

Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.编写年度最高气温统计
如上图说所示:有一个temp的文件,里面存放的是每年的数据,该数据全部是文本内容,大小2M左右,我已将他放在百度云(链接:https://pan.baidu.com/s/1CEcHAXlII2kKxbn1dmTPKA 密码:jgp0),当你下载后,看到该文件的第15列到19列存放的是年份,而第87列到92列存放的是温度,注意999是无效值,需要排除! 最终测试实验结果如下:

其实这个跟我上次写的wordCount如出一辙,只需要稍微改动一下,就可以轻松实现这个统计结果,具体代码如下:


1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.maxtemp; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Mapper; 12 13 import java.io.IOException; 14 15 /** 16 * 我们定义的map端类为MaxTempMapper,它需要继承“org.apache.hadoop.mapreduce.Mapper.Mapper”, 17 * 该Mapper有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出 18 * key和value的数据类型。 19 */ 20 public class MaxTempMapper extends Mapper<LongWritable,Text,Text,IntWritable> { 21 22 /** 23 * 24 * @param key : 表示输入的key变量。 25 * @param value : 表示输入的value 26 * @param context : 表示map端的上下文,它是负责将map端数据传给reduce。 27 */ 28 @Override 29 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 30 //得到一行数据 31 String line = value.toString(); 32 //得到年份 33 String year = line.substring(15, 19); 34 //得到气温 35 int temp = Integer.parseInt(line.substring(87, 92)); 36 //判断temp不能为9999 37 if (temp != 9999){ 38 //通过上线文将yaer和temp发给reduce端 39 context.write(new Text(year),new IntWritable(temp)); 40 } 41 } 42 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.maxtemp; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import java.io.IOException; 12 13 /** 14 * 我们定义的reduce端类为MaxTempReducer,它需要继承“org.apache.hadoop.mapreduce.Reducer.Reducer”, 15 * 该Reducer有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出 16 * key和value的数据类型。 17 */ 18 public class MaxTempReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 19 /** 20 * 21 * @param key : 表示输入的key变量。这里的key实际上就是mapper端传过来的year。 22 * @param values : 表示输入的value,这个变量是可迭代的,因此传递的是多个值。这个value实际上就是传过来的temp。 23 * @param context : 表示reduce端的上下文,它是负责将reduce端数据传给调用者(调用者可以传递的数据输出到文件,也可以输出到下一个MapReduce程序。 24 */ 25 @Override 26 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 27 //给max变量定义一个最小的int初始值方便用于比较 28 int max = Integer.MIN_VALUE; 29 //由于输入端只有一个key,因此value的所有值都属于这个key的,我们需要做的是对value进行遍历并将所有数据进行相加操作,最终的结果就得到了同一个key的出现的次数。 30 for (IntWritable value : values){ 31 //获取到value的get方法获取到value的值。然后和max进行比较,将较大的值重新赋值给max 32 max = Math.max(max,value.get()); 33 } 34 //我们将key原封不动的返回,并将key的values的所有int类型的参数进行折叠,最终返回单词书以及该单词总共出现的次数。 35 context.write(key,new IntWritable(max)); 36 } 37 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.maxtemp; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import java.io.IOException; 17 18 public class MaxTempApp { 19 20 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 21 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 22 Configuration conf = new Configuration(); 23 //将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。 24 conf.set("fs.defaultFS","file:///"); 25 //创建一个任务对象job,别忘记把conf穿进去哟! 26 Job job = Job.getInstance(conf); 27 //给任务起个名字 28 job.setJobName("WordCount"); 29 //指定main函数所在的类,也就是当前所在的类名 30 job.setJarByClass(MaxTempApp.class); 31 //指定map的类名,这里指定咱们自定义的map程序即可 32 job.setMapperClass(MaxTempMapper.class); 33 //指定reduce的类名,这里指定咱们自定义的reduce程序即可 34 job.setReducerClass(MaxTempReducer.class); 35 //设置输出key的数据类型 36 job.setOutputKeyClass(Text.class); 37 //设置输出value的数据类型 38 job.setOutputValueClass(IntWritable.class); 39 //设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径 40 FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\temp")); 41 //初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。我的目的是调用该对象的delete方法,删除已经存在的文件夹 42 FileSystem fs = FileSystem.get(conf); 43 //通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录 44 Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out"); 45 if (fs.exists(outPath)){ 46 fs.delete(outPath,true); 47 } 48 //设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径 49 FileOutputFormat.setOutputPath(job,outPath); 50 //等待任务执行结束,将里面的值设置为true。 51 job.waitForCompletion(true); 52 } 53 }
关于MapReduce处理的大致流程,我画了一个草图,如下:
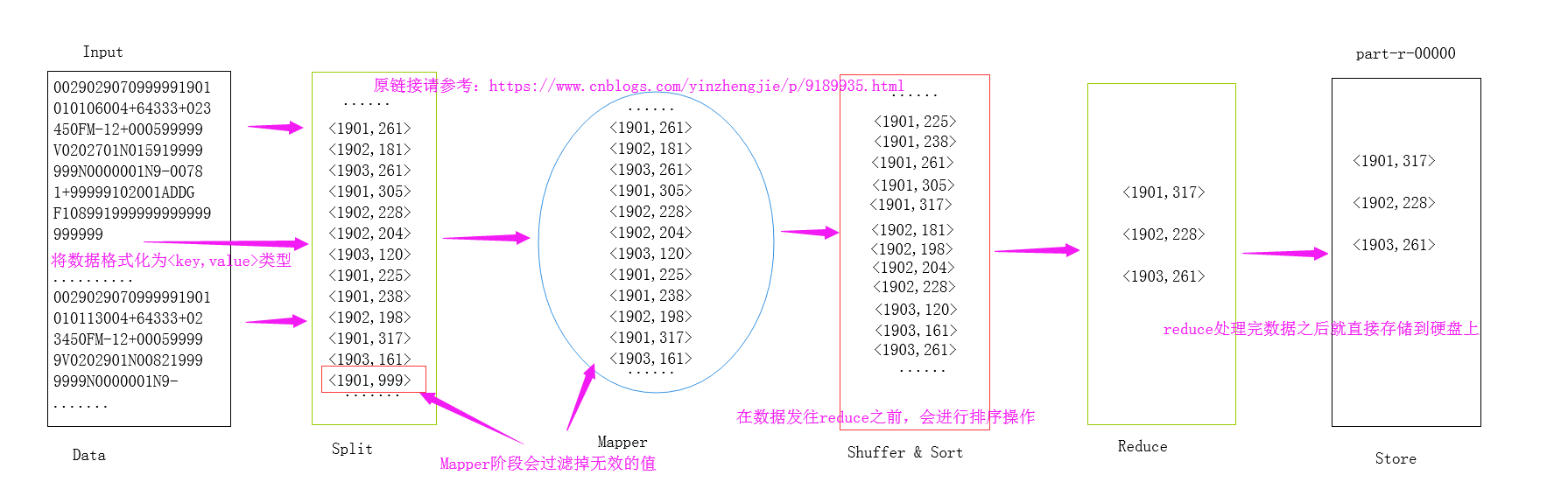
上述代码实现过程很简单,用到了一个Map程序和一个Reduce程序,那么问题来了,不用Reduce程序也能实现相同的效果吗?只用一个Map程序就把这个这个事情搞定可以吗?答案是肯定的,我们只需用Combiner就可以帮我们实现,那什么是Combiner呢?Combiner就相当于Map端的Reduce,用于减少网络间分发,属于预聚合阶段。Combiner适用场景:不适用于平均值,适用于最大值,最小值等等。接下来我们一起来研究研究它。
二.Combiner
1>.Combiner适用场景
简单来说:Combiner相当于Map端的Reduce,用于减少网络间分发,属于预聚合阶段,不适用于平均值,适用于最大值,最小值等等。具体用法我都不啰嗦了,一切尽在注释中!
2>.只有一个Map的情况
在上面的截图中我已经简单的分析了MapReduce的大致关系,其实实际生成环境中一个Map和一个Reduce的情况并不能代表所有,而是很多情况都是多个Map和多个Reduce,为了方便说明,我这里就简单的画一个Map和一个Reduce的情况,如果想要了解单个Reduce或者多个Reduce以及没有Re
3>.实现代码
MaxTempMapper.java 文件内容如下:
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.maxtemp; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Mapper; 12 13 import java.io.IOException; 14 15 /** 16 * 我们定义的map端类为MaxTempMapper,它需要继承“org.apache.hadoop.mapreduce.Mapper.Mapper”, 17 * 该Mapper有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出 18 * key和value的数据类型。 19 */ 20 public class MaxTempMapper extends Mapper<LongWritable,Text,Text,IntWritable> { 21 22 /** 23 * 24 * @param key : 表示输入的key变量。 25 * @param value : 表示输入的value 26 * @param context : 表示map端的上下文,它是负责将map端数据传给reduce。 27 */ 28 @Override 29 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 30 //得到一行数据 31 String line = value.toString(); 32 //得到年份 33 String year = line.substring(15, 19); 34 //得到气温 35 int temp = Integer.parseInt(line.substring(87, 92)); 36 //判断temp不能为9999 37 if (temp != 9999){ 38 //通过上线文将yaer和temp发给reduce端 39 context.write(new Text(year),new IntWritable(temp)); 40 } 41 } 42 }
MaxTempReducer.java文件内容如下:
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.maxtemp; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import java.io.IOException; 12 13 /** 14 * 我们定义的reduce端类为MaxTempReducer,它需要继承“org.apache.hadoop.mapreduce.Reducer.Reducer”, 15 * 该Reducer有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出 16 * key和value的数据类型。 17 */ 18 public class MaxTempReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 19 /** 20 * 21 * @param key : 表示输入的key变量。这里的key实际上就是mapper端传过来的year。 22 * @param values : 表示输入的value,这个变量是可迭代的,因此传递的是多个值。这个value实际上就是传过来的temp。 23 * @param context : 表示reduce端的上下文,它是负责将reduce端数据传给调用者(调用者可以传递的数据输出到文件,也可以输出到下一个MapReduce程序。 24 */ 25 @Override 26 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 27 //给max变量定义一个最小的int初始值方便用于比较 28 int max = Integer.MIN_VALUE; 29 //由于输入端只有一个key,因此value的所有值都属于这个key的,我们需要做的是对value进行遍历并将所有数据进行相加操作,最终的结果就得到了同一个key的出现的次数。 30 for (IntWritable value : values){ 31 //获取到value的get方法获取到value的值。然后和max进行比较,将较大的值重新赋值给max 32 max = Math.max(max,value.get()); 33 } 34 //我们将key原封不动的返回,并将key的values的所有int类型的参数进行折叠,最终返回单词书以及该单词总共出现的次数。 35 context.write(key,new IntWritable(max)); 36 } 37 }
MaxTempApp.java文件内容如下:
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.maxtemp; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import java.io.IOException; 17 18 public class MaxTempApp { 19 20 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 21 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 22 Configuration conf = new Configuration(); 23 //将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。 24 conf.set("fs.defaultFS","file:///"); 25 //创建一个任务对象job,别忘记把conf穿进去哟! 26 Job job = Job.getInstance(conf); 27 //给任务起个名字 28 job.setJobName("WordCount"); 29 //指定main函数所在的类,也就是当前所在的类名 30 job.setJarByClass(MaxTempApp.class); 31 //指定map的类名,这里指定咱们自定义的map程序即可 32 job.setMapperClass(MaxTempMapper.class); 33 //指定Combiner的类名,这里指定咱们自定义的reduce程序即可,注意,咱们这里没有设置Reduce程序,只是用了Map和Combiner。 34 job.setCombinerClass(MaxTempReducer.class); 35 //设置输出key的数据类型 36 job.setOutputKeyClass(Text.class); 37 //设置输出value的数据类型 38 job.setOutputValueClass(IntWritable.class); 39 //设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径 40 FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\temp")); 41 //初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。我的目的是调用该对象的delete方法,删除已经存在的文件夹 42 FileSystem fs = FileSystem.get(conf); 43 //通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录 44 Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out"); 45 if (fs.exists(outPath)){ 46 fs.delete(outPath,true); 47 } 48 //设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径 49 FileOutputFormat.setOutputPath(job,outPath); 50 //等待任务执行结束,将里面的值设置为true。 51 job.waitForCompletion(true); 52 } 53 }
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/9189935.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
