
Linux防火墙核心概念详解
Linux防火墙核心概念详解
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.防火墙(Firewall)概述
1>.什么是防火墙
防火墙就是简单来说就是一款隔离工具,工作与主机或网络边缘,对于进出本主机或本网络的报文根据事先定义的检查规则做出匹配检测,对于能够被规则匹配到的报文做出相应处理的组件。
2>.主机防火墙和网络防火墙
有过网络基础的同学应该知道,数据包能到达一台主机就只有两种情况,要么是通过单播的形式到达该主机,要么就是通过广播的形式到达该主机。 熟悉Linux操作系统的小伙伴应该知道Linux服务器是可以当路由器来使用的,只需要在"/etc/sysctl.conf"这个系统配置文件中可以设置一个叫做"net.ipv4.ip_forward = 1"就会开启网络转发功能,如果在服务器配置了多块网卡,完全可以把服务器当作公司的路由器网关来使用。 综上所述,到达本主机的数据包一般情况下也得分是去往本机的还是去往其它网段的,如果是去往本机的则会交给主机防火墙进行处理,而如果是去往其它网络的就得需要交给网络防火墙处理。很显然,主机防火墙和网络防火墙可以在同一台服务器上。
3>.软件防火墙和硬件防火墙
软件防火墙:
利用Linux内核纯软件逻辑从而实现防火墙功能。
硬件防火墙:
自身的防火墙有硬件优势再加上软件逻辑实现防火墙功能。
二者之间的区别:
我们通用的X86的服务器计算机它的CPU指令设置起来非常底层和通用,它根据我们编程实现具体功能,比如安装一个操作系统,虚拟化软件,软件防火墙等功能,而硬件防火墙是专用CPU,可以在CPU级别就能完成报文的拆封,检查等功能。
举个例子,很有可能硬件防火墙和软件防火墙在匹配同一规则时,硬件防火墙只需要2-3条指令就能搞定,而通用的服务器计算机通过软件防火墙实现同一规则时可能底层需要转换成20-30条指令不等,所以硬件防火墙相比软件防火墙性能要更强。
这就好比你让一个大数据运维工程师去处理一个DBA相关的工作时,一般情况下,这个大数据运维工程师也可以处理,但是它处理起来的效率就是没有专业的DBA效率块。
二.Linux防火墙-iptables概述
1>.Linux防火墙发展版本
其实Linux防火墙发展到今天已经有好几代了,如下所示:
在Linux内核2.0之前的版本,称为ipfw(ipfirewall);
在Linux内核2.0-2.2之间的版本,称为ipchains(firewall framework);
在Linux内核2.4之后的版本,称为iptables;
在Linux内核4.0之后的版本,称为nftables;
2>.什么是iptables
简单的说iptables就是一个给用户用的管理工具(就好比我们在服务器上用的解释器shell,最终还是要交个内核去处理),它能调用内核对操作系统暴漏的接口。我们使用iptables工具写好规则后,最终执行这些交个netfilter内核框架去执行这些规则实现frewall功能。 我们知道iptables只是位于用户空间的通用编写工具,真正实现firewall的功能是内核中的netfilter。而netfilter在内核中内建了五个钩子函数(hook function,对应小写字母)分别处于整个访问主机路径的不同位置,而使用iptables工具编写规则是不能直接使用netfilter钩子函数的,而是使用和netfilter钩子函数同名的大写字母,我们称之为链(chain),如下所示: prerouting钩子函数:
iptables工具通过PREROUTING链(chain)将操作转给netfilter内核框架中的prerouting钩子函数,PREROUTING链指的是刚刚到达本机的报文,即数据包进入路由表之前。 input钩子函数:
iptables工具通过INPUT链(chain)将操作转给netfilter内核框架中的input钩子函数,INPUT链指的是通过路由表后目的地为本机。 forwarding钩子函数:
iptable工具通过FORWARDING链(chain)将操作转给netfilter内核框架中的forwarding钩子函数,FORWARDING链指的是通过路由表后,目的地不为本机。 output钩子函数:
iptables工具通过OUTPUT链(chain)将操作转给netfilter内核框架中的output钩子函数,OUTPUT链指的是数据报文由本机产生,向外转发。 postrouting钩子函数:
iptables工具通过POSTROUTING链(chain)将操作转给netfilter内核框架中的postrouting钩子函数,POSTROUTING链指的是数据报文发送到网卡接口之前。
iptables这个工具用起来可不是好玩的,因此在CentOS7.x以后,RedHat公司比较体贴的研发了firewalld。firewall是使用python语言研发的一个多功能的命令行工具,不仅如此,它还有一个前端图形界面可以让运维人员去配置(在命令行执行"firewall-config")。
firewalld的图形界面对于非专业人士来讲是很好的工具,就好像我们都是windows用户,需要通过图形化界面去配置一些规则,不过作为一个Linux专业人士试图要通过图形化界面来配置各种防火墙此处我就做不评价了。
3>.iptables的功能
用户空间的iptables和内核空间的netfilter所能够实现的功能不仅仅是防火墙(filter),它还能实现其他的额外功能。还支持nat,magle,rwa等功能。
filter:
作用:
过滤数据包,实现防火墙功能。
基于内核模块:
iptables_filter
可编辑的链(chain):
INPUT
FORWARD
OUTPUT
nat:
作用:
全称为Network address transation,用于修改源IP或目标IP,也可以改端口。转换网络地址的目的是为了隐藏局域网内部主机真实地址。
基于内核模块:
iptable_nat
可编辑的链(chain):
PREROUTING
POSTROUTING
OUTPUT
mangle:
作用:
拆解报文,做出修改,并重新封装起来,即数据包管理(修改包头信息,例如ttl等信息;修改数据包的服务类型;并且可以配置路由实现QOS[流量控制]);
基于内核模块:
iptable_mangle;
可以编辑的链(chain):
PREROUTING
POSTROUTING
INPUT
OUTPUT
FORWARD;
raw:
作用:
关闭nat表上启用的链接追踪机制,即数据包跟踪,决定数据包是否被状态跟踪机制处理。
基于内核模块:
iptable_raw
可修编辑的链(chain):
OUTPUT、PREROUTING
security:
作用:
此表用于强制访问控制(MAC)网络规则,例如由SECMARK和CONNSECMARK目标启用的规则。安全表是在筛选表之后调用,允许筛选表中的任意访问控制(DAC)规则在MAC规则之前生效。
基于内核模块:
强制访问控制由Linux安全模块(如SELinux)实现。
可编辑的链:
INPUT
OUTPUT
FORWARD
三.iptables的工作原理
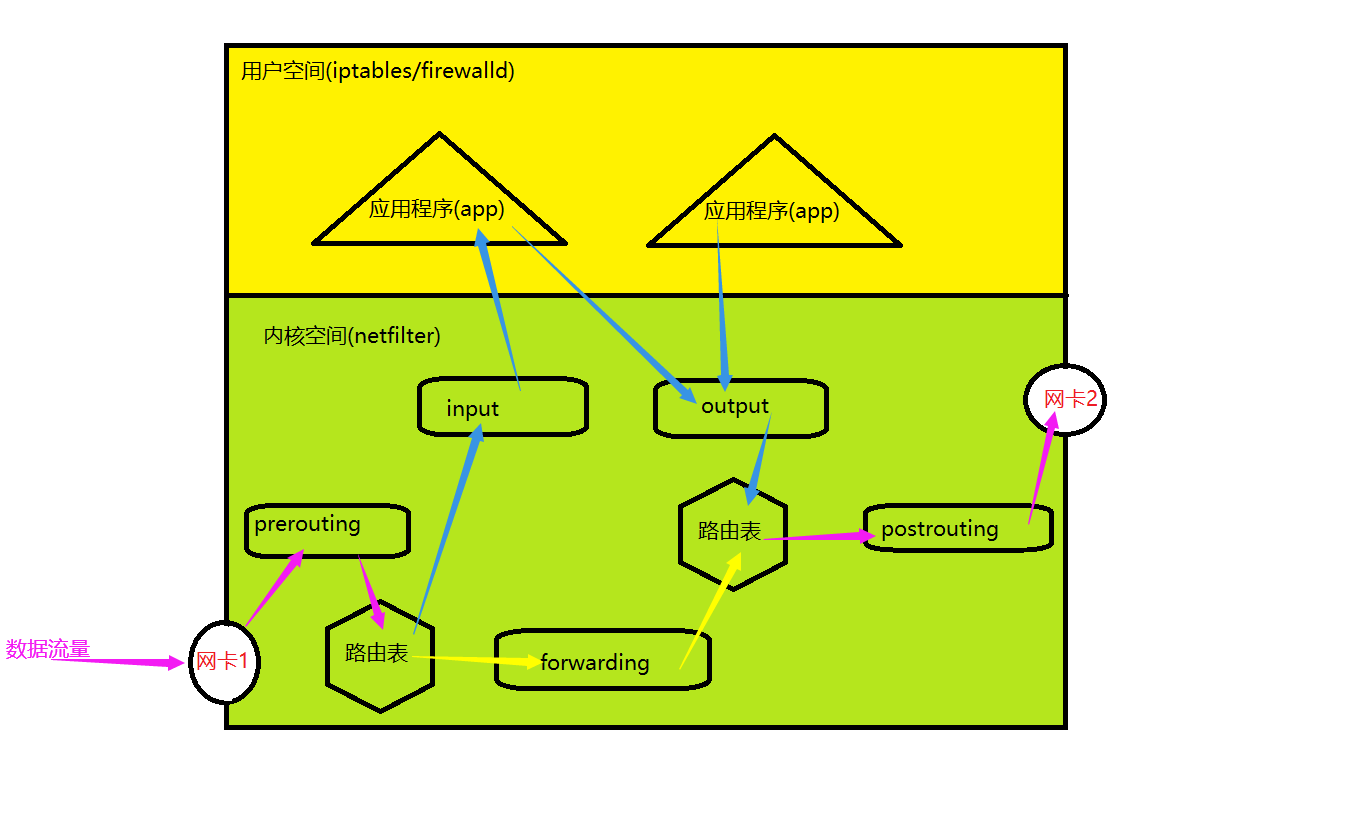
1>.netfilter的工作逻辑
如下图所示: (1)流量通过网卡发送到主机后,会先流向内核空间的prerouting钩子函数,经过一系列规则过滤之后流向了路由表; (2)路由表根据路由规则匹配数据报文,通过包头信息判断出数据包是否归属当前主机,若数据报文属于当前主机则会将该数据报文发送给input钩子函数,否则会发送给forwarding钩子函数; (3)input钩子函数经过一系列规则过滤之后从将数据从内核空间发送给用户空间的应用程序处理; (4)forwarding钩子函数经过一系列规则过滤之后从将数据从再一次发送给路由表; (5)用户空间的程序如果想要发送数给其它主机,需要将数据从用户空间发送给内核空间的output钩子函数,output钩子函数经过一系列规则过滤之后也将数据发送给路由表; (6)路由表根据路由规则匹配吓一跳路由,数据经过postrouting钩子函数发送给网卡;
2>.iptables报文流向规则
入站数据流向(即流入本机流量:PREROUTING ---> INPUT ) 从外界到达防火墙的数据包,先被PREROUTING规则链处理(是否修改数据包地址等),之后会进行路由选择(判断该数据包应该发往何处),如果数据包的目标主机是防火墙本机(比如说Internet用户访问防火墙主机中的web服务器的数据包),那么内核将其传给INPUT链进行处理(决定是否允许通过等),通过以后再交给系统上层的应用程序(比如Apache服务器)进行响应。 转发数据流向(转发的流量: PREROUTING --> FORWARD ---> POSTROUTING ) 来自外界的数据包到达防火墙后,首先被PREROUTING规则链处理,之后会进行路由选择,如果数据包的目标地址是其它外部地址(比如局域网用户通过网关访问QQ站点的数据包),则内核将其传递给FORWARD链进行处理(是否转发或拦截),然后再交给POSTROUTING规则链(是否修改数据包的地址等)进行处理。 出站数据流向(由本机流出的流量:OUTPUT ---> POSTROUTING) 防火墙本机向外部地址发送的数据包(比如在防火墙主机中测试公网DNS服务器时),首先被OUTPUT规则链处理,之后进行路由选择,然后传递给POSTROUTING规则链(是否修改数据包的地址等)进行处理。 上面只是大致介绍了iptables的报文流向规则,实际的iptables各规则表之间的顺序应为:raw ---> mangle ---> nat ---> filter,因此大致走向如下图所示。

3>.编写iptables的规则的注意事项
规则的组成部分: 根据匹配规则来尝试匹配报文,一旦匹配成功,就由规则定义的处理动作做出处理。 匹配条件支持以下两种条件: 基本匹配条件:内建 扩展匹配条件:由扩展模块定义 处理动作: 基本处理动作:内建 扩展处理动作:由扩展模块定义 自定义处理机制:指的是自定义链 iptables的链(chain): 内置链: 对应netfilter内核框架的钩子函数(hook function) 自定义链接: 用于内置链的扩展和补充,可实现更灵活的规则管理机制。 添加规则时的重要考量点: (1)要实现那种功能:即判断添加到哪个表上。 (2)报文流经的路径:即判断添加到哪里链上。 链上的规则次序,即为检查的次序,换句话说,就是链上的规则从上往下依次匹配,一旦匹配上就不再往下匹配,若一条规则都没有匹配上则执行默认规则。因此,定义链上规则次序隐含一定的应用法制: (1)同类规则(访问同一应用):匹配范围小的放在上面,举例如下: 访问apache服务时,我们的规则是匹配172.200.0.0/21这个网段可以访问,其中172.200.1.110/21这台主机不允许访问,默认策略是拒绝所有主机,此时我们应该将拒绝172.200.1.110/21这条规则放在最上面,如果我们将172.200.0.0/21这条规则放在最上面则达不到要想拒绝172.200.1.110/21这台主机访问的效果。 (2)不同类的规则(访问不同应用),匹配到报文频率较大的放在上面,举例如下: 假设服务器有两个应用,sshd服务和haproxy服务,如果有2000万个请求量都是访问复杂均衡器haproxy的,我们应该将haproxy的规则放在上面,否者这2000万个连接每次访问haproxy之前都得先和匹配sshd的规则,发现访问的应用不是sshd后再去匹配第二天规则,从而大量浪费iptables的性能,如果将访问量较多的harpyx规则放在上面,大多数连接都会第一时间匹配到haproxy对应的规则,从而提升性能。 (3)将哪些可由一条规则描述的多个规则合并起来,举例如下: 如果又连续10条规则可以合并为一条建议大家合并为一条规则,否则数据包达到服务器时会依次匹配10次,如果合并10条规则为1条规则时,则可以减少九次匹配的时间,从而提升了工作效率。 (4)设置默认策略 所有规则都没有匹配上则执行默认策略,默认策略如果是拒绝(REJECT[这种方式会响应客户端数据报文,明显的拒绝,不推荐使用]或者DROP[这种方式是悄悄地把数据报文丢掉,推荐使用]),则说明在该链上定义的是白名单,如果默认策略是允许(ACCEPT),则说明在该链上定义的是黑名单。生产环境中建议大家使用白名单。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/12199312.html
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/6255862.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

