
HDFS集群PB级数据迁移方案-DistCp生产环境实操篇
HDFS集群PB级数据迁移方案-DistCp生产环境实操篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
用了接近2个星期的时间,终于把公司的需要的大数据组建部署完毕了,当然,在部署的过程中踩了不少坑,自己也对系统,网络,各个大数据生态圈常用软件进行了调优操作,后期等我整理好笔记后会分享给大家参考的。集群是部署好了,但是没有数据的话也没有人会去用。因此我们需要把旧集群的数据迁移至新集群中(旧集群的数据都是存放在云平台上的,而新集群),在迁移的过程中,参考网上的很多解决方案,最终选择了distcp,官网文档也是相当的友好啊,大家一看就懂(我在下文已经给出了相应的链接)。
温馨提示:我的hadoop采用的是CDH方式部署的,对于不同Hadoop版本间的拷贝,用户应该使用HftpFileSystem。 这是一个只读文件系统,所以DistCp必须运行在目标端集群上(更确切的说是在能够写入目标集群的TaskTracker上)。 源的格式是 hftp://<dfs.http.address>/<path> (默认情况dfs.http.address是 <namenode>:50070)。
一.DistCp注意事项
1>.什么是DistCp
用官方的话解释就是:DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。 它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。 它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。 由于使用了Map/Reduce方法,这个工具在语义和执行上都会有特殊的地方。 这篇文档会为常用DistCp操作提供指南并阐述它的工作模型。
2>.使用方法
请参考官网:http://hadoop.apache.org/docs/r1.0.4/cn/distcp.html。
3>.DistCp的注意事项(摘自官网)
1>.DistCp会尝试着均分需要拷贝的内容,这样每个map拷贝差不多相等大小的内容。 但因为文件是最小的拷贝粒度,所以配置增加同时拷贝(如map)的数目不一定会增加实际同时拷贝的数目以及总吞吐量。 2>.如果没使用-m选项,DistCp会尝试在调度工作时指定map的数目 为 min (total_bytes / bytes.per.map, 20 * num_task_trackers), 其中bytes.per.map默认是256MB。 3>.建议对于长时间运行或定期运行的作业,根据源和目标集群大小、拷贝数量大小以及带宽调整map的数目。 4>.对于不同Hadoop版本间的拷贝,用户应该使用HftpFileSystem。 这是一个只读文件系统,所以DistCp必须运行在目标端集群上(更确切的说是在能够写入目标集群的TaskTracker上)。 源的格式是 hftp://<dfs.http.address>/<path> (默认情况dfs.http.address是 <namenode>:50070)。 5>.Map/Reduce和副效应 像前面提到的(参考官网),map拷贝输入文件失败时,会带来一些副效应。 5.1>.除非使用了-i,任务产生的日志会被新的尝试替换掉。 5.2>.除非使用了-overwrite,文件被之前的map成功拷贝后当又一次执行拷贝时会被标记为 "被忽略"。 5.3>.如果map失败了mapred.map.max.attempts次,剩下的map任务会被终止(除非使用了-i)。 5.4>.如果mapred.speculative.execution被设置为 final和true,则拷贝的结果是未定义的。
二.DistCp使用案例
[root@node105 ~]# hostname node105.yinzhengjie.org.cn [root@node105 ~]# [root@node105 ~]# free -h total used free shared buff/cache available Mem: 17G 2.2G 8.3G 11M 6.9G 14G Swap: 8.9G 0B 8.9G [root@node105 ~]# [root@node105 ~]# [root@node105 ~]# hadoop distcp usage: distcp OPTIONS [source_path...] <target_path> OPTIONS -append Reuse existing data in target files and append new data to them if possible -async Should distcp execution be blocking -atomic Commit all changes or none -bandwidth <arg> Specify bandwidth per map in MB -blocksperchunk <arg> If set to a positive value, fileswith more blocks than this value will be split into chunks of <blocksperchunk> blocks to be transferred in parallel, and reassembled on the destination. By default, <blocksperchunk> is 0 and the files will be transmitted in their entirety without splitting. This switch is only applicable when the source file system implements getBlockLocations method and the target file system implements concat method -copybuffersize <arg> Size of the copy buffer to use. By default <copybuffersize> is 8192B. -delete Delete from target, files missing in source -diff <arg> Use snapshot diff report to identify the difference between source and target -f <arg> List of files that need to be copied -filelimit <arg> (Deprecated!) Limit number of files copied to <= n -filters <arg> The path to a file containing a list of strings for paths to be excluded from the copy. -i Ignore failures during copy -log <arg> Folder on DFS where distcp execution logs are saved -m <arg> Max number of concurrent maps to use for copy -mapredSslConf <arg> Configuration for ssl config file, to use with hftps://. Must be in the classpath. -numListstatusThreads <arg> Number of threads to use for building file listing (max 40). -overwrite Choose to overwrite target files unconditionally, even if they exist. -p <arg> preserve status (rbugpcaxt)(replication, block-size, user, group, permission, checksum-type, ACL, XATTR, timestamps). If -p is specified with no <arg>, then preserves replication, block size, user, group, permission, checksum type and timestamps. raw.* xattrs are preserved when both the source and destination paths are in the /.reserved/raw hierarchy (HDFS only). raw.* xattrpreservation is independent of the -p flag. Refer to the DistCp documentation for more details. -rdiff <arg> Use target snapshot diff report to identify changes made on target -sizelimit <arg> (Deprecated!) Limit number of files copied to <= n bytes -skipcrccheck Whether to skip CRC checks between source and target paths. -strategy <arg> Copy strategy to use. Default is dividing work based on file sizes -tmp <arg> Intermediate work path to be used for atomic commit -update Update target, copying only missingfiles or directories [root@node105 ~]#
[root@calculation101 ~]# hdfs dfs -du -h /user/kuaikan/report_new/2018/10/

[root@node105 ~]# hostname node105.yinzhengjie.org.cn [root@node105 ~]# [root@node105 ~]# su hdfs [hdfs@node105 root]$ [hdfs@node105 root]$ hdfs dfs -mkdir -p /yinzhengjie/data/ [hdfs@node105 root]$ [hdfs@node105 root]$ hdfs dfs -chown -R root:root /yinzhengjie/data/ [hdfs@node105 root]$ [hdfs@node105 root]$ exit exit [root@node105 ~]# [root@node105 ~]# hdfs dfs -ls /yinzhengjie Found 1 items drwxr-xr-x - root root 0 2018-10-29 03:29 /yinzhengjie/data [root@node105 ~]#
[root@node105 ~]# jps 17617 NameNode 17985 DFSZKFailoverController 18406 Bootstrap 11047 Jps [root@node105 ~]# [root@node105 ~]# mkdir /yinzhengjie [root@node105 ~]# [root@node105 ~]# [root@node105 ~]# nohup time hadoop distcp hdfs://10.1.1.111:8020/user/kuaikan/report_new/2018/10/23 hdfs://node105.yinzhengjie.org.cn:8020//yinzhengjie/data >> /yinzhengjie/distcp.log 2>&1 & [1] 11125 [root@node105 ~]# [root@node105 ~]# jobs [1]+ Running nohup time hadoop distcp hdfs://10.1.1.111:8020/user/kuaikan/report_new/2018/10/23 hdfs://node105.yinzhengjie.org.cn:8020//yinzhengjie/data >> /yinzhengjie/distcp.log 2>&1 & [root@node105 ~]# [root@node105 ~]# jps 17617 NameNode 17985 DFSZKFailoverController 11126 DistCp ------>注意,开始拷贝的同时,distcp也启动了相应的进程。 18406 Bootstrap 11357 Jps [root@node105 ~]# [root@node105 ~]# hostname node105.yinzhengjie.org.cn [root@node105 ~]# [root@node105 ~]# free -h total used free shared buff/cache available Mem: 17G 2.4G 8.1G 11M 7.0G 14G Swap: 8.9G 0B 8.9G [root@node105 ~]#
[root@node105 ~]# tail -100f /yinzhengjie/distcp.log
[root@node105 ~]# jobs [root@node105 ~]# [root@node105 ~]# jps 17617 NameNode 17985 DFSZKFailoverController 18406 Bootstrap 15097 Jps [root@node105 ~]# [root@node105 ~]# [root@node105 ~]# tail -35f /yinzhengjie/distcp.log
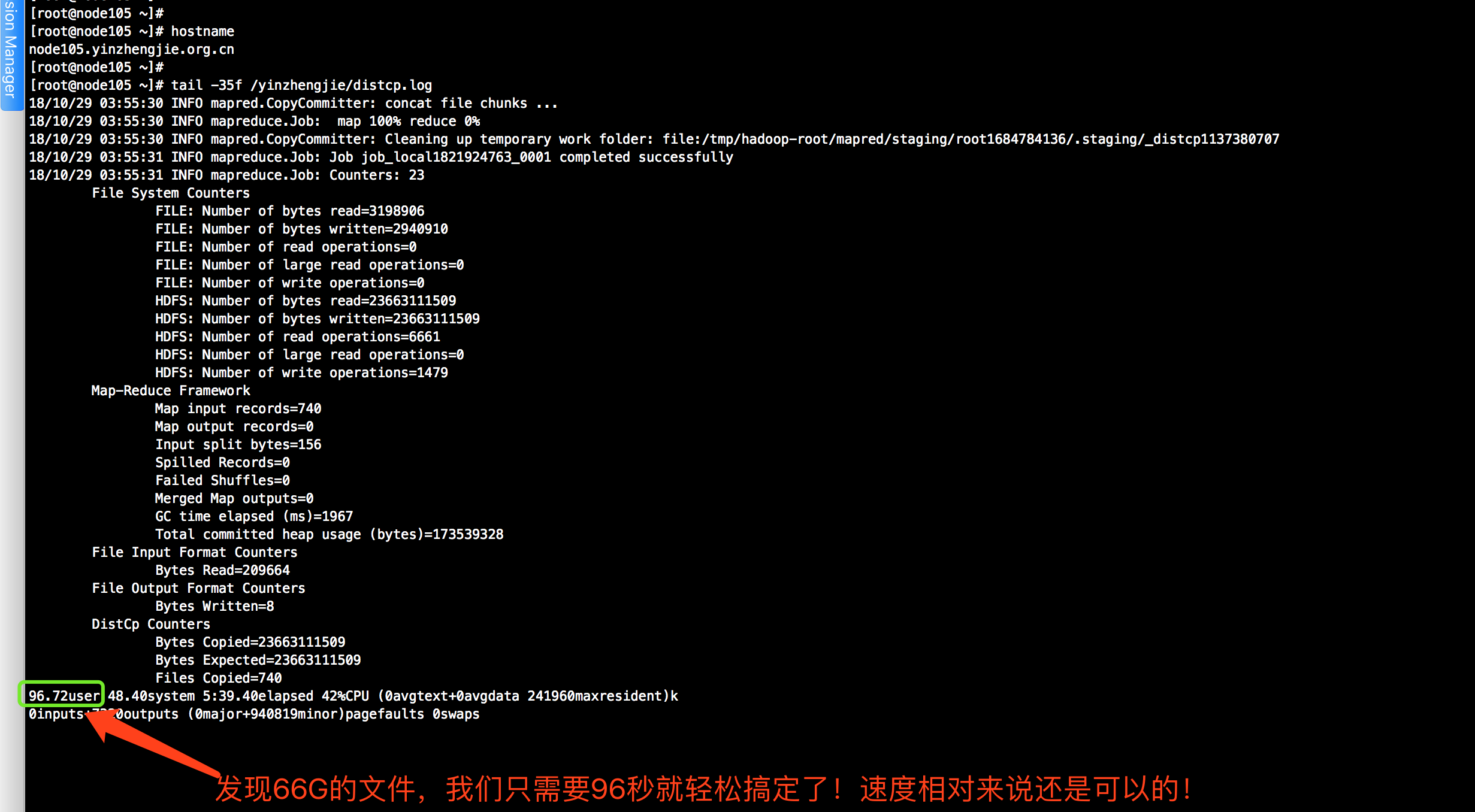
[root@node105 ~]# hdfs dfs -ls /yinzhengjie/data Found 1 items drwxr-xr-x - root root 0 2018-10-29 03:55 /yinzhengjie/data/23 [root@node105 ~]# [root@node105 ~]# hdfs dfs -du -h /yinzhengjie/data 22.0 G 66.1 G /yinzhengjie/data/23 [root@node105 ~]# [root@node105 ~]# hostname node105.yinzhengjie.org.cn [root@node105 ~]#

三.自定义脚本实现自动拷贝(结合我的生产环境)
我上面只是对distcp对简单使用,生产环境我们需要编写脚本,让他自己迁移数据。下面是我在生产环境中使用的一个简单的shell脚本:可供参考
1 #!/bin/bash 2 #@author :yinzhengjie 3 #blog:http://www.cnblogs.com/yinzhengjie 4 #EMAIL:y1053419035@qq.com 5 6 7 #判断用户输入的参数是否合法,我这个脚本要求传入3个参数,第一个参数是数据库名称,第二个参数是表面,第三个参数是具体的日期。 8 if [ $# -eq 3 ];then 9 vl=`expr length $3` 10 if [ $vl -ne '8' ];then 11 echo "`date` ERROR:Input '$dateValue' should be 'YYYYMMDD'" 12 exit 1 13 fi 14 dateValue=`date -d "0 day ago $3" +"%Y%m%d"` 15 else 16 dateValue=`date -d"-1 days" +"%Y%m%d"` 17 fi 18 19 20 #用来提示任务即将启动,标志着任务的开始 21 echo "`date` copy work of table $2 on database $1 start, dateValue is $dateValue " 22 23 24 #将旧机群的数据拷贝至新集群,并将日志保存在:"/yinzhengjie/distcp.log" 25 #nohup time hadoop distcp hdfs://uhadoop-2mqmxu-master2:8020/user/hive/warehouse/$1.db/$2/dt=${dateValue} hdfs://node101.yinzhengjie.org.cn:8020/user/hive/warehouse/$1.db/$2 >> /yinzhengjie/distcp.log 2>&1 & 26 time hadoop distcp hdfs://uhadoop-2mqmxu-master2:8020/user/hive/warehouse/$1.db/$2/dt=${dateValue} hdfs://node101.yinzhengjie.org.cn:8020/user/hive/warehouse/$1.db/$2 27 28 #用来提示任务执行完毕,标志着拷贝完成 29 echo "`date` copy work of table $2 on database $1 done, dateValue is $dateValue "
注意,执行distcp命令是支持带宽限速的,迁移数据我们走的是专线,但是distcp会将带宽流量吃满,导致其他的业务在高峰期使用这条专线的时候存在丢包的情况。感兴趣的小伙伴可以调试一下他的相关参数。当然,测试起来会很麻烦,你得调试参数,还得使用监控软件实时监控到专线带宽的使用量。我索性在高峰期就不启动distcp进程,写了一个python脚本仅供大家参考。
1 #!/usr/bin/python 2 # -*- coding: utf-8 -*- 3 #@author :yinzhengjie 4 #blog:http://www.cnblogs.com/yinzhengjie/tag/python%E8%87%AA%E5%8A%A8%E5%8C%96%E8%BF%90%E7%BB%B4%E4%B9%8B%E8%B7%AF/ 5 #EMAIL:y1053419035@qq.com 6 7 8 import json 9 import subprocess 10 import threading 11 import time 12 from datetime import datetime, timedelta #我们将获取时间的包倒入。 13 14 #获取当前操作系统的时间 15 today = datetime.today() 16 17 18 19 #这个函数是用来操作系统运行命令的脚本,需要传入2个参数,第一个参数是执行的命令,第二个参数是shell的布尔直,调用复杂的linux命令(比如:"df -h | grep /dev/sda1")的方法,需要加“shell=True” 20 def runCommand(cmdstring, isTrue=False): 21 cmdstring_list = cmdstring.split() 22 #调用复杂的linux命令的方法,需要加“shell=True”,表示将前面引号的内容放在一个终端(terminal)去执行, 23 p = subprocess.Popen(cmdstring_list, stdout=subprocess.PIPE, stderr=subprocess.STDOUT,shell=isTrue) 24 #communicate() 等待任务结束,并将结果输入的结果复制给变量。使用两个out变量接受输出结果,使用err变量接受error信息 25 out,err = p.communicate() 26 #需要注意的是这个不能保存命令输出的结果,而是保存命令执行的结果哟!一般非“0”就表示命令没有执行成功,而结果是“0”表示执行命令实成功的,但是命令的输出结果是无法保存的!切记! 27 ret = p.returncode 28 return ret,out,err 29 30 31 32 #咱们这里的定义了一个线程类,主要是用来调用我们需要指定的Linux脚本。 33 class myThread(threading.Thread): 34 cmd='' 35 36 def __init__(self,cmd): 37 threading.Thread.__init__(self) 38 self.cmd = cmd 39 40 def run(self): 41 print datetime.today().__str__().split('.')[0] 42 print "Thread: '%s' started." % (self.cmd) 43 ret,out,err = runCommand(self.cmd) 44 print out 45 print err 46 print "Thread: '%s' finished." % (self.cmd) 47 48 49 50 # 顾名思义,这里定义获取日期的函数,里面需要传入一个参数,参数的默认值是1,也就是说默认你会获取到一天以前的时间。比如当前的时间是"2018-10-30 15:19:23.620339",则返回:"20181029" 51 def getDate(delta=1): 52 #注意,timedelta(delta)函数可以指定一个周期,需要传入一个int类型的参数,基本单位是day, 53 mydate = today - timedelta(delta) 54 #返回值是将mydate转换成字符串,并用字符串的split方法将其变成一个数组并取得第一个元素,并将取出来的元素中含有"-"给去除掉。 55 return (mydate.__str__().split())[0].replace('-','') 56 57 58 # 该函数的功能和上面的getDate函数功能基本一样,里面也需要传入一个参数,参数的默认值是1,也就是说默认你会获取到一天以前的时间。比如当前的时间是"2018-10-30 15:19:23.620339",则返回:"2018_10_29" 59 def getDate_ex(delta=1): 60 today = datetime.today() 61 mydate = today - timedelta(delta) 62 return (mydate.__str__().split())[0].replace('-','_') 63 64 65 #定义获取当前小时的方法 66 def getDate_hour(): 67 return (datetime.today().__str__().split())[1].split(":")[0] 68 69 print getDate_hour() 70 71 date_list=[] 72 73 date_list_ex=[] 74 75 threads=[] 76 77 78 #设置总线程个数,根据你的服务器性能以及贷款的大小,选择合适的线程数,由于我们专线带宽就2G,还要保证kafka的传输带宽,因此我这里给出3个。 79 total_thread_num=3 80 81 82 #业务逻辑如下:第一个参数是当前时间距离需要迁移的天数的时间,比如我从距离225天(温馨提示:可以使用"date -d "225 days ago"进行运算。)开始拷贝数据,距离400天前时结束。 83 for delta in range(225,400): 84 while(True): 85 hour=getDate_hour() 86 current_thread_num = 0 87 for thread in threads: 88 if thread.isAlive(): 89 current_thread_num += 1 90 #由于迁移数据时,我们需要避免掉高峰期,我们的专线只有2G的带宽,在高峰期传输的话,会导致kafka集群出现数据丢失的情况! 91 if (current_thread_num >= total_thread_num or hour in ('19','20','21','22')): 92 print "%s\tThreading pool is full. Waiting for 60s..." % (datetime.today().__str__().split('.')[0]) 93 time.sleep(30) 94 continue 95 else: 96 break 97 date=getDate(delta) 98 time.sleep(10) 99 #注意,下面的"/data/extract/tablecp/tablecp_storage.sh" 就是我上面关于distcp的shell脚本。 100 current_thread = myThread("/data/extract/tablecp/tablecp_storage.sh yingshi ad_sarrs_hour " + date) 101 current_thread.start() 102 threads.append(current_thread) 103 104 print datetime.today().__str__().split('.')[0], 105 print "\tAll task finished."
后记:由于我司带宽专线仅有10G带宽,在没有其他业务时,迁移数据时速度还凑合,但是随着业务不断往我们的新建数据中心迁移时,发现带宽是实时打满的,导致日志收集出现丢包的情况,被迫研究了一下带宽的限速,重新修改了一下脚本:


#!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com if [ $# -eq 3 ];then vl=`expr length $3` if [ $vl -ne '8' ];then echo "`date` ERROR:Input '$dateValue' should be 'YYYYMMDD'" exit 1 fi dateValue=`date -d "0 day ago $3" +"%Y%m%d"` else dateValue=`date -d"-1 days" +"%Y%m%d"` fi echo "`date` copy work of table $2 on database $1 start, dateValue is $dateValue " hadoop distcp -Dmapred.jobtracker.maxtasks.per.job=1 -Dmapred.job.max.map.running=1 -Ddistcp.bandwidth=8192 hdfs://uhadoop-2mqmxu-master2:8020/user/hive/warehouse/$1.db/$2/dt=${dateValue} hdfs://10.1.3.101:8020/user/hive/warehouse/$1.db/$2 echo "`date` copy work of table $2 on database $1 done, dateValue is $dateValue "
Hadoop 1版本 distcp [OPTIONS] <srcurl> * <desturl> 选项: -p [rbugp] 状态 r:复制数 b:块大小 u:用户 g:组 p:权限 t:修改和访问时间 -p单独相当于-prbugpt -i 忽略失败 -basedir <basedir> 从<srcurl>复制文件时,使用<basedir>作为基本目录 -log <logdir> 将日志写入<logdir> -m <num_maps> 最大并发副本数 -overwrite 覆盖目的地 -update 如果src大小与dst大小不同,则覆盖 -skipcrccheck 不要使用CRC检查来确定src是否是 不同于dest。 -copybychunk 剁碎和复制的文件 -f <urilist_uri> 将<urilist_uri>中的列表用作src列表 -filelimit <n> 将文件的总数限制为<= n -filelimitpermap <n> 每个地图要复制的最大文件数 -sizelimit <n> 将总大小限制为<= n个字节 -sizelimitpermap <n> 每个映射要复制的最大字节数 -delete 删除dst中存在的文件,但不在src中 -mapredSslConf <f> 映射器任务的SSL配置文件名 -usefastcopy 使用FastCopy(仅适用于DFS) 注1:如果设置了-overwrite或-update,则每个源URI和目标URI保持同级一致。 例如: hadoop distcp -p -update hdfs://A:9000//home/aa hdfs://B:9000//home/bb 支持的通用选项是 -conf <configuration file>指定应用程序配置文件 -D <property = value>给定属性的使用值 -fs <local | namenode:port>指定一个namenode -jt <local | jobtracker:port>指定jobtracker在corona上 -jtold <local | jobtracker:port>指定jobtracker在mapreduce上 -files <逗号分隔的文件列表>指定要复制到map reduce cluster的逗号分隔文件 -libjars <逗号分隔的jars列表> 指定要包含在类路径中的逗号分隔的jar文件。 -archives <逗号分隔的归档列表> 指定要在计算机上取消归档的逗号分隔的归档。
Hadoop 2版本 用法:distcp OPTIONS [source_path ...] <target_path> OPTIONS -append 重新使用目标文件中的现有数据并追加新的如果可能,给他们的数据 -async 应该是distcp执行阻塞 -atomic 提交所有更改或无 -bandwidth <arg> 以MB为单位指定每个map的带宽,注意由于在互联网数据传输都是以二进制形式传输,因此,我们将MB的文件需要转换称大Mb需要乘以八个比特位,因此1Gb = 1024MB = 1024MB * 8bits = 8192Mb -delete 从目标中删除,源文件丢失 -diff <arg> 使用snapshot diff报告来标识源和目标之间的差异 -f <arg> 需要复制的文件列表 -filelimit <arg> (已弃用!)限制复制到<= n的文件数 -i 在复制期间忽略故障 -log <arg> DFS上的distcp执行日志文件夹保存 -m <arg> 要用于副本的最大并发map数 -mapredSslConf <arg> 配置ssl配置文件,用于hftps:// -overwrite 选择无条件覆盖目标文件,即使它们存在。 -p <arg> 保留源文件状态(rbugpcaxt) (复制,块大小,用户,组,权限,校验和类型,ACL,XATTR,时间戳) 如果-p是指定为no <arg>,然后保留复制,块大小,用户,组,权限,校验和类型和时间戳。 原始的* xattrs是源和目的地都保留路径位于/.reserved/raw层次结构中(HDF只要)。原始* xattrpreservation是独立的-p标志。请参阅DistCp文档更多细节。 -sizelimit <arg> (已弃用!)限制复制到<= n的文件数字节 -skipcrccheck 是否跳过源和源之间的CRC检查目标路径。 -strategy <arg> 复制策略使用。默认是分工基于文件大小 -tmp <arg> 要用于原子的中间工作路径承诺 -update 更新目标,仅复制missingfiles或目录
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/9872365.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号