
Hadoop基础-Hadoop的集群管理之服役和退役
Hadoop基础-Hadoop的集群管理之服役和退役
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
在实际生产环境中,如果是上千万规模的集群,难免一个一个月会有那么几台服务器出点故障,在IDE机房这种事情几乎每个星期都会有那么几起事故发生,比如服务器断电,磁盘过慢,网络不同,核心路由故障,接入层交换机故障,在严重点就是一些二级运营商出口被攻击导致网络拥堵等等。刚刚说的这些事件都是我在实际工作中遇到的一些现象,因此,在大规模集群部署上,尤其是大数据,存储的都是海量数据,甚至可以用PB级别来形容,几十台服务器做大数据的公司估计也就是玩玩,像BATJ这样的大公司集群规模在4000个节点已经不再话下,每个服务器可插入的硬盘卡槽优先,4000台存储设备服务器,我生产中接触的是爱数的设备,他们有20个卡槽,每个卡槽可以装2T的文件,也就是一台机器只能保存40T文件,如果4000台这样的设备的话,也就160000T的数据,换算成PB差不多也就160PB的数据。
好了,说说我们本篇博客的重点,就是服务器的服役和退役,IDE人员喜欢统称这种操作为上架和下架。很久很久以前,去过北京朝阳酒仙桥的一个IDC机房实习了两个星期(那时候刚刚入职,领导让我去了解一下机房情况),其实用上架和下架来形容服役和退役的话不完全正确,为什么这么说呢?在IDE机房中,上架指的是给服务器通电,插上网线并将公网ip告知客户。下架就是断电将服务器或者网络设备归还给租户,而我们说的服役和退役,不仅仅是开机这么简单,而是让他进入工作状态,才是服役,而退役和其相反,就是不提供服务。
一.添加新节点的过程(服役)
1>.在dfs. hosts文件中(hdfs-site-xml)包含新节点名称,该文件在NameNode的本地目录。 dfs. hosts属性是真正指定DataNode服务器的节点,相当于指定白名单。如下: [/soft/hadoop/etc/hadoop/DataNodesHostname.txt] s102 s103 s104 2>.在hdfs-site-xml文件中添加属性 <property> <name>dfs.hosts</name> <value>/soft/hadoop/etc/hadoop/DataNodesHostname.txt</value> </property> 3>.在NameNode上刷新节点(hdfs服务) [yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes 4>.在NameNode上刷新节点(yarn服务,如果你没有启动该服务的话就可以暂时不管他) [yinzhengjie@s101 ~]$ yarn rmadmin -refreshNodes 5>.在slaves文件中添加新节点ip(主机名) 一行代表一个主机,如下: s102 s103 s104 s105 6>.单独启动新节点中的datanode [yinzhengjie@s101 ~]$ hadoop-daemon.sh start datanode
二.删除旧节点的过程(退役)
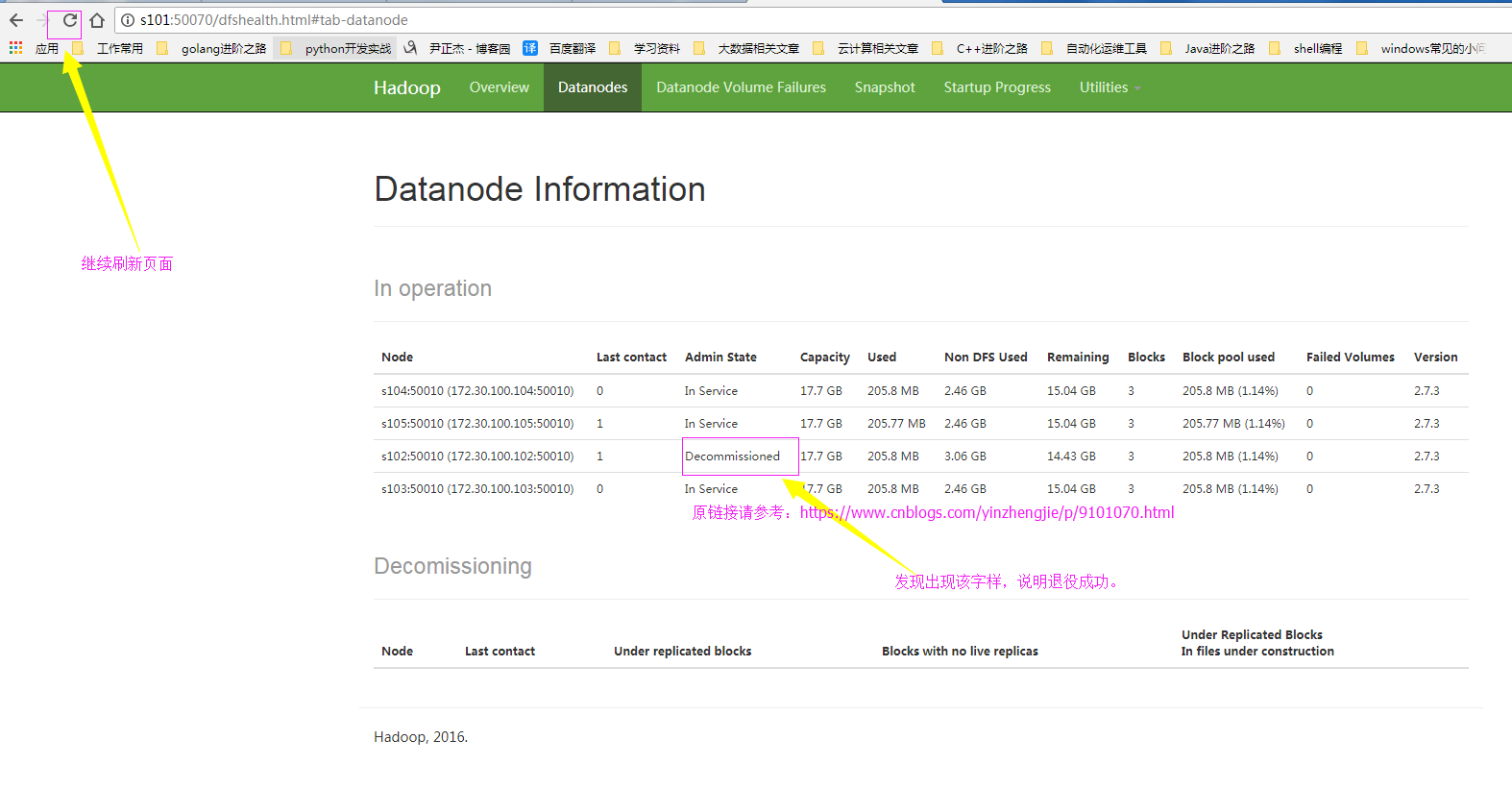
1>.添加退役节点的ip到黑名单(dfs.hosts.exclude),不要更新白名单 案例如下:在下面的配置文件中写入相应的主机名 [/soft/hadoop/etc/dfs.hosts.exclude.txt] s101 s102 2>.配置hdfs-site.xml配置文件 <property> <name>dfs.hosts.exclude</name> <value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value> </property> 3>.在NameNode上刷新节点(hdfs服务) [yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes 4>.在NameNode上刷新节点(yarn服务,如果你没有启动该服务的话就可以暂时不管他) [yinzhengjie@s101 ~]$ yarn rmadmin -refreshNodes 5>.查看webUI 节点状态在decommisstion In Progresss 6>.当所有的要退役的节点都报告为Decommissioned 要退役的节点报告信息是Decommissioned ,说明退役成功。说明退役的过程就是在迁移数据到服役的节点中。 7>.从白名单删除节点,并刷新节点 [yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes 8>.从slave文件中删除退役的节点
三.黑白名单的组合情况

四.节点的服役案例展示
1>.查看webUI的界面
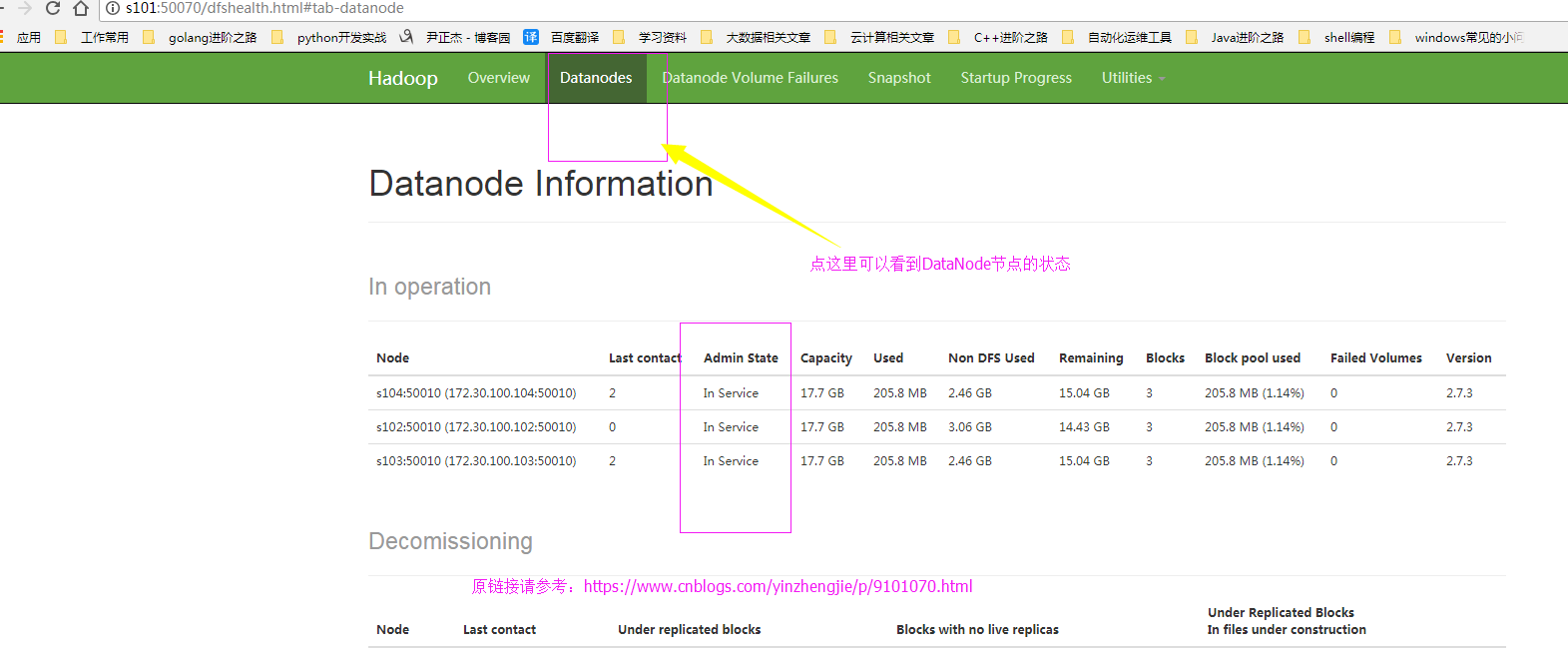
2>.编辑hdfs-site.xml 配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- <property> <name>dfs.hosts</name> <value>/soft/hadoop/etc/hadoop/DataNodesHostname.txt</value> </property> --> <property> <name>dfs.hosts.exclude</name> <value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value> </property> </configuration> <!-- hdfs-site.xml 配置文件的作用: #HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限 等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.replication 参数的作用: #为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据 块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用 保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个 软件级备份。 dfs.hosts 参数的作用: #添加白名单,功能和黑名单(dfs.hosts.exclude)相反。我这里是将其注释掉了。 dfs.hosts.exclude 参数的作用: #这是我们添加的黑名单,该属性的value定义的是一个配置文件,这个配置文件的主机就是需要退役的节点。 --> [yinzhengjie@s101 ~]$
3>.编辑黑名单
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/dfs.hosts.exclude.txt s102 [yinzhengjie@s101 ~]$
4>.刷新NameNode节点
[yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[yinzhengjie@s101 ~]$
5>.上线新的节点(这台机器配置需要和完全分布式的DataNode模式一致),启动DataNode服务
[yinzhengjie@s105 ~]$ ll /soft/hadoop/etc/ total 12 drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 May 28 01:27 full drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 May 25 00:12 local drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 May 28 01:28 pseudo [yinzhengjie@s105 ~]$ [yinzhengjie@s105 ~]$ ln -s /soft/hadoop/etc/full/ /soft/hadoop/etc/hadoop [yinzhengjie@s105 ~]$ [yinzhengjie@s105 ~]$ ll /soft/hadoop/etc/ total 12 drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 May 28 01:27 full lrwxrwxrwx. 1 yinzhengjie yinzhengjie 22 May 28 01:32 hadoop -> /soft/hadoop/etc/full/ drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 May 25 00:12 local drwxr-xr-x. 2 yinzhengjie yinzhengjie 4096 May 28 01:28 pseudo [yinzhengjie@s105 ~]$ [yinzhengjie@s105 ~]$ hadoop-daemon.sh start datanode starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s105.out [yinzhengjie@s105 ~]$ jps 2757 Jps 2680 DataNode [yinzhengjie@s105 ~]$
6>.再次查看webUI界面,查看新节点是否上线
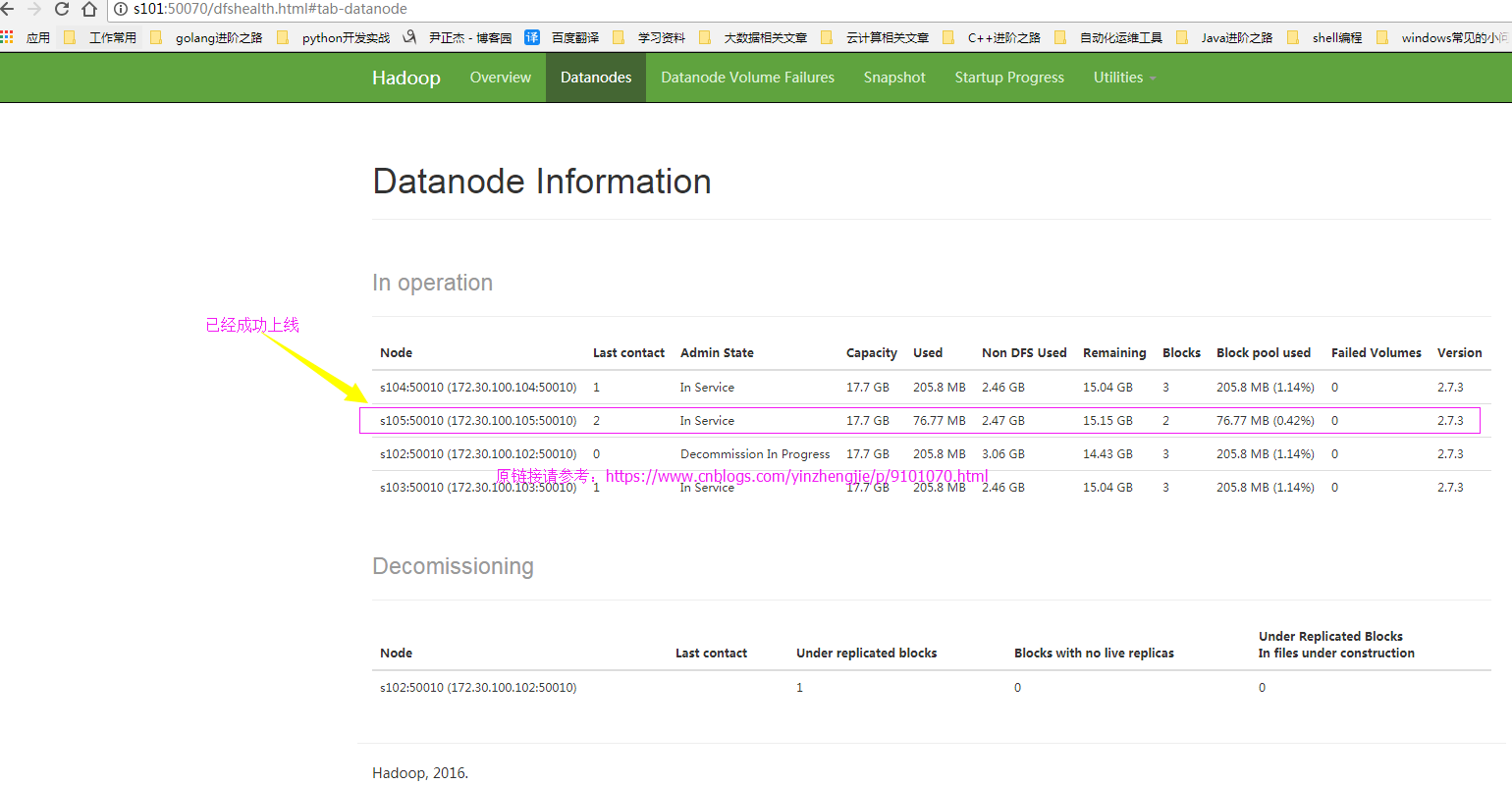
7>.确认退役成功
四.节点的服役案例展示
1>.查webUI界面,发现新服役的节点正常工作但是之前的退役节点还在,我们需要将退役的节点删除掉!
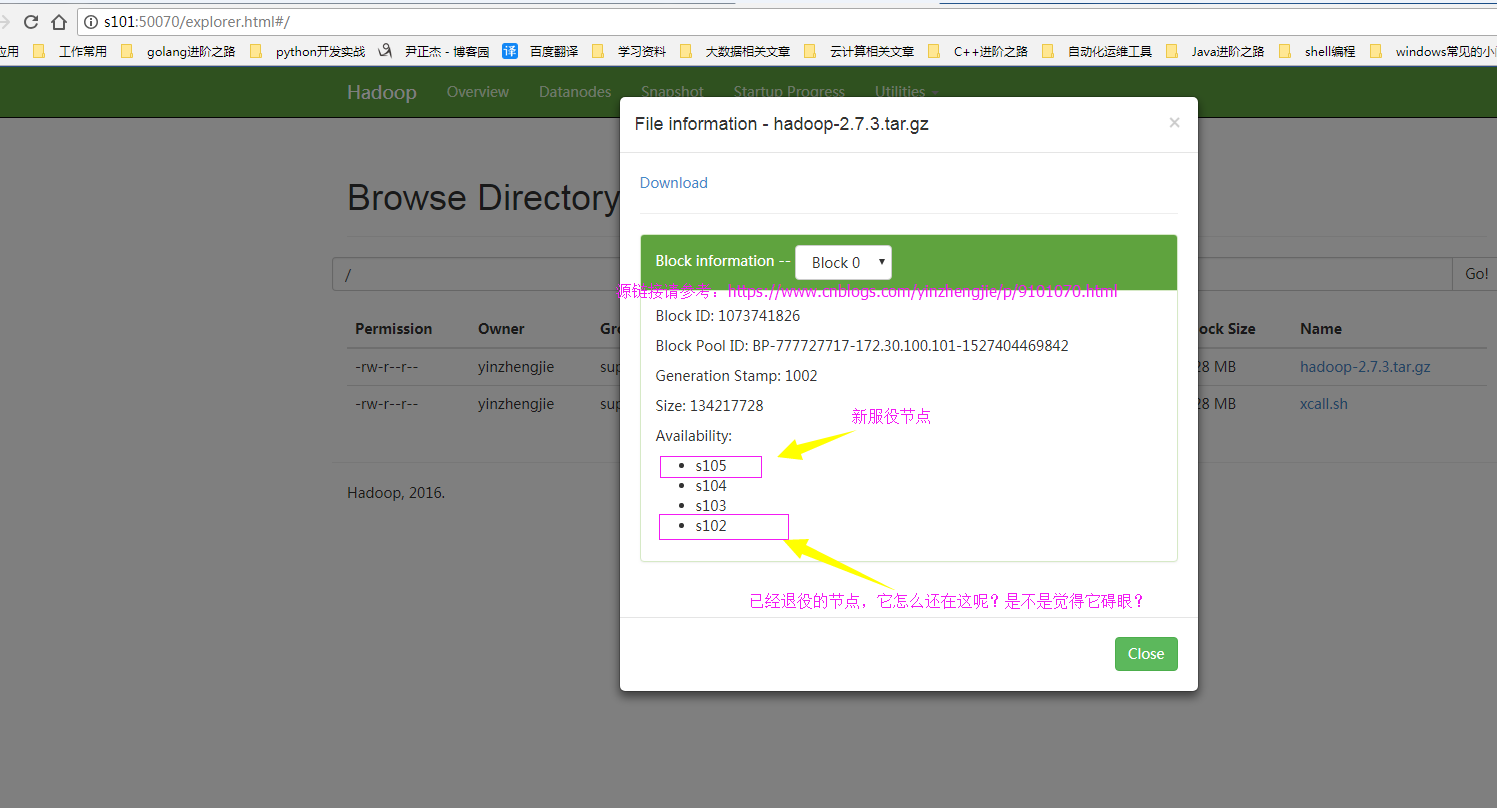
2>.编辑hdfs-site.xml 配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.hosts</name> <value>/soft/hadoop/etc/hadoop/DataNodesHostname.txt</value> </property> <property> <name>dfs.hosts.exclude</name> <value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value> </property> </configuration> <!-- hdfs-site.xml 配置文件的作用: #HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限 等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.replication 参数的作用: #为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据 块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用 保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个 软件级备份。 dfs.include 参数的作用: #添加白名单,功能和黑名单(dfs.hosts.exclude)相反。 dfs.hosts.exclude 参数的作用: #这是我们添加的黑名单,该属性的value定义的是一个配置文件,这个配置文件的主机就是需要退役的节点。 --> [yinzhengjie@s101 ~]$
3>.编辑白名单
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/DataNodesHostname.txt s103 s104 s105 [yinzhengjie@s101 ~]$
4>.查看当前的webUI界面(节点已经处于退役状态)
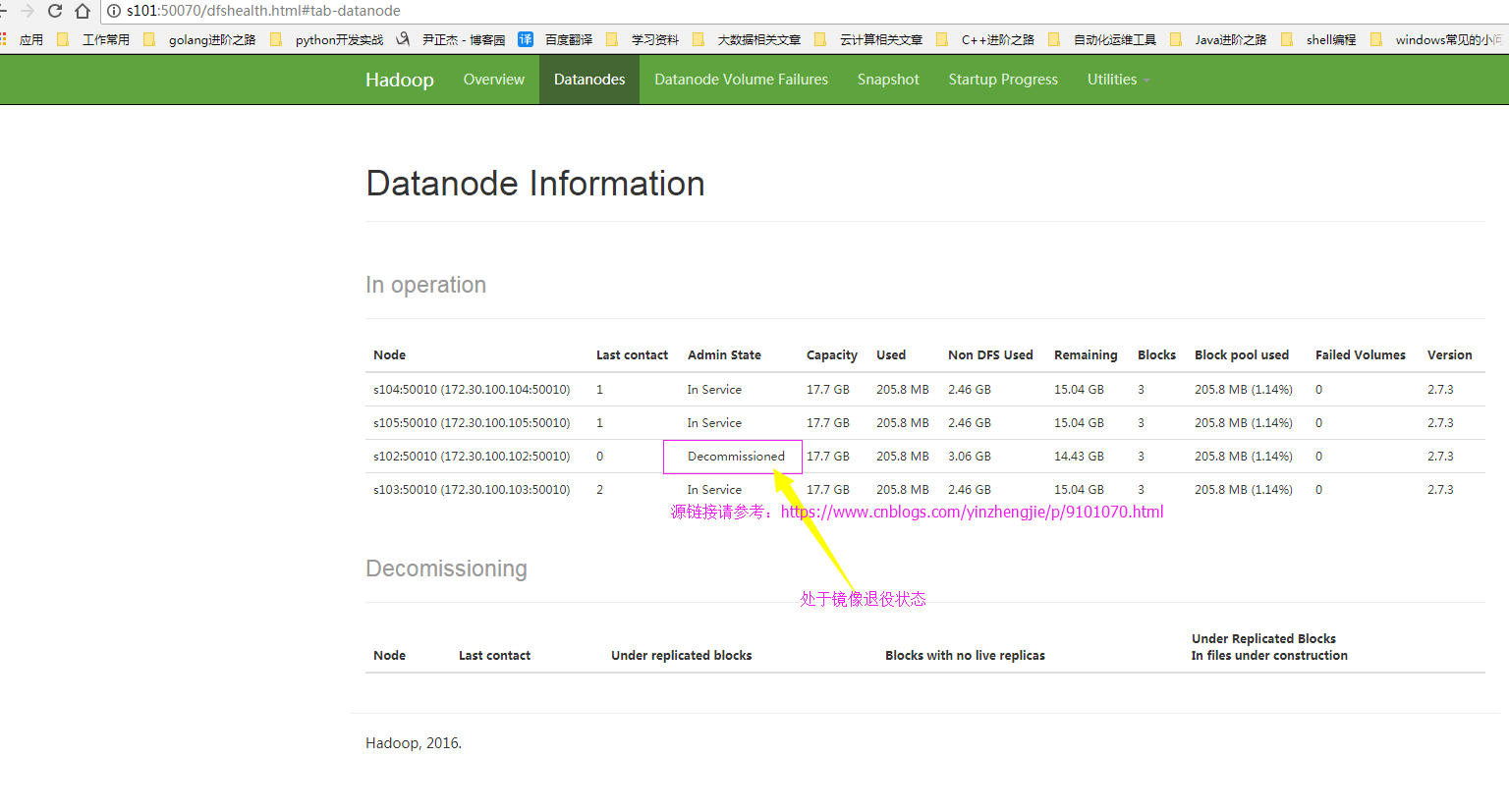
5>.刷新NameNode节点
[yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[yinzhengjie@s101 ~]$
6>.webUI确认刷新成功
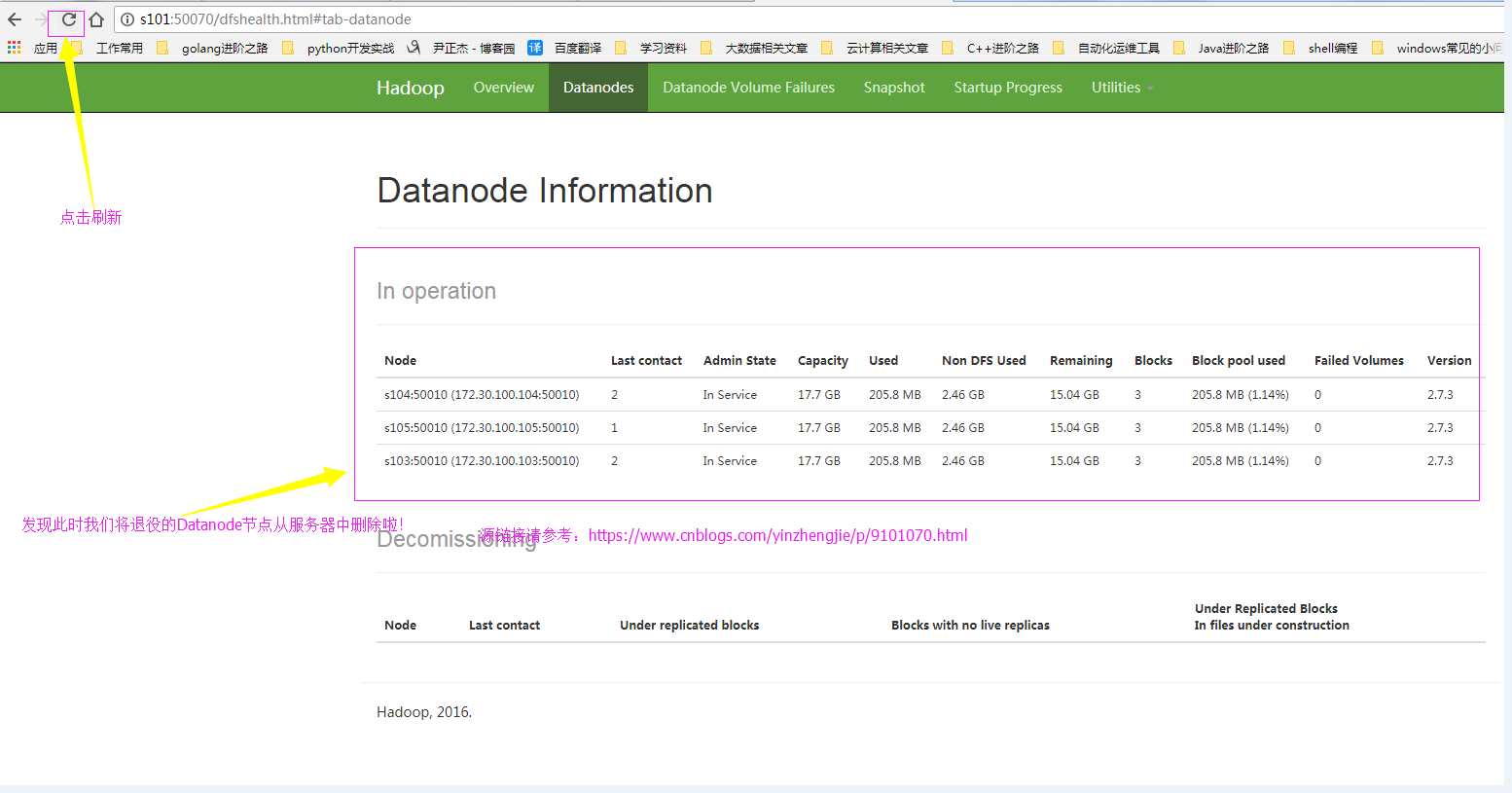
六.yarn的服役和退役
如果你会了hdfs的服役和退役的话,其实yarn就是so easy的一件事啦,就是照猫画虎的方法,步骤重复过程较多,我就懒得截图了,配置过程跟我上面配置hdfs不愁类似,相信你有举一反三的能力哟。 1>.首先修改yarn的配置文件("yarn-site-xml")。修改其属性“yarn.resourcemanager.nodes.exclude-path”即可,黑名单配置如下: [/sotf/hadoop/etc/hadoop/yarn-site.xml] <property> <name>yarn.resourcemanager.nodes.exclude-path</name> <value>/soft/hadoop/etc/hadoop/yarn.exclude.hosts</value> </property> 对了,如果想要配置白名单的话,需要设置“yarn.resourcemanager.nodes.include-path”属性哟! 2>.编辑yarn的配置文件“yarn.resourcemanager.nodes.exclude-path” 修改配置文件内容如下: [/soft/hadoop/etc/hadoop/yarn.exclude.hosts] s102 3>.刷新节点 配置上述步骤后及得刷新节点,使用命令:“[yinzhengjie@s101 ~]$ yarn rmadmin -refreshNodes” 即可。 4>.单独启动新的节点中 nodemanager [yinzhengjie@s101 ~]$ yarn-daemon.sh start nodemananger
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/9101070.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号