
Ubuntu22.04LTS基于cephadm快速部署Ceph Reef(18.2.X)集群
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
目录
一.ceph概述
1.ceph支持的存储类型对比
| 存储类型 | 典型设备 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| cephFS | FTP,NFS服务器为了克服块存储文件无法共享的问题,所以有了文件存储。 在服务器上架设FTP和NFS服务,就是文件存储。 |
1.造价低; 2.方便文件共享; |
1.读写速度低; 2.传输速度慢; |
1.日志存储; 2.有目录结构的文件存储; |
| RBD | 磁盘阵列,硬盘主要将裸磁盘空间映射给主机使用的。 | 1.通过RAID与LVM等手段,对数据提供了保护; 2.多块廉价的硬盘组合起来,提高容量; 3.多块磁盘组合出来的逻辑盘,提升读写效率; |
1.采用SAN架构组网时,光纤交换机,造价成本高; 2.主机之间无法共享数据; |
1.docker容器,虚拟机磁盘存储分配; 2.日志存储; 3.文件存储; |
| RGW | 内置大容量硬盘的分布式服务器(swift,s3)多态服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能。 | 1.具备块存储的读写高速; 2.具备文件存储的共享等特性; |
适合更新变动较少的数据。 1.图片 2.视频 3.音乐等。 |
2.ceph常用术语
2.1 ceph组件介绍
| 组件名称 | 功能描述 |
|---|---|
| monitors | ceph monitor(监视器)对应守护进程为ceph-mon,维护集群状态的映射,包括监视器映射,管理器映射,OSD映射,MDS映射和CRUSH映射。这些映射是ceph守护进程相互协调所需的关键集群状态。 ceph monitor(监视器)还负责守护进程和客户端之间身份验证,通常至少需要三个监视器才能实现冗余和高可用性,基于paxos协议实现节点间的信息同步。 |
| managers | ceph manager(管理器)对应守护进程ceph-mgr,负责跟踪运行时和ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。 ceph管理器守护进程还托管基于Python的模块来管理和公开ceph集群信息,包括基于web的ceph仪表盘和REST API。 高可用性通常至少要两个管理器,基于raft协议实现节点间的信息同步。 |
| ceph osds | Ceph OSD(对象存储设备)对应守护进程ceph-osd,负责存储数据,处理数据复制,恢复,重新平衡,并通过检查其他ceph osd守护进程的心跳像ceph monitor(监视器)和ceph manager(管理器)提供一些监控信息。 同上至少需要3个ceph osd来实现冗余和高可用,本质上osd就是一个个host主机上的存储磁盘。 |
| mds | ceph元数据服务器(MDS[Metadata Server])对应守护进程ceps-mds,负责cephFS存储元数据。 ceph元数据服务器允许POSIX(为应用程序提供的接口标准)文件系统用户执行基本命令(如ls,find等),而不会给ceph存储集群带来巨大负担。 |
| cephfs | 分布式文件系统。类似于高可用的NFS。 |
| radowgw | 对象存储网关,提供http|https接口。 |
2.2 存储术语
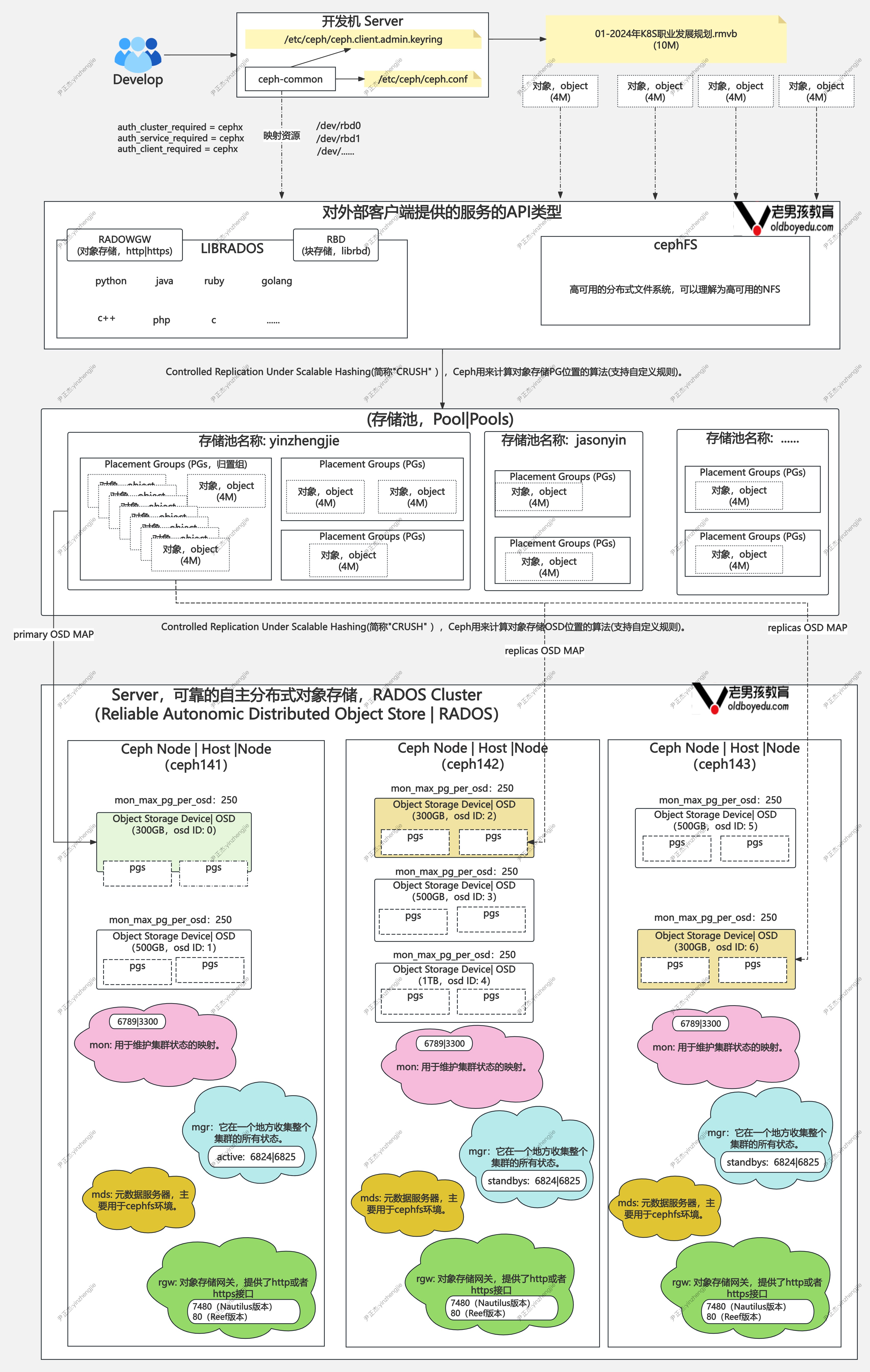
| 名词 | 说明 |
|---|---|
| Pool | RADOS存储集群提供的基础存储服务,需要由“存储池(pool)”分割为逻辑存储区域,一般用于业务数据的逻辑分组管理。 为了方便大家理解,此处可以和前面为讲解的ElasticSearch的"index"术语来类比理解。 |
| Object | 数据在存储到ceph集群时,会将数据按照指定大小切分,分布式存储到ceph到OSD节点设备。 其中每一个被切割的最小存储单位是object(2的22次方,默认是4MB)。 |
| PG | 英文全称为"Placement Group",翻译为归置组,是一个逻辑概念,每个PG中可以存储多个Object对象。 为了方便大家理解,此处可以和前面讲解的ElasticSearch的"Shard"术语来类别理解。 PG是一个虚拟组件,它是对象应是到存储池时使用的虚拟层,是实现大容量集群的关键效率技术。 引入PG这一层其实就是为了更好分配数据和定位数据,一个PG的数据最终会被写到多个不同节点的OSD上以实现数据的冗余。 |
| PGP | 英文全称为"Placement Group for Placement",是用于维持PG和OSD的一种策略。 防止OSD重新分配时候,PG找不到之前的OSD,从而引起大范围的数据迁移。 我们可使用"pgp_num"用于归置PG数了,其值应该等于PG的数量。 |
| CRUSH | 英文全称为"Controlled Replication Under Scalable Hashing",它是一种数据分布式算法,类似于一致性哈希算法。 把对象直接映射到OSD之上会导致二者之间的紧密耦合关系,在OSD设备变动时不可避免地对整个集群产生影响。 所以ceph将一个对象映射进RADOS集群的过程分为两步: - 1.通过一致性哈希算法将对象名称映射到PG; - 2.将PG ID基于CRUSH算法映射到OSD; |
| Crush-releset-name | 存储池所用的CRUSH规则集的名称,饮用的规则集必须事先存在,用户可以自定义这些规则。 |
| RADOS | 英文全称为"Reliable Autonomic Distributed Object Store",可靠的自主分布式对象存储,RADOS Cluster指的是ceph集群。 |
3.ceph的部署方式
| 部署方式 | 原理说明 | 备注 |
|---|---|---|
| cephadm | 1.使用容器和systemd安装和管理ceph集群并与cli和仪表盘GUI紧密集成; 2.仅支持Octopus和更新版本,需要容器和Python3支持; 3.与新的编排API完全集成; |
需要提前安装docker和python环境,官方推荐方法。 |
| rook | 1.在Kubernetes中运行的ceph集群,同时还支持通过Kubernetes API管理存储资源和配置; 2.仅支持Nautilus和较新版本的ceph; |
需要准备一套k8s环境。 |
| ceph-ansible | 使用ansible部署ceph集群,对于新的编排器功能,管理功能和仪表盘支持不好。 | 需要你熟练使用ansible功能。 |
| ceph-deploy | 是一个快速部署集群的工具,不支持CentOS 8系统。对于CentOS官方支持也仅到N版本。 | 1.对于O版本也可以部署成功,但是dashboard功能并不友好,慎重选择; 2.官方已经弃用了,但对于学习来说是一个不错的工具; |
| ceph-mon | 使用JuJu安装ceph | |
| puppet-ceph | 使用puppet安装ceph | |
| 二进制源码 | 手工安装 | |
| window图形 | 在windows主机上,通过鼠标操作就能完成安装。 |
版本特性:
x.0.z
开发版本
x.1.z
候选版本
x.2.z
稳定版本
推荐阅读:
https://docs.ceph.com/en/latest/releases/general/
https://docs.ceph.com/en/latest/install/
https://docs.ceph.com/en/latest/releases/
4.网络划分
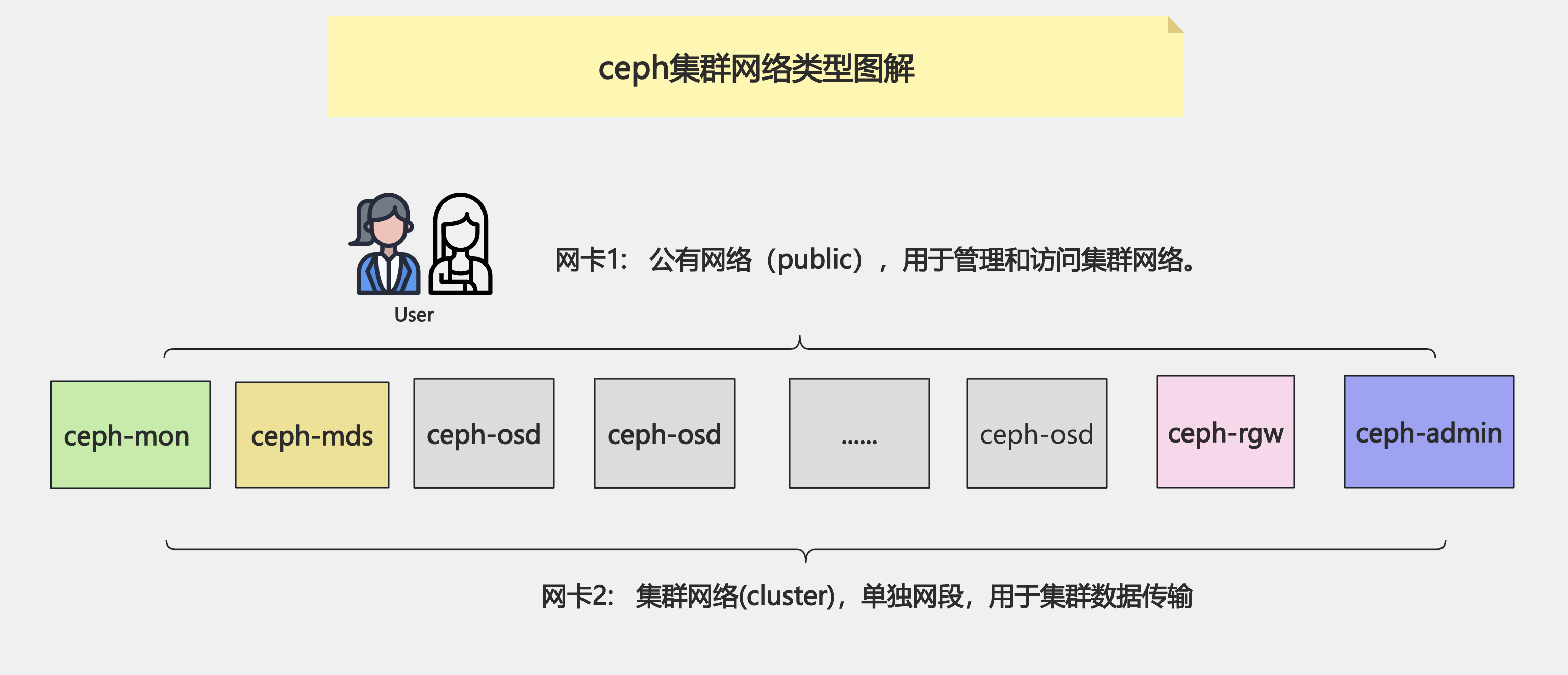
公有网络(public):
用于用户数据通信,可以使用"--public-network"选项指定,比如: 10.0.0.0/24。
集群网络(cluster):
用于集群内部的管理通信,可以使用“--cluster-network”选项指定,比如:"172.30.100.0/24"。
温馨提示:
- 1.早期使用ceph-deploy部署时的确可以使用"--public-network"和“--cluster-network”指定。
- 2.但cephadm部署仅支持"--cluster-network"选项。
5.下载ceph
https://download.ceph.com/
二.Ubuntu22.04LTS基于cephadm快速部署Ceph Reef(18.2.X)集群
1.基础配置
1.基于cephadm部署前提条件,官方提的要求Ubuntu 22.04 LTS出了容器运行时其他都满足
- Python 3
- Systemd
- Podman or Docker for running containers
- Time synchronization (such as Chrony or the legacy ntpd)
- LVM2 for provisioning storage devices
参考链接:
https://docs.ceph.com/en/latest/cephadm/install/#requirements
2.设置时区
timedatectl set-timezone Asia/Shanghai
ll /etc/localtime
3.安装docker环境
略,国内的小伙伴建议二进制安装,yum或者apt安装都需要FQ,可以考虑使用国内的软件源。
当然,SVIP的小伙伴不要慌,用完给大家的一键部署脚步即可。
4.添加hosts文件解析
[root@ceph141 ~]# cat >> /etc/hosts <<EOF
10.0.0.141 ceph141
10.0.0.142 ceph142
10.0.0.143 ceph143
EOF
5.集群时间同步【可跳过】
参考链接:
https://www.cnblogs.com/yinzhengjie/p/14238720.html#3配置时间同步
6.集群环境准备
ceph141:
CPU: 1c
Memory: 2G
/dev/sdb:300GB
/dev/sdc: 500GB
ceph141:
CPU: 1c
Memory: 2G
/dev/sdb:300GB
/dev/sdc: 500GB
/dev/sdd: 1TB
ceph143:
CPU: 1c
Memory: 2G
/dev/sdb:300GB
/dev/sdc: 500GB
2. 启动ceph新集群
1.下载需要安装ceph版本的cephadm
CEPH_RELEASE=18.2.4
curl --silent --remote-name --location https://download.ceph.com/rpm-${CEPH_RELEASE}/el9/noarch/cephadm
2.将cephadm添加到PATH环境变量
[root@ceph141 ~]# mv cephadm /usr/local/bin/
[root@ceph141 ~]#
[root@ceph141 ~]# chmod +x /usr/local/bin/cephadm
[root@ceph141 ~]#
[root@ceph141 ~]# ls -l /usr/local/bin/cephadm
-rwxr-xr-x 1 root root 215316 Aug 20 22:19 /usr/local/bin/cephadm
[root@ceph141 ~]#
3.创建新集群
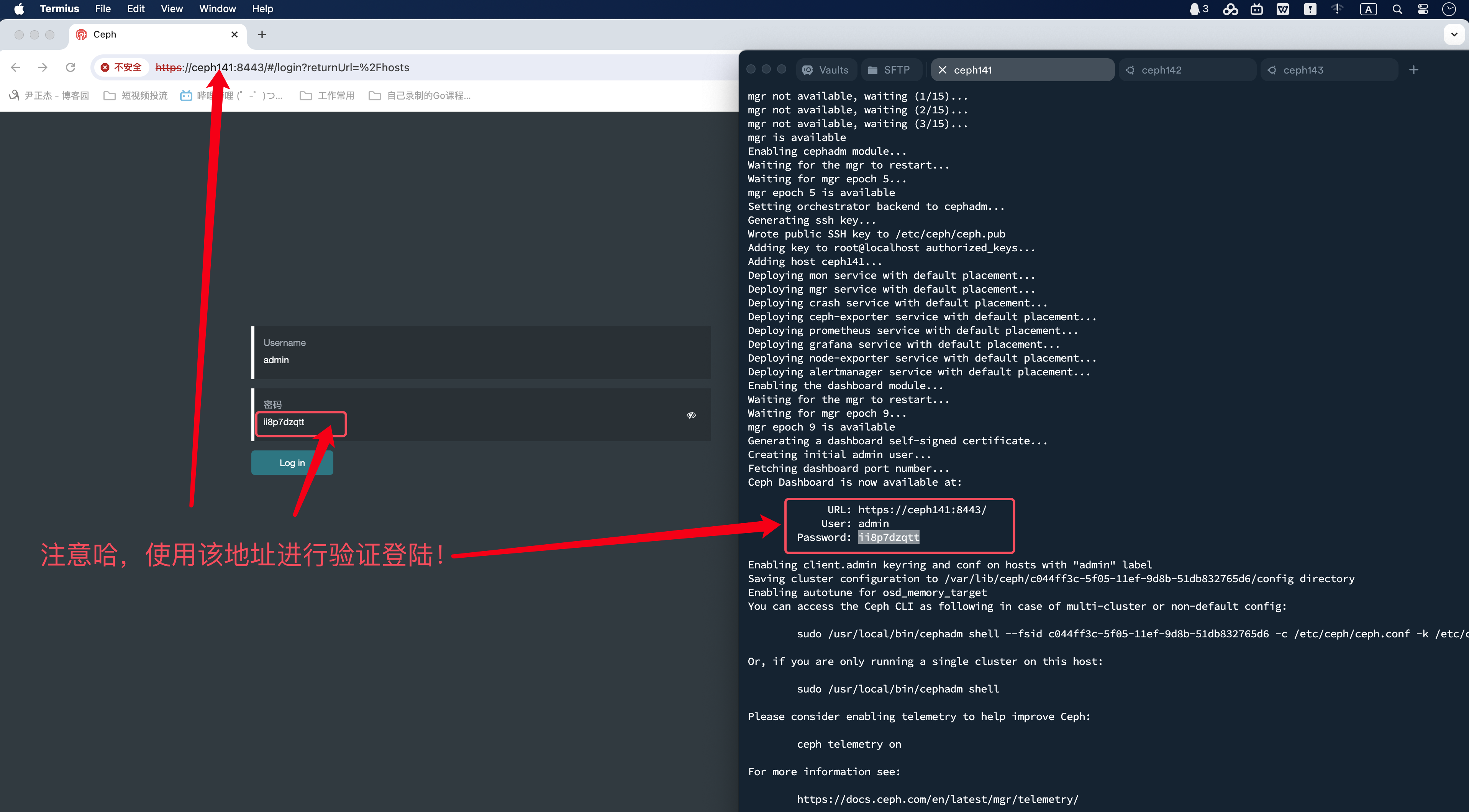
[root@ceph141 ~]# cephadm bootstrap --mon-ip 10.0.0.141 --cluster-network 10.0.0.0/24 --allow-fqdn-hostname
...
Pulling container image quay.io/ceph/ceph:v18...
Ceph version: ceph version 18.2.4 (e7ad5345525c7aa95470c26863873b581076945d) reef (stable)
...
URL: https://ceph141:8443/
User: admin
Password: ii8p7dzqtt
...
sudo /usr/local/bin/cephadm shell --fsid c044ff3c-5f05-11ef-9d8b-51db832765d6 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/local/bin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/en/latest/mgr/telemetry/
Bootstrap complete.
温馨提示:
- 1.此步骤会去官方下载镜像,我们可以将惊喜手动导入;
https://docs.ceph.com/en/latest/install/containers/#containers
- 2.注意观察输出信息,记录dashboard账号信息
3.初始化dashboard的管理员密码
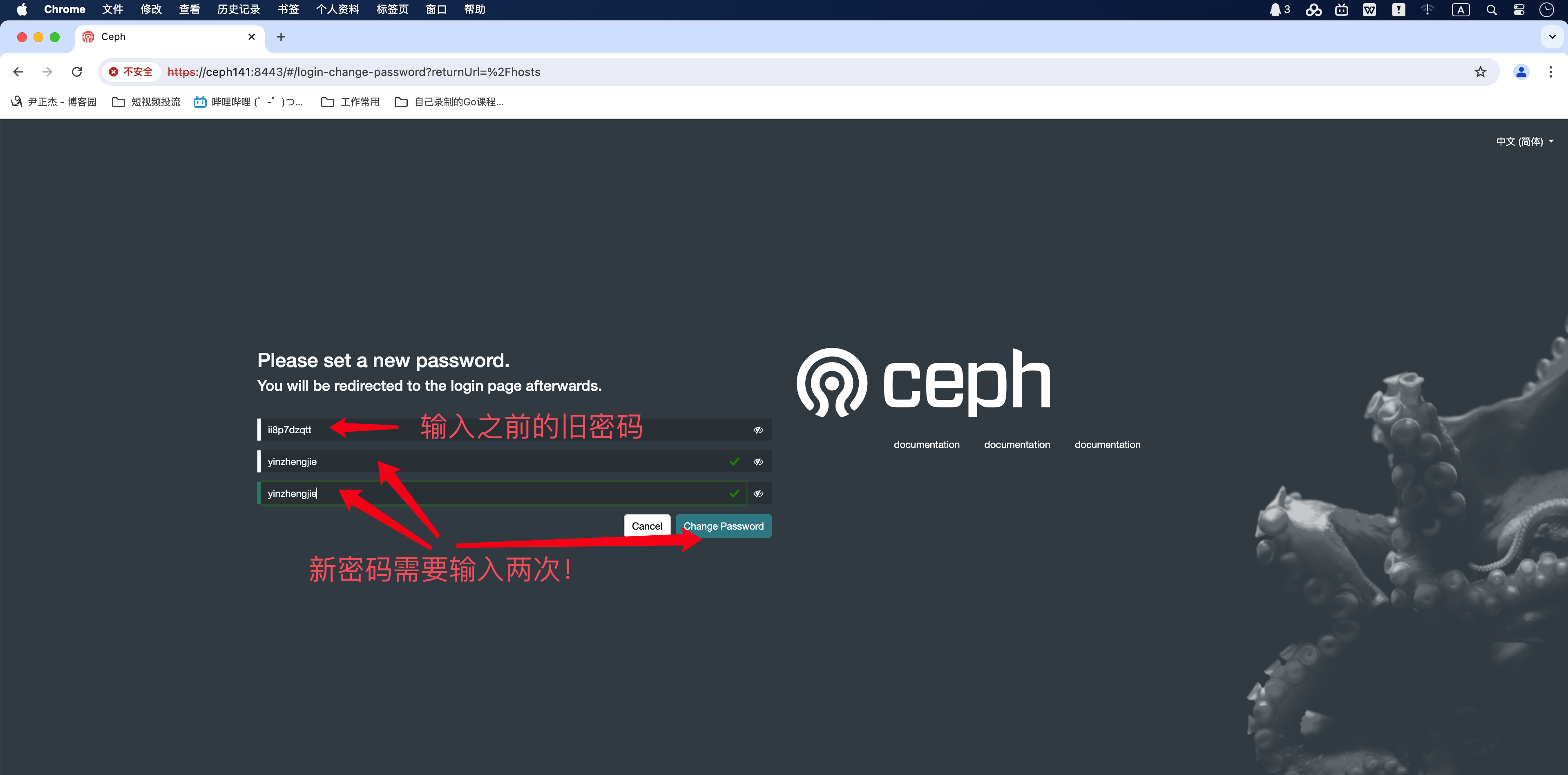
如上图所示,我们首次登陆需要修改密码,按照你的环境自行修改即可。
如下图所示,密码修改成功后就可以登陆dashboard页面啦~
温馨提示:
- 1.先配置ceph管理员节点
参考连接:
https://www.cnblogs.com/yinzhengjie/p/18372796
- 2.除了上面在WebUI的方式修改密码外,也可以基于命令行方式修改密码,只不过在应用时可能需要等待一段时间才能生效。【目前官方已经弃用,大概需要等30s-1min】
[root@ceph141 ~]# echo jasonyin2020 | ceph dashboard set-login-credentials admin -i -
******************************************************************
*** WARNING: this command is deprecated. ***
*** Please use the ac-user-* related commands to manage users. ***
******************************************************************
Username and password updated
[root@ceph141 ~]#
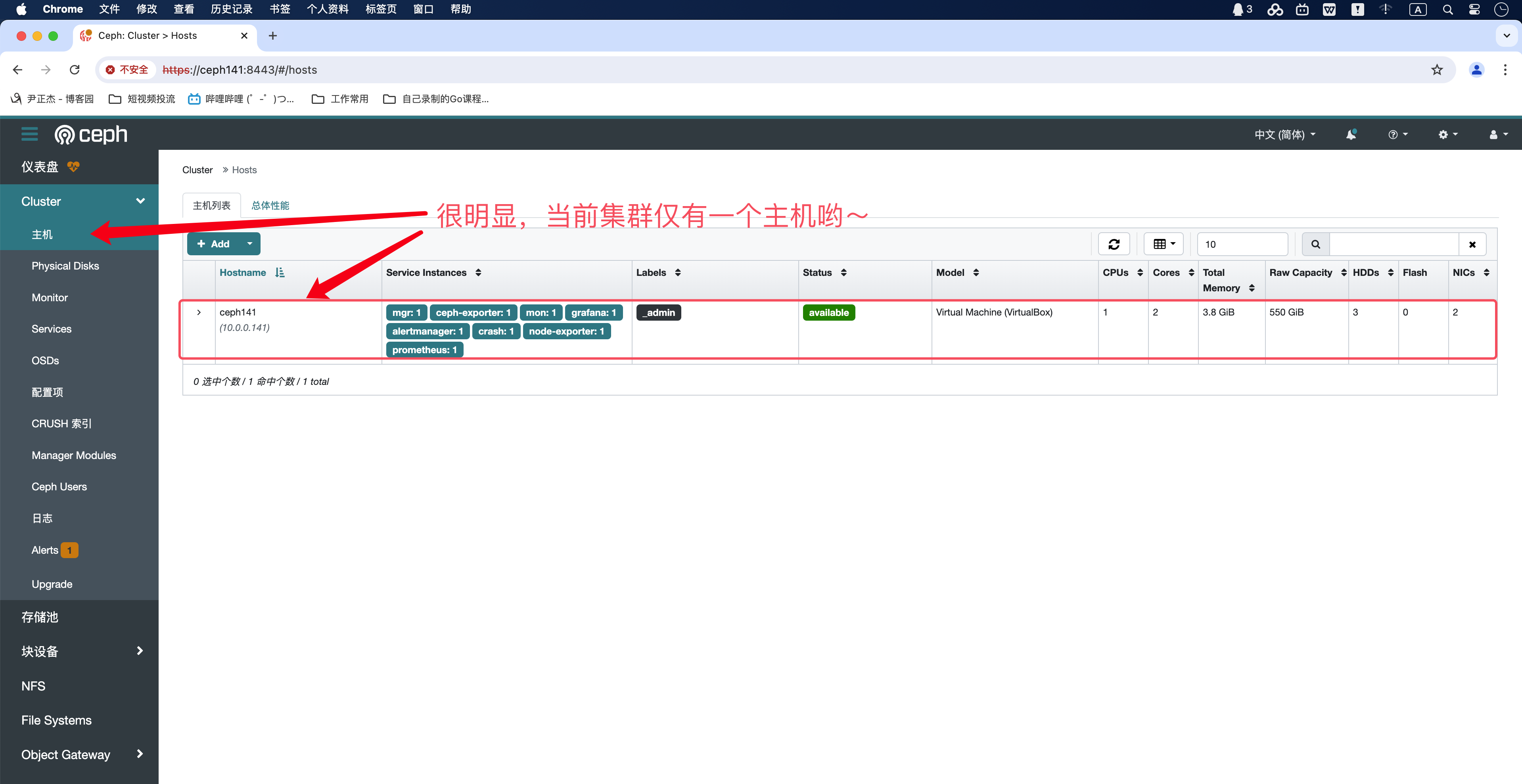
4.ceph集群添加或移除主机
1.查看现有的集群主机列表
[root@ceph141 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph141 10.0.0.141 _admin
1 hosts in cluster
[root@ceph141 ~]#
2.把秘钥放到其他服务器上
[root@ceph141 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub ceph142
[root@ceph141 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub ceph143
3.将秘钥节点加入到集群
[root@ceph141 ~]# ceph orch host add ceph142 10.0.0.142
Added host 'ceph142' with addr '10.0.0.142'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host add ceph143 10.0.0.143
Added host 'ceph143' with addr '10.0.0.143'
[root@ceph141 ~]#
温馨提示:
将集群加入成功后,会自动创建"/var/lib/ceph/<Ceph_Cluster_ID>"相关数据目录。
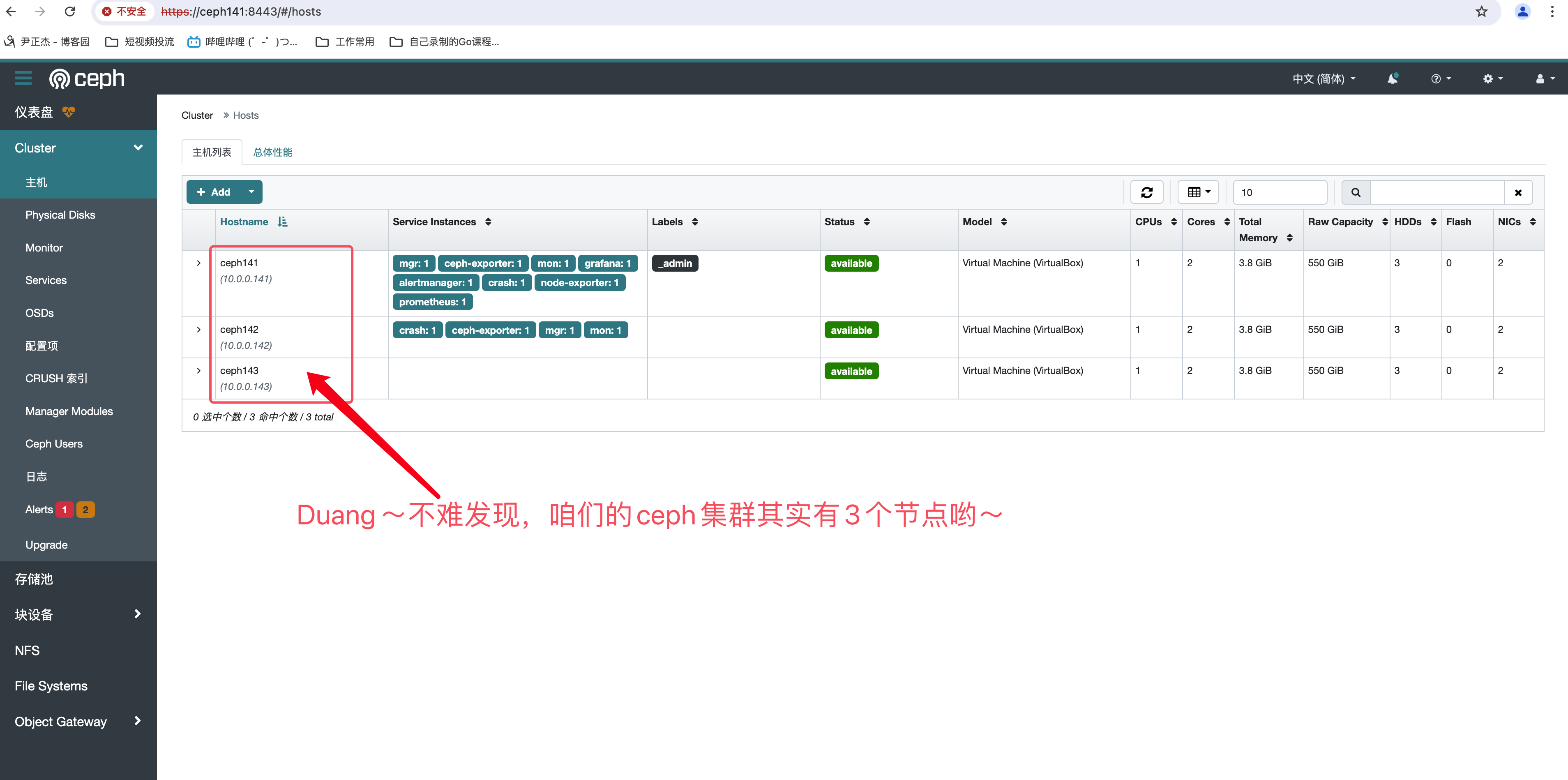
4.再次查看集群的主机列表
[root@ceph141 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph141 10.0.0.141 _admin
ceph142 10.0.0.142
ceph143 10.0.0.143
3 hosts in cluster
[root@ceph141 ~]#
温馨提示:
当然,也可以通过查看WebUI观察ceph集群有多少个主机。
https://ceph141:8443/#/hosts
5.移除主机【选做,如果你将来真有这个需求在操作】
[root@ceph141 ~]# ceph orch host rm ceph143
Removed host 'ceph143'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph141 10.0.0.141 _admin
ceph142 10.0.0.142
2 hosts in cluster
[root@ceph141 ~]#
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host add ceph143 10.0.0.143 # 为了实验效果,我还是将ceph143加回来
Added host 'ceph143' with addr '10.0.0.143'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph141 10.0.0.141 _admin
ceph142 10.0.0.142
ceph143 10.0.0.143
3 hosts in cluster
[root@ceph141 ~]#
5.添加OSD设备到ceph集群
1.添加OSD之前环境查看
1.1 查看集群可用的设备【每个设备想要加入到集群,则其大小不得小于5GB】
[root@ceph141 ~]# ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
ceph141 /dev/sdb hdd 300G Yes 3m ago
ceph141 /dev/sdc hdd 500G Yes 3m ago
ceph141 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 3m ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
ceph142 /dev/sdb hdd 300G Yes 3m ago
ceph142 /dev/sdc hdd 500G Yes 3m ago
ceph142 /dev/sdd hdd 1000G Yes 3m ago
ceph142 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 3m ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
ceph143 /dev/sdb hdd 300G Yes 17s ago
ceph143 /dev/sdc hdd 500G Yes 17s ago
ceph143 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 17s ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
[root@ceph141 ~]#
温馨提示:
如果一个设备想要加入ceph集群,要求满足2个条件:
- 1.设备未被使用;
- 2.设备的存储大小必须大于5GB;
- 3.需要等待一段时间,快则30s,慢则3分钟,线下教学有人笔记本性能不高甚至有等了25min或者40min才等出现设备结果;
1.2 查看各节点的空闲设备信息
[root@ceph141 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
sdb 8:16 0 300G 0 disk
sdc 8:32 0 500G 0 disk
...
[root@ceph141 ~]#
[root@ceph142 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
sdb 8:16 0 300G 0 disk
sdc 8:32 0 500G 0 disk
sdd 8:48 0 1000G 0 disk
...
[root@ceph142 ~]#
[root@ceph143 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
sdb 8:16 0 300G 0 disk
sdc 8:32 0 500G 0 disk
...
[root@ceph143 ~]#
1.3 查看OSD列表
[root@ceph141 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0 root default
[root@ceph141 ~]#
2.添加OSD设备到集群
2.1 添加ceph141节点的设备到ceph集群
[root@ceph141 ~]# ceph orch daemon add osd ceph141:/dev/sdb
Created osd(s) 0 on host 'ceph141'
[root@ceph141 ~]#
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph141:/dev/sdc
Created osd(s) 1 on host 'ceph141'
[root@ceph141 ~]#
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph142:/dev/sdb
Created osd(s) 2 on host 'ceph142'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph142:/dev/sdc
Created osd(s) 3 on host 'ceph142'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph143:/dev/sdb
Created osd(s) 4 on host 'ceph143'
[root@ceph141 ~]#
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph143:/dev/sdc
Created osd(s) 5 on host 'ceph143'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph142:/dev/sdd
Created osd(s) 6 on host 'ceph142'
[root@ceph141 ~]#
温馨提示:
- 1.此步骤会在"/var/lib/ceph/<Ceph_Cluster_ID>/osd.<OSD_ID>/fsid"文件中记录对应ceph的OSD编号对应本地的磁盘设备标识。
- 2.比如查看ceph142节点的硬盘和OSD的对应关系如下:
[root@ceph142 ~]# ll -d /var/lib/ceph/3cb12fba-5f6e-11ef-b412-9d303a22b70f/osd.*
drwx------ 2 167 167 4096 Aug 21 15:18 /var/lib/ceph/3cb12fba-5f6e-11ef-b412-9d303a22b70f/osd.2/
drwx------ 2 167 167 4096 Aug 21 15:19 /var/lib/ceph/3cb12fba-5f6e-11ef-b412-9d303a22b70f/osd.3/
drwx------ 2 167 167 4096 Aug 21 15:22 /var/lib/ceph/3cb12fba-5f6e-11ef-b412-9d303a22b70f/osd.6/
[root@ceph142 ~]#
[root@ceph142 ~]# cat /var/lib/ceph/3cb12fba-5f6e-11ef-b412-9d303a22b70f/osd.*/fsid
68ff55fb-358a-4014-ba0e-075adb18c6d9
b9096186-53af-4ca0-b233-01fd913bdaba
d4ccefb2-5812-4ca2-97ca-9642ff4539f2
[root@ceph142 ~]#
[root@ceph142 ~]# lsblk # 不难发现,ceph底层是基于lvm技术磁盘的。
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
sdb 8:16 0 300G 0 disk
└─ceph--bb7e7dd0--d4e2--4da2--9cfb--da1dcd70222d-osd--block--68ff55fb--358a--4014--ba0e--075adb18c6d9
253:1 0 300G 0 lvm
sdc 8:32 0 500G 0 disk
└─ceph--5b511438--e561--456f--a33e--82bfc9c4abfd-osd--block--b9096186--53af--4ca0--b233--01fd913bdaba
253:2 0 500G 0 lvm
sdd 8:48 0 1000G 0 disk
└─ceph--0d9e77e1--051d--4ba6--8274--cfd85e213ab9-osd--block--d4ccefb2--5812--4ca2--97ca--9642ff4539f2
253:3 0 1000G 0 lvm
...
[root@ceph142 ~]#
2.2 查看集群的osd总容量大小
[root@ceph141 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 3.32048 root default
-3 0.78130 host ceph141
0 hdd 0.29300 osd.0 up 1.00000 1.00000
1 hdd 0.48830 osd.1 up 1.00000 1.00000
-5 1.75789 host ceph142
2 hdd 0.29300 osd.2 up 1.00000 1.00000
3 hdd 0.48830 osd.3 up 1.00000 1.00000
6 hdd 0.97659 osd.6 up 1.00000 1.00000
-7 0.78130 host ceph143
4 hdd 0.29300 osd.4 up 1.00000 1.00000
5 hdd 0.48830 osd.5 up 1.00000 1.00000
[root@ceph141 ~]#
2.3 查看集群的大小
[root@ceph141 ~]# ceph -s
cluster:
id: 3cb12fba-5f6e-11ef-b412-9d303a22b70f
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph141,ceph142,ceph143 (age 19m)
mgr: ceph141.cwgrgj(active, since 3h), standbys: ceph142.ymuzfe
osd: 7 osds: 7 up (since 2m), 7 in (since 3m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 188 MiB used, 3.3 TiB / 3.3 TiB avail # 注意,这是咱们的集群大小共计3.3TB!
pgs: 1 active+clean
[root@ceph141 ~]#
3.当然,也可以在dashboard中查看OSD信息
https://ceph141:8443/#/osd
三.测试集群可用性
1 测试集群
1.创建存储池
[root@ceph141 ~]# ceph osd pool create yinzhengjie
pool 'yinzhengjie' created
[root@ceph141 ~]#
2.往存储池上传文件
[root@ceph141 ~]# rados put sys.txt /etc/os-release -p yinzhengjie
3.查看存储池上传的文件
[root@ceph141 ~]# rados ls -p yinzhengjie
sys.txt
[root@ceph141 ~]#
4.查看存储池文件的状态信息
[root@ceph141 ~]# rados -p yinzhengjie stat sys.txt
yinzhengjie/sys.txt mtime 2024-08-25T09:49:58.000000+0800, size 386
[root@ceph141 ~]#
5.查看PG的副本在哪些OSD上
[root@ceph141 ~]# ceph osd map yinzhengjie sys.txt # 不难发现,pg到三个副本分别在2,1,5哟~
osdmap e64 pool 'yinzhengjie' (2) object 'sys.txt' -> pg 2.486f5322 (2.2) -> up ([2,1,5], p2) acting ([2,1,5], p2)
[root@ceph141 ~]#
6.删除文件
[root@ceph141 ~]# rados -p yinzhengjie rm sys.txt
[root@ceph141 ~]#
[root@ceph141 ~]# rados -p yinzhengjie ls
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd map yinzhengjie sys.txt # 删除文件后不难发现映射信息还在,那如何删除这些映射信息呢?我们后面会陆续讲解到。
osdmap e64 pool 'yinzhengjie' (2) object 'sys.txt' -> pg 2.486f5322 (2.2) -> up ([2,1,5], p2) acting ([2,1,5], p2)
[root@ceph141 ~]#
2.ceph集群拍快照
温馨提示:
关机,拍快照!
3 推荐阅读
ceph集群的OSD管理基础及OSD节点扩缩容:
https://www.cnblogs.com/yinzhengjie/p/18370804
cephadm访问ceph集群的方式及管理员节点配置案例
https://www.cnblogs.com/yinzhengjie/p/18372796
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/18370686,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
标签:
Ceph


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 我干了两个月的大项目,开源了!
· 推荐一款非常好用的在线 SSH 管理工具
· 千万级的大表,如何做性能调优?
· 聊一聊 操作系统蓝屏 c0000102 的故障分析
· .NET周刊【1月第1期 2025-01-05】
2018-08-21 Tomcat定义虚拟主机案例