/jobhistory drwxrwx--- - root yinzhengjie 0 2020-03-12 16:54 /yinzhengjie2020/jobhistory/manager drwxrwx--- - root yinzhengjie 0 2020-03-12 16:54 /yinzhengjie2020/jobhistory/manager/2020 drwxrwx--- - root yinzhengjie 0 2020-03-12 16:54 /yinzhengjie2020/jobhistory/manager/2020/03 drwxrwx--- - root yinzhengjie 0 2020-03-12 16:54 /yinzhengjie2020/jobhistory/manager/2020/03/12 drwxrwx--- - root yinzhengjie 0 2020-03-12 19:20 /yinzhengjie2020/jobhistory/manager/2020/03/12/000000 -rwxrwx--- 2 root yinzhengjie 33731 2020-03-12 16:54 /yinzhengjie2020/jobhistory/manager/2020/03/12/000000/job_1584002509171_0001-1584003247341-root-word+count-1584003263906-1-1-SUCCEEDED-default -1584003252477.jhist-rwxrwx--- 2 root yinzhengjie 202992 2020-03-12 16:54 /yinzhengjie2020/jobhistory/manager/2020/03/12/000000/job_1584002509171_0001_conf.xml -rwxrwx--- 2 root yinzhengjie 33735 2020-03-12 19:09 /yinzhengjie2020/jobhistory/manager/2020/03/12/000000/job_1584010951301_0001-1584011344282-root-word+count-1584011360241-1-1-SUCCEEDED-default -1584011349879.jhist-rwxrwx--- 2 root yinzhengjie 202988 2020-03-12 19:09 /yinzhengjie2020/jobhistory/manager/2020/03/12/000000/job_1584010951301_0001_conf.xml -rwxrwx--- 2 root yinzhengjie 33732 2020-03-12 19:20 /yinzhengjie2020/jobhistory/manager/2020/03/12/000000/job_1584011863930_0001-1584012039874-root-word+count-1584012056179-1-1-SUCCEEDED-default -1584012045689.jhist-rwxrwx--- 2 root yinzhengjie 202988 2020-03-12 19:20 /yinzhengjie2020/jobhistory/manager/2020/03/12/000000/job_1584011863930_0001_conf.xml drwxrwxrwt - root yinzhengjie 0 2020-03-12 16:54 /yinzhengjie2020/jobhistory/tmp drwxrwx--- - root yinzhengjie 0 2020-03-12 19:20 /yinzhengjie2020/jobhistory/tmp/root [root@hadoop101.yinzhengjie.org.cn ~]#
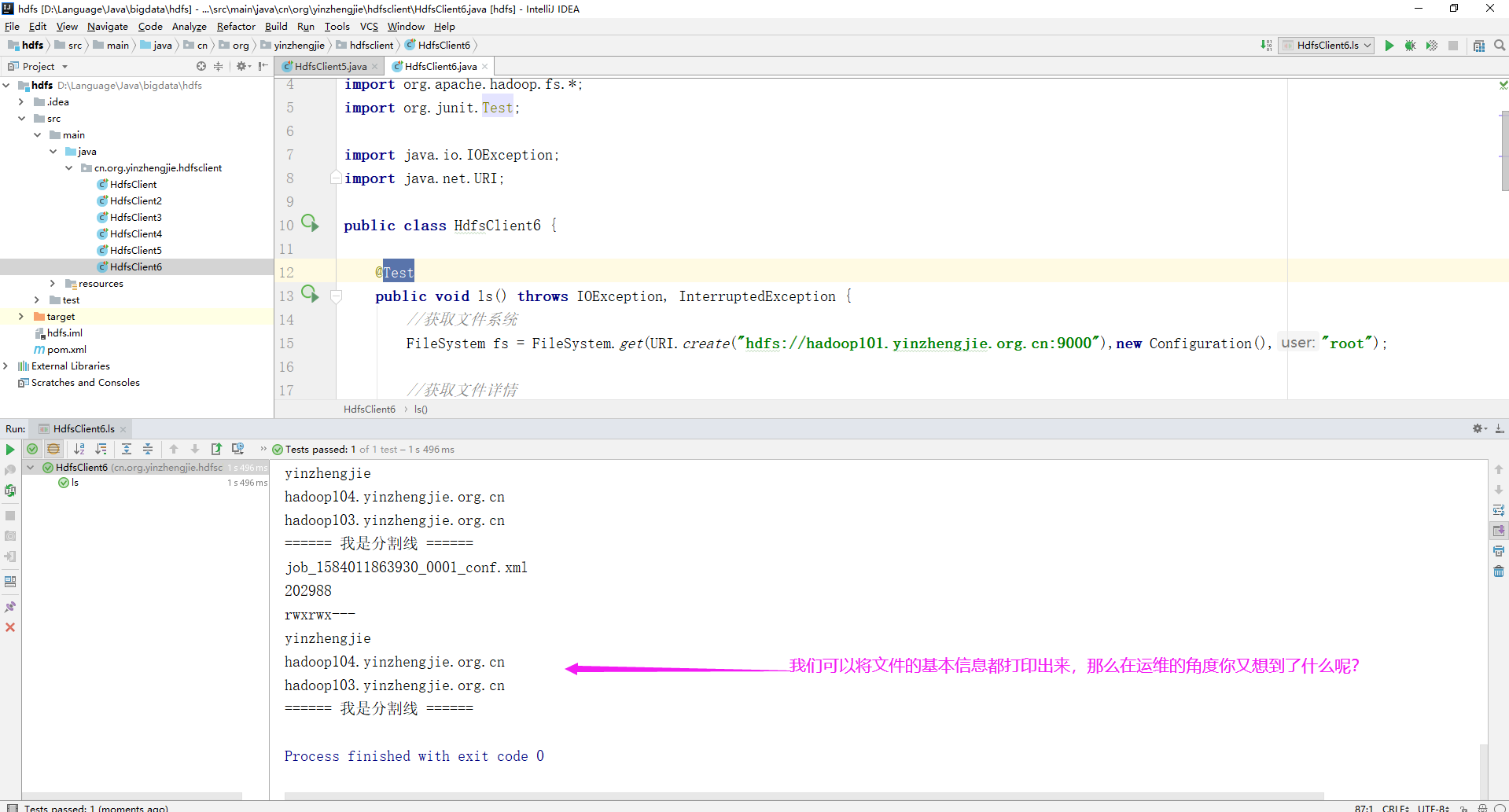
2>.编写JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.Test; import java.io.IOException; import java.net.URI; public class HdfsClient6 { @Test public void ls() throws IOException, InterruptedException { //获取文件系统 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),new Configuration(),"root"); //获取文件详情 RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); while (listFiles.hasNext()){ LocatedFileStatus status = listFiles.next(); //获取文件名称 System.out.println(status.getPath().getName()); //获取文件长度 System.out.println(status.getLen()); //获取文件权限 System.out.println(status.getPermission()); //获取分组权限 System.out.println(status.getGroup()); //获取存储的块信息 BlockLocation[] blockLocations = status.getBlockLocations(); for (BlockLocation block : blockLocations){ //获取块存储的主机节点 String[] hosts = block.getHosts(); for (String host:hosts){ System.out.println(host); } } System.out.println("======"); } //释放资源 fs.close(); } }
3>.代码执行结果
host.log 86 rw-r--r-- supergroup hadoop104.yinzhengjie.org.cn hadoop102.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1583999614207_0001-1584001369965-root-word+count-1584001390351-1-1-SUCCEEDED-default-1584001376310.jhist 33748 rwxrwx--- supergroup hadoop104.yinzhengjie.org.cn hadoop102.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1583999614207_0001_conf.xml 203051 rwxrwx--- supergroup hadoop104.yinzhengjie.org.cn hadoop102.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== hadoop103.yinzhengjie.org.cn_25441 58844 rw-r----- root hadoop104.yinzhengjie.org.cn hadoop102.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== hadoop104.yinzhengjie.org.cn_34288 53748 rw-r----- root hadoop104.yinzhengjie.org.cn hadoop102.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1584002509171_0001-1584003247341-root-word+count-1584003263906-1-1-SUCCEEDED-default-1584003252477.jhist 33731 rwxrwx--- yinzhengjie hadoop104.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1584002509171_0001_conf.xml 202992 rwxrwx--- yinzhengjie hadoop104.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1584010951301_0001-1584011344282-root-word+count-1584011360241-1-1-SUCCEEDED-default-1584011349879.jhist 33735 rwxrwx--- yinzhengjie hadoop104.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1584010951301_0001_conf.xml 202988 rwxrwx--- yinzhengjie hadoop104.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1584011863930_0001-1584012039874-root-word+count-1584012056179-1-1-SUCCEEDED-default-1584012045689.jhist 33732 rwxrwx--- yinzhengjie hadoop104.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ====== job_1584011863930_0001_conf.xml 202988 rwxrwx--- yinzhengjie hadoop104.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn ====== 我是分割线 ======
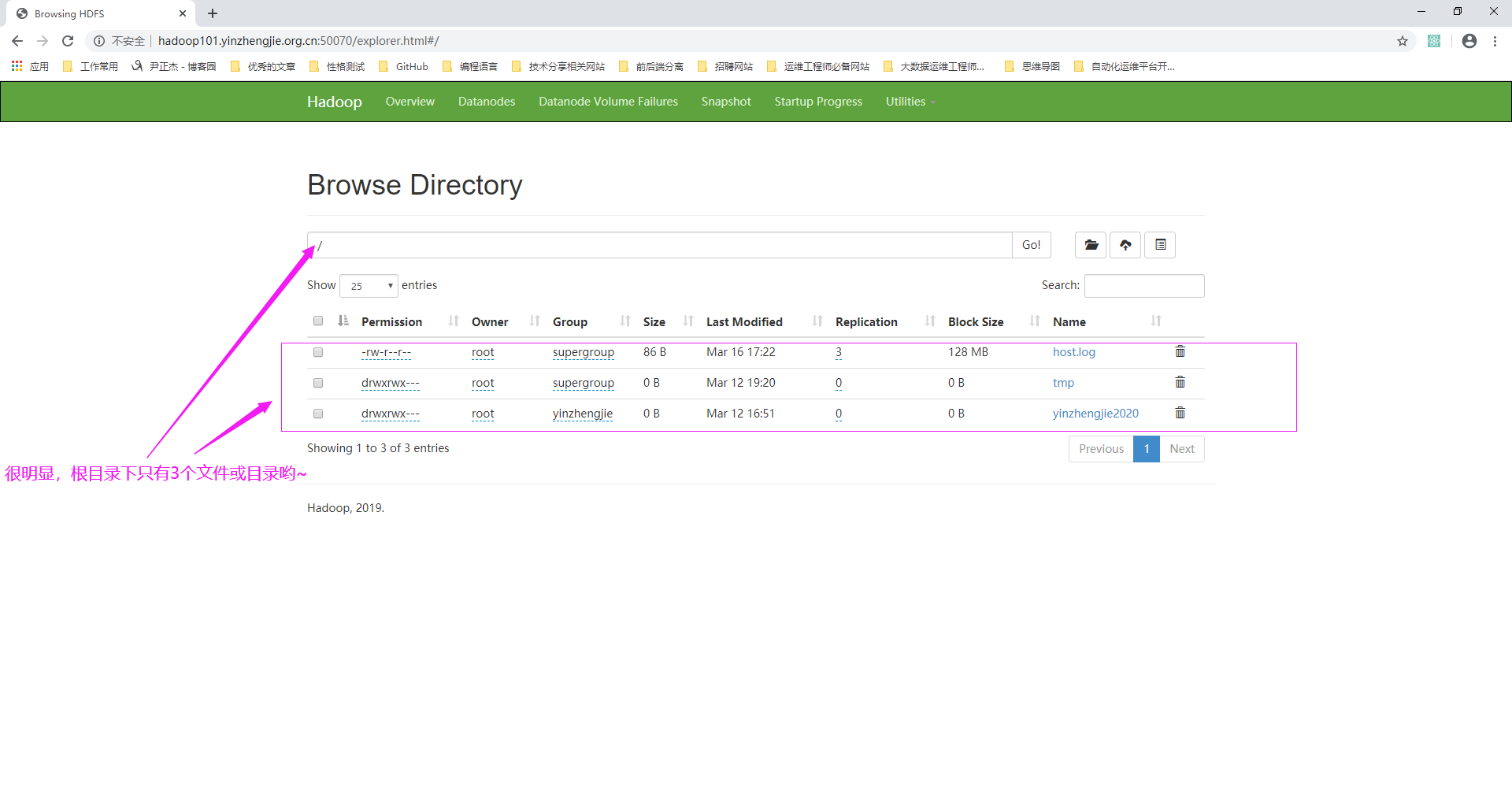
八.HDFS的文件和文件夹判断
1>.访问NameNode的WebUI
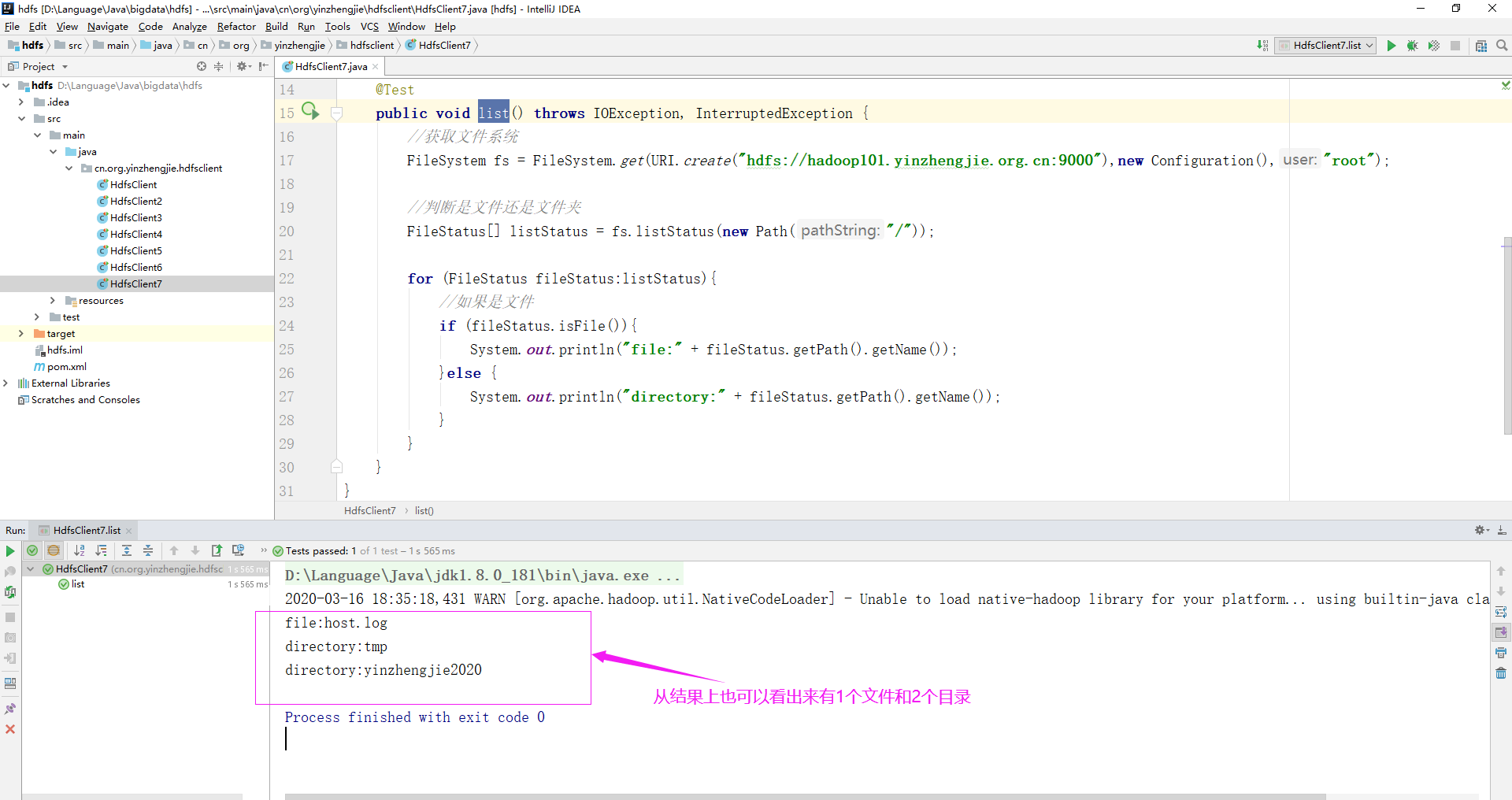
2>.编写JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.Test; import java.io.IOException; import java.net.URI; public class HdfsClient7 { @Test public void list() throws IOException, InterruptedException { //获取文件系统 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),new Configuration(),"root"); //判断是文件还是文件夹 FileStatus[] listStatus = fs.listStatus(new Path("/")); for (FileStatus fileStatus:listStatus){ //如果是文件 if (fileStatus.isFile()){ System.out.println("file:" + fileStatus.getPath().getName()); }else { System.out.println("directory:" + fileStatus.getPath().getName()); } } } }
3>.代码执行结果
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186
