
ceph分布式存储系统常见术语篇
目录
- 一.分布式存储概述
- 二.Ceph概述
- 三.ceph常见术语
- 1 Application
- 2 BlueStore
- 3 Bucket
- 4 Ceph
- 5 Ceph Block Device | RBD
- 6 Ceph Block Storage
- 7 Ceph Client
- 8 Ceph Client Libraries
- 9 Ceph Cluster Map | Cluster-Map
- 10 Ceph Dashboard | Ceph Manager Dashboard | Dashboard Module
- 11 Ceph File System| CephFS
- 12 Releases
- 13 Ceph Kernel Modules
- 14 Ceph Manager
- 15 FQDN
- 16 Ceph Metadata Server| MDS
- 17 Ceph Monitor
- 18 Ceph Node | Host |Node
- 19 Ceph Object Gateway
- 20 Ceph Object Storage| Ceph Object Store
- 21 Ceph OSD | Ceph OSD Daemon
- 22 Ceph Platform
- 23 Ceph Project
- 24 Ceph Stack
- 25 Ceph Storage Cluster
- 26 CephX
- 27 Client
- 28 Cloud Stacks
- 29 CRUSH
- 30 CRUSH rule
- 31 DAS
- 32 Dashboard
- 33 Hybrid OSD
- 34 LVM tags
- 35 MGR
- 36 MON
- 37 Monitor Store
- 38 Object Storage Device| OSD
- 39 OSD fsid | OSD uuid
- 40 OSD id
- 41 Period
- 42 Placement Groups (PGs)
- 43 Pool|Pools
- 44 Primary Affinity
- 45 Quorum
- 46 RADOS | Reliable Autonomic Distributed Object Store
- 47 RADOS Cluster
- 48 RADOS Gateway | RGW
- 49 Realm
- 50 scrubs
- 51 secrets
- 52 SDS
- 53 systemd oneshot
- 54 Teuthology
- 55 User
- 56 Zone
一.分布式存储概述
1.存储系统分类
存储分为封闭系统的存储和开放系统的存储,而对于开放系统的存储又被分为内置存储和外挂存储。
外挂存储又被细分为直连式存储(DAS)和网络存储(Fabric Attached Storage,FAS),而网络存储又被细分网络接入存储(NAS)和存储区域网络(SAN)等。
- 直连式存储(Direct-attached Storage,DAS):
直连存储,即直接连接到主板的总线上去的,我们可以对这些设备进行格式化操作。典型代表有:IDE,SATA,SCSI,SAS,USB等。
- 网络存储(Fabric Attached Storage,FAS):
存储区域网络(Storage Area Network,SAN):
存储区域网络,是一个网络上的磁盘。它提供的一个块设备而非文件系统。
早期是通过SCSI协议传输数据,后来设计通过光纤通道交换机连接存储阵列和服务器主机,也称为FC SAN,当然也可以基于以太网传输,我们称之为ISCSI协议。
网络附加存储 (Network Attached Storage,NAS):
网络附加存储,是一个网络上的文件系统,我们无法进行格式化操作。典型代表有:NFS,CIFS等。
由于NAS对于普通消费者而言较为熟悉,所以一般网络存储都指NAS。
专门的存储厂商可以通过RAID技术来实现数据的高效存储,国内外很多企业都有自己的存储设备,例如EMC,NetApp,IBM,惠普,Dell,爱数等。
但是这些专业的存储设备不仅价格是非常昂贵的,而且是非常重的,大多数都是基于FC SAN,ISCSI或者NAS访问接口,所以在某种意义上将他们的存储能力和扩展能力是非常有限的,这个时候我们就需要一个能够实现横向存储的分布式存储。
2.存储系统的分类
- 块存储系统:
通常对应的是一个裸设备,比如一块磁盘,我们需要格式化后进行挂载方能使用。
代表产品: lvm,cinder。
- 文件系统存储系统:
文件系统只是数据组织存放的接口。文件系统通常是构建在一个块存储级别之上。
文件系统被分为元数据区域和数据区域,对于用户而言,它呈现为一个树形结构(实际上提供的是一个目录)。
代表产品: NFS,glusterfs。
- 对象存储系统:
对象存储并没有向文件系统那样划分为元数据区域和数据区域,而是按照不同的对象进行存储,而且每个对象内部维护着元数据和数据区域。
因此每个对象都有自己独立的管理格式。
代表产品: Fastdfs,swift。
温馨提示:
上述存储系统的分类中,大家可能不太理解的是"对象存储系统",其实我们实际工作中经常使用,比如百度网盘,QQ离线传送文件等等。
那对象存储到底是如何存储的呢?此处我们以网盘业务为例进行分析:
Q1: 为啥网盘业务通常不会选择文件系统进行存储呢?
答: 基于文件系统进行存储会造成大量的数据冗余,以Linux用户为例,oldboy用户和root用户的家目录并不相同,如果这两个用户都有10TB的"小视频"资源,则2个用户会单独占用2份存储空间,当用户的并发量到达上百万,千万甚至上亿级别就非常浪费存储空间,对公司来说是一笔不小的开销哟。
Q2: 为啥网盘业务通常会使用对象存储呢?
答: 基于对象的一个好处是对于同一个文件始终只存储一份,尽管有上千个用户上传了同一个文件,无论该文件名称是否一致,但只要内容是同一个文件,则始终会上传一个文件哟。这也是为什么我们在上传一个文件时能达到秒传的目的。如何校验不同文件名称其存储的数据相同呢?方法有很多种,比如Linux的"md5sum"命令。
Q3: 基于对象存储的原理是如何的呢?
答: 我们假设网盘有文件的哈希值数据库,有用户表,文件和用户关系表,用户的存储容量表,用户的好友表,用户的分享资源表等等。其工作原理分析如下:
(1)客户端读取本地文件并校验值并发送服务端
当我们上传文件时,客户端程序会读取本地文件内容并计算该文件的哈希值或者是MD5值,并将该值发送给服务端;
(2)服务端校验文件是否上传
1)服务端接收到该哈希值或者是MD5值后,会去查询哈希值数据库,如果数据库有记录,说明该文件已存在,直接返回给客户端数据上传完毕,也就是我们常见的秒上传效果;
2)如果服务端发现客户端发送的哈希值不存在,才会开始上传文件,这意味着是第一次上传该对象资源哟,因此等待的时间比较长。
(3)更新用户信息的元数据
如果用户上传文件后,系统会自动更新用户的存储目录的文件名称哟,也就是元数据的更新。
某影视公司实际案例分享:(我有幸在一家影视类互联网公司工作过)
以上对于对象存储分析看似过于简单,但有助于我们理解对象存储,实际生产环境中比这个要复杂,尤其是第一次上传文件时,通常会对视频数据进行验证,比如"黄","赌","毒"相关视频禁止上传,否则国家会大力整顿。
二.Ceph概述
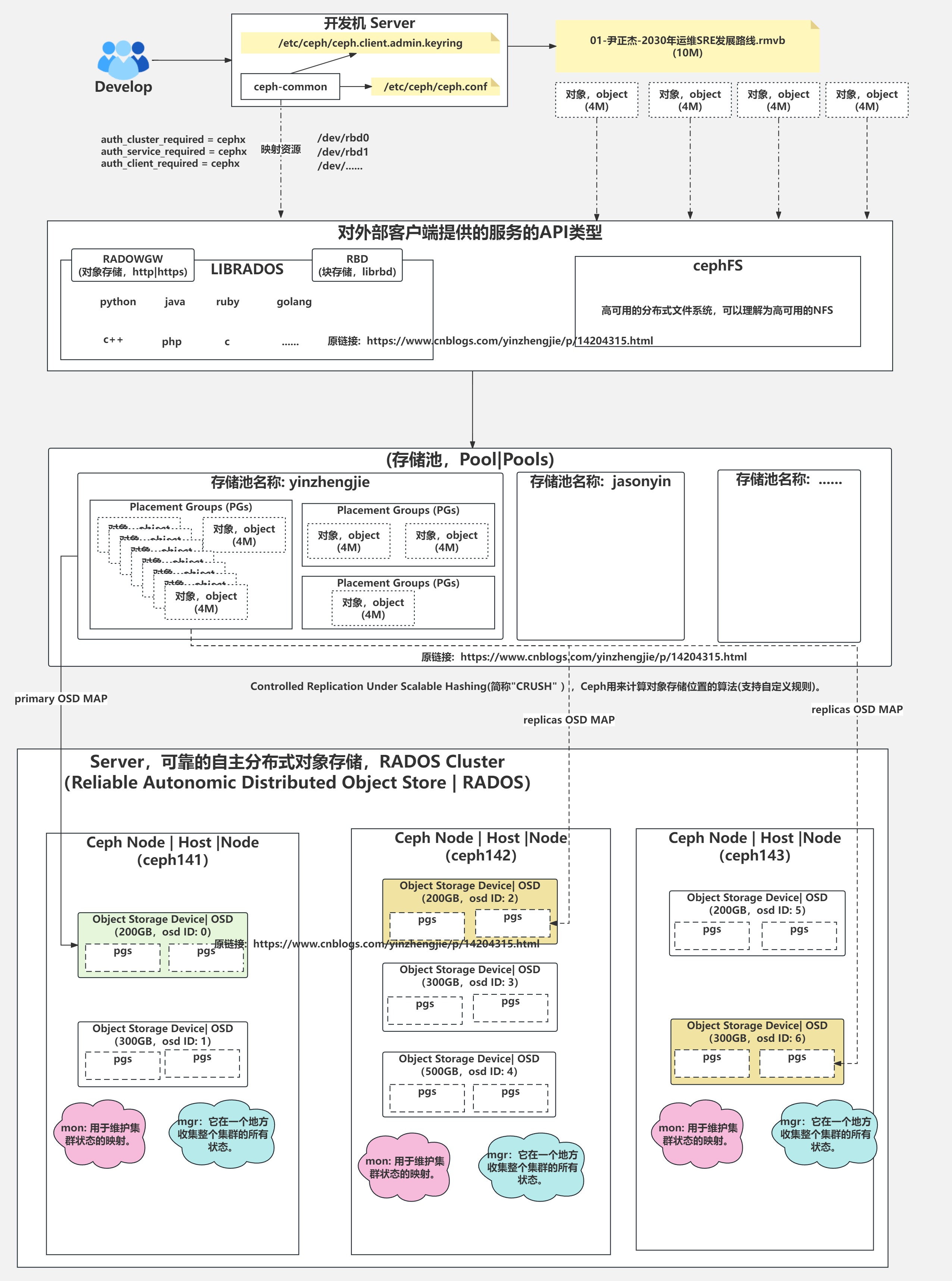
1.Ceph分布式存储系统概述
Ceph是一个对象(object)式存储系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小的对象数据,并以其为原子单元完成数据存取。
对象数据的底层存储服务是由多个主机(host)组成的存储系统,该集群也被称之为RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠,自动化,分布式对象存储系统。
如上图所示,librados是RADOS存储集群的API,它支持C,C++,Java,Python,Ruby和PHP等编程语言。
由于直接基于librados这个API才能使用Ceph集群的话对使用者是有一定门槛的。当然,这一点Ceph官方也意识到了,于是他们还对Ceph做出了三个抽象资源,分别为RADOSGW,RBD,CEPHFS等。
RadosGw,RBD和CephFS都是RADOS存储服务的客户端,他们把RADOS的存储服务接口(librados)分别从不同的角度做了进一步抽象,因而各自适用不同的应用场景,如下所示:
RadosGw:
它是一个更抽象的能够跨互联网的云存储对象,它是基于RESTful风格提供的服务。每一个文件都是一个对象,而文件大小是各不相同的。
他和Ceph集群的内部的对象(object,它是固定大小的存储块,只能在Ceph集群内部使用,基于RPC协议工作的)并不相同。
值得注意的是,RadosGw依赖于librados哟,访问他可以基于http/https协议来进行访问。
RBD:
将ceph集群提供的存储空间模拟成一个又一个独立的块设备。每个块设备都相当于一个传统磁(硬)盘一样,你可以对它做格式化,分区,挂载等处理。
值得注意的是,RBD依赖于librados哟,访问需要Linux内核支持librdb相关模块哟。
CephFS:
很明显,这是Ceph集群的文件系统,我们可以很轻松的像NFS那样使用,但它的性能瓶颈相比NFS来说是很难遇到的。
值得注意的是,CephFS并不依赖于librados哟,它和librados是两个不同的组件。但该组件使用的热度相比RadosGw和RBD要低。
推荐阅读:
查看ceph的官方文档:
https://docs.ceph.com/en/latest/
中文社区文档: (2023年下旬已经停止维护了)
http://docs.ceph.org.cn
温馨提示:
(1)CRUSH算法是Ceph内部数据对象存储路由的算法。它没有中心节点,即没有元数据中心服务器。
(2)无论使用librados,RadosGw,RBD,CephFS哪个客户端来存储数据,最终的数据都会被写入到Rados Cluster,值得注意的是这些客户端和Rados Cluster之间应该有多个存储池(pool),每个客户端类型都有自己的存储池资源。
2.ceph集群架构

参考连接:
https://docs.ceph.com/en/latest/architecture/
三.ceph常见术语
参考连接:
https://docs.ceph.com/en/latest/glossary/
1 Application
更恰当地称为客户端的是,应用程序是Ceph外部使用Ceph集群存储和复制数据的任何程序。
2 BlueStore
OSD BlueStore是OSD守护进程使用的存储后端,专门为与Ceph一起使用而设计。
BlueStore是在Ceph Kraken(V11.2.1,2017-01-01~2017-08-01)发布中引入的。
Ceph的Luminous(V12.2.13,2017-08-01~2020-03-01)版本将BlueStore提升为默认的OSD后端,取代了FileStore。
自Reef(V18.2.1,2023-08-07~2025-08-01)发布以来,FileStore不再作为存储后端使用。
BlueStore将对象直接存储在原始块设备或分区上,并且不与已安装的文件系统交互。
BlueStore使用RocksDB的键/值数据库将对象名称映射到磁盘上的块位置。
3 Bucket
在RGW的上下文中,bucket是一组对象。
在基于文件系统的类比中,对象是文件的对应对象,存储桶是目录的对应对象。
可以在存储桶上设置多站点同步策略,以提供从一个区域到另一个区域的数据移动的细粒度控制。
存储桶的概念取自AWS S3。OpenStack Swift使用术语“容器”来表示RGW和AWS所称的“桶”。
推荐阅读:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/creating-buckets-s3.html
https://docs.aws.amazon.com/AmazonS3/latest/userguide/UsingBucket.html
https://docs.openstack.org/swift/latest/api/object_api_v1_overview.html
4 Ceph
Ceph是一个具有分布式元数据管理和POSIX语义的分布式网络存储和文件系统。
5 Ceph Block Device | RBD
也称为“RADOS块设备”和RBD。
一种软件工具,用于协调Ceph中基于块的数据存储。
Ceph Block Device将基于块的应用程序数据拆分为“块”。
RADOS将这些块存储为对象。
Ceph块设备协调存储集群中这些对象的存储。
6 Ceph Block Storage
Ceph支持的三种存储之一(另外两种是对象存储和文件存储)。
Ceph块存储是块存储“产品”,指的是与以下集合结合使用时与块存储相关的服务和功能:
- librbd(一种提供对RBD映像的类似文件访问的python模块);
- QEMU或Xen等管理程序;
- libvirt等管理程序抽象层;
7 Ceph Client
任何可以访问Ceph存储集群的Ceph组件。
这包括Ceph对象网关、Ceph块设备、Ceph文件系统及其相应的库。
它还包括内核模块和FUSE(USERspace中的文件系统)。
8 Ceph Client Libraries
可用于与Ceph集群组件交互的库集合。
9 Ceph Cluster Map | Cluster-Map
由监视器图、OSD图、PG图、MDS图和CRUSH图组成的一组图,它们一起报告Ceph集群的状态。
为了使Ceph集群正常工作,Ceph客户端和Ceph操作系统必须具有关于集群拓扑的当前信息。
当前信息存储在“Cluster-Map”中,实际上它是五个Map的集合。构成集群地图的五个Map是:
- 监视器映射(The Monitor Map):
包含每个监视器的群集fsid、位置、名称、地址和TCP端口。
监视映射指定当前历元、创建监视映射的时间以及上次修改监视映射的日期。
要查看监视器映射,请运行: "ceph mon dump"。
- OSD映射(The OSD Map):
包含集群fsid、创建OSD映射的时间、OSD映射最后一次修改的时间、池列表、副本大小列表、PG编号列表以及操作系统及其状态列表(例如,up、in)。
要查看OSD地图,请运行: "ceph osd dump"。
- PG贴图(The PG Map):
包含PG版本、时间戳、上一个OSD贴图历元、完整比例以及每个放置组的详细信息。
这包括PG ID、Up Set、Acting Set、PG的状态(例如,active+clean)以及每个池的数据使用统计信息。
- CRUSH映射(The CRUSH Map):
包含存储设备列表、故障域层次结构(例如,设备、主机、机架、行、房间)以及存储数据时遍历层次结构的规则。
要查看CRUSH映射:
- 1.请运行"eph osd getcrushmap -o {filename}",
- 2.然后通过运行"crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename}"来对其进行反编译。
- 3.最后在使用文本编辑器或cat查看反编译的地图。
- MDS映射(The MDS Map):
包含当前MDS映射epoch、创建映射的时间以及上次更改的时间。
它还包含用于存储元数据的池、元数据服务器列表以及哪些元数据服务器已启动。
要查看MDS映射,请执行: "eph fs dump"。
每个映射都会维护其操作状态的更改历史记录。
Ceph监视器维护集群映射的主副本。此主副本包括集群成员、集群状态、对集群的更改以及记录Ceph存储集群总体运行状况的信息。
推荐阅读:
https://docs.ceph.com/en/latest/architecture/#architecture-cluster-map
10 Ceph Dashboard | Ceph Manager Dashboard | Dashboard Module
Ceph Dashboard是一个内置的基于web的Ceph管理和监控应用程序,通过它您可以检查和管理集群中的各种资源。
它被实现为Ceph管理器守护程序模块。
11 Ceph File System| CephFS
ceph文件系统,或称CephFS,是一个兼容POSIX的文件系统,构建在Ceph的分布式对象存储RADOS之上。
推荐阅读:
https://docs.ceph.com/en/latest/architecture/#arch-cephfs
12 Releases
Ceph Interim Release:
Ceph的一个版本尚未通过质量保证测试。可能包含新功能。
Ceph Point Release
任何只包括错误修复和安全修复的临时发布。
Ceph Release
Ceph的任何不同编号版本。
Ceph Release Candidate
Ceph的一个主要版本已经进行了初步的质量保证测试,并准备好进行测试。
Ceph Stable Release
Ceph的一个主要版本,其中之前中期发布的所有功能都已成功通过质量保证测试。
13 Ceph Kernel Modules
可用于与Ceph集群交互的内核模块的集合(例如:Ceph.ko、rbd.ko)。
14 Ceph Manager
Ceph管理器守护进程(Ceph-mgr)是一个与监视器守护进程一起运行的守护进程,用于提供监视以及与外部监视和管理系统的接口。
自从Luminous发布(12.x)以来,没有一个Ceph集群能够正常工作,除非它包含一个正在运行的Ceph-mgr守护进程。
15 FQDN
完全限定域名。应用于网络中某个节点的域名,用于指定该节点在DNS树层次结构中的确切位置。
在Ceph集群管理的上下文中,FQDN通常应用于主机。
在本文档中,术语“FQDN”主要用于区分FQDN和相对较简单的主机名,它们不指定主机在DNS树层次结构中的确切位置,而仅命名主机。
16 Ceph Metadata Server| MDS
Ceph元数据服务器守护进程。也称为“ceph-mds”。
Ceph元数据服务器守护进程必须在运行CephFS文件系统的任何Ceph集群中运行。
MDS存储所有文件系统元数据。
17 Ceph Monitor
一个守护进程,用于维护集群状态的映射。
这个“集群状态”包括监视器映射、管理器映射、OSD映射和CRUSH映射。
Ceph集群必须至少包含三个正在运行的监控器,才能具有冗余性和高可用性。
Ceph监视器及其运行的节点通常被称为“mon”。
推荐阅读:
https://docs.ceph.com/en/latest/rados/configuration/mon-config-ref/#monitor-config-reference
18 Ceph Node | Host |Node
Ceph集群中的任何一台机器或服务器。
Ceph节点是Ceph集群的一个单元,它与Ceph集群中的其他节点通信,以复制和重新分发数据。
所有节点一起称为Ceph存储集群。
Ceph节点包括操作系统、Ceph监视器、Ceph管理器和MDS。
术语“节点”通常相当于Ceph文档中的“主机”。
如果您有一个正在运行的Ceph Cluster,您可以通过运行命令"ceph node ls all"列出其中的所有节点。
19 Ceph Object Gateway
一个建立在librados之上的对象存储接口。
Ceph对象网关提供了应用程序和Ceph存储集群之间的RESTful网关。
20 Ceph Object Storage| Ceph Object Store
Ceph对象存储由Ceph存储集群和Ceph对象网关(RGW)组成。
21 Ceph OSD | Ceph OSD Daemon
Ceph对象存储守护进程。Ceph OSD软件与逻辑磁盘(OSD)交互。
2013年前后,“研究与工业”(Sage自己的话)试图坚持使用“OSD”一词仅表示“对象存储设备”,但Ceph社区一直坚持使用这个词来表示“对象存储Daemon”,正如Sage Weil本人在2022年11月证实的那样,“Daemon 对Ceph的构建方式更准确”(Zac Dover和Sage Weir之间的私人通信,2022年11日7日)。
22 Ceph Platform
所有Ceph软件,包括托管在https://github.com/ceph.
23 Ceph Project
Ceph的人员、软件、任务和基础设施的统称。
24 Ceph Stack
Ceph的两个或多个成分的集合。
25 Ceph Storage Cluster
Ceph监视器、Ceph管理器、Ceph元数据服务器和操作系统的集合,它们协同工作以存储和复制数据供应用程序、Ceph用户和Ceph客户端使用。
Ceph存储集群接收来自Ceph客户端的数据。
26 CephX
Ceph身份验证协议。
CephX对用户和守护进程进行身份验证。
CephX的操作方式与Kerberos类似,但它没有单点故障。
推荐阅读:
https://docs.ceph.com/en/latest/architecture/#arch-high-availability-authentication
https://docs.ceph.com/en/latest/rados/configuration/auth-config-ref/#rados-cephx-config-ref
27 Client
客户端是Ceph外部使用Ceph集群存储和复制数据的任何程序。
28 Cloud Stacks
第三方云供应平台,如OpenStack、CloudStack、OpenNebula和Proxmox VE。
29 CRUSH
可扩展哈希下的受控复制。Ceph用来计算对象存储位置的算法。
30 CRUSH rule
应用于一个或多个特定池的CRUSH数据放置规则。
31 DAS
直连存储。
直接连接到访问它的计算机的存储器,而不需要通过网络。
与NAS和SAN形成对比。
32 Dashboard
一个内置的基于web的Ceph管理和监控应用程序,用于管理集群的各个方面和对象。仪表板是作为Ceph Manager模块实现的。
33 Hybrid OSD
指同时具有HDD和SSD驱动器的OSD。
34 LVM tags
逻辑卷管理器标记。
LVM卷和组的可扩展元数据。
它们用于存储关于设备及其与操作系统的关系的Ceph特定信息。
35 MGR
Ceph管理器软件,它在一个地方收集整个集群的所有状态。
36 MON
Ceph监测软件。
37 Monitor Store
监视器使用的永久性存储。这包括Monitor的RocksDB和"/var/lib/ceph"中的所有相关文件。
38 Object Storage Device| OSD
可能是Ceph OSD,但不一定。
有时(尤其是在较旧的通信中,尤其是在不是专门为Ceph编写的文档中),“OSD”的意思是“对象存储设备”,指的是物理或逻辑存储单元(例如:LUN)。
Ceph社区一直使用“OSD”一词来指代Ceph OSD Daemon,尽管行业在2010年代中期坚持“OSD”应指代“对象存储设备”,因此了解其含义很重要。
39 OSD fsid | OSD uuid
这是用于识别OSD的唯一标识符。它位于名为OSD_fsid的文件的OSD路径中。术语fsid可与uuid互换使用。
40 OSD id
定义OSD的整数。它是在创建每个OSD的过程中由监视器生成的。
41 Period
在RGW的上下文中,周期(Period)是境界(Realm)的配置状态。
时段存储多站点配置的配置状态。
当周期(Period)被更新时,“历元(epoch)”被称为已经改变。
42 Placement Groups (PGs)
放置组(PG)是每个逻辑Ceph池的子集。放置组执行将对象(作为一个组)放置到操作系统中的功能。
Ceph以放置组粒度在内部管理数据:这比管理单个(因此数量更多)RADOS对象更好。
具有较大数量的放置组(例如,每个OSD 100个)的集群比具有较小数量放置组的相同集群更好地平衡。
Ceph的内部RADOS对象都映射到一个特定的放置组,每个放置组恰好属于一个Ceph池。
43 Pool|Pools
池是用于存储对象的逻辑分区。
44 Primary Affinity
OSD的特性,控制给定OSD被选为动作集中的主要OSD(或“主要OSD”)的可能性。
一级亲和性是在萤火虫(v.0.80)中引入的。
推荐阅读:
https://docs.ceph.com/en/latest/rados/operations/crush-map/#rados-ops-primary-affinity
45 Quorum
Quorum是指当群集中的大多数监视器都启动时存在的状态。
群集中必须至少存在三个监视器,才能实现法定人数。
46 RADOS | Reliable Autonomic Distributed Object Store
可靠的自主分布式对象存储。
RADOS是为大小可变的对象提供可扩展服务的对象存储。
RADOS对象存储是Ceph集群的核心组件。存储用户数据的核心存储软件集(MON+OSD)
这篇2009年的博客文章提供了RADOS的入门介绍。有兴趣更深入地了解RADOS的读者可以访问RADOS:用于Petabyte规模存储集群的可扩展、可靠的存储服务。
推荐阅读:
https://ceph.io/en/news/blog/2009/the-rados-distributed-object-store/
https://ceph.io/assets/pdfs/weil-rados-pdsw07.pdf
47 RADOS Cluster
Ceph集群的适当子集,包括操作系统、Ceph监视器和Ceph管理器。
48 RADOS Gateway | RGW
RADOS网关,也称为“Ceph对象网关”。
Ceph的组件为Amazon S3 RESTful API 和Amazon S3 RESTful API提供了一个网关。
49 Realm
在RADOS网关(RGW)的上下文中,领域是一个全局唯一的命名空间,由一个或多个区域组组成。
50 scrubs
Ceph确保数据完整性的过程。
在清理过程中,Ceph会生成一个放置组中所有对象的目录,然后通过将每个主对象与其存储在其他操作系统中的副本进行比较,确保没有对象丢失或不匹配。
任何PG被确定为具有与其他副本不同或完全缺失的对象的副本,则标记为“不一致”(即PG标记为“一致”)。
擦洗有两种:轻度擦洗和深度擦洗(分别称为“正常擦洗”和“深度擦洗”)。
- 每天都会进行轻度清理,只不过是确认给定对象的存在及其元数据是否正确。
- 每周进行一次深度清理,读取数据并使用校验和来确保数据的完整性。
请参阅《RADOS OSD配置参考指南》和《掌握Ceph》第二版(Fisk,Nick,2019)第141页中的“擦除”。
推荐阅读:
https://docs.ceph.com/en/latest/rados/configuration/osd-config-ref/#rados-config-scrubbing
51 secrets
机密是在特权用户必须访问需要身份验证的系统时用于执行数字身份验证的凭据。
秘密可以是密码、API密钥、令牌、SSH密钥、私有证书或加密密钥。
52 SDS
软件定义存储。
53 systemd oneshot
一种系统类型,其中在ExecStart中定义了一个命令,该命令将在完成后退出(不用于守护进程)
54 Teuthology
对Ceph执行脚本测试的软件集合。
55 User
使用Ceph客户端与Ceph存储集群交互的个人或系统参与者(例如,应用程序)。
推荐阅读:
https://docs.ceph.com/en/latest/glossary/#term-Ceph-Storage-Cluster
https://docs.ceph.com/en/latest/rados/operations/user-management/#rados-ops-user
https://docs.ceph.com/en/latest/radosgw/multisite/#radosgw-zones
56 Zone
在RGW的上下文中,分区是由一个或多个RGW实例组成的逻辑组。
区域(Zone)的配置状态存储在时段(period)中。
推荐阅读:
https://docs.ceph.com/en/latest/radosgw/multisite/#radosgw-zones
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/14204315.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

