

虚拟化技术基础原理
虚拟化技术基础原理
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.什么是叫虚拟化
将底层的计算机资源给它抽象(或虚拟)为多组彼此之间互相隔离的计算平台,每一个计算平台都应该具有计算机五大基本部件中的所有设备。
其实虚拟化有很多种类型,虚拟出一个完整的计算机只是其实现方式之一,目前为止,还有很多其他常见的虚拟化技术。比如说,像用户空间的虚拟化,还有像库级别的虚拟化等等。
二.CPU的虚拟化
CPU虚拟化有两种方式:
1>.模拟(emulation,通过软件实现【需要模拟环0,环1,环2,环3】,效率低);
2>.虚拟(virtulization,比如我们常用的VMwore workstation【只需要模拟环0】的软件就是一款完全虚拟化平台)。
CPU执行时会有所谓的环的的概念,X86的CPU架构大概分成了四个层次,由内之外共有四个环,被称为环0,环1,环2,环3。我们知道环0的都是特权指令,环3的都是用户指令。环1和环2是为被使用的。
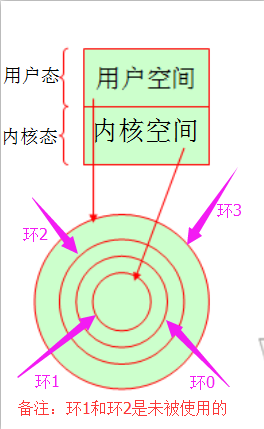
环0是特权环,所有的特权指令,包括直接操作硬件的,操作CPU当中某些敏感的寄存器的,尤其是跟硬件管控有关寄存器的都必须用环0的指令才能运行。而我们开发操作系统时,这个操作系统在研发时就明确知道自己是直接在特权级别的。也就意味着内核空间是在环0上执行。而用户空间的进程它明确知道自己要使用任何特权资源都必须发起系统调用,是不可以直接执行特权指令的。
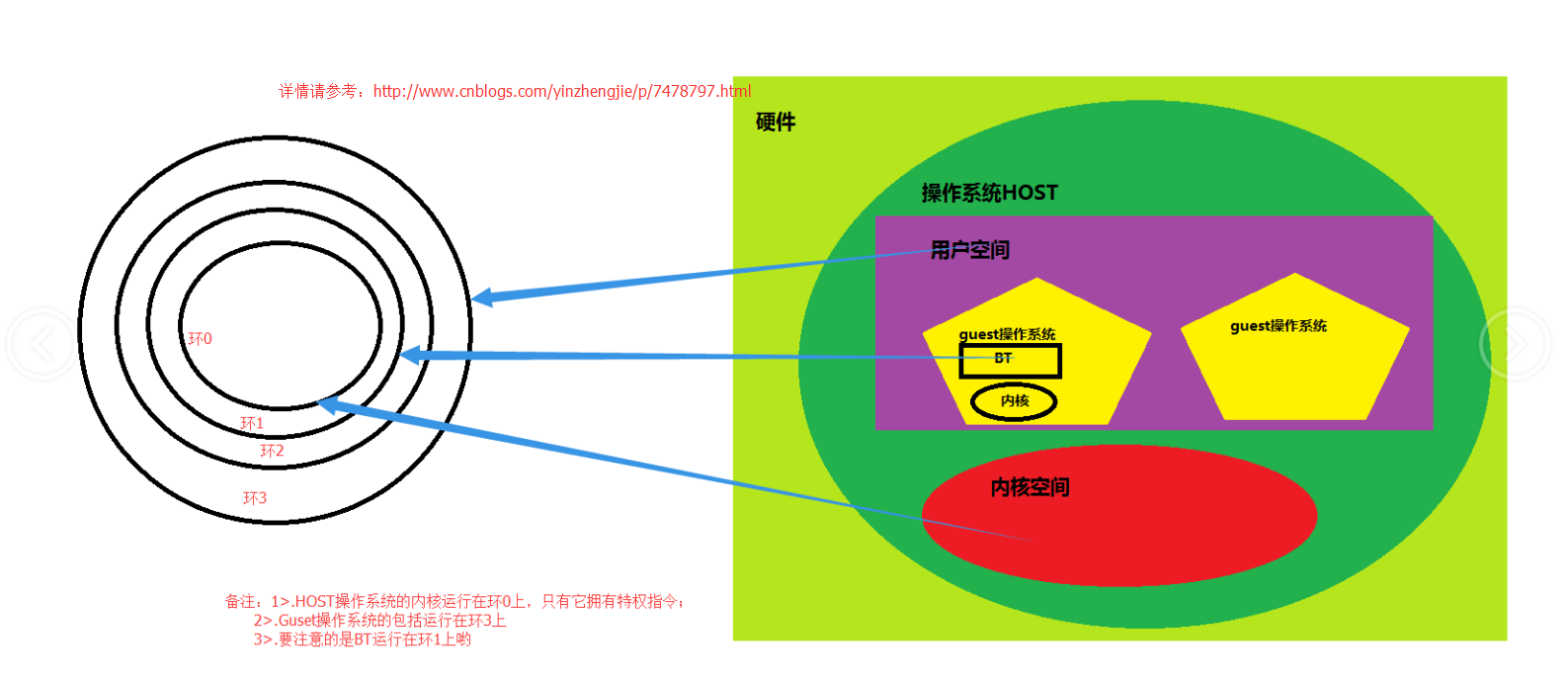
一般而言,对于虚拟机来说,CPU是通过软件模拟出来的。我们用一个进程(也可能是一个线程)来模拟一颗CPU,供Guest使用。所以,虚拟化就是在我们虚拟机环境中要能创建一个用软件生成的CPU供给guest使用。所以这个CPU也有自己的环0,环1,环2,环3等等,这个虚拟机运行在这个假的CPU中。这颗假的CPU同样也拥有特权指令,只不过它执行时需要将指令传给guest内核,guest内核并无权限执行特权指令(因为它是软件虚拟出来的,并不是直接操作硬件的操作系统。)它
需要执行解码,模拟等操然后转换成host的特权指令的调用。整个过程是相当消耗时间的,所以基于这种方式实现虚拟化性能是非常低的。
那如何提示其性能呢?VMware公司引入了一个新的技术,即BT(Binary Translation )技术,它是一种直接翻译可执行二进制程序的技术。它能够让Guest各虚拟机对特权指令的调用直接翻译成对host主机的特权指令的调用,这就不用再软件级别多次进行解码操作,而是边运行,边调用,边转换。使得早起模拟的技术大大的提升了,简单的将如果一个虚拟机所能够获取到的性能相当于硬件的60左右的话,基于引入BT技术的话,性能会提升到80~85%。
扩展小知识:
一般虚拟机模拟出来的硬件设备最好不要超过宿主机的配置,尽管我们的虚拟机是可以实现模拟的硬件设备高于宿主机的配置,但是运行起来效果并不是很好,它的配置要低于宿主机本身的配置效果最佳。即:如果虚拟机和底层的硬件架构一样的话,Guest个各非特权指令就可以直接在CPU上运行。·
关于BT技术要注意的是:当宿主机操作系统是64位的时候,虚拟机可以是32位的也可以是64位的操作系统,但是当宿主机的操作系统是32位的时候,想要虚拟机是64位的操作系统,则CPU必须支持硬件虚拟化。
三.完全虚拟化(full-virtulization)
完全虚拟化的主要目的就是让各个Guest并不能意识到自己是运行在虚拟化环境中的。
1>.BT:二进制翻译(软件虚拟化)
2>.HVM:硬件辅助的虚拟化(硬件虚拟化)
所谓硬件虚拟化就是让CPU具有5个环,分别是:环3,环2,环1,环0,环-1。如下图:
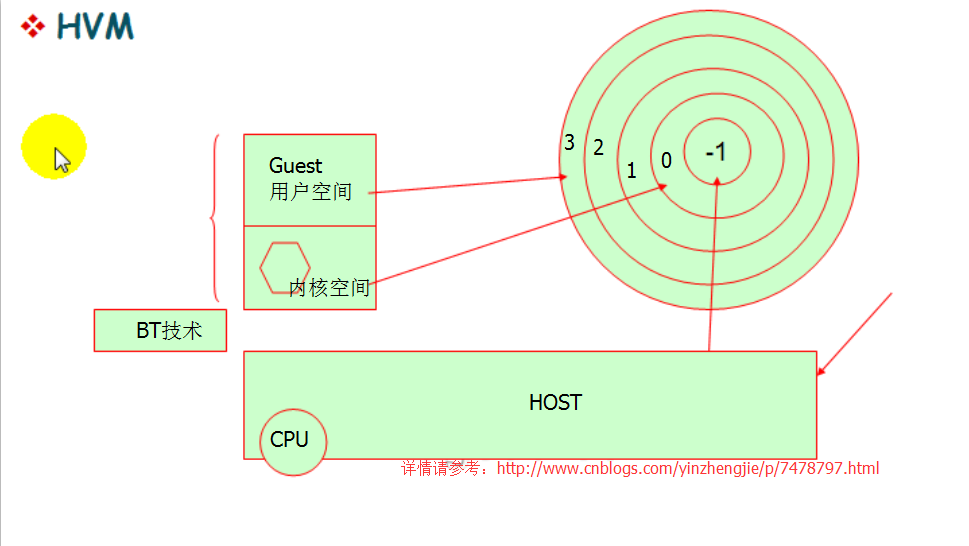
所以,我们称之为环-1位虚拟化的根环(区域),这就意味着HOST主机内核运行在环-1上的(因为此时的它是特权指令环),各个Guest主机运行在环0上,此时环0虽然存在,但并没有特权指令的,只是一个空壳而已。虚拟机的用户空间一人是运行在环3上的。由于虚拟机内核运行在环1上,它会认为自己就拥有了特权指令,但是当他调用特权指令的时候,会HTOS内核是可以捕获到各个Guest对于特权指令的调用,最后由CPU硬件自己转换成(需要HOST内核的参与)-1环中的特权指令。这就叫硬件辅助的虚拟机,简称HVM。
四.半虚拟化(para-virtulization)
半虚拟化也有人称之为准虚拟化,当操作系统发现需要调用操作系统的特权指令时,内核不是直接调用cpu的特权指令了,而是自己乖乖的去找宿主机的内核去请求,而不是茫然无知的调用硬件的特权指令。(它是明确知道自己是在虚拟化环境中的。)
VM monitor也叫hypervisor,它其实就是HOST宿主机。hypervisor直接管理硬件,它就相当于Host的内核,hypervisor可以管理底层核心硬件(一般而言指的是CPU和内存,不包括IO设备)设备。hypervisor把CPU和内存的使用分配过程给它虚拟成“hyper call”(可以理解成hypervisor调用)
hypervisor的好处就是当虚拟机在实现要执行特权指令时,只要调用的特权指令不会影响到其他的虚拟机或是hypervisor的就直接用虚拟机自己的内核去执行,如果会对其他的虚拟机有影响的话,会将这个特权指令发给“hyper call”,然后由“hyper call”自己到硬件上去执行,这个过程就省去了中间的翻译的过程,即直接调用而非翻译。
一旦使用了半虚拟化技术就必须要修改操作系统内核了,不然的话它就并不会知道对“hyper call”进行调用。hypervisor明显比BT的翻译技术更强了。半虚拟化是为了提高模拟转换效率的,但是由于硬件的辅助的虚拟化出现,基本上半虚拟化可用武之地也少了。
五.内存虚拟化
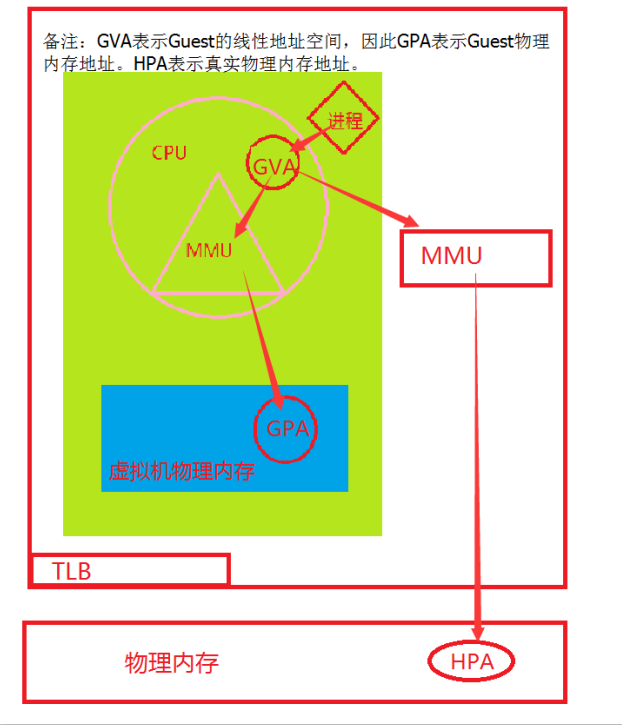
Memory本身就是虚拟化的,因为进程使用的是线性地址空间,内核使用的才是物理地址空间。
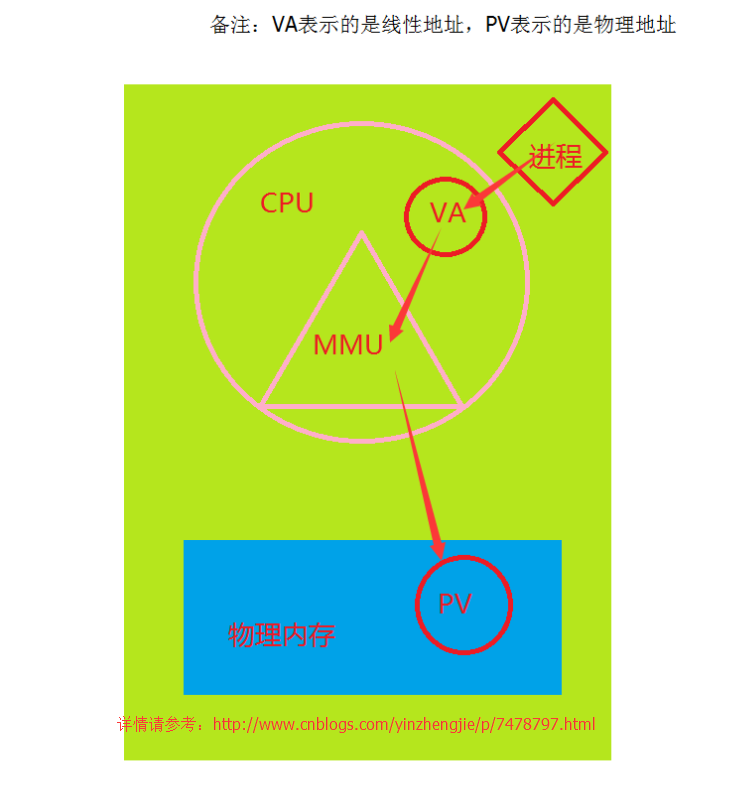
1.在没有安装虚拟机的环境中,如果你只有一个操作系统,也没有安装虚拟化软件。
当一个进程想要拿到一个数据,比如你用Golang语言定义了一个变量,如果你想要拿到这个变量所对应的数据,首先会将线性地址传给CPU,我们知道线性地址是虚拟的,并不真实存在,这个时候CPU不会去这个线性地址取数据,而是将这个线性地址交给MMU,然后由MMU进行计算,将这个线性地址的对应的物理地址给找出来。并将这个对应关系在TLB中缓存。
2.如果在宿主机上安装了虚拟化软件,并在这个虚拟化新建了Guest。
我们知道上面没有安装虚拟机的内存转换过程,那么推算出有虚拟机的内存转换想必对家也不是难事,就是虚拟机的线性地址转换成虚拟机的物理地址,但是宿主机而言,它仍然不是真正的物理地址,因此在虚拟机中的线性地址经过虚拟机的MMU的转换得到的虚拟机的内存地址是不可用的,还需要让宿主机的MMU再一次进行计算,才能得到真正的物理内存。这种效率那是相当的低啊。这样频繁的转换也就罢了,在虚拟机来回切换时,也会存在一个坑,就是当宿主机由虚拟机A切换到虚拟机B时,必须将TLB的【转换后援缓冲器(缓存页表的查询结果)】缓存清空,这样TLB的功能基本上就起不到太大的作用了,这种实现虚拟化的方式我们称之为:Shaow Page Table。
由于上述实现内存的虚拟化很低小,因此我们出现了一系列支持硬件虚拟化。
A.需要对MMU做虚拟化(MMU Virtulization):虚拟机将GVA转换成GPA的同时,MMU虚拟化会自动将GVA转换成HPA的,省略了GPA到HPA转换的过程。
Intel:EPT(Extended Page Table)
AMD:NTP(Nested Page Table)
B.也需要对TLB做虚拟化(TLB virtulization):操作系统将TLB进行打标签处理,表明是哪个虚拟机主机的线性地址对应着真正物理内存地址。
tagged TLB
六.I/O设备虚拟化
最基本的I/O设备有外存(硬盘,光盘,U盘),网络设备(网卡),显示设备(图形设备器,即VGA),键盘鼠标(PS/2或者USB接口)。
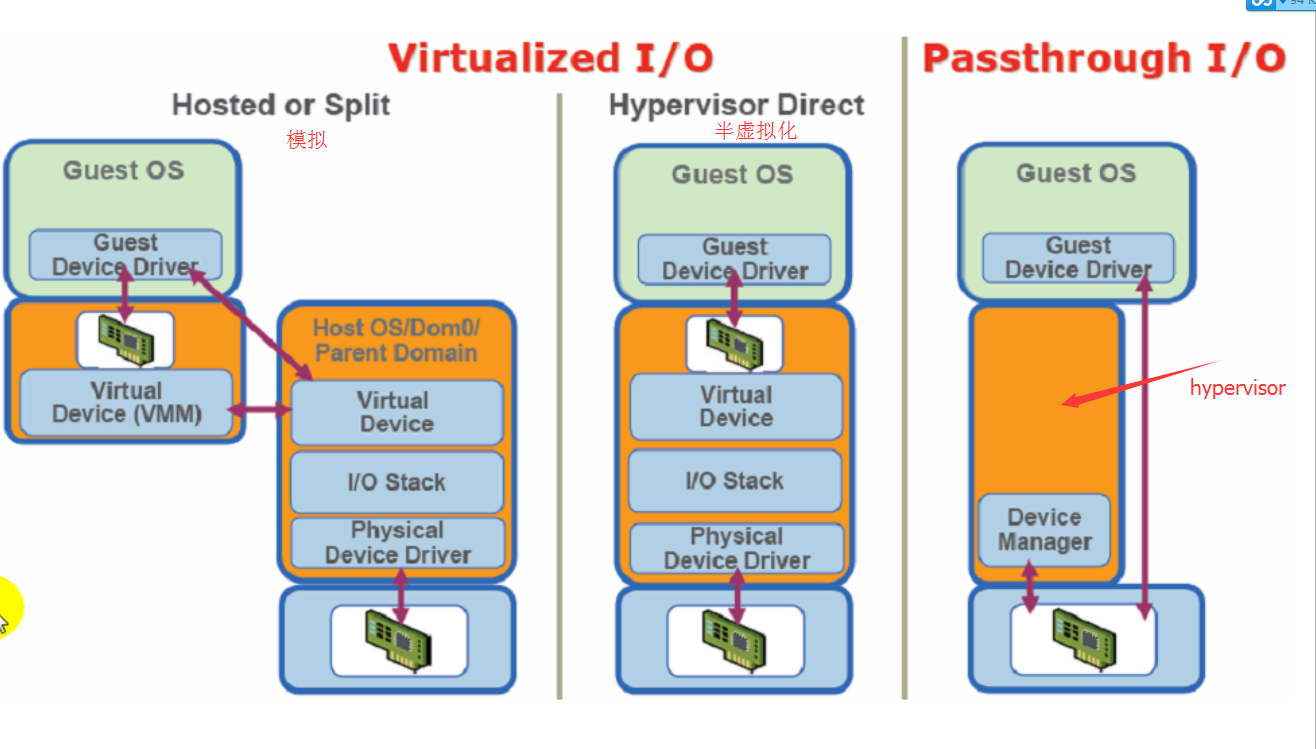
I/O虚拟化的方式有三种:
1>.模拟(Hosted or Split):完全使用软件来模拟真实硬件。
一个虚拟化软件可以安装多个Guest,如果这些Guest想要想外面发送数据的话,他们转发的机制是什么呢?外面以一台Guest为例进行说明,首先,Guest的进程需要进行I/O请求,让IO stack(栈)进行调度,通过网卡驱动将数据传递给虚拟机的模拟网卡,但是数据并不会被真正的发送出去,而是将数据发送到hypervisor(宿主机)上的虚拟化软件(例如:VMware Workstation Pro)的虚拟化软件网卡,然后通过hypervisor的IO Stack调用物理网卡驱动,最终将数据发送给真正的物理网卡,最终数据完成了发送。
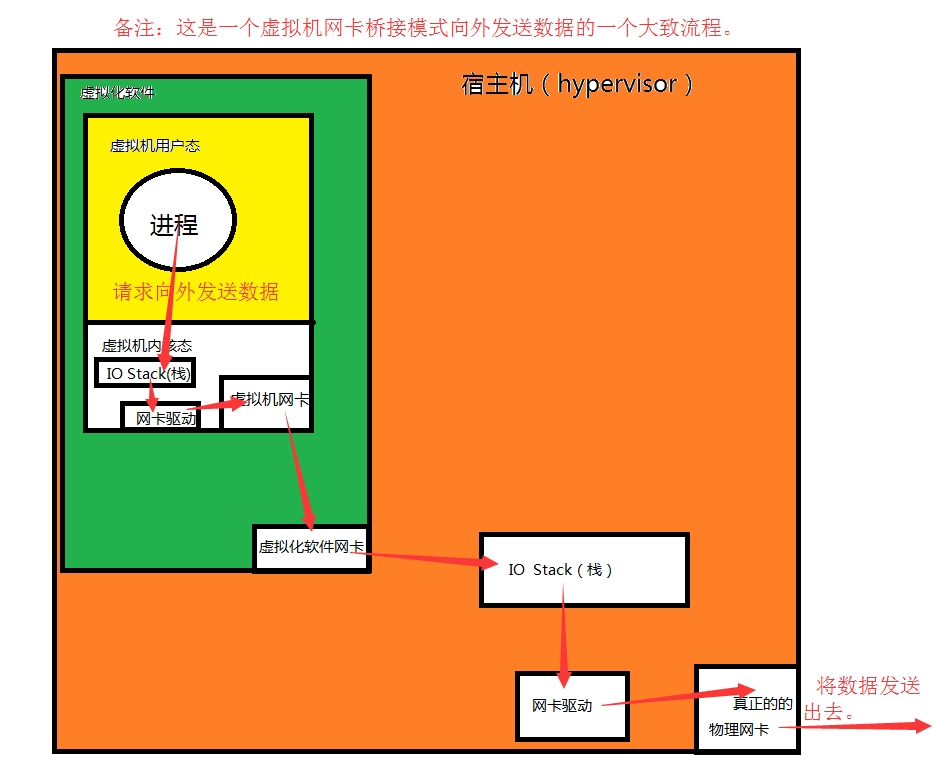
我们知道模拟的网卡的工作模式之后,会发现数据在发送的时候,需要经过两次的调用系统内核,一次是Guest自己调用虚拟机的物理网卡,另一次是在hypervisor上的再一次调用,效率是很低低下的。据说,模拟方式实现的虚拟化可以利用到物理网卡的70%就已经很不错了。
2.半虚拟化(Hypervisor Direct ):
半虚拟化中,Guest的内核是明确知道自己是运行在虚拟化环境中的,所以在网络数据传输时,通过前端驱动(IO Frontend,但是在用户看来还是一块物理网卡)将数据直接转发给后端驱动(IO backend)。这样就省去了模拟是Guest调用其内核驱动的步骤。很显然这是一种很好的性能实现,在半虚拟化的确能使用到接近其物理设备95%左右的性能。
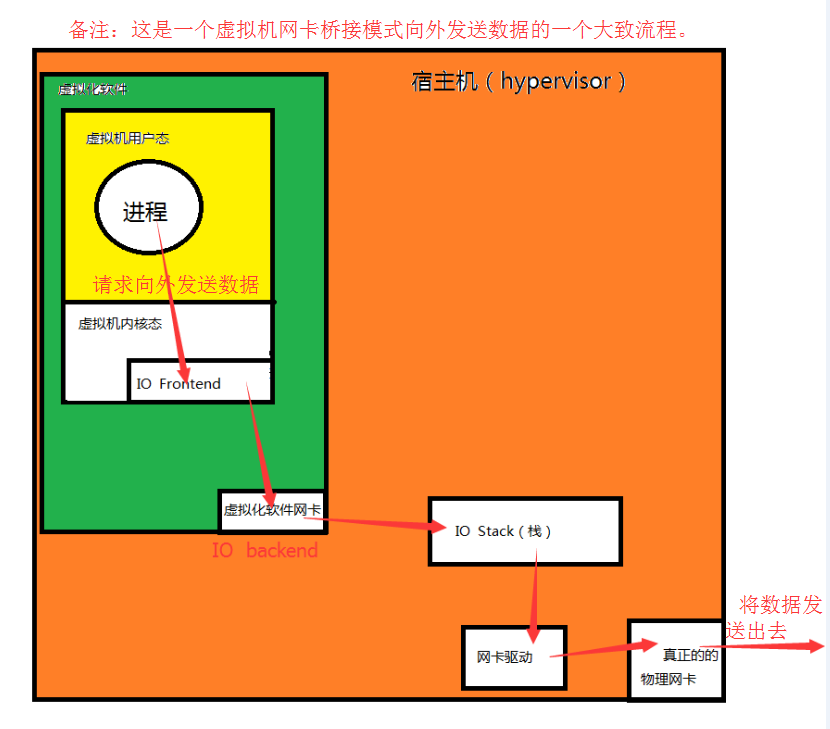
扩展小知识:
这种所谓的前端,后端驱动通常只适用于硬盘和网卡设备。所以存储设备和网络设备可以通过这种方式来虚拟。但是虚拟显示设备是不可用这样虚拟的,显示设备的虚拟是通过Frame buffer(帧缓冲) 机制给每个虚拟机一个独立的窗口来实现的。虚拟一个显示设备是非常麻烦的,因为显示是要通过显卡来支持的,所以当虚拟机A切换到虚拟机B时:虚拟机A使用的显卡的显存内容会被清空。很多显卡都有硬件加速功能在虚拟机上显卡功能实现效果都不会特别好。你也不要妄图在虚拟机上安装一个大型的游戏(比如:魔兽世界,英雄联盟等等)。
键盘鼠标都是通过完全模拟实现的,通过所谓的当前的焦点捕获的方式来实现将模拟的设备和物理设备建立关联关系。例如:当我们将鼠标移动到虚拟机里面是,并点击虚拟机的界面,焦点被虚拟机捕获到,我们输入的所有的内容都会被虚拟机捕获到(此时物理机是捕获不到的)。所以我们可以说它是临时建立关联关系的方式来实现的。
3.IO-through,也叫IO透传(Passthrough I/O)
在hypervisor的协调下让虚拟机直接使用物理设备,它几乎接近于硬件设备性能来使用硬件。
以上三种技术可用图形表示为:
扩展小知识:
要实现I/O透传技术的话((Passthrough I/O),一般也要求硬件必须有相应透传功能的支持,也就是说你的主板上的一般实现I/O桥的功能要支持透传技术。比如Intel的VT-d的技术,实现了I/O MMU.
4,.为什么要使用硬件虚拟化技术?
事实上,在我们传统的PC(或是PC server x86)系统架构上,所有的I/O设备通常有一个共享的(或集中式)DMA(直接内存访问)。在DMA中其实实现的是IO MMU,即IO 内存地址映射(当然你也可以叫IO 内存管理单元)。我们知道每个IO设备都是有寄存器的,每一个寄存器都有相应的IO端口(IO 地址)。因此,IOMMU就是实现从IO总线到IO端口转换的的一个自动转换设备,也在类似于主机上实现。很显然,如果你能直接将一个IO设备直接分配一个某一个虚拟机使用的话,那么也就意味着,这个hypervisor级别的对于某个IO端口的调用就只能接受某一个虚拟机来进行了,因此我们必须在IO MMU界别上进行隔离的,而Intel的VT-d就是实现这种功能的。简单的讲:VT-d是基于北桥的硬件辅助的虚拟化技术。
扩展小知识:
Intel硬件辅助虚拟化:
第一类:跟处理器相关:vt-x;
第二类:跟芯片相关:vt-d;
第三类:跟IO相关:VMDq和SR-IOV;
七.虚拟化的两种实现方式(两种模型)
1.Type-I型
不需要在硬件安装操作系统,让虚拟化软件(hypervisor,你可以理解它是一个虚拟机监控程序 )直接运行在硬件上,它可以直接接管CPU,内存等等,所有运行在当前物理硬件上的主机都是虚拟机。
典型代表有:xen,vmware ESX/ESXi.
2.Type-II型(易于管理,方便借助HOST的管理工具)
需要在硬件上安装一个操作系统,在操作系统上安装一个虚拟化软件,通过虚拟化软件创建各个虚拟机。
典型代表:kvm,VMware Workstation,Virtualbox
八.虚拟化技术分类
1.模拟
所谓模拟是指:在硬件之上安装操作系统,在操作系统上安装虚拟化软件(也可以叫做虚拟环境模拟器[Emulator]),这个模拟器完全使用软件模拟出来一套或多套硬件环境,这个模拟出来的每一套硬件环境都是不同的虚拟机。Emulator即使一个Emulator工具,也是一个虚拟机健康器,我们也可以称之为虚拟机监控器(VMM).
著名的模拟器:
a>.PearPC;
b>.Bochs;
c>.QEMU;
2.完全虚拟化(Full virtualization)
也称为原生虚拟化(native virtulization)。说白了就是我们CPU和内存不做模拟,只对它做相应的分配和管理,但是I/O等需要做模拟,内存由MMU进行管理。从某种意义上来讲,它类似于模拟但也有别于模拟,完全虚拟化所虚拟的CPU架构跟底层物理平台的架构要保持一致。完全虚拟化要比模拟要高一点。有两种加速方式我们上文已经提到了,即BT与HVM.
完全虚拟化的相关产品:
a>.VMware Workstation
b>.VMware Server
c>.Parallels Desktop
d>.KVM
e>.Xen(HVM)
3.半虚拟化(Para-Virtualization)
所谓的半虚拟化是因为我们必须要求其Guest OS内核是明确知道自己是运行在虚拟化环境中的,因此虚拟化的架构与底层的架构必须完全相同,而Guest OS还必须修改其内核,基于“hyper call”的ABI(因为Hyper call在hypervisor的运行环境中,所以叫做应用二进制接口,简称ABI,而在开发环境中我们称之为API)调用来完成的。在半虚拟化中,虚拟出来的架构也必须和底层的架构保持完全一致。半虚拟化也有人称之为准虚拟化。
半虚拟化相关的产品:
a>.xen;
b>.uml(user-mode linux)
4.OS级别的虚拟化
在底层硬件上运行一个内核,并在内核上运行一个虚拟化管理器,然后在虚拟化管理器上运行各个用户空间的虚拟机,每个用户空间都共享使用底层内核。相比以上几种虚拟化化而言,这种性能是最好的(因为相比之下,中间少了一个转换的层次),但是稳定性的话就相对弱一点(比如一个虚拟机将内核搞挂掉了,那么其他的虚拟机将无法使用了,因为他们是共用一个内核的)。被IDC很青睐.
OS级别的虚拟化相关产品:
a>.OpenVZ;(大型的IDC提供VPS使用的就是它)
b>.lxc
c>.Solaris Containers
d>.FreeBSD Jails
5.库虚拟化
在Linux模拟出来一种Windows库(Windows的ABI),所以,在Windows下安装的软件在Linux上都是可以安装的,在Linux上跑windows程序,如安装一个搜狗输入法,安装一个魔兽世界,英雄联盟等等。性能也是相当不错的。所以你可以大胆的将你的宿主机换成Linux版本的啦~哈哈
库虚拟化的相关产品:
a>.wine,
6.应用程序虚拟化
给一个应用程序提供一个虚拟化环境。
应用程序虚拟化的相关产品:
a>.jvm
九.虚拟化网络
1.桥接(bridge mode)
桥接模式其实就是将宿主机的网卡当成交换机来使用,然后自己再虚拟出来一块桥接设备(用来接收真正发往本机的数据包的),其MAC地址和物理网卡的MAC是一致的,如果目标MAC是发往宿主机的就将数据包转发给这个宿主机虚拟出来的物理网卡,如果目标MAC是发往虚拟机的,就将数据转发给虚拟机网卡。存在的缺陷就是宿主机和虚拟机的数据包都通过宿主机的物理网卡进行收发包,这样就很可能导致一台虚拟机不断地往外部发包,而其他虚拟机的数据包发送不出去的情况。
2.仅主机(host-only mode)
通过软件模拟的方式,在宿主机上虚拟出来一个交换机,然后让各个虚拟机都连接到这同一个交换机且他们要再同一个网段,专业就实现了虚拟机之间的相互通信,但是为了让宿主机也能和这些虚拟机通信,还需要在宿主机上虚拟出来一块网卡,这个虚拟网卡也要连接到之前虚拟的交换机上,这样我们只需要把这个虚拟网卡的IP配成和虚拟机一个网段就可以轻松实现宿主机和各个虚拟机的互联啦。也就是说,仅主机能够让虚拟机之间进行通信,也能够让各个虚拟机和本机通信。但是虚拟机是和外部网络是完全隔离的。
3.路由模式(routed mode)
其实路由模式和仅主机模式就是隔了一道门了,只要我们登门一脚就能让他能够轻松愉快的访问到互联网了,我们知道仅主机模式其实需要在宿主机中虚拟出来一块网卡,让其与虚拟机进行通信。说明虚拟机的数据包是可以到达宿主机的,这个时候我们虚拟网卡的数据包转发给物理网卡就可以将数据轻松的发送给互联网啦。
4.NAT模式(nat mode)
宿主机虚拟出来一个NAT服务器,虚拟机将数据发送到宿主机的虚拟网卡时,如果想要将数据发送出去,先将数据包的源IP地址(虚拟机的网卡地址)通过NAT服务器修改为物理网卡地址,然后再将数据发送出去,这样将数据发送到目的端后,目的端发现发送来的源地址是其发送来的宿主机的物理网卡地址,而看不到真正的虚拟机的IP,从而实现了对虚拟机IP的一种保护机制。
5.隔离模式(isolation mode)
虚拟化软件虚拟一个交换机,然后各个虚拟机都连接到这个虚拟交换机上,这样就轻松实现了各个宿主机之间的互通,这个时候宿主机并没有创建虚拟网卡连接到这个交换机上来,这样就导致了虚拟机之间可以互相通信,并且宿主机无法连接到这个虚拟机的。
扩展小知识:
在计算机网络中,TUN与TAP是操作系统内核中的虚拟网络设备。不同于普通靠硬件网络板卡实现的设备,这些虚拟的网络设备全部用软件实现,并向运行于操作系统上的软件提供与硬件的网络设备完全相同的功能。
TAP等同于一个以太网设备,它操作第二层数据包如以太网数据帧。TUN模拟了网络层设备,操作第三层数据包比如IP数据封包。
操作系统通过TUN/TAP设备向绑定该设备的用户空间的程序发送数据,反之,用户空间的程序也可以像操作硬件网络那样,通过TUN/TAP设备发送数据。在后种情况下,TUN/TAP设备向操作系统的网络栈投递(或"注入")数据包,从而模拟从外部接收数据的过程。
关于桥接网卡的基本配置,可参考:http://www.cnblogs.com/yinzhengjie/p/7446226.html
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/7478797.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
