

Prometheus分位值Sumary和Histogram数据格式查看
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.分位值概述
1.什么是分位值
分位值是随机变量的特征数之一。将随机变量分布曲线与X轴包围的面积作N等分,得N—1个值(X_1、X_2……X_(N-1)),这些值称为N分位值。
分位值(数)在统计学中也有很多应用,比如在一般的数据分析当中,需要我们计算25分位(下四分位),50分位(中位),75分位(上四分位)值。
2.分位值的意义是什么
分位值即把所有数据从小到达排序,取前N%位置的值,即为该分位的值。
一般用分位值来观察大部分用户数据,平均值会"削峰填谷",同时高分位的稳定性可以忽略掉少量的长尾数据。
高分位数据不适用于全部的业务场景,例如金融支付行业,可能就会要求100%的成功。
3.分位值是如何计算的
以95分位值为例,将采集到的100个数据,从小到大排列,95分位值就是取出第95个用户的数据做统计,同理,50非文职就是第50个人的数据。
举个例子: 有一组数 A=【65 23 55 78 98 54 88 90 33 48 91 84】,计算他的25分位,50分位,75分位值。
- 1.先把上面12个数按从小到大排序:
23、33、48、54、55、65、78、84、88、90、91、98
- 2.12个数有11个间隔,每个四分位间11/4=2.75个数
- 3.手工计算分位值:先把上面12个数按从小到大排序
- 计算25分位:
第1个四分位数为上面12个数中的第1+2.75=3.75个数
指第3个数对应的值48及第3个数与第4个数之间的0.75位置处,即:48+(0.75)*(54-48)=52.5 (52.5为25分位值)。
- 计算50分位:
第2个四分位数为上面12个数中的第1+2.75*2=6.5个数
指第6个数对应的值65及第6个数与第7个数之间的0.5位置处,即:65+(0.5)*(78-65)=71.5 (71.5为50分位值)。
中位值也可以用一种很简单的方法计算,按从小到大排列后:
若数组中数的个数为奇数,则最中间那个数对应的值则为中位值;
若数组中数的个数为偶数,则取中间两个数值的平均值则为中位值,如上(78+65)/2=71.5
- 计算75分位:
第3个四分位数为上面12个数中的第1+2.75*3=9.25个数
指第9个数对应的值88及第9个数与第10个数之间的0.25位置处,即:88+(0.25)*(90-88)=88.5 (88.5为75分位值)。
课后练习:
将1到100分为10等分,则有10个10分位,用以上的方法可计算10分位值和90分位值。
二. histogram数据说明
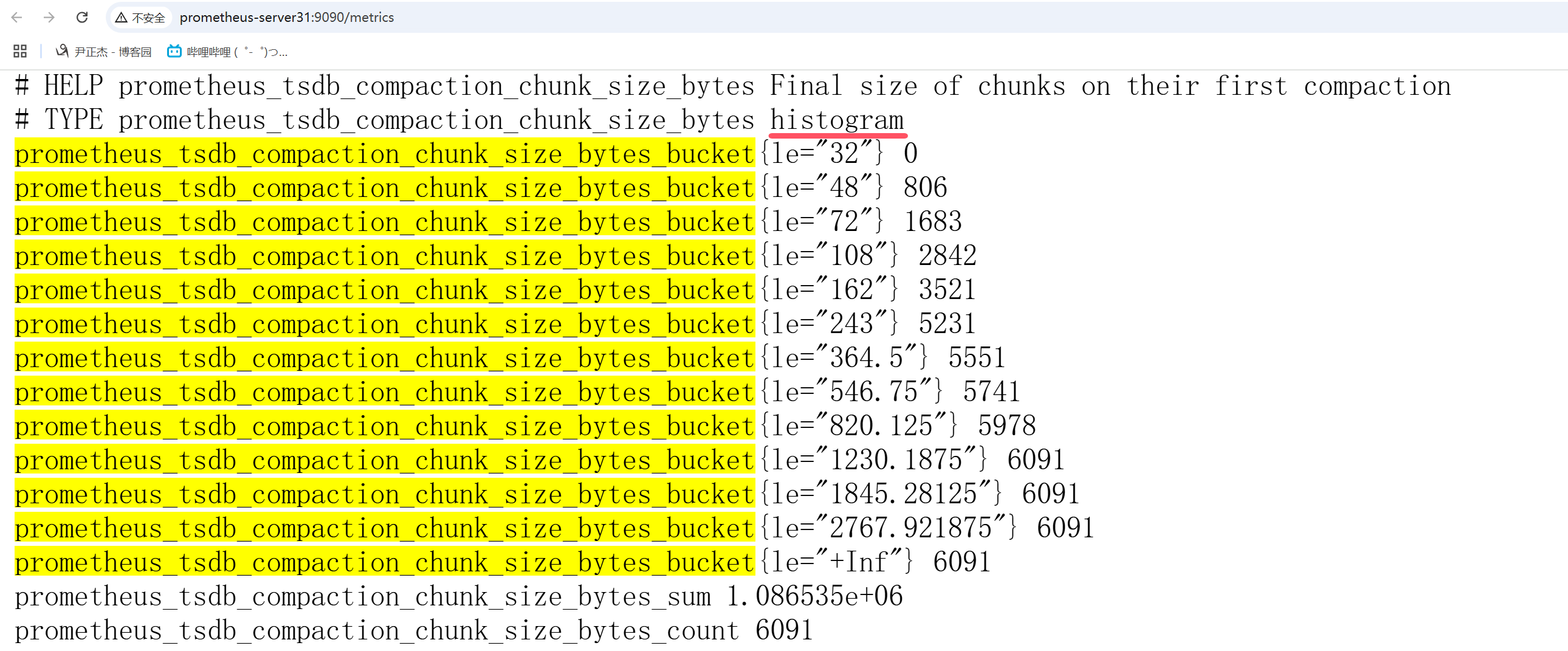
histogram数据指标格式说明:
- XXX_bucket:
代表描述"tsdb_compaction_chunk_size_bytes"小于这个le的记录数位多少个:
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="32"} 0
tsdb压缩块大小小于32bytes的有0个。
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="48"} 806
tsdb压缩块大小小于48byte的有806个。
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="72"} 1683
tsdb压缩块大小小于72byte的有1683个。
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="108"} 2842
tsdb压缩块大小小于108byte的有2842个。
...
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="+Inf"} 6091
最后一定是一个"+Inf"(表示"正无穷")的记录,因为算分位值的时候要用到"+Inf"。
值得注意的是,一个新的数据上报时,会把大于这个value的bucket全部"+1"。
- XXX_sum:
代表记录的和,比如这个指标就是"tsdb_compaction_chunk_size_bytes"tsdb压缩块大小字节总和为"1.086535e+06"(将近1MB)。
- XXX_count:
代表记录"tsdb_compaction_chunk_size_bytes"的数量和,就是一共"6091"次上报。
Prometheus可以使用histogram数据类型可以采用分位值的方式随机采样短时间范围内的数据,从而及时发现问题,这需要配合histogram_quantile函数来使用。
举个例子: HTTP请求的延迟柱状图(下面的"0.95"表示的是分位值,你可以根据需求自行修改即可。)
histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket[1m])) by (le))
histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket{handler="/api/v1/query"}[5m])) by (le))
三. summary数据说明

summary数据指标格式说明:
- XXX{...,quantile=XXX}:
使用quantile关键字定义具体的分位值。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.01"} 14.997928423
代表就是"1"分位值为"14.997928423"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.05"} 14.998842243
代表就是"5"分位值为"14.997928423"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.5"} 15.000025528
代表就是"50"分位值为"15.000025528"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.9"} 15.000811084
代表就是"90"分位值为"15.000811084"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.99"} 15.001590525
代表就是"99"分位值为"15.001590525"秒。
- XXX_sum:
代表记录的和,比如这个指标就是"target_interval(采集目标间隔时间)"消耗描述的和为"4785.00520029"。
- XXX_count:
代表记录的数量和,一共上报了"319"次。
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/18522782,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
标签:
Prometheus


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
· Manus的开源复刻OpenManus初探
2023-11-03 kvm虚拟机磁盘管理
2019-11-03 MySQL/MariaDB数据库的各种日志管理