
Spark进阶之路-Standalone模式搭建
Spark进阶之路-Standalone模式搭建
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Spark的集群的准备环境
1>.master节点信息(s101)
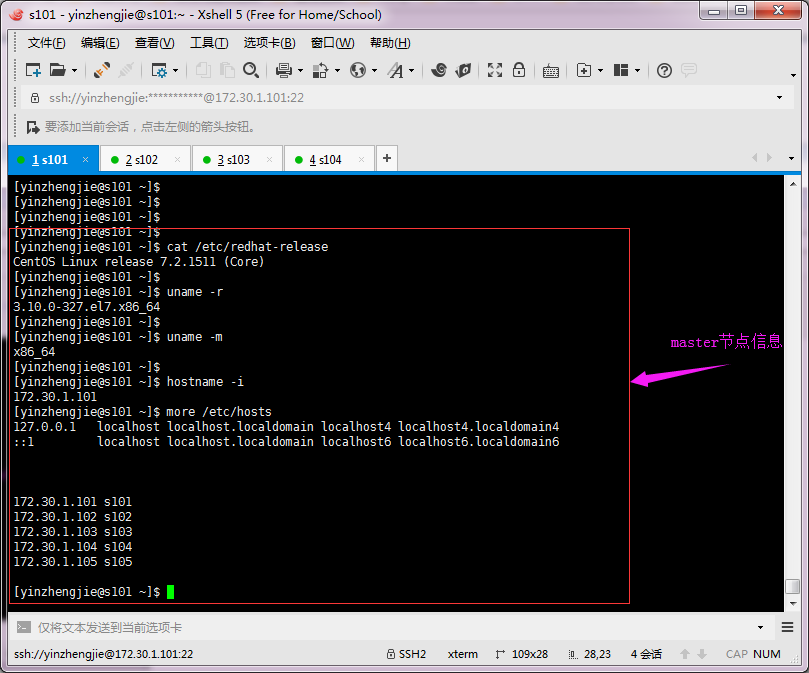
2>.worker节点信息(s102)

3>.worker节点信息(s103)

4>.worker节点信息(s104)

二.Spark的Standalone模式搭建
1>.下载Spark安装包
Spark下载地址:https://archive.apache.org/dist/spark/


[yinzhengjie@s101 download]$ sudo yum -y install wget [sudo] password for yinzhengjie: Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com Resolving Dependencies --> Running transaction check ---> Package wget.x86_64 0:1.14-15.el7_4.1 will be installed --> Finished Dependency Resolution Dependencies Resolved ===================================================================================================================================================================== Package Arch Version Repository Size ===================================================================================================================================================================== Installing: wget x86_64 1.14-15.el7_4.1 base 547 k Transaction Summary ===================================================================================================================================================================== Install 1 Package Total download size: 547 k Installed size: 2.0 M Downloading packages: wget-1.14-15.el7_4.1.x86_64.rpm | 547 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : wget-1.14-15.el7_4.1.x86_64 1/1 Verifying : wget-1.14-15.el7_4.1.x86_64 1/1 Installed: wget.x86_64 0:1.14-15.el7_4.1 Complete! [yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ wget https://archive.apache.org/dist/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz #下载你想要下载的版本
2>.解压配置文件
[yinzhengjie@s101 download]$ ll total 622512 -rw-r--r--. 1 yinzhengjie yinzhengjie 214092195 Aug 26 2016 hadoop-2.7.3.tar.gz -rw-r--r--. 1 yinzhengjie yinzhengjie 185540433 May 17 2017 jdk-8u131-linux-x64.tar.gz -rw-r--r--. 1 yinzhengjie yinzhengjie 201142612 Jul 25 2017 spark-2.1.1-bin-hadoop2.7.tgz -rw-r--r--. 1 yinzhengjie yinzhengjie 36667596 Jun 20 09:29 zookeeper-3.4.12.tar.gz [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /soft/ #加压Spark安装包到指定目录 [yinzhengjie@s101 download]$ ll /soft/ total 16 lrwxrwxrwx. 1 yinzhengjie yinzhengjie 19 Aug 13 10:31 hadoop -> /soft/hadoop-2.7.3/ drwxr-xr-x. 10 yinzhengjie yinzhengjie 4096 Aug 13 12:44 hadoop-2.7.3 lrwxrwxrwx. 1 yinzhengjie yinzhengjie 19 Aug 13 10:32 jdk -> /soft/jdk1.8.0_131/ drwxr-xr-x. 8 yinzhengjie yinzhengjie 4096 Mar 15 2017 jdk1.8.0_131 drwxr-xr-x. 12 yinzhengjie yinzhengjie 4096 Apr 25 2017 spark-2.1.1-bin-hadoop2.7 lrwxrwxrwx. 1 yinzhengjie yinzhengjie 23 Aug 13 12:13 zk -> /soft/zookeeper-3.4.12/ drwxr-xr-x. 10 yinzhengjie yinzhengjie 4096 Mar 27 00:36 zookeeper-3.4.12 [yinzhengjie@s101 download]$ ll /soft/spark-2.1.1-bin-hadoop2.7/ #查看目录结构 total 88 drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 Apr 25 2017 bin drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 Apr 25 2017 conf drwxr-xr-x. 5 yinzhengjie yinzhengjie 47 Apr 25 2017 data drwxr-xr-x. 4 yinzhengjie yinzhengjie 27 Apr 25 2017 examples drwxr-xr-x. 2 yinzhengjie yinzhengjie 8192 Apr 25 2017 jars -rw-r--r--. 1 yinzhengjie yinzhengjie 17811 Apr 25 2017 LICENSE drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 Apr 25 2017 licenses -rw-r--r--. 1 yinzhengjie yinzhengjie 24645 Apr 25 2017 NOTICE drwxr-xr-x. 8 yinzhengjie yinzhengjie 4096 Apr 25 2017 python drwxr-xr-x. 3 yinzhengjie yinzhengjie 16 Apr 25 2017 R -rw-r--r--. 1 yinzhengjie yinzhengjie 3817 Apr 25 2017 README.md -rw-r--r--. 1 yinzhengjie yinzhengjie 128 Apr 25 2017 RELEASE drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 Apr 25 2017 sbin drwxr-xr-x. 2 yinzhengjie yinzhengjie 41 Apr 25 2017 yarn [yinzhengjie@s101 download]$
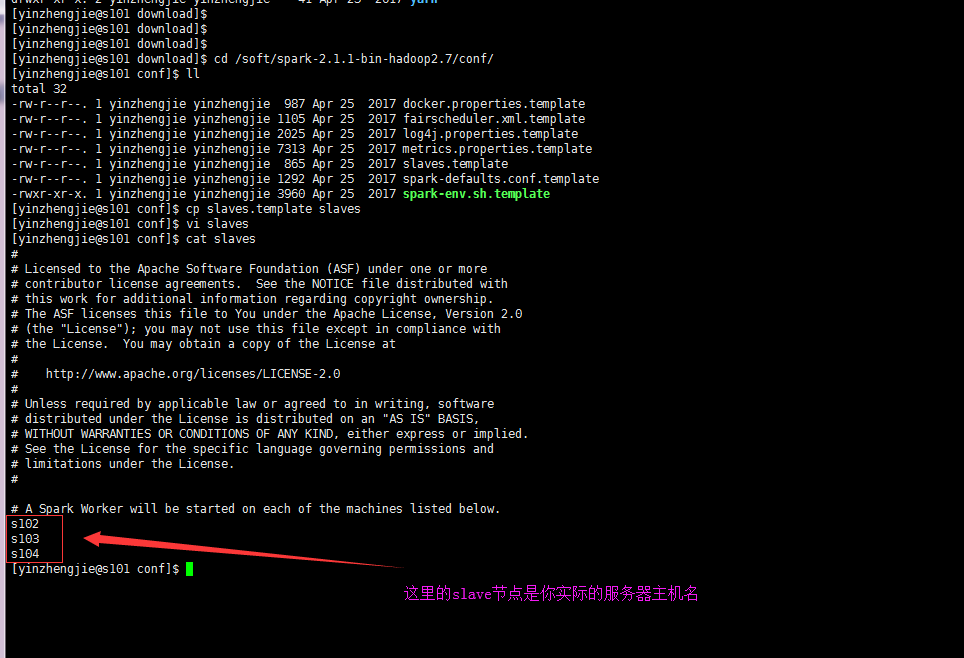
3>.编辑slaves配置文件,将worker的节点主机名输入,默认是localhost
[yinzhengjie@s101 download]$ cd /soft/spark-2.1.1-bin-hadoop2.7/conf/ [yinzhengjie@s101 conf]$ ll total 32 -rw-r--r--. 1 yinzhengjie yinzhengjie 987 Apr 25 2017 docker.properties.template -rw-r--r--. 1 yinzhengjie yinzhengjie 1105 Apr 25 2017 fairscheduler.xml.template -rw-r--r--. 1 yinzhengjie yinzhengjie 2025 Apr 25 2017 log4j.properties.template -rw-r--r--. 1 yinzhengjie yinzhengjie 7313 Apr 25 2017 metrics.properties.template -rw-r--r--. 1 yinzhengjie yinzhengjie 865 Apr 25 2017 slaves.template -rw-r--r--. 1 yinzhengjie yinzhengjie 1292 Apr 25 2017 spark-defaults.conf.template -rwxr-xr-x. 1 yinzhengjie yinzhengjie 3960 Apr 25 2017 spark-env.sh.template [yinzhengjie@s101 conf]$ cp slaves.template slaves [yinzhengjie@s101 conf]$ vi slaves [yinzhengjie@s101 conf]$ cat slaves # # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # A Spark Worker will be started on each of the machines listed below. s102 s103 s104 [yinzhengjie@s101 conf]$
4>.编辑spark-env.sh文件,指定master节点和端口号
[yinzhengjie@s101 ~]$ cp /soft/spark/conf/spark-env.sh.template /soft/spark/conf/spark-env.sh [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ echo export JAVA_HOME=/soft/jdk >> /soft/spark/conf/spark-env.sh [yinzhengjie@s101 ~]$ echo SPARK_MASTER_HOST=s101 >> /soft/spark/conf/spark-env.sh [yinzhengjie@s101 ~]$ echo SPARK_MASTER_PORT=7077 >> /soft/spark/conf/spark-env.sh [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ grep -v ^# /soft/spark/conf/spark-env.sh | grep -v ^$ export JAVA_HOME=/soft/jdk SPARK_MASTER_HOST=s101 SPARK_MASTER_PORT=7077 [yinzhengjie@s101 ~]$
5>.将s101的spark配置信息分发到worker节点
[yinzhengjie@s101 ~]$ more `which xrsync.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数"; exit fi #获取文件路径 file=$@ #获取子路径 filename=`basename $file` #获取父路径 dirpath=`dirname $file` #获取完整路径 cd $dirpath fullpath=`pwd -P` #同步文件到DataNode for (( i=102;i<=104;i++ )) do #使终端变绿色 tput setaf 2 echo =========== s$i %file =========== #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 rsync -lr $filename `whoami`@s$i:$fullpath #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [yinzhengjie@s101 ~]$
关于配置无秘钥登录请参考我之间的笔记:https://www.cnblogs.com/yinzhengjie/p/9065191.html。配置好无秘钥登录后,直接执行上面的脚本进行同步数据。
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark-2.1.1-bin-hadoop2.7/ =========== s102 %file =========== 命令执行成功 =========== s103 %file =========== 命令执行成功 =========== s104 %file =========== 命令执行成功 [yinzhengjie@s101 ~]$
6>.修改配置文件,将spark运行脚本添加至系统环境变量
[yinzhengjie@s101 ~]$ ln -s /soft/spark-2.1.1-bin-hadoop2.7/ /soft/spark #这里做一个软连接,方便简写目录名称 [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ sudo vi /etc/profile #修改系统环境变量的配置文件 [sudo] password for yinzhengjie: [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ tail -3 /etc/profile #ADD SPARK_PATH by yinzhengjie export SPARK_HOME=/soft/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ source /etc/profile #重写加载系统配置文件,使其变量在当前shell生效。 [yinzhengjie@s101 ~]$
7>.启动spark集群
[yinzhengjie@s101 ~]$ more `which xcall.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数" exit fi #获取用户输入的命令 cmd=$@ for (( i=101;i<=104;i++ )) do #使终端变绿色 tput setaf 2 echo ============= s$i $cmd ============ #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 ssh s$i $cmd #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ /soft/spark/sbin/start-all.sh #启动spark集群 starting org.apache.spark.deploy.master.Master, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.master.Master-1-s101.out s102: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s102.out s103: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s103.out s104: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s104.out [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ xcall.sh jps #查看进程master和slave节点是否起来了 ============= s101 jps ============ 17587 Jps 17464 Master 命令执行成功 ============= s102 jps ============ 12845 Jps 12767 Worker 命令执行成功 ============= s103 jps ============ 12523 Jps 12445 Worker 命令执行成功 ============= s104 jps ============ 12317 Jps 12239 Worker 命令执行成功 [yinzhengjie@s101 ~]$
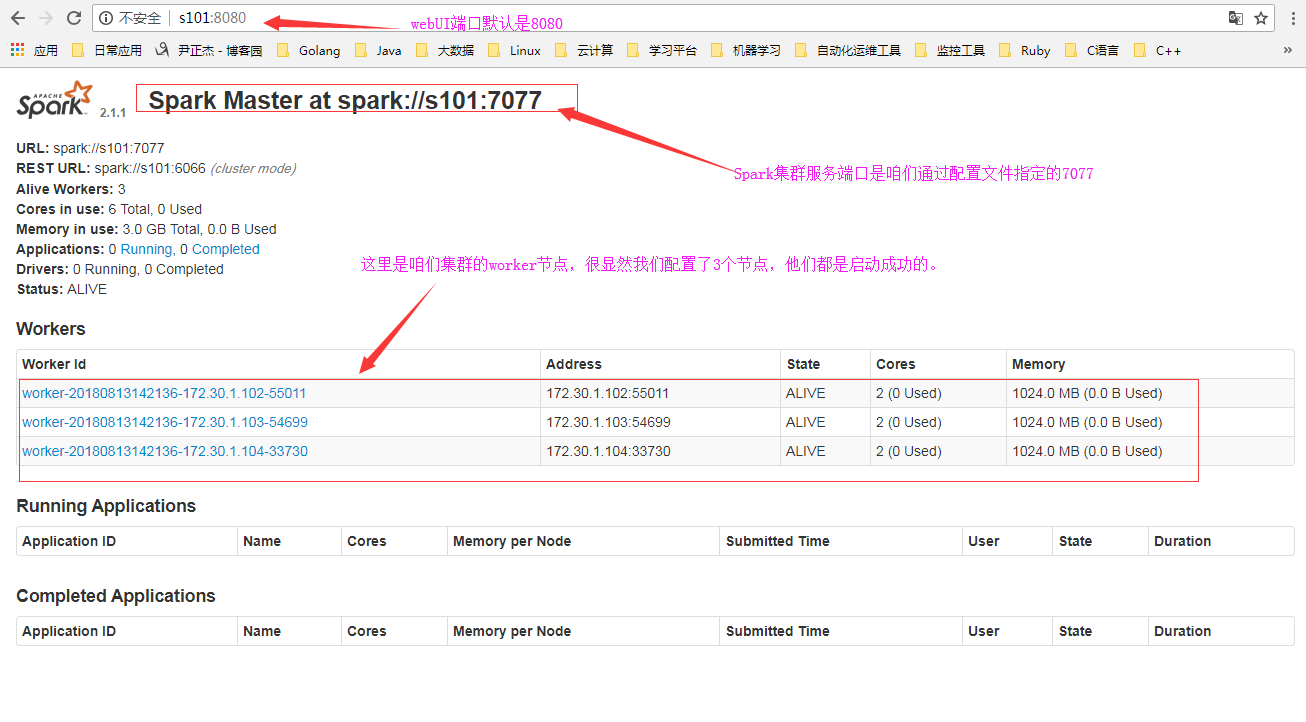
8>.检查Spark的webUI界面
9>.启动spark-shell

三.在Spark集群中执行Wordcount
1>.链接到master集群([yinzhengjie@s101 ~]$ spark-shell --master spark://s101:7077)

2>.登录webUI,查看正在运行的APP

3>.查看应用细节

4>.查看job的信息
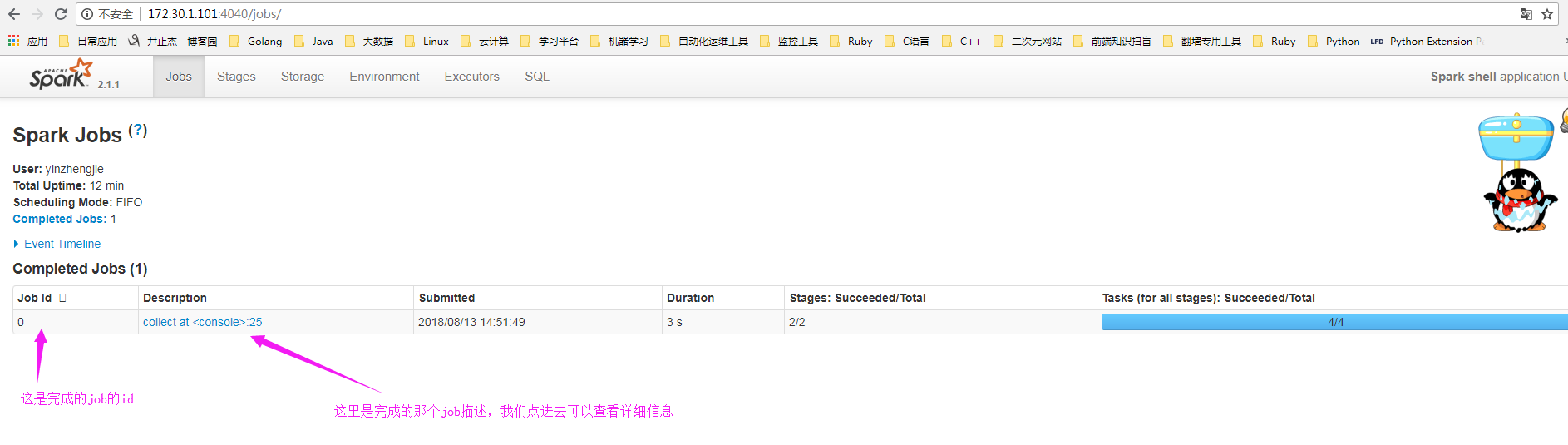
5>.查看stage

6>.查看具体的详细信息

7>.退出spark-shell

8>.查看spark的完成应用,发现日志没了?

那么问题来了。如果看日志呢?详情请参考:https://www.cnblogs.com/yinzhengjie/p/9410989.html。
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/9458161.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
