

Hadoop3.X高可用环境搭建
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.基础环境准备
1.角色分配
| 主机名 | IP地址 | 硬件配置 | 角色说明 | 备注 |
|---|---|---|---|---|
| hadoop151 | 10.0.0.151 | 2Core/4GB/50GB+ | NN,DN,ZKFC,JN,RM,NM | zookeeper,Hadoop,JDK环境 |
| hadoop152 | 10.0.0.152 | 2Core/4GB/50GB+ | DN,JN,RM,NM | zookeeper,Hadoop,JDK环境 |
| hadoop153 | 10.0.0.153 | 2Core/4GB/50GB+ | NN,DN,ZKFC,JN,RM,NM | zookeeper,Hadoop,JDK环境 |
2.准备软件源
[root@hadoop151 ~]# cat /etc/apt/sources.list
deb https://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
[root@hadoop151 ~]#
参考链接:
https://developer.aliyun.com/mirror/ubuntu
温馨提示:
对于阿里云ECS用户,需要将配置文件中 https://mirrors.aliyun.com/ 替换成 http://mirrors.cloud.aliyuncs.com/ 进行使用。
sed -i 's/https:\/\/mirrors.aliyun.com/http:\/\/mirrors.cloud.aliyuncs.com/g' /etc/apt/sources.list
3.部署JDK环境
1.创建工作目录
[root@hadoop151 ~]# mkdir -pv /yinzhengjie/softwares
2.解压软件包
[root@hadoop151 ~]# tar xf jdk-8u291-linux-x64.tar.gz -C /yinzhengjie/softwares
3.配置环境变量
[root@hadoop151 ~]# cat /etc/profile.d/jdk.sh
#!/bin/bash
export JAVA_HOME=/yinzhengjie/softwares/jdk1.8.0_291
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@hadoop151 ~]#
4.加载环境变量
[root@hadoop151 ~]# source /etc/profile.d/jdk.sh
[root@hadoop151 ~]#
5.验证环境是否部署成功
[root@hadoop151 ~]# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
[root@hadoop151 ~]#
温馨提示:
所有节点都需要安装JDK环境哟~
[root@hadoop152 ~]# source /etc/profile.d/jdk.sh
[root@hadoop152 ~]# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
[root@hadoop152 ~]#
[root@hadoop153 ~]# source /etc/profile.d/jdk.sh
[root@hadoop153 ~]# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
[root@hadoop153 ~]#
4.配置host文件解析
[root@hadoop151 ~]# cat >> /etc/hosts <<EOF
10.0.0.151 hadoop151
10.0.0.152 hadoop152
10.0.0.153 hadoop153
EOF
5.配置ssh免密登录
1.更新apt软件源
[root@hadoop151 ~]# apt update
2.安装expect软件包
[root@hadoop151 ~]# apt -y install expect
3.配置免密登录
[root@hadoop151 ~]# cat > password_free_login.sh <<'EOF'
#!/bin/bash
# auther: Jason Yin
# 创建密钥对
ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa -q
# 声明你服务器密码,建议所有节点的密码均一致,否则该脚本需要再次进行优化
export mypasswd=yinzhengjie
# 定义主机列表
hadoop_list=(hadoop151 hadoop152 hadoop153)
# 配置免密登录,利用expect工具免交互输入
for i in ${hadoop_list[@]};do
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@$i
expect {
\"*yes/no*\" {send \"yes\r\"; exp_continue}
\"*password*\" {send \"$mypasswd\r\"; exp_continue}
}"
done
EOF
4.调用免密脚本
[root@hadoop151 ~]# bash password_free_login.sh
5.测试验证
[root@hadoop151 ~]# ssh 'root@hadoop153'
Welcome to Ubuntu 22.04.4 LTS (GNU/Linux 5.15.0-122-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/pro
System information as of Tue Oct 15 08:50:15 AM CST 2024
System load: 0.0 Processes: 217
Usage of /: 19.2% of 47.93GB Users logged in: 1
Memory usage: 11% IPv4 address for eth0: 10.0.0.153
Swap usage: 0%
Expanded Security Maintenance for Applications is not enabled.
50 updates can be applied immediately.
To see these additional updates run: apt list --upgradable
Enable ESM Apps to receive additional future security updates.
See https://ubuntu.com/esm or run: sudo pro status
New release '24.04.1 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Last login: Tue Oct 15 08:43:03 2024 from 10.0.0.1
[root@hadoop153 ~]#
[root@hadoop153 ~]# logout
Connection to hadoop153 closed.
[root@hadoop151 ~]#
6.编写data_rsync.sh同步脚本
1.编写同步脚本
[root@hadoop151 ~]# cat > /usr/local/sbin/data_rsync.sh <<'EOF'
#!/bin/bash
# Auther: Jason Yin
if [ $# -lt 1 ];then
echo "Usage: $0 /path/to/file(绝对路径)"
exit
fi
if [ ! -e $1 ];then
echo "[ $1 ] dir or file not find!"
exit
fi
fullpath=`dirname $1`
basename=`basename $1`
cd $fullpath
HADOOP_NODE=(hadoop151 hadoop152 hadoop153)
for host in ${HADOOP_NODE[@]};do
tput setaf 2
echo ===== rsyncing ${host}: $basename =====
tput setaf 7
ssh ${host} mkdir -pv /yinzhengjie/softwares /yinzhengjie/data/zk
rsync -az $basename `whoami`@${host}:$fullpath
if [ $? -eq 0 ];then
echo "命令执行成功!"
fi
done
EOF
2.添加执行权限
[root@hadoop151 ~]# chmod +x /usr/local/sbin/data_rsync.sh
二.安装zookeeper环境
1.zookeeper集群的节点数量选择
当每秒请求量低于6w/s,读取数据占据70%,大多数是读的场景,官方测试数据建议选择3台集群。
参考链接:
https://zookeeper.apache.org/doc/current/zookeeperOver.html
2.下载zookeeper软件
[root@hadoop151 ~]# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz
3.解压软件包
[root@hadoop151 ~]# tar xf apache-zookeeper-3.8.4-bin.tar.gz -C /yinzhengjie/softwares/
4.配置环境变量
[root@hadoop151 ~]# cat /etc/profile.d/zk.sh
#!/bin/bash
export ZK_HOME=/yinzhengjie/softwares/apache-zookeeper-3.8.4-bin
export PATH=$PATH:$ZK_HOME/bin:$JAVA_HOME/bin
[root@hadoop151 ~]#
[root@hadoop151 ~]# source /etc/profile.d/zk.sh
[root@hadoop151 ~]#
5.准备配置文件
[root@hadoop151 ~]# cat /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/conf/zoo.cfg
# 定义最小单元的时间范围tick。
tickTime=2000
# 启动时最长等待tick数量。
initLimit=5
# 数据同步时最长等待的tick时间进行响应ACK
syncLimit=2
# 指定数据目录
dataDir=/yinzhengjie/data/zk
# 监听端口
clientPort=2181
# 开启四字命令允许所有的节点访问。
4lw.commands.whitelist=*
# server.ID=A:B:C[:D]
# ID:
# zk的唯一编号。
# A:
# zk的主机地址。
# B:
# leader的选举端口,是谁leader角色,就会监听该端口。
# C:
# 数据通信端口。
# D:
# 可选配置,指定角色。
server.151=10.0.0.151:2888:3888
server.152=10.0.0.152:2888:3888
server.153=10.0.0.153:2888:3888
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
[root@hadoop151 ~]#
6.同步数据
[root@hadoop151 ~]# data_rsync.sh /etc/hosts
[root@hadoop151 ~]# data_rsync.sh /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin
[root@hadoop151 ~]# data_rsync.sh /etc/profile.d/zk.sh
7.生成myid文件
[root@hadoop151 ~]# for ((host_id=151;host_id<=153;host_id++)) do ssh hadoop${host_id} "echo ${host_id} > /yinzhengjie/data/zk/myid";done
8.启动zookeeper集群
1.各节点启动服务
source /etc/profile.d/zk.sh
zkServer.sh start
2.各节点查看服务
[root@hadoop151 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@hadoop151 ~]#
[root@hadoop152 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@hadoop152 ~]#
[root@hadoop153 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@hadoop153 ~]#
三.部署Hadoop集群
1.下载Hadoop软件版
1.各节点安装HDFS HA自动切换的依赖
apt -y install psmisc
2.下载Hadoop软件包
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
2.解压软件包
[root@hadoop151 ~]# tar xf hadoop-3.3.6.tar.gz -C /yinzhengjie/softwares/
3.配置环境变量
1.创建环境变量文件
[root@hadoop151 ~]# cat /etc/profile.d/hadoop.sh
#!/bin/bash
export HADOOP_HOME=/yinzhengjie/softwares/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@hadoop151 ~]#
2.使得环境变量生效
[root@hadoop151 ~]# source /etc/profile.d/hadoop.sh
[root@hadoop151 ~]#
4.导入JAVA_HOME环境变量
[root@hadoop151 ~]# vim /yinzhengjie/softwares/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
...
export JAVA_HOME=/yinzhengjie/softwares/jdk1.8.0_291
5.编辑hdfs-site.xml配置文件
[root@hadoop151 ~]# cat /yinzhengjie/softwares/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 这里是配置逻辑名称,可以随意写 -->
<property>
<name>dfs.nameservices</name>
<value>yinzhengjie-hadoop</value>
</property>
<property>
<!-- 禁用权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置NameNode的名称,多个用逗号分割 -->
<name>dfs.ha.namenodes.yinzhengjie-hadoop</name>
<value>nn1,nn2</value>
</property>
<property>
<!--
语法格式: "dfs.namenode.rpc-address.[nameservice ID].[namenode ID]"
表示namenode所在服务器名称和RPC监听端口号
-->
<name>dfs.namenode.rpc-address.yinzhengjie-hadoop.nn1</name>
<value>hadoop151:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.yinzhengjie-hadoop.nn2</name>
<value>hadoop153:8020</value>
</property>
<property>
<!--
语法格式: "dfs.namenode.http-address.[nameservice ID].[namenode ID]"
表示namenode所在服务器名称和HTTP监听端口号
-->
<name>dfs.namenode.http-address.yinzhengjie-hadoop.nn1</name>
<value>hadoop151:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.yinzhengjie-hadoop.nn2</name>
<value>hadoop153:50070</value>
</property>
<property>
<!-- namenode共享的编辑目录,journalnode所在服务器名称和监听的端口 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop151:8485;hadoop152:8485;hadoop153:8485/yinzhengjie-hadoop</value>
</property>
<property>
<!-- namenode高可用代理类,这里配置HDFS客户端连接到Active NameNode的一个java类 -->
<name>dfs.client.failover.proxy.provider.yinzhengjie-hadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 在容灾发生时,保护活跃的namenode,使用ssh自动免密登录。 -->
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<!-- 指定私钥的存储路径 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- 指定HDFS副本数量。 -->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- 指定namenode数据的存储路径 -->
<name>dfs.namenode.name.dir</name>
<value>/yinzhengjie/hadoop/hdfs/namenode</value>
</property>
<property>
<!-- 指定datanode数据的存储路径 -->
<name>dfs.datanode.data.dir</name>
<value>/yinzhengjie/hadoop/hdfs/datanode</value>
</property>
<property>
<!-- 指定journalnode数据的存储路径 -->
<name>dfs.journalnode.edits.dir</name>
<value>/yinzhengjie/hadoop/hdfs/journalnode</value>
</property>
<property>
<!-- 配置namenode自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
[root@hadoop151 ~]#
6.编辑core-site.xml配置文件
[root@hadoop151 ~]# cat /yinzhengjie/softwares/hadoop-3.3.6/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!-- 客户端连接HDFS时,为Hadoop客户端配置默认的高可用路径前缀。 -->
<name>fs.defaultFS</name>
<value>hdfs://yinzhengjie-hadoop</value>
</property>
<property>
<!--
Hadoop数据存放的路径,namenode,datanode数据存放路径都依赖本路径。
不要使用"file:///"开头,使用绝对路径即可。
namenode默认存储路径:
file://${hadoop.tmp.dir}/dfs/name
datanode默认存储路径
file://${hadoop.tmp.dir}/dfs/data
-->
<name>hadoop.tmp.dir</name>
<value>/yinzhengjie/data/hdfs/ha</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>ha.zookeeper.quorum</name>
<value>hadoop151:2181,hadoop152:2181,hadoop153:2181</value>
</property>
</configuration>
[root@hadoop151 ~]#
7.编辑yarn-site.xml配置文件
[root@hadoop151 ~]# cat /yinzhengjie/softwares/hadoop-3.3.6/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Reducer获取数据的方式</description>
</property>
<property>
<name>yarn.nodename.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
<description>声明YARN节点的环境变量</description>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>启用resourcemanager的HA功能</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yinzhengjie-hadoop</value>
<description>标识集群,以确保RM不会接替另一个群集的活动状态</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm151,rm153</value>
<description>ResourceManager的逻辑ID列表</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm151</name>
<value>hadoop151</value>
<description>指定rm151逻辑别名对应的真实服务器地址,即您可以理解添加映射关系.</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm153</name>
<value>hadoop153</value>
<description>指定rm153逻辑别名对应的真实服务器地址,即您可以理解添加映射关系.</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm151</name>
<value>hadoop151:8088</value>
<description>指定RM http监听的节点</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm153</name>
<value>hadoop153:8088</value>
<description>指定RM http监听的节点</description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop151:2181,hadoop152:2181,hadoop153:2181</value>
<description>指定zookeeper集群的地址</description>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>启用自动故障转移(即自动恢复功能)</description>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>指定resourcemanager的状态信息存储在zookeeper集群</description>
</property>
<property>
<name>yarn.resourcemanager.vmem-check-enabled</name>
<value>false</value>
<description>关闭虚拟内存检查</description>
</property>
<property>
<name>yarn.nodemanager.resource.datect-hardware-capabilities</name>
<value>true</value>
<description>启用节点的内存和CPU自动检测,最小内存为1GB</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>启用或禁用日志聚合的配置,默认为false,即禁用,将该值设置为true,表示开启日志聚集功能使能</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
<description>删除聚合日志前要保留多长时间(默认单位是秒),默认值是"-1"表示禁用,请注意,将此值设置得太小,您将向Namenode发送垃圾邮件.</description>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>3600</value>
<description>单位为秒,检查聚合日志保留之间的时间.如果设置为0或负值,那么该值将被计算为聚合日志保留时间的十分之一;请注意,将此值设置得太小,您将向名称节点发送垃圾邮件.</description>
</property>
</configuration>
[root@hadoop151 ~]#
8.编辑mapred-site.xml 配置文件
[root@hadoop151 ~]# cat /yinzhengjie/softwares/hadoop-3.3.6/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!-- 声明MapReduce框架在YARN上运行 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
[root@hadoop151 ~]#
9.编辑workers配置文件
[root@hadoop151 ~]# cat /yinzhengjie/softwares/hadoop-3.3.6/etc/hadoop/workers
hadoop151
hadoop152
hadoop153
[root@hadoop151 ~]#
10.配置启停脚本环境变量
[root@hadoop151 ~]# vim /yinzhengjie/softwares/hadoop-3.3.6/sbin/start-dfs.sh
...
# 注意,这几个变量需要在脚本的开头定义,不要放在脚本的末尾,否则识别不到这些变量哟~
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
[root@hadoop151 ~]# vim /yinzhengjie/softwares/hadoop-3.3.6/sbin/stop-dfs.sh
...
# 注意,这几个变量需要在脚本的开头定义,不要放在脚本的末尾,否则识别不到这些变量哟~
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
[root@hadoop151 ~]# vim /yinzhengjie/softwares/hadoop-3.3.6/sbin/start-yarn.sh
...
# 注意,这几个变量需要在脚本的开头定义,不要放在脚本的末尾,否则识别不到这些变量哟~
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@hadoop151 ~]# vim /yinzhengjie/softwares/hadoop-3.3.6/sbin/stop-yarn.sh
...
# 注意,这几个变量需要在脚本的开头定义,不要放在脚本的末尾,否则识别不到这些变量哟~
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
11.同步配置到集群其它节点
[root@hadoop151 ~]# data_rsync.sh /etc/profile.d/hadoop.sh
[root@hadoop151 ~]# data_rsync.sh /yinzhengjie/softwares/hadoop-3.3.6/
四.HDFS初始化及启停
1.启动zookeeper集群
1.各节点启动zk集群
[root@hadoop151 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop151 ~]#
[root@hadoop152 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop152 ~]#
[root@hadoop153 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop153 ~]#
2.检查ZK集群状态
[root@hadoop151 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@hadoop151 ~]#
[root@hadoop152 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@hadoop152 ~]#
[root@hadoop153 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@hadoop153 ~]#
2.HDFS初始化zookeeper信息
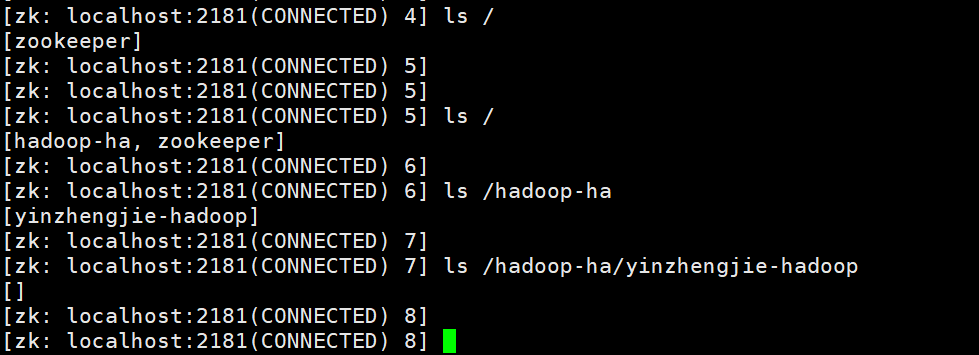
[root@hadoop151 ~]# hdfs zkfc -formatZK
2024-10-12 10:56:13,858 INFO tools.DFSZKFailoverController: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting DFSZKFailoverController
STARTUP_MSG: host = hadoop151/10.0.0.151
STARTUP_MSG: args = [-formatZK]
STARTUP_MSG: version = 3.3.6
...
2024-10-12 10:56:14,514 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/yinzhengjie-hadoop in ZK.
2024-10-12 10:56:14,636 INFO zookeeper.ZooKeeper: Session: 0x9800009c9e070002 closed
2024-10-12 10:56:14,636 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x9800009c9e070002
2024-10-12 10:56:14,637 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x9800009c9e070002
2024-10-12 10:56:14,637 INFO zookeeper.ClientCnxn: EventThread shut down for session: 0x9800009c9e070002
2024-10-12 10:56:14,639 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DFSZKFailoverController at hadoop151/10.0.0.151
************************************************************/
[root@hadoop151 ~]#
温馨提示:
如上图所示,格式化成功后,在zookeeper集群中会自动初始化创建对应的znode信息哟。
3.启动JN集群
[root@hadoop151 ~]# hdfs --daemon start journalnode
[root@hadoop151 ~]#
[root@hadoop151 ~]# jps
2611 JournalNode
2652 Jps
1742 QuorumPeerMain
[root@hadoop151 ~]#
[root@hadoop152 ~]# hdfs --daemon start journalnode
WARNING: /yinzhengjie/softwares/hadoop-3.3.6/logs does not exist. Creating.
[root@hadoop152 ~]#
[root@hadoop152 ~]# jps
1586 QuorumPeerMain
2307 JournalNode
1721 ZooKeeperMain
2347 Jps
[root@hadoop152 ~]#
[root@hadoop153 ~]# hdfs --daemon start journalnode
WARNING: /yinzhengjie/softwares/hadoop-3.3.6/logs does not exist. Creating.
[root@hadoop153 ~]#
[root@hadoop153 ~]# jps
2549 JournalNode
1993 QuorumPeerMain
2590 Jps
[root@hadoop153 ~]#
4.格式化namenode生成默认的镜像文件
[root@hadoop151 ~]# hdfs namenode -format
2024-10-12 11:04:18,575 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop151/10.0.0.151
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.3.6
...
2024-10-12 11:04:21,112 INFO common.Storage: Storage directory /yinzhengjie/hadoop/hdfs/namenode has been successfully formatted.
2024-10-12 11:04:21,295 INFO namenode.FSImageFormatProtobuf: Saving image file /yinzhengjie/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
2024-10-12 11:04:21,493 INFO namenode.FSImageFormatProtobuf: Image file /yinzhengjie/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2024-10-12 11:04:21,510 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2024-10-12 11:04:21,565 INFO namenode.FSNamesystem: Stopping services started for active state
2024-10-12 11:04:21,566 INFO namenode.FSNamesystem: Stopping services started for standby state
2024-10-12 11:04:21,572 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2024-10-12 11:04:21,572 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop151/10.0.0.151
************************************************************/
[root@hadoop151 ~]#
[root@hadoop151 ~]# ll /yinzhengjie/hadoop/hdfs/namenode/current/
total 24
drwx------ 2 root root 4096 Oct 12 19:04 ./
drwxr-xr-x 3 root root 4096 Oct 12 19:04 ../
-rw-r--r-- 1 root root 399 Oct 12 19:04 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Oct 12 19:04 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 Oct 12 19:04 seen_txid
-rw-r--r-- 1 root root 215 Oct 12 19:04 VERSION
[root@hadoop151 ~]#
5.启动active的namenode
[root@hadoop151 ~]# hdfs --daemon start namenode
[root@hadoop151 ~]#
[root@hadoop151 ~]# jps
2769 NameNode
2611 JournalNode
2841 Jps
1742 QuorumPeerMain
[root@hadoop151 ~]#
6.启动Standby的namenode
[root@hadoop153 ~]# hdfs namenode -bootstrapStandby
2024-10-12 11:10:43,268 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop153/10.0.0.153
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 3.3.6
...
STARTUP_MSG: java = 1.8.0_291
************************************************************/
2024-10-12 11:10:43,283 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2024-10-12 11:10:43,414 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
2024-10-12 11:10:43,761 INFO ha.BootstrapStandby: Found nn: nn1, ipc: hadoop151/10.0.0.151:8020
2024-10-12 11:10:44,184 INFO common.Util: Assuming 'file' scheme for path /yinzhengjie/hadoop/hdfs/namenode in configuration.
2024-10-12 11:10:44,184 INFO common.Util: Assuming 'file' scheme for path /yinzhengjie/hadoop/hdfs/namenode in configuration.
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: yinzhengjie-hadoop
Other Namenode ID: nn1
Other NN's HTTP address: http://hadoop151:50070
Other NN's IPC address: hadoop151/10.0.0.151:8020
Namespace ID: 1026241580
Block pool ID: BP-1359559689-10.0.0.151-1728731061094
Cluster ID: CID-d6e4bfb6-4c28-4f14-870c-5ee80196b4db
Layout version: -66
isUpgradeFinalized: true
=====================================================
2024-10-12 11:10:44,798 INFO common.Storage: Storage directory /yinzhengjie/hadoop/hdfs/namenode has been successfully formatted.
2024-10-12 11:10:44,813 INFO common.Util: Assuming 'file' scheme for path /yinzhengjie/hadoop/hdfs/namenode in configuration.
2024-10-12 11:10:44,814 INFO common.Util: Assuming 'file' scheme for path /yinzhengjie/hadoop/hdfs/namenode in configuration.
2024-10-12 11:10:44,849 INFO namenode.FSEditLog: Edit logging is async:true
2024-10-12 11:10:44,932 INFO namenode.TransferFsImage: Opening connection to http://hadoop151:50070/imagetransfer?getimage=1&txid=0&storageInfo=-66:1026241580:1728731061094:CID-d6e4bfb6-4c28-4f14-870c-5ee80196b4db&bootstrapstandby=true
2024-10-12 11:10:45,059 INFO common.Util: Combined time for file download and fsync to all disks took 0.01s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /yinzhengjie/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 took 0.00s.
2024-10-12 11:10:45,059 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 399 bytes.
2024-10-12 11:10:45,066 INFO ha.BootstrapStandby: Skipping InMemoryAliasMap bootstrap as it was not configured
2024-10-12 11:10:45,073 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop153/10.0.0.153
************************************************************/
[root@hadoop153 ~]#
7.启动HDFS集群
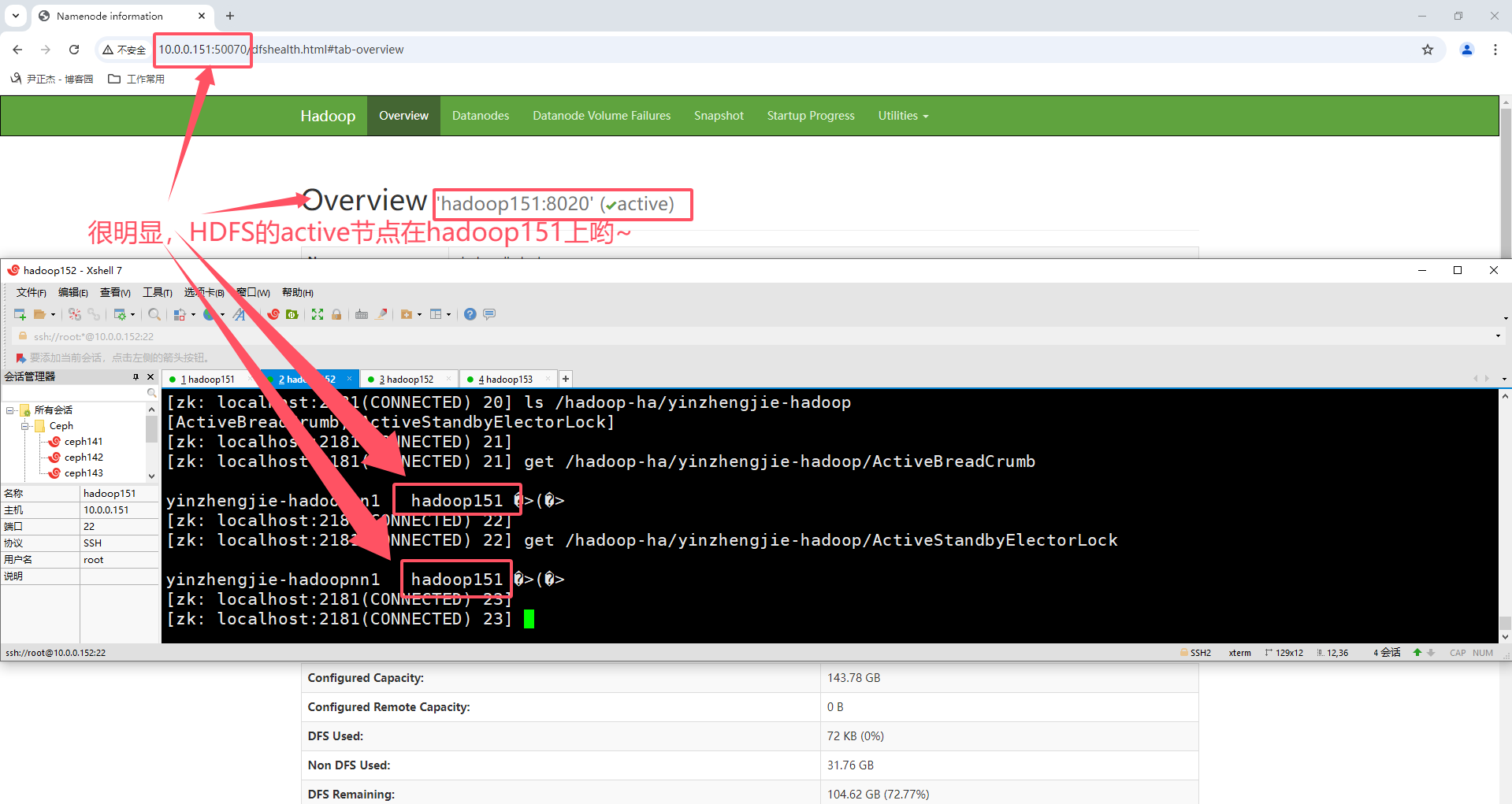
温馨提示:
HDFS集群启动成功后,可以访问NameNode的WebUI,即50070端口
[root@hadoop151 ~]# start-dfs.sh
Starting namenodes on [hadoop151 hadoop153]
hadoop151: namenode is running as process 2769. Stop it first and ensure /tmp/hadoop-root-namenode.pid file is empty before retry.
Starting datanodes
Starting journal nodes [hadoop151 hadoop152 hadoop153]
hadoop152: journalnode is running as process 2307. Stop it first and ensure /tmp/hadoop-root-journalnode.pid file is empty before retry.
hadoop151: journalnode is running as process 2611. Stop it first and ensure /tmp/hadoop-root-journalnode.pid file is empty before retry.
hadoop153: journalnode is running as process 2549. Stop it first and ensure /tmp/hadoop-root-journalnode.pid file is empty before retry.
Starting ZK Failover Controllers on NN hosts [hadoop151 hadoop153]
[root@hadoop151 ~]#
[root@hadoop151 ~]# jps
2769 NameNode
3986 Jps
2611 JournalNode
3927 DFSZKFailoverController
3531 DataNode
1742 QuorumPeerMain
[root@hadoop151 ~]#
[root@hadoop152 ~]# jps
1586 QuorumPeerMain
2594 DataNode
2307 JournalNode
1721 ZooKeeperMain
2747 Jps
[root@hadoop152 ~]#
[root@hadoop153 ~]# jps
3264 Jps
2549 JournalNode
1993 QuorumPeerMain
3212 DFSZKFailoverController
2846 NameNode
2958 DataNode
[root@hadoop153 ~]#
8.启动YARN集群
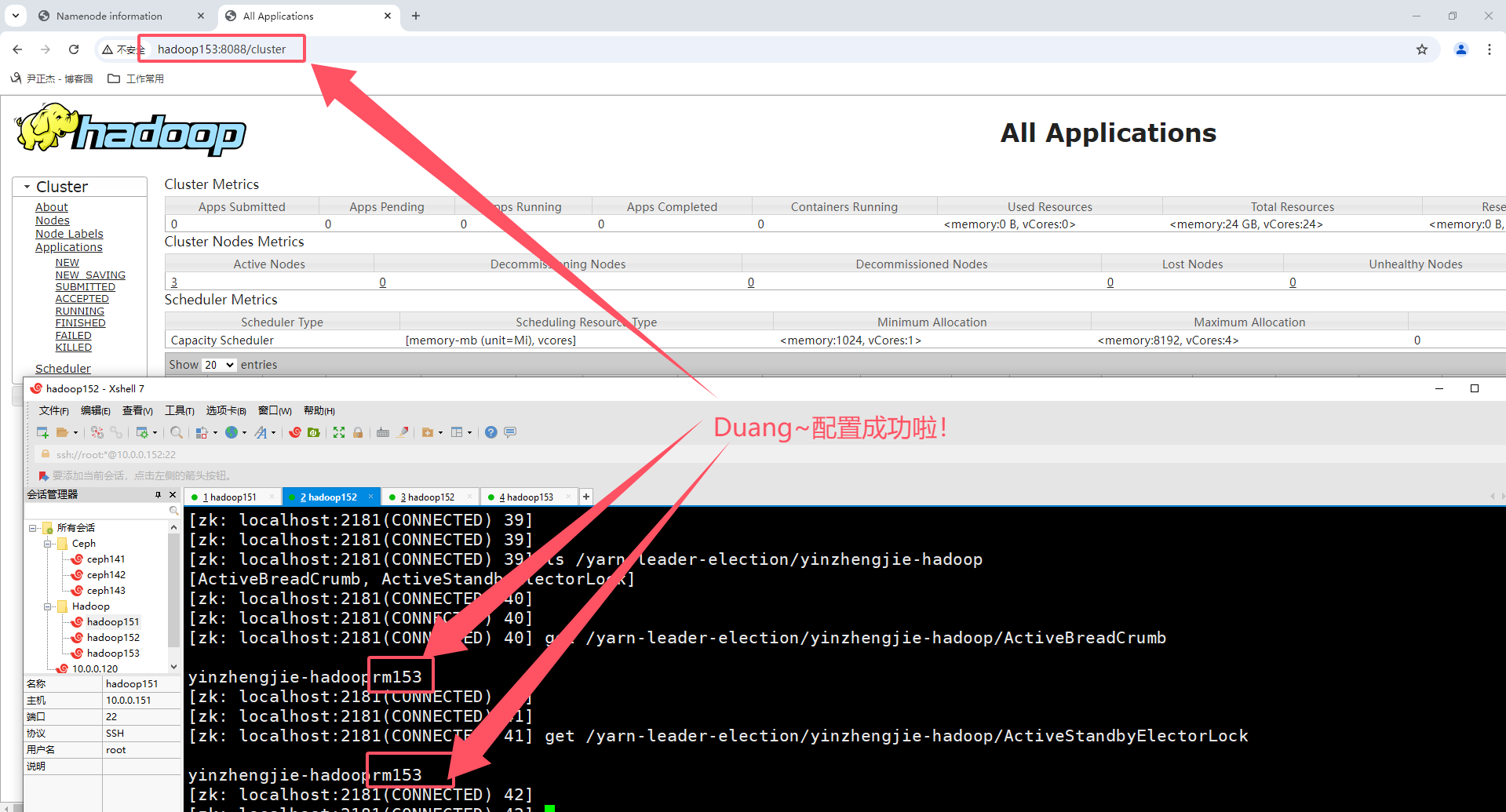
温馨提示:
YARN集群启动成功后,可以访问ResourceManager的WebUI,即8088端口
[root@hadoop151 ~]# start-yarn.sh
Starting resourcemanagers on [ hadoop151 hadoop153]
Starting nodemanagers
[root@hadoop151 ~]#
[root@hadoop151 ~]# jps
2769 NameNode
2611 JournalNode
3927 DFSZKFailoverController
6153 Jps
4795 NodeManager
5947 ResourceManager
3531 DataNode
1742 QuorumPeerMain
[root@hadoop151 ~]#
[root@hadoop152 ~]# jps
1586 QuorumPeerMain
2594 DataNode
3010 NodeManager
2307 JournalNode
1721 ZooKeeperMain
3422 Jps
[root@hadoop152 ~]#
[root@hadoop153 ~]# jps
4242 ResourceManager
2549 JournalNode
4568 Jps
1993 QuorumPeerMain
3212 DFSZKFailoverController
3660 NodeManager
2846 NameNode
2958 DataNode
[root@hadoop153 ~]#
五.补充知识
1.Hadoop停止集群
1.先停止Hadoop集群
[root@hadoop151 ~]# stop-all.sh
Stopping namenodes on [hadoop151 hadoop153]
Stopping datanodes
Stopping journal nodes [hadoop151 hadoop152 hadoop153]
Stopping ZK Failover Controllers on NN hosts [hadoop151 hadoop153]
Stopping nodemanagers
Stopping resourcemanagers on [ hadoop151 hadoop153]
[root@hadoop151 ~]#
2.在停止zookeeper集群
[root@hadoop151 ~]# zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
[root@hadoop151 ~]#
[root@hadoop151 ~]# jps
7323 Jps
[root@hadoop151 ~]#
[root@hadoop152 ~]# zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
[root@hadoop152 ~]#
[root@hadoop152 ~]# jps
3885 Jps
[root@hadoop152 ~]#
[root@hadoop153 ~]# zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /yinzhengjie/softwares/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
[root@hadoop153 ~]#
[root@hadoop153 ~]# jps
5251 Jps
[root@hadoop153 ~]#
3.集群拍快照
略。
2.启动Hadoop集群
1.先启动zookeeper集群
[root@hadoop151 ~]# zkServer.sh start
[root@hadoop152 ~]# zkServer.sh start
[root@hadoop153 ~]# zkServer.sh start
2.启动Hadoop集群
[root@hadoop151 ~]# start-all.sh
Starting namenodes on [hadoop151 hadoop153]
Starting datanodes
Starting journal nodes [hadoop151 hadoop152 hadoop153]
Starting ZK Failover Controllers on NN hosts [hadoop151 hadoop153]
Starting resourcemanagers on [ hadoop151 hadoop153]
Starting nodemanagers
[root@hadoop151 ~]#
[root@hadoop151 ~]#
[root@hadoop151 ~]# jps
1697 DataNode
2966 Jps
2614 NodeManager
2152 DFSZKFailoverController
1929 JournalNode
1290 QuorumPeerMain
1548 NameNode
2463 ResourceManager
[root@hadoop151 ~]#
[root@hadoop152 ~]# jps
1809 Jps
1249 QuorumPeerMain
1691 NodeManager
1421 DataNode
1549 JournalNode
[root@hadoop152 ~]#
[root@hadoop153 ~]# jps
1971 ResourceManager
2215 Jps
1256 QuorumPeerMain
1816 DFSZKFailoverController
1529 DataNode
2075 NodeManager
1420 NameNode
1661 JournalNode
[root@hadoop153 ~]#
3.测试HDFS是否正常工作
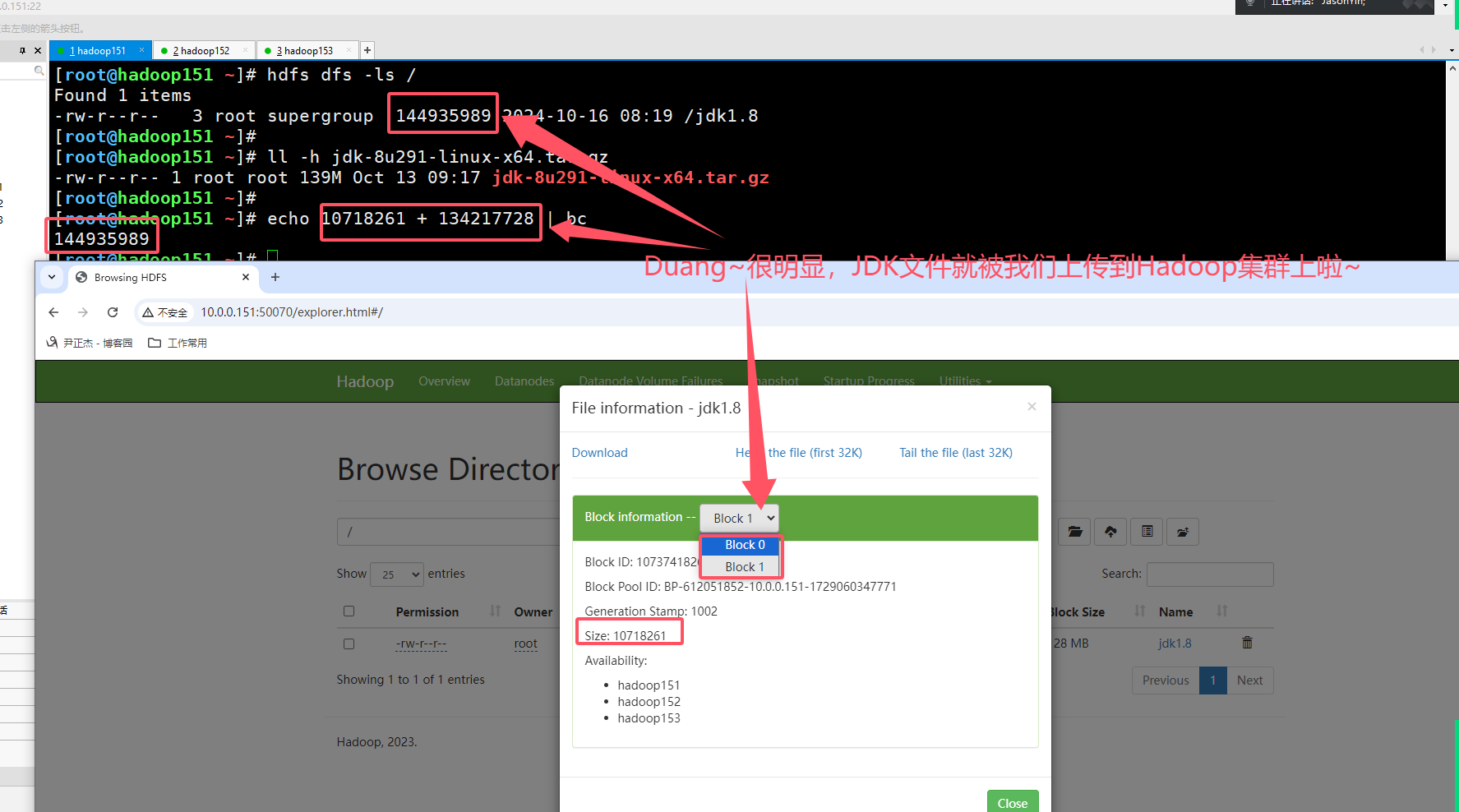
[root@hadoop151 ~]# ll -h jdk-8u291-linux-x64.tar.gz
-rw-r--r-- 1 root root 139M Oct 13 09:17 jdk-8u291-linux-x64.tar.gz
[root@hadoop151 ~]#
[root@hadoop151 ~]# hdfs dfs -put jdk-8u291-linux-x64.tar.gz /jdk1.8
[root@hadoop151 ~]#
[root@hadoop151 ~]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 3 root supergroup 144935989 2024-10-16 08:19 /jdk1.8
[root@hadoop151 ~]#
4.yarn上执行MapReduce程序
1.编写测试文件
cat > k8s.log <<EOF
pod
deploy
ds
rs
rc
jobs
cj
sts
pod
affinity
scheduler
pod
EOF
2.将文件上传到HDFS集群
[root@hadoop151 ~]# hdfs dfs -put k8s.log /yinzhengjie-k8s
[root@hadoop151 ~]#
[root@hadoop151 ~]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 3 root supergroup 144935989 2024-10-16 08:19 /jdk1.8
drwxr-xr-x - root supergroup 0 2024-10-16 08:30 /tmp
-rw-r--r-- 3 root supergroup 59 2024-10-16 08:33 /yinzhengjie-k8s
[root@hadoop151 ~]#
3.测试wordcount示例
hadoop jar /oldboyedu/softwares/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /yinzhengjie-k8s /yinzhengjie/data/output
4.查看产生的数据是否正确
[root@hadoop151 ~]# hdfs dfs -ls /yinzhengjie/data/output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2024-10-16 08:44 /yinzhengjie/data/output/_SUCCESS
-rw-r--r-- 3 root supergroup 71 2024-10-16 08:44 /yinzhengjie/data/output/part-r-00000
[root@hadoop151 ~]#
5.查看测试结果
[root@hadoop151 ~]# hdfs dfs -cat /yinzhengjie/data/output/part-r-00000
affinity 1
cj 1
deploy 1
ds 1
jobs 1
pod 3
rc 1
rs 1
scheduler 1
sts 1
[root@hadoop151 ~]#
5.启用yarn日志聚集功能
推荐阅读:
https://www.cnblogs.com/yinzhengjie/p/9471921.html
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/18473316,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
