

Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例)
Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.编辑配置文件(pml.xml)(我们这里配置的是对“cn.org.yinzhengjie.compress.TestCompressCodec”该包进行打包操作)
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>groupId</groupId> 8 <artifactId>yinzhengjieCode</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <dependencies> 12 <dependency> 13 <groupId>org.apache.hadoop</groupId> 14 <artifactId>hadoop-client</artifactId> 15 <version>2.7.3</version> 16 </dependency> 17 18 <dependency> 19 <groupId>org.anarres.lzo</groupId> 20 <artifactId>lzo-hadoop</artifactId> 21 <version>1.0.0</version> 22 </dependency> 23 24 </dependencies> 25 26 <!--将指定类的所有依赖打入到一个包中--> 27 <build> 28 <plugins> 29 <plugin> 30 <artifactId>maven-assembly-plugin</artifactId> 31 <configuration> 32 <descriptorRefs> 33 <descriptorRef>jar-with-dependencies</descriptorRef> 34 </descriptorRefs> 35 <archive> 36 <manifest> 37 <!-- main函数所在的类 --> 38 <mainClass>cn.org.yinzhengjie.compress.TestCompressCodec</mainClass> 39 </manifest> 40 </archive> 41 </configuration> 42 <executions> 43 <execution> 44 <id>make-assembly</id> <!-- this is used for inheritance merges --> 45 <phase>package</phase> <!-- bind to the packaging phase --> 46 <goals> 47 <goal>single</goal> 48 </goals> 49 </execution> 50 </executions> 51 </plugin> 52 </plugins> 53 </build> 54 55 </project>
注意事项如下:
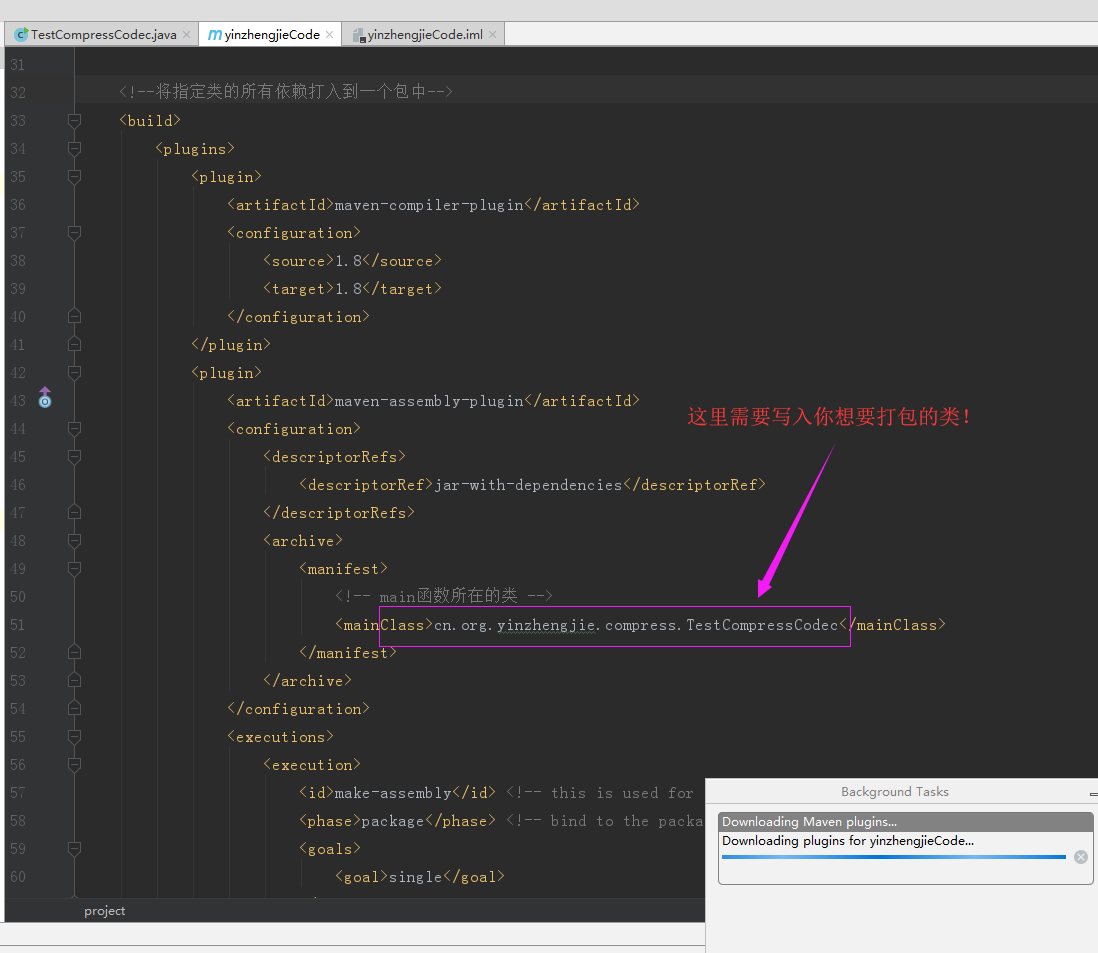
我们通过pom.xml配置文件不难看出我们需要打的包是“cn.org.yinzhengjie.compress.TestCompressCodec”,上述的配置主要是对该包打入相应的依赖包关系,且上述配置仅对该包有效哟。当然我所述的只是“<build></build>”标签里面里面的参数,它是对手动添加依赖的关键!
二.开始打包
1>.需要打包(cn.org.yinzhengjie.compress.TestCompressCodec)的代码如下:
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.compress; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.io.IOUtils; 10 import org.apache.hadoop.io.compress.*; 11 import org.apache.hadoop.util.ReflectionUtils; 12 import java.io.File; 13 import java.io.FileInputStream; 14 import java.io.FileOutputStream; 15 16 17 public class TestCompressCodec { 18 /** 19 * 设置路径动态传参 20 * @param args 21 */ 22 public static void main(String[] args) { 23 if(args == null || args.length == 0){ 24 System.out.println("需要输入路径"); 25 System.exit(-1); 26 } 27 Class[] classes = { 28 DefaultCodec.class, 29 GzipCodec.class, 30 BZip2Codec.class, 31 Lz4Codec.class, 32 LzopCodec.class, 33 SnappyCodec.class 34 }; 35 for(Class clazz : classes){ 36 testCompress(clazz, args[0]); 37 testDecompress(clazz,args[0]); 38 } 39 } 40 /** 41 * Gzip压缩 42 * @throws Exception 43 */ 44 public static void testCompress(Class clazz, String path) { 45 try { 46 long start = System.currentTimeMillis(); 47 Configuration conf = new Configuration(); 48 conf.set("fs.defaultFS", "file:///"); 49 CompressionCodec codec = (CompressionCodec)ReflectionUtils.newInstance(clazz, conf); 50 FileInputStream fis = new FileInputStream(path); 51 //获取扩展名 52 String ext = codec.getDefaultExtension(); 53 //创建压缩输出流 54 CompressionOutputStream cos = codec.createOutputStream(new FileOutputStream(path+ext)); 55 IOUtils.copyBytes(fis,cos,1024); 56 fis.close(); 57 cos.close(); 58 System.out.print("压缩类型:"+ ext+"\t"+ "压缩时间:" + (System.currentTimeMillis() - start)+ "\t"); 59 File f = new File(path+ext); 60 System.out.print("文件大小:"+ f.length() + "\t"); 61 } catch (Exception e) { 62 e.printStackTrace(); 63 } 64 } 65 66 /** 67 * Gzip解压 68 * @throws Exception 69 */ 70 public static void testDecompress(Class clazz,String path) { 71 try { 72 long start = System.currentTimeMillis(); 73 Configuration conf = new Configuration(); 74 conf.set("fs.defaultFS", "file:///"); 75 CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(clazz, conf); 76 //扩展名 77 String ext = codec.getDefaultExtension(); 78 //压缩输入流 79 CompressionInputStream cis = codec.createInputStream(new FileInputStream(path+ext)); 80 FileOutputStream fos = new FileOutputStream(path+ext+".txt"); 81 IOUtils.copyBytes(cis,fos,1024); 82 cis.close(); 83 fos.close(); 84 System.out.println("解压时间:" + (System.currentTimeMillis() - start)); 85 } catch (Exception e) { 86 e.printStackTrace(); 87 } 88 } 89 }
2>.点击“package进行打包操作”
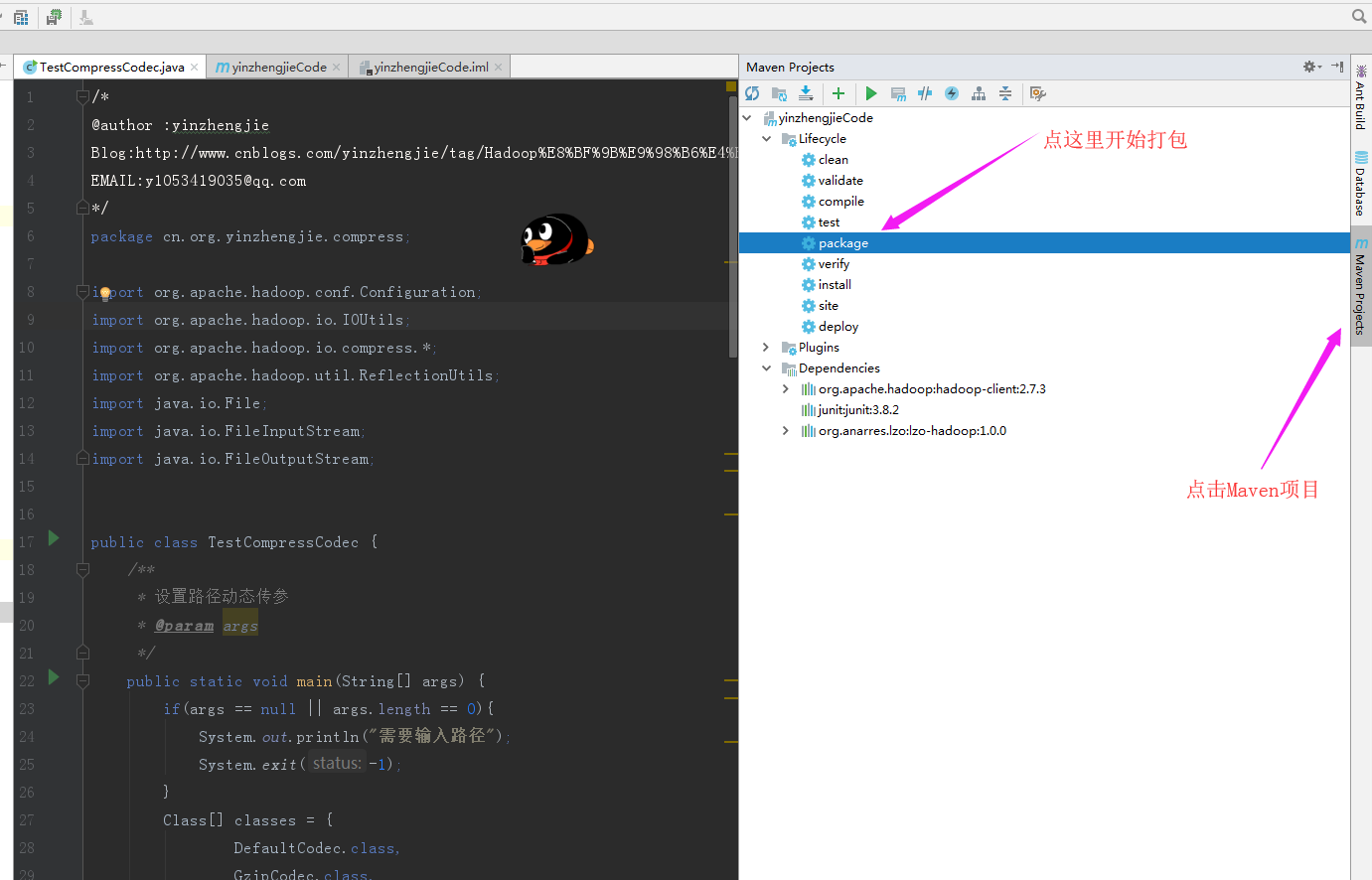
3>.打包后的产物
在打包的过程需要一定的时间,我们需要耐心等待
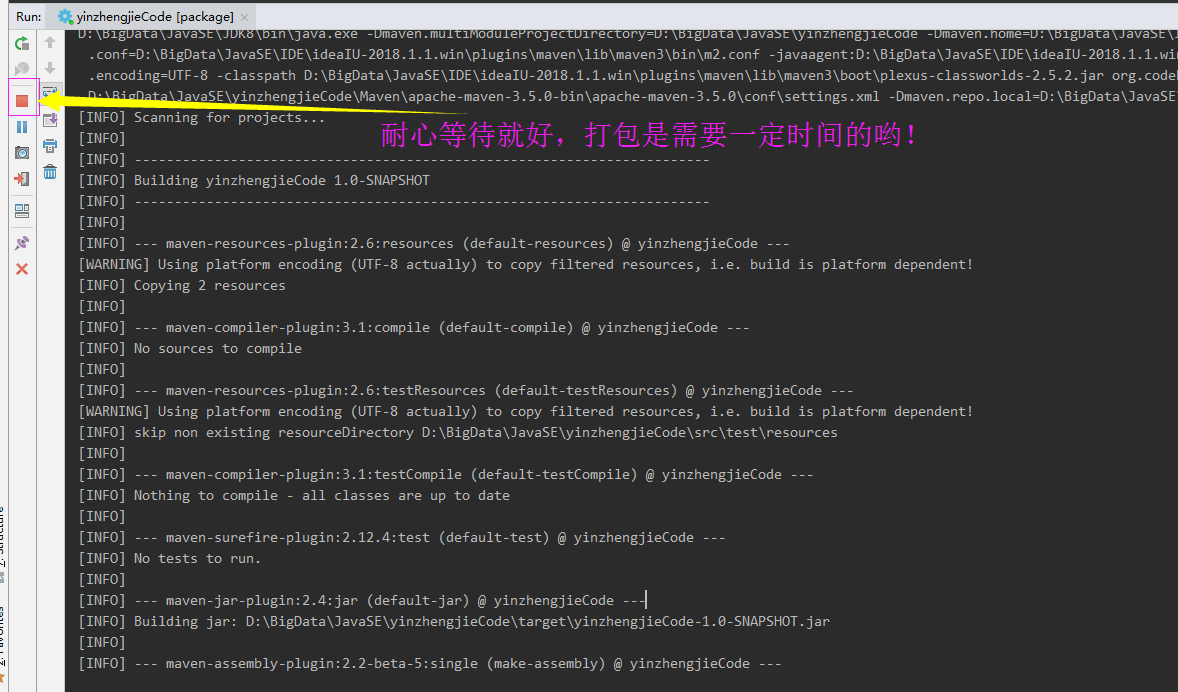
打包过程中如果没有遇到错误,就会出现以下的界面
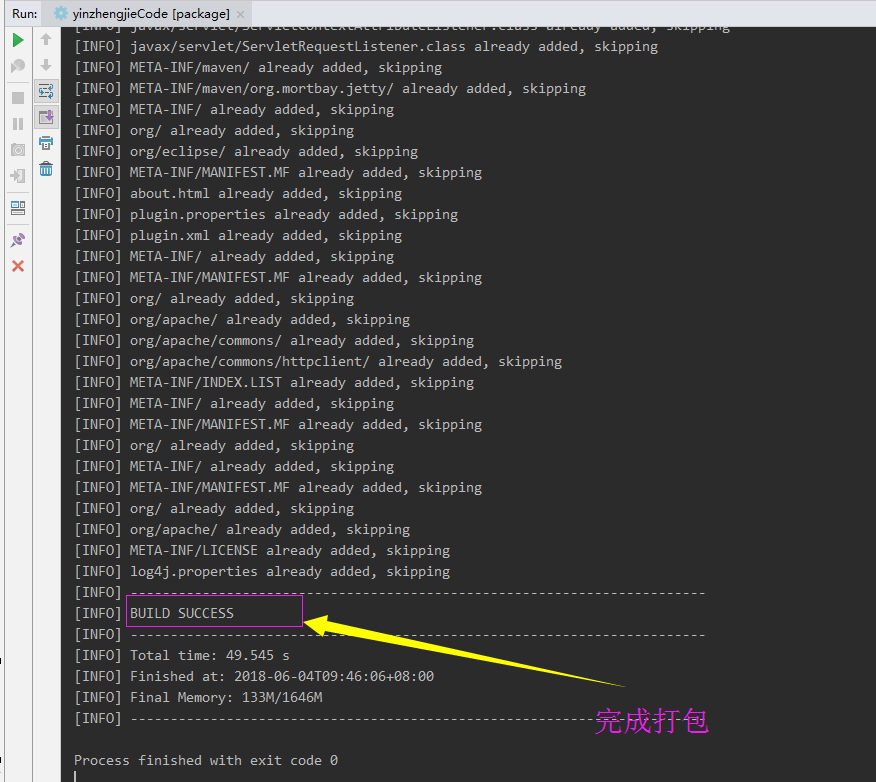
打包完成之后,会有两个文件生成,如下图:
三.Hadoop压缩格式综合测试
由于我在Windows测试说当前Hadoop版本不支持snappy压缩格式,官网上也没有相应的下载版本(链接:https://pan.baidu.com/s/1Clhsvv-gzvVX7lQOQ27vng 密码:d367),不过有大神编译了Hadoop支持snappy格式的,如果有时间了我也得去研究研究,到时候会把笔记共享给大家。好了,下图就是我使用支持snappy压缩格式的版本进行测试的。
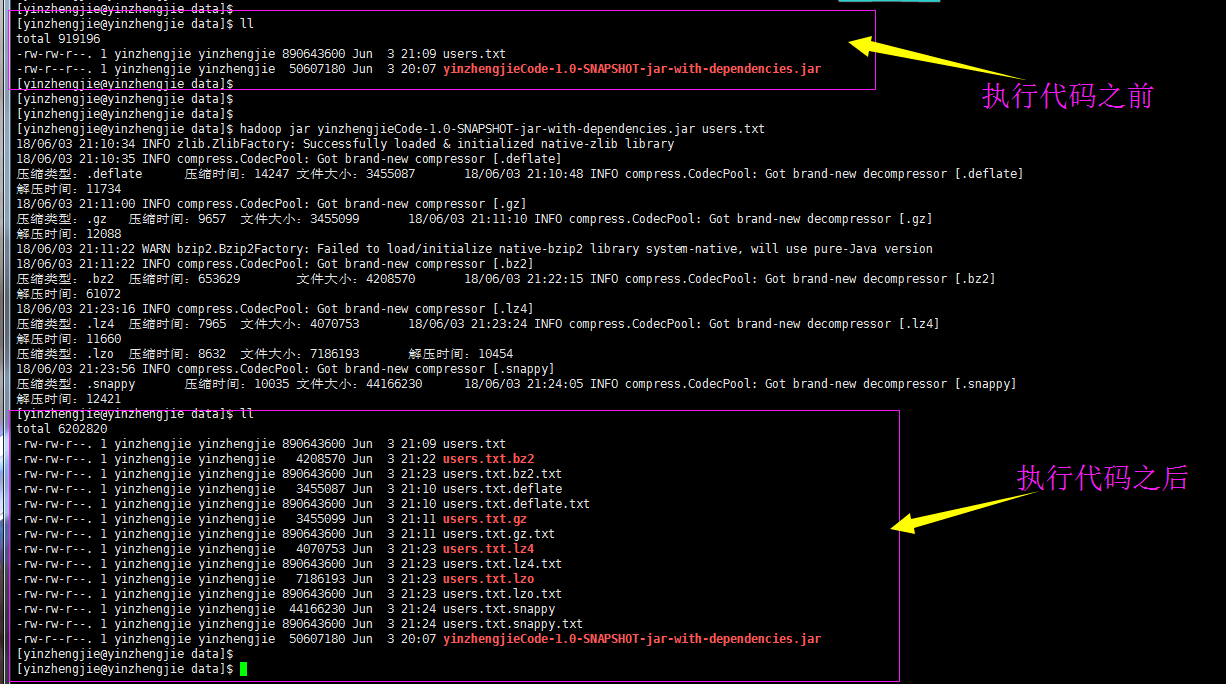
我们将上面的核心信息抽取如下:
压缩类型:.deflate 压缩时间:14247 文件大小:3455087 解压时间:11734 压缩类型:.gz 压缩时间:9657 文件大小:3455099 解压时间:12088 压缩类型:.bz2 压缩时间:653629 文件大小:4208570 解压时间:61072 压缩类型:.lz4 压缩时间:7965 文件大小:4070753 解压时间:11660 压缩类型:.lzo 压缩时间:8632 文件大小:7186193 解压时间:10454 压缩类型:.snappy 压缩时间:10035 文件大小:44166230 解压时间:12421
根据结果反推理论:(以上实验是对一个890M的文件进行处理,生成环境最好以实际生成环境为准,这个数据仅供参考!)
压缩时间从小到大:
lz4 < lzo < gz < snappy < deflate < bz2;
压缩大小从小到大:
defalte < gz < lz4 < bz2 < lzo < snappy;
解压时间从小到大:
zo < lz4 < deflate < gz < snappy < bz2;
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/9124038.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
